linux高可用集群(HA)原理详解(转载)
一、什么是高可用集群
高可用集群就是当某一个节点或服务器发生故障时,另一个 节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务。高可用集群是用于单个节点发 生故障时,能够自动将资源、服务进行切换,这样可以保证服务一直在线。在这个过程中,对于客户端来说是透明的。
二、高可用集群的衡量标准
高可用集群一般是通过系统的可靠性(reliability)和系统 的可维护性(maintainability)来衡量的。通常用平均无故障时间(MTTF)来衡量系统的可靠性,用平均维护 时间(MTTR)来衡量系统的可维护性。因此,一个高可用集群服务可以这样来定义:HA=MTTF/(MTTF+MTTR)*100%。
一般高可用集群的标准有如下几种:
99%:表示 一年宕机时间不超过4天
99.9% :表示一年宕机时间不超过10小时
99.99%: 表示一年宕机时间不超过1小时
99.999% :表示一年宕机时间不超过6分钟
三、高可用集群的三种方式
实现高可用集群有三种方式:
(1)、主从方式(非对称)
这种方式组建的高可用集群通常包含2个节点和一个或多个服务器,其中一台作为主节点(active),另一台作为备份节点(standy)。备份节点随时都在检测主节点的健康状况,当主节点发生故障时,服务会自动切换到备份节点上以保证服务正常运行。
这种方式下的高可用集群其中的备份节点平时不会启动服务,只有发生故障时才会有用,因此感觉比较浪费。
(2)、对称方式
这种方式一般包含2个节点和一个或多个服务,其中每一个节点都运行着不同的服务且相互作为备份,两个节点互相检测对方的健康状况,这样当其中一个节点发生故障时,该节点上的服务会自动切换到另一个节点上去。这样可以保证服务正常运行。
(3)、多机方式
这种集群包含多个节点和多个服务。每一个节点都可能运行和不运行服务,每台服务器都监视着几个指定的服务,当其中的一个节点发生故障时,会自动切换到这组服务器中的一个节点上去。
四、高可用集群的组件
实现高可用集群需要用到如下组件:
1、 Messaging Layer:可以理解为信息层,主要的作用是传递当前节点的心跳信息,并告知给对方,这样对方就知道其他节点是否在线。如果不在线,则可以实现资源转移, 这样另一台节点就可以充当主节点,并正常提供服务。传递心跳信息一般使用一根心跳线连接,该线接口可以使用串行接口也可以是以太网接口来连接。每一个节点 上都包含信息层。
可以提供该组件的软件有:
(1)、heartbeat
heartbeat有三个版本即heartbeat v1、heartbeat v2和heartbeat v3
heartbeat v1是比较老的版本,heartbeat v2是目前稳定的版本,在做实验的时候使用该版本。
(2)、corosync(openAIS的子项目)
(3)、keepalive
(4)、cman
Heartbeat 是比较常用的软件,Keepalived配置相对比较简单,而ultramonkey好像不怎么常用,Corosync比heartbeat功能还要强大,功能更加丰富。
后续实验过程以上三种都会使用到
2、
CRM:Cluster Resource
Messager,该组件叫做资源管理器,它主要是用来提供那些不具有高可用的服务提供高可用性的。它需要借助Messaging
Layer来实现工作,因此工作在Messaging Layer上层。资源管理器的主要工作是根据messaging
Layer传递的健康信息来决定服务的启动、停止和资源转移、资源的定义和资源分配。在每一个节点上都包含一个CRM,且每个CRM都维护这一个
CIB(Cluster Internet
Base,集群信息库),只有在主节点上的CIB是可以修改的,其他节点上的CIB都是从主节点那里复制而来的。在CRM中还包含LRM和DC等组件。
可以提供CRM的软件有:
heartbeat v1自带的资源管理为haresource
heartbeat v2自带的资源管理有haresource和crm
其中crm由于配置文件是XML格式的,大多数人如果不懂其语法格式的话,可能会出现配置错误。因此crm提供了一个监听端口,可以用其它GUI工具来配置管理集群
Heartbeat V3 版后资源管理器独立出来,而不是作为Heartbeat的一部分了,它的名字叫Pacemaker功能异常强大,还提供了命令行工具来管理集群。
Cman 是红帽开发的一个资源管理器,在红帽5.X版本上可能遇到,6.x版本后红帽也开始使用强大的pacemaker
3、LRM:Local Resource Messager,叫做本地资源管理器,它是CRM的一个子组件,用来获取某个资源的状态,并且管理本地资源的。例如:当检测到对方没有心跳信息时,则会启动本地相应服务。
4、
DC:可以理解为事务协调员,这个是当多个节点之间彼此收不到对方的心跳信息时,这样各个节点都会认为对方发生故障了,于是就会产尘分裂状况(分组)。并
且都运行着相关服务,因此就会发生资源争夺的状况。因此,事务协调员在这种情况下应运而生。事务协调员会根据每个组的法定票数来决定哪些节点启动服务,哪
些节点停止服务。 例如高可用集群有3个节点,其中2个节点可以正常传递心跳信息,与另一个节点不能相互传递心跳信息,因此,这样3个节点就被分成了2
组,其中每一个组都会推选一个DC,用来收集每个组中集群的事务信息,并形成CIB,且同步到每一个集群节点上。同时DC还会统计每个组的法定票数(quorum),当该组的法定票数大于二分之一时,则表示启动该组节点上的服务;否则停止该节点上的服务。对于某些性能比较强的节点来说,它可以投多张票,因此每个节点的法定票数并不是只有一票,需要根据服务器的性能来确定。DC一般位于主节点上。
5、PE和TE
PE和TE也是DC的子组件,其中:
PE(Policy Engine):策略引擎,来定义资源转移的一整套转移方式,但只是做策略者,并不亲自来参加资源转移的过程,而是让TE来执行自己的策略。
TE(Transition Engine): 就是来执行PE做出的策略的并且只有DC上才运行PE和TE。
6、stonithd组件
STONITH(Shoot The Other Node in the
Head,”爆头“), 这种方式直接操作电源开关,当一个节点发生故障时,另
一个节点如果能侦测到,就会通过网络发出命令,控制故障节点的电源开关,通过暂时断电,而又上电的方式使故障节点被重启动或者直接断电,
这种方式需要硬件支持。
如果备份节点在某一时刻不能收到主节点的心跳信息时,那么如果此时备份节点立刻抢占资源时,而此时主节点正好在执行
写操作,备份节点一旦也执行相应的写操作,会导致文件系统错乱或者服务器崩溃,因此在抢占资源的时候可以使用资源隔离机制来防止此类事件发生。而我们常常
使用stonithd(即爆头)来使主节点不在抢占资源。
其中资源隔离包括:
(1)、节点级别
使用stonithd设备来实现
(2)、资源级别
例如:使用FC SAN switch可以实现在存储资源级别拒绝某节点的访问
7、共享存储
对
于某些服务如http、mysql等服务,需要将某些数据共享,这样当使用不同的节点来访问存储设备时,都可以返回正确的信息。如果不使用存储设备,假设
http服务为例,当某个客户想访问某个图片时,如果这个图片只放在某个指定的服务器上时,一旦该服务器挂了,http服务就会切换到另一台设备上去,而
另一台设备上面没有该图片,那么该用户此时就不能访问该图片了,当然这种情况是我们不想看到了。为了解决这类事件发生,可以使用共享存储设备,将相关的数
据放在共享设备上,这样无论那一台服务器挂了,都不会影响用户的访问。
常用的共享存储设备有如下三种:
DAS:Direct Attached Storage,直接附加存储
NAS:Network Attached Storage,网络附加存储
SAN:Storage Area Network,存储区域网络
因此,一个高可用集群服务的组件架构大概是这样子的:
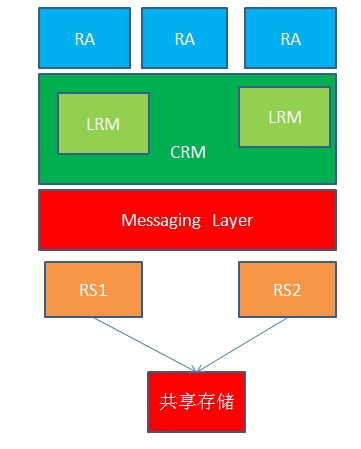
8、资源
在上面好多地方都讲到了资源,那么什么是资源呢?实现一个高可用性需要那些资源呢?
其实资源就是启动一个服务需要的子项目。例如启动一个httpd服务,需要ip,也需要服务脚本、还需要文件系统(用来存储数据的),这些我们都可以统称为资源。因此,实现一个高可用集群一般需要
ip、服务(脚本)和文件系统(存储数据),当然有些高可用集群不需要存储设备的。
资源也是有类型的,可以分为这样几类:
(1)、primitive:可以理解为主资源,有时候看到的会是native,都是一个意思,该资源只在主节点上有。(当然备份节点一旦将资源夺过来了,也就成了主节点,因此,主节点是相对来说的)
(2)、group:组资源,将多个资源绑定在一个同一个组上面且运行在同一个节点上。
(3)、clone:是将primitive资源克隆n份且运行在每一个节点上
(4)、master/slave:也是将primitive克隆2份、其中master和slave节点各运行一份,且只能在这2个节点上运行。
对于某些集群服务来说,启动相关的资源是有先后顺序的。例如启动一个mysql集群服务,首先应该先挂载共享存储设备,否则即时mysql服务启动起来了,用户也访问不了数据。因此,一般说来,我们需要将资源进行约束。资源约束有如下几类:
(1)、 位置约束(location):资源对节点的倾向程度,通常可以使用一个分数(score)来定义,当score为正值时,表示资源倾向与此节点;负值表 示资源倾向逃离于此节点。也可以将score定义为-inf(负无穷大)和inf(正无穷大)。例如:有三个节点rs1、rs2、rs3当rs1是主节点 且发生故障时,则比较rs2和rs3的score值,谁是正值,则资源将会转移到哪个节点上去。
(2)、排列约束(colocation):用来定义资源是否可以在一起,通常也是使用一个score来定义的。当score是正值表示资源可以在一起;否则表示不可以在一起。通过定义资源类型为group也可以来将所有资源绑定在一起。
(3)、顺序约束(order):用来定义资源启动和停止的顺序。例如,首先应该先挂载共享存储,在启动httpd或mysqld服务才行吧。
资源粘性:用来定义资源是否倾向留在该节点。通常使用score来定义,当score为正数表示乐意留在当前节点,负数表示不乐意留在当前节点。
当某个高可用集群即包含资源粘性又包含位置约束,一旦该节点发生故障后,资源就会转移到另一个节点上去。但是当之前的节点恢复正常时,需要比较所有的资源粘性之和与所有位置约束之和谁大谁小,这样资源才会留在大的一方。
资源转移
将有故障节点的VIP设置到另一个节点上去,并在另一个节点启用相应的服务,挂载相应的存储设备等等都可以叫做资源转移。
9、资源代理(Resource Agent)
RA实际负责启动资源的,LRM用来管理本地资源的,但是不能启动资源,当需要启动资源时会调用RA来启动,RA是一个脚本文件,在一个节点上可能有多个RA。通常在rhel上,启动系统服务的不也都是一些脚本文件吗。常见的RA有如下风格:
(1)、LSB(Linux Standard Base),这是一种我们常见的如/etc/init.d/下的标准linux脚本风格。
(2)、OCF(Open Cluster Framwork):OCF脚本是比LSB更强大的一种脚本,支持更多的参数
一般说来,构建一个高可用集群服务需要以上组件才能完成。
linux高可用集群(HA)原理详解(转载)的更多相关文章
- linux高可用集群(HA)原理详解
高可用集群 一.什么是高可用集群 高可用集群就是当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服 ...
- 高可用集群(HA)之DRBD原理和基础配置
目录 1.工作原理图 2.用户空间工具 3.工作模式 4.实现主备故障自动切换 5.所需软件 6.配置文件 7.详细配置 1.配置通用属性信息 2.定义一个资源 3.初始化资源 ...
- 高可用集群(HA)之Keeplived原理+配置过程
原理--> 通过vrrp协议,定义虚拟路由,在多个服务节点上进行转移. 通过节点优先级,将初始虚拟路由到优先级高的节点上,checker工作进程检测到主节点出问题时,则降低此节点优先级,从而实现 ...
- 使用 Load Balancer,Corosync,Pacemaker 搭建 Linux 高可用集群
由于网络架构的原因,在一般虚拟机或物理环境中常见的用 VIP 来实现双机高可用方案,无法照搬到 Azure 平台.但利用 Azure 平台提供的负载均衡或者内部负载均衡功能,可以达到类似的效果. 本文 ...
- Sqlserver on linux 高可用集群搭建
一.环境准备 1 部署环境: 服务器数量:3台 Ip地址:192.168.1.191(主) 192.168.1.192(从) 192.168.1.193(从) 操作系统:CentOS Linux re ...
- 使用Keepalived实现linux高可用集群
安装 apt install libipset-dev keepalived -y 创建账户 useradd -s/usr/sbin/nologin -M -g root keepalived_scr ...
- Hadoop集群的JobHistoryServer详解(转载)
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map.用了多少个Reduce.作业提交时间.作业启动时间.作业完成时间等信息.默认情况下 ...
- k8s 开船记:升级为豪华邮轮(高可用集群)与遇到奇怪故障(dns解析异常)
之前我们搭建的 k8s 集群只用了1台 master ,可用性不高,这两天开始搭建高可用集群,但由于之前用 kubeadm 命令创建集群时没有使用 --control-plane-endpoint 参 ...
- 全是干货---Linux 高可用(HA)集群基本概念详解
http://www.linuxidc.com/Linux/2013-08/88522.htm 高可用集群的衡量标准 HA(High Available), 高可用性群集是通过系统的可靠性(re ...
随机推荐
- vim 操作
vim -b test.bin vim 的 -b 选项是告诉 vim 打开的是一个二进制文件,不指定的话,会在后面加上 0x0a ,即一个换行符,这样若是二进制文件,则文件被改变了,后面多了一个0x0 ...
- Java集合框架之LinkedList-----用LinkedList模拟队列和堆栈
LinkedList的特有方法: (一)添加方法 addFisrt(E e):将指定元素插入此列表的开头.//参数e可以理解成Object对象,因为列表可以接收任何类型的对象,所以e就是Object对 ...
- POJ1179Polygon(DP)
Polygon Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 4456 Accepted: 1856 Descripti ...
- Hash Table构建
get-item e:\test\* |format-table @{name="aa";expression={$_.name.tostring().split(".& ...
- Codeforces Round #192 (Div. 1) B. Biridian Forest 暴力bfs
B. Biridian Forest Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/329/pr ...
- thinkphp中的HTTP类实现下载
public function test(){ import('ORG.Net.Http'); $filename="Uploads/v1.2.doc"; //exit($file ...
- Cocos2d-x学习笔记(10)(CCMenu菜单)
1.CCMenu创建方式 CCMenu* menu = CCMenu::create(cocos2d::CCMenuItem* item,--)參数为CCMenuItem菜单项的对象可变參数列表 2. ...
- Linux下进程的同步相互排斥实例——生产者消费者
linux下的同步和相互排斥 Linux sync_mutex 看的更舒服点的版本号= = https://github.com/Svtter/MyBlog/blob/master/Linux/pth ...
- 搭建Nginx图片服务器
搭建Nginx图片服务器 Part-I 安装Nginx 安装PCRE 下载 ngx_cache_purge 并解压,用来清除缓存 下载Nginx并解压 cd nginx-1.7.7 编译,--pref ...
- iOS开发——网络编程Swift篇&(三)同步Get方式
同步Get方式 // MARK: - 同步Get方式 func synchronousGet() { //创建NSURL对象 var url:NSURL! = NSURL(string: " ...