Java并发容器,底层原理深入分析
ConcurrentHashMap
ConcurrentHashMap底层具体实现
JDK 1.7底层实现
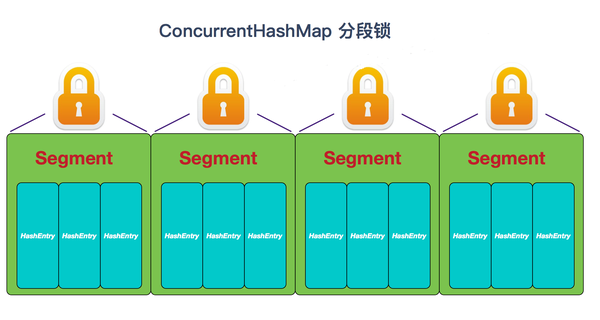
将数据分为一段一段的存储,然后给每一段数据配一把锁, 当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。 其中Segment 实现了 ReentrantLock,所以Segment是一种可重入锁,扮演锁的角色。 HashEntry 用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组。 Segment结构和HashMap类似,是一种数组和链表结构, 一个Segment包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得对应的Segment的锁。
JDK 1.8底层实现
TreeBin: 红黑二叉树节点 Node: 链表节点
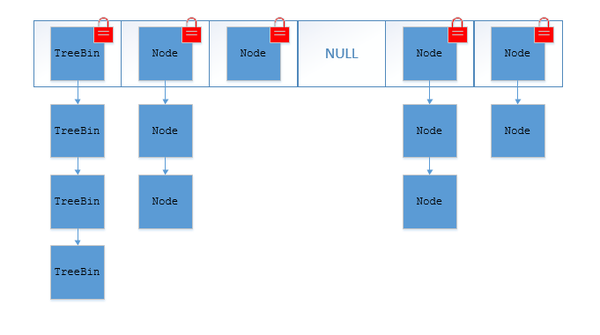
ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。 数据结构与HashMap1.8的结构类似,数组+链表/红黑二叉树(链表长度>8时,转换为红黑树)。
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash值不冲突,就不会产生并发。
ConcurrentHashMap和Hashtable的区别
底层数据结构:
JDK1.7 的ConcurrentHashMap底层采用分段的数组+链表实现, JDK1.8 的ConcurrentHashMap底层采用的数据结构与JDK1.8 的HashMap的结构一样,数组+链表/红黑二叉树。
Hashtable和JDK1.8 之前的HashMap的底层数据结构类似都是采用数组+链表的形式, 数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
实现线程安全的方式
JDK1.7的ConcurrentHashMap(分段锁)对整个桶数组进行了分割分段(Segment), 每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 JDK 1.8 采用数组+链表/红黑二叉树的数据结构来实现,并发控制使用synchronized和CAS来操作。
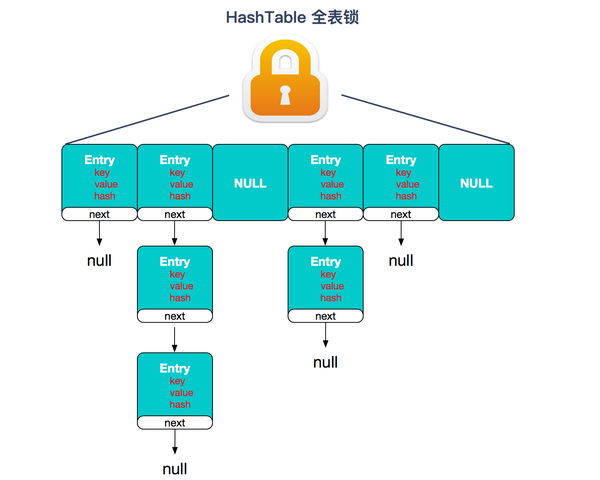
Hashtable:使用 synchronized 来保证线程安全,效率非常低下。 当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态, 如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈。
HashTable全表锁
ConcurrentHashMap分段锁
CopyOnWriteArrayList
public class CopyOnWriteArrayList<E> extends Object
implements List<E>, RandomAccess, Cloneable, Serializable在很多应用场景中,读操作可能会远远大于写操作。 由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。 我们应该允许多个线程同时访问List的内部数据,毕竟读取操作是安全的。 这和ReentrantReadWriteLock读写锁的思想非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。 JDK中提供了CopyOnWriteArrayList类比相比于在读写锁的思想又更进一步。 为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,并且写入也不会阻塞读取操作。 只有写入和写入之间需要进行同步等待。这样,读操作的性能就会大幅度提高。
CopyOnWriteArrayList的实现机制
CopyOnWriteArrayLis 类的所有可变操作(add,set等等)都是通过创建底层数组的新副本来实现的。 当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。 写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。
CopyOnWriteArrayList是满足CopyOnWrite的ArrayList, 所谓CopyOnWrite也就是说: 在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作, 而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存, 原来的内存就可以被回收掉了。
CopyOnWriteArrayList读取和写入源码简单分析
CopyOnWriteArrayList读取操作的实现
读取操作没有任何同步控制和锁操作, 因为内部数组array不会发生修改,只会被另外一个array替换,因此可以保证数据安全。
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
public E get(int index) {
return get(getArray(), index);
}
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
final Object[] getArray() {
return array;
}
CopyOnWriteArrayList读取操作的实现
CopyOnWriteArrayList 写入操作 add() 方法在添加集合的时候加了锁, 保证同步,避免了多线程写的时候会复制出多个副本出来。
/**
* Appends the specified element to the end of this list.
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();//释放锁
}
}
ConcurrentLinkedQueue
Java提供的线程安全的 Queue 可以分为阻塞队列和非阻塞队列,其中阻塞队列的典型例子是 BlockingQueue, 非阻塞队列的典型例子是ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 阻塞队列可以通过加锁来实现,非阻塞队列可以通过CAS操作实现。
ConcurrentLinkedQueue使用链表作为其数据结构。 ConcurrentLinkedQueue应该算是在高并发环境中性能最好的队列了。 它之所有能有很好的性能,是因为其内部复杂的实现。
ConcurrentLinkedQueue 主要使用CAS非阻塞算法来实现线程安全。 适合在对性能要求相对较高,对个线程同时对队列进行读写的场景, 即如果对队列加锁的成本较高则适合使用无锁的ConcurrentLinkedQueue来替代。
BlockingQueue
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
FIFO 队列 :LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
优先级队列 :PriorityBlockingQueue
提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容; 如果队列为满 put() 将阻塞,直到队列有空闲位置。
使用 BlockingQueue 实现生产者消费者问题
public class ProducerConsumer {
private static BlockingQueue<String> queue = new ArrayBlockingQueue<>(5);
private static class Producer extends Thread {
@Override
public void run() {
try {
queue.put("product");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print("produce..");
}
}
private static class Consumer extends Thread {
@Override
public void run() {
try {
String product = queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print("consume..");
}
}
}
public static void main(String[] args) {
for (int i = 0; i < 2; i++) {
Producer producer = new Producer();
producer.start();
}
for (int i = 0; i < 5; i++) {
Consumer consumer = new Consumer();
consumer.start();
}
for (int i = 0; i < 3; i++) {
Producer producer = new Producer();
producer.start();
}
}
produce..produce..consume..consume..produce..consume..produce..consume..produce..consume..
免费Java高级资料需要自己领取,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并发分布式等教程,一共30G。 传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
Java并发容器,底层原理深入分析的更多相关文章
- Java并发编程原理与实战三十四:并发容器CopyOnWriteArrayList原理与使用
1.ArrayList的实现原理是怎样的呢? ------>例如:ArrayList本质是实现了一个可变长度的数组. 假如这个数组的长度为10,调用add方法的时候,下标会移动到下一位,当移动到 ...
- 理解java容器底层原理--手动实现HashMap
HashMap结构 HashMap的底层是数组+链表,百度百科找了张图: 先写个链表节点的类 package com.xzlf.collection2; public class Node { int ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
- Java 并发系列之六:java 并发容器(4个)
1. ConcurrentHashMap 2. ConcurrentLinkedQueue 3. ConcurrentSkipListMap 4. ConcurrentSkipListSet 5. t ...
- 《Java并发编程的艺术》第6/7/8章 Java并发容器与框架/13个原子操作/并发工具类
第6章 Java并发容器和框架 6.1 ConcurrentHashMap(线程安全的HashMap.锁分段技术) 6.1.1 为什么要使用ConcurrentHashMap 在并发编程中使用Has ...
- Java并发-volatile的原理及用法
Java并发-volatile的原理及用法 volatile属性:可见性.保证有序性.不保证原子性.一.volatile可见性 在Java的内存中所有的变量都存在主内存中,每个线程有单独CPU缓存内存 ...
- java 并发容器一之BoundedConcurrentHashMap(基于JDK1.8)
最近开始学习java并发容器,以补充自己在并发方面的知识,从源码上进行.如有不正确之处,还请各位大神批评指正. 前言: 本人个人理解,看一个类的源码要先从构造器入手,然后再看方法.下面看Bounded ...
- Java并发——volatile的原理
111 Java并发——volatile的原理
- Java 并发机制底层实现 —— volatile 原理、synchronize 锁优化机制
本书部分摘自<Java 并发编程的艺术> 概述 相信大家都很熟悉如何使用 Java 编写处理并发的代码,也知道 Java 代码在编译后变成 Class 字节码,字节码被类加载器加载到 JV ...
- Java并发编程底层实现原理 - volatile
Java语言规范第三版中对volatile的定义如下: Java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致性的更新,线程应该确保通过排他锁 单独获得这个变量. volatile有时候 ...
随机推荐
- SQL语句小练习
一.创建如下表结构(t_book) Id 主键 自增一 bookName 可变长 20 Price 小数 Author 可变长20 bookTypeId 图书类 ...
- MySQL练习50题
介绍一个学习SQL的网站:https://sqlbolt.com/ 习题来源于网络,SQL语句是自己的练习答案,部分参考了网络上的答案. 花了一晚上的时间做完,个人认为其中的难点有:分组提取前几名的数 ...
- LeetCode(173) Binary Search Tree Iterator
题目 Implement an iterator over a binary search tree (BST). Your iterator will be initialized with the ...
- Power Calculus UVA - 1374 迭代加深搜索
迭代加深搜索经典题目,好久不做迭代加深搜索题目,拿来复习了,我们直接对当前深度进行搜索,注意剪枝,还有数组要适当开大,因为2^maxd可能很大 题目:题目链接 AC代码: #include <i ...
- Linux学习-系统基本设定
网络设定 (手动设定与 DHCP 自动取得) 网络其实是又可爱又麻烦的玩意儿,如果你是网络管理员,那么你必须要了解局域网络内的 IP, gateway, netmask 等参数,如果还想要连上 Int ...
- 【报错】invalid or unexpected token
结果发现是把英文的,写成了中文字符,系统没法识别.
- HDU 4871 Shortest-path tree 最短路 + 树分治
题意: 输入一个带权的无向连通图 定义以顶点\(u\)为根的最短路生成树为: 树上任何点\(v\)到\(u\)的距离都是原图最短的,如果有多条最短路,取字典序最小的那条. 然后询问生成树上恰好包含\( ...
- TCP缓冲区大小及限制
这个问题在前面有的部分已经涉及,这里在重新总结下.主要参考UNIX网络编程. (1)数据报大小IPv4的数据报最大大小是65535字节,包括IPv4首部.因为首部中说明大小的字段为16位.IPv6的数 ...
- 2019年北航OO第四次博客总结<完结撒花>
一.UML单元架构设计 1. 类图解析器架构设计 1.1 UML类图 这次作业的目标是要解析一个UML类图,首先为了解耦,我新建了一个类UmTree进行解析工作,而Interaction类仅仅作为实现 ...
- IOS开发之----全局变量extern的使用
extern,作用在IOS中,为了使用全局变量.比写在appDelegate和定义单例方便一些: 举例: 1.MyExternClass.h添加这个类,并在.m文件添加 代码 #import &quo ...