大数据学习——Storm集群搭建
安装storm之前要安装zookeeper
一.安装storm步骤
1.下载安装包

2.解压安装包
tar -zxvf apache-storm-0.9..tar.gz mv apache-storm-0.9. storm
3.修改配置文件
mv /root/apps/storm/conf/storm.yaml /root/apps/storm/conf/storm.yaml.bak vi /root/apps/storm/conf/storm.yaml
修改环境变量/etc/profile
export STORM_HOME=/root/apps/storm
export PATH=${STORM_HOME}/bin:$PATH
#指定storm使用的zk集群
storm.zookeeper.servers:
- "mini1"
- "mini2"
- "mini3"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "mini1"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx1024m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx768m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4.分发安装包
scp -r $PWD mini2:$PWD
scp -r $PWD mini3:$PWD
5.启动集群
storm的集群中的是三个角色
nimbus 主节点,管理节点
supervisor每个机器上的管理者
ui界面
mini1的/root/apps/storm/bin目录下
./storm nimbus
./storm supervisor
./storm ui mini2的/root/apps/storm/bin目录下
./storm supervisor mini3的/root/apps/storm/bin目录下
./storm supervisor
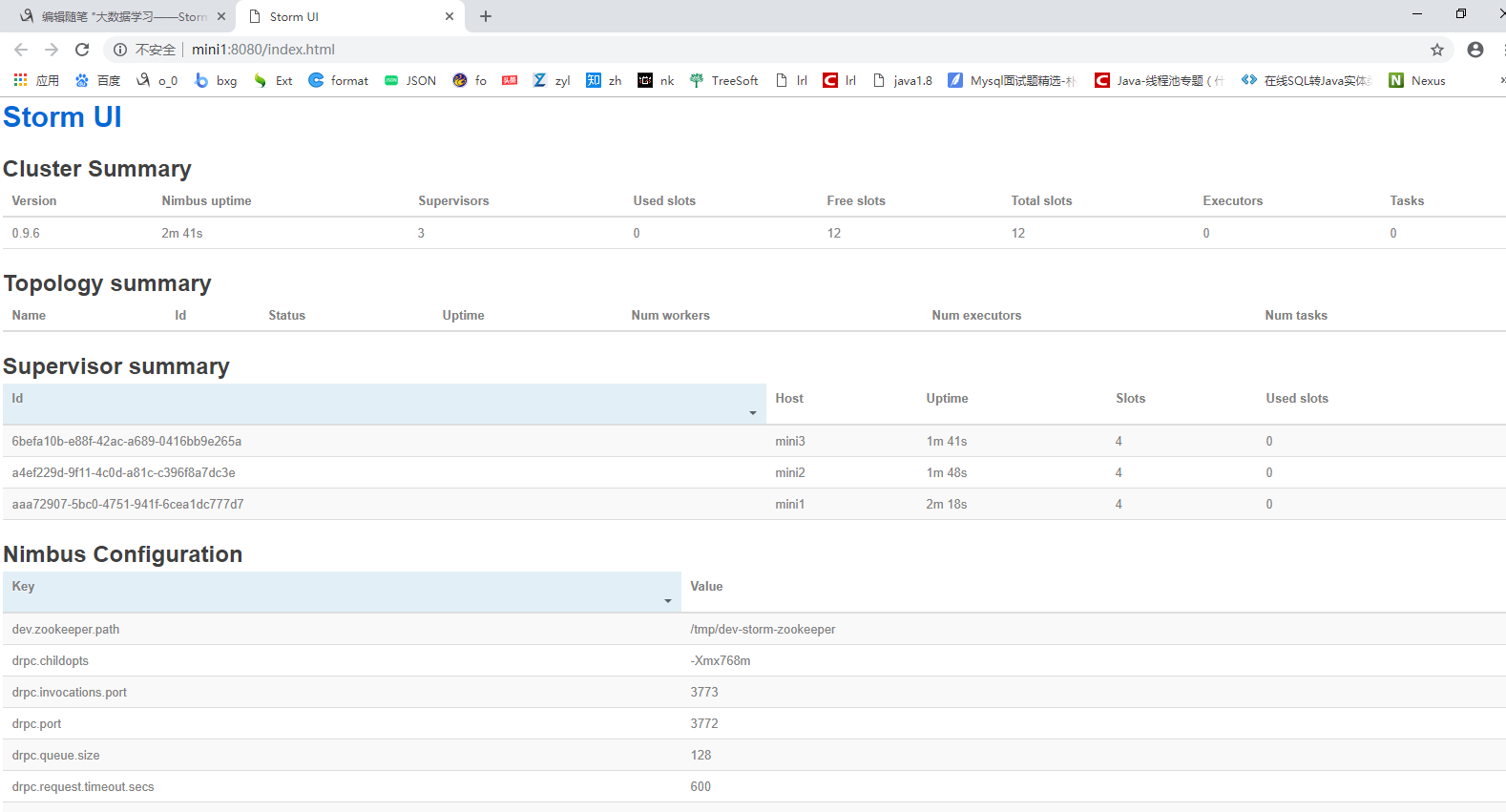
6.查看集群
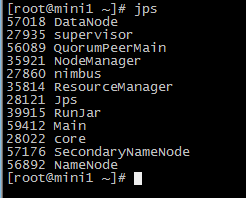
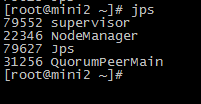
http://mini1:8080/index.html
大数据学习——Storm集群搭建的更多相关文章
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Kafka集群部署
1下载安装包 2解压安装包 -0.9.0.1.tgz -0.9.0.1 kafka 3修改配置文件 cp server.properties server.properties.bak # Lice ...
- 大数据学习——hdfs集群启动
第一种方式: 1 格式化namecode(是对namecode进行格式化) hdfs namenode -format(或者是hadoop namenode -format) 进入 cd /root/ ...
随机推荐
- 我的NopCommerce之旅(8): 路由分析
一.导图和基础介绍 本文主要介绍NopCommerce的路由机制,网上有一篇不错的文章,有兴趣的可以看看NopCommerce源码架构详解--对seo友好Url的路由机制实现源码分析 SEO,Sear ...
- 前端之css(宽高)设置小技巧
一.css宽高自适应: 1.宽度自适应: 元素宽度设为100%(块状元素的默认宽度为100%) 注:应用在通栏效果中 2.高度自适应: height:auto;或者不设置高度 3.最小,最大高度,最小 ...
- Scrapy框架的基本组成及功能使用
1.什么是scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.框架的本质就是集成各种功能.具有很强通用性的项目模板. 2.安装 Linux: pip3 in ...
- Cuda入门笔记
最近在学cuda ,找了好久入门的教程,感觉入门这个教程比较好,网上买的书基本都是在掌握基础后才能看懂,所以在这里记录一下.百度文库下载,所以不知道原作者是谁,向其致敬! 文章目录 1. CUDA是什 ...
- SVN的两种存储方式FSFS和BDB比较【转】
版本库数据存储 在Subversion1.2中,版本库中存储数据有两种方式.一种是在Berkeley DB数据库中存储数据:另一种是使用普通的文件,使用自定义格式.因为Subversion的开发者称版 ...
- Azure 项目构建 – 构建直播教学系统之媒体服务篇
本课程主要介绍如何在 Azure 平台上快速构建和部署基于 Azure 媒体服务的点播和直播教学系统, 实践讲解如何使用 Azure 门户创建媒体服务, 配置视频流进行传输,连接 CDN 加速等. 具 ...
- COGS 2084. Asm.Def的基本算法
★☆ 输入文件:asm_algo.in 输出文件:asm_algo.out 简单对比时间限制:1 s 内存限制:256 MB [题目描述] “有句美国俗语说,如果走起来像鸭子,叫起来像 ...
- (二)SpringMVC之执行的过程
(DispatcherServlet在Spring当中充当一个前端控制器的角色,它的核心功能是分发请求.请求会被分发给对应处理的Java类,Spring MVC中称为Handle.) ① 用户把请 ...
- Vue v-if与v-show的区别
用了 viewjs 预览图片的时候 发现 用着两个 还是有区别的, 相同点==== v-if与v-show都可以动态控制dom元素显示隐藏 不同点 = ====v-if显示隐藏是将dom元素整个添加 ...
- oracle数据比对工具
上半年的工作重心主要是机房搬迁,免不了要经常的数据比对,保证主备库数据一致,为了节约工作时间,提高工作效率,开发了这个数据比对小工具.用起来还可以.有需要的QQ私聊(1603039990),方便大家, ...