PCANet: A Simple Deep Learning Baseline for Image Classification?----中文翻译
一 摘要
在本文中,我们提出了一个非常简单的图像分类深度学习框架,它主要依赖几个基本的数据处理方法:1)级联主成分分析(PCA);2)二值化哈希编码;3)分块直方图。在所提出的框架中,首先通过PCA方法学习多层滤波器核,然后使用二值化哈希编码以及分块直方图特征来进行下采样和编码。因此,该框架称为PCANet,并且很容易设计与学习。为了进行比较并且更好的理解,我们还介绍和研究了PCANet的两个类似的框架:RandNet和LDANet。它们与PCANet有相同的拓扑结构,但RandNet的滤波器核采用随机初始化的方式,LDANet的滤波器核通过线性判别分析来学习得到。针对不同的任务,我们已经使用多种基准视觉数据集测试了这些框架,包括用于人脸认证的LFW,用于人脸识别的FERET数据集(由耶鲁的B,AR扩展),用于手写数字识别的MNIST数据集。令人惊讶的的是,对于所有的任务而言,这种看似简单的PCANet模型与复杂的手选特征识别或通过深度神经网络(DNN)精心学习的最先进的功能相比,都存在一些优势。更令人惊讶的是,该模型在MNIST数据集和由耶鲁的B,AR扩展的FERET数据集上的许多分类任务达到了新的高度。对其他公共数据集的实验也表明PCANet作为纹理分类和对象识别简单但有高度竞争力基线的潜力。
关键词:卷积神经网络,深度学习,PCANet,RandNet,LDANet,人脸识别,手写数字识别,对象分类。
二 引言
基于视觉语义的图像分类是一项非常具有挑战性的任务,很大程度上是因为不同的光照条件,不匹配不对齐,形变因素,遮挡因素,通常会在每一类图像内部产生大量的可变性。我们已经进行了许多努力来抵消可变性,如通过手动设计用于分类任务的低级特征。代表性的例子是用于纹理和面部分类的Gabor features和LBP以及用于对象识别的SIFT和HOG features。。虽然这些手选的底层特征能够很好的应对特定情况下的数据处理任务,但是这些特征的泛化能力有限,对待新问题往往需要构建新的特征。
从数据中学习得到感兴趣的特征被认为是克服手选特征局限性的一个好的方法,最典型的一个例子就是通过深度神经网路来进行特征学习,这种网络最近引起了人们的极大关注。深度学习的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。目前深度学习中一个关键的、相对成功的框架是卷积网络框架。一个深度卷积网络结构包含多层训练结构以及有监督的分类器,每一层都包含三个子层,分别为卷积层、非线性处理层以及下采样层。
为了在卷积网络结构中每层结构学习滤波器核,已经提出了各种各样的技术,比如:RBM和正则化自动编码以及其变体对于这种卷积网络结构一般都通过随机梯度下降法对其进行训练。然而要想学习得到一个优质的卷及网络分类结构,需要有各种各样的调参经验和技巧。
尽管针对不同的视觉识别任务,人们提出了许多各种各样的卷积神经网络结构,并取得了显著效果。但可以说,有明确的数学证明的第一个例子是小波散射模型(ScatNet)。其通过将卷积核改为小波核来避免算法学习的步骤。然而就是这一简单改动,使其居然能够在手写数字识别和文本识别等方面超过相同层次的卷积网络和深度神经网络,不过它在人脸识别方面表现不佳,难以应对光照变化和遮挡影响。
A 动机和目的
我们最开始的研究目标是试图针对卷积模型和小波散射模型之前的差异性来提出解决方案,我们希望达到两个目标:首先我们希望我们所设计的深度学习模型结构简单,能够在不同的数据和场景任务下进行训练和分类;其次,希望能为深度学习的深入研究和应用提供一个基本的参考标准。
为了达到以上目标,我们使用最基本的PCA滤波器作为卷积层滤波器,在非线性层使用二值化哈希编码处理,在重采样层使用分块扩展直方图并辅以二值哈希编码,将重采样层的输出作为整个PCANet网络最终的特征提取结果,考虑到以上的因素,我们将这种简洁的深度学习结构命名为PCANet。图一展示了一个2阶PCANet特征提取流程:
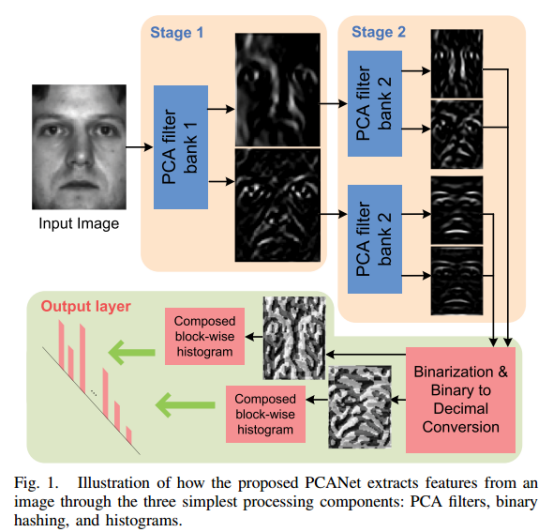
PCANet的重要特点就在于其结构的简单性,例如每层只进行PCA映射,只在最后一层的输出层进行二值化哈希编码和直方图的分块处理,这种简单性似乎对已有的传统深度学习模型(例如卷积网络结构以及小波分散式网络结构)构成挑战。然而通过大量实验证明,大道至简的深度模型在不同类型的数据库上表现还都令人满意。
一个与PCANet十分相近的网络结构当属于二阶导向型PCA(OPCA),这种结构最早应用于音频处理过程。二者之间显著的不同点事OPCA没有连接哈希编码和局部块直方图处理过程,对于附加了噪声的协方差矩阵,OPCA有着额外的噪声及形变鲁棒性,当然PCANet也吸收了OPCA这一优点,对噪声有着较好的鲁棒性。最后我们会对PCANet进行一些扩展研究,包括通过线性判别分析来训练卷积核(LDANet)、通过随机初始化的方法来出事PCANet的卷积核(RandNet)。在文章中我们会通过大量对比实验来对比PCANet与现有的深度学习模型(卷积网路模型、小波分散卷积模型等)的性能,希望通过实验能使大家对PCANet有一个更好的理解。
B 所做的工作
虽然我们初始的目的是通过构建一个简单的深度模型框架来为大家提供一个横向深度学习模型性能的基本标准,但是通过各种各样的实验我们惊奇的发现:这个基本的PCANet框架,在一些主流的数据库上所表现出的优越性能,例如人脸识别、手写字体分类、文本分类等等,已经能和当下相对成熟的深度学习模型相匹敌。以单样本人脸识别为例,在Yale B数据库上达到了99.58%正确率,在AR数据库的光照子集上达到了95%的识别率,在FERET数据库上达到97.25%正确率,在其DUP-1和DUP-2两个子集上分别达到95.84%和94.02%的正确率。在LFW数据库上,该模型在无监督人脸认证测试过程中达到86.28%的正确率。在MNIST数据库上该模型同样表现出色。通过实验,我们能够充分证明PCANet能够学习得到适合分类的鲁棒特征。
PCANet模型中几乎没有包含任何新的深度学习方面的方法,我们目前所做的研究也是大部分都基于以前积累的经验。不过无论怎么说,这个如此简单的模型已经在深度学习和视觉图像识别方面展现出了巨大价值,这种情况给我们传递了两条重要信息:一方面PCANet能够充当一个简洁但又极具竞争力的深度模型判断标准;另一方面,PCANet之所以能够取得巨大成功,很大程度上得益于其分层级联的特征学习结构。更重要的是,由于CPANet在二值化哈希编码和直方图分块之后只进行一次线性映射,使其能够从数学分析判断的角度论证其有效性。这个模型有利于我们更深入的洞察深度结构的理论基础,而这正是当下大家急需努力的方向。
三 级联线性网络结构(PCANet)
A PCANet的网络结构
假定我们有N个训练图片样本,每个样本的尺寸为m*n,设置每层的滤波器尺寸为k1*k2,图2为一个典型的PCANet模型,图中只用PCA滤波器核需要从训练样本集中进行学习,我们会依据这个网络结构来详细的介绍图中各个部分的含义。
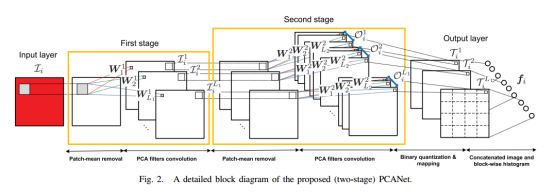
1) 第一层(PCA)
对于每个像素,我们都在其周围进行一次k1*k2的块采样(这里采样时逐个像素进行的,因此是完全的覆盖式采样),然后收集所有的采样块,进行级联,作为第i张图片的表示
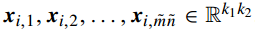
其中:
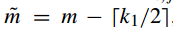
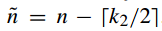
接下来需要对采样得到的块进行零均值化,具体如下:
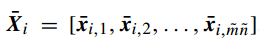
其中对于其中每一个元素做如下操作:
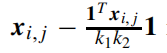
然后对训练集中的其他图片也做相同处理,最终得到处理后的训练样本矩阵:
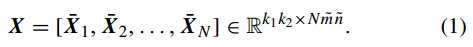
假定在第i层的滤波器数量为Li,PCA算法的目的就是通过寻找一系列的标准正交矩阵来最小化重构误差:
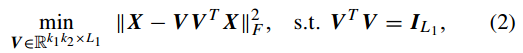
这个问题的求解就是经典的主成分分析,即矩阵X的协方差矩阵的前n个特征向量,因此对应的PCA滤波器表示如下:
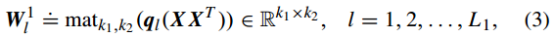
这个方程的含义就是提取X的协方差矩阵的前L1个最大特征值对应的特征向量来组成特征映射矩阵。这些主成分中保留了这些零均值的训练样本的主要信息。当然,与DNN和ScatNet相似,我们同样可以通过提高网络层数来提取更为抽象的特征。
2)第二层(PCA)
第二层的映射过程和第一层的映射机制基本相同,首先计算第一层的PCA映射输出:
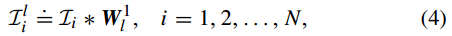
注意这里在计算卷积映射之前需要实现对样本进行边缘补零操作,以保证映射结果与原图像的尺寸相同(卷积操作会导致尺寸变小)。正如第一层中所做的分块操作,在第二层同样对输入矩阵(也就是第一层的映射输出)进行块采样、级联、零均值化:
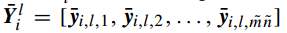
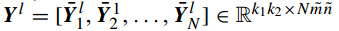
对每个输入矩阵都进行上述操作,最终得到第二层输入数据的块采样形式:

同理,第二层的PCA滤波器同样通过选取协方差矩阵对应的特征向量来组成:
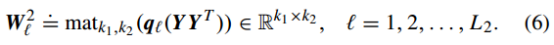
由于第一层具有L1个滤波器核,一次第一层会产生L1个输出矩阵,在第二层中针对第一层输出的每一个特征举证,对应都产生L2个特征输出。最终对于每一张样本,二阶PCANet都会产生L1*L2个输出的特征矩阵:
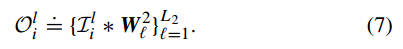
可见,第一层和第二层在结构上是十分相似的,因此很容易将PCANet扩展成包含更多层的深度网络结构。
3) 输出层(哈希编码和直方图处理)
我们对第二层的每个输出矩阵都进行二值处理,得到的结果中只包含整数和零,然后在对其进行二值化哈希编码,编码位数与第二层的滤波器个数相同:

这里的函数H()类似于一个单位阶跃函数。经过上述处理,每个像素值都被编码成为(0,255)之间的整数(在L2=8的情况下)。当然这里的编码值与权重并没联系,因为我们将每个编码值都视为一个独立的关键字。
对于第一层的每个输出矩阵,将其分为B块,计算统计每个块的直方图信息,然后在将各个块的直方图特征进行级联,最终得到块扩展直方图特征:
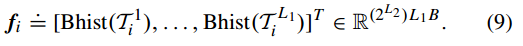
在进行直方图分块时同样可以采用重叠分块和非重叠分块模式,需要视情况而定。实验表明非重叠分块适用于人脸识别,重叠分块模式使用于手写数字识别、文本识别、目标识别等等。此外直方图特征还为PCANet提取到的特征添加了一些变换上的稳定性(例如尺度不变形)。
注:以上就是原文中对于PCANet的基本描述和原理介绍,剩下的有关PCANet性能分析、实验结果等内容就不再翻译,这部分内容直接参照原文中的数据即可。
参考:https://blog.csdn.net/u013088062/article/details/50039573
PCANet: A Simple Deep Learning Baseline for Image Classification?----中文翻译的更多相关文章
- PCANet: A Simple Deep Learning Baseline for Image Classification?--名词解释
1 上采样与下采样 缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的有两个: 使得图像符合显示区域的大小 生成对应图像的缩略图 下采样原理:对于一幅图像I尺 ...
- 高光谱图像分类简述+《Deep Learning for Hyperspectral Image Classification: An Overview》综述论文笔记
论文题目<Deep Learning for Hyperspectral Image Classification: An Overview> 论文作者:Shutao Li, Weiwei ...
- Comparison of SIFT Encoded and Deep Learning Features for the Classification and Detection of Esca Disease in Bordeaux Vineyards(分类MobileNet,目标检测 RetinaNet)
识别葡萄的一种虫害,比较了传统SIFT和深度学习分类,最后还做了目标检测 分类用的 MobileNet,目标检测 RetinaNet MobileNet 是将传统深度可分离卷积分成了两步,深度卷积和逐 ...
- 学习RaphaelJS矢量图形包--Learning Raphael JS Vector Graphics中文翻译(一)
(原文地址:http://www.cnblogs.com/idealer3d/p/LearningRaphaelJSVectorGraphics.html) 前面3篇博文里面,我们讲解了一本叫做< ...
- Review of Semantic Segmentation with Deep Learning
In this post, I review the literature on semantic segmentation. Most research on semantic segmentati ...
- Unsupervised Feature Learning and Deep Learning(UFLDL) Exercise 总结
7.27 暑假开始后,稍有时间,“搞完”金融项目,便开始跑跑 Deep Learning的程序 Hinton 在Nature上文章的代码 跑了3天 也没跑完 后来Debug 把batch 从200改到 ...
- (转) Awesome - Most Cited Deep Learning Papers
转自:https://github.com/terryum/awesome-deep-learning-papers Awesome - Most Cited Deep Learning Papers ...
- 如何选择分类器?LR、SVM、Ensemble、Deep learning
转自:https://www.quora.com/What-are-the-advantages-of-different-classification-algorithms There are a ...
- Applied Deep Learning Resources
Applied Deep Learning Resources A collection of research articles, blog posts, slides and code snipp ...
随机推荐
- mysql系列之1.mysql基础
非关系型(NOSQL)数据库 键值存储数据库: memcached / redis / memcachedb / Berkeley db 列存储数据库: Cassandra / Hba ...
- centos开放80端口
增加一条规则 #/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT 将更改进行保存 /etc/rc.d/init.d/iptables save 查 ...
- python网络爬虫之初识网络爬虫
第一次接触到python是一个很偶然的因素,由于经常在网上看连载小说,很多小说都是上几百的连载.因此想到能不能自己做一个工具自动下载这些小说,然后copy到电脑或者手机上,这样在没有网络或者网络信号不 ...
- linux卸载软件
rpm -q -a 查询当前系统安装的所有软件包 rpm -e 软件包名 参数e的作用是使rpm进入卸载模式,对名为某某某的软件报名进行卸载 rpm -e 软件包名 -nodeps 由于系统中各个软件 ...
- HTML5/CSS3淡入淡出滑块焦点图
在线演示 本地下载
- uboot 从sd卡加载文件并烧写到nand flash
uboot下可以从用tftp和nfs加载文件. 但是现在有个开发板配套uboot网络功能出现异常,执行ping命令就会导致开发板重启,只能选择先从sd卡加载文件 启动开发板,任意键进入uboot,然后 ...
- 程序连接Oracle数据库出现未找到提供程序.该程序可能未正确安装错误提示
好不容易使用plsql可以成功连上数据库了,应用程序连接数据库却出现了问题 其实解决这个问题也简单: 1. 查看oracle安装目录下的BIN目录,E:\app\Administrator\prod ...
- IIS反向代理实现Revel域名访问
Revel实现域名访问 1.在cmd中启动revel项目,我设置的端口为8000 2.下载IIS的Application Request Routing Cache组件下载地址 3.安装ARR 4.打 ...
- BZOJ3262 陌上花开 —— 三维偏序 CDQ分治
题目链接:https://vjudge.net/problem/HYSBZ-3262 3262: 陌上花开 Time Limit: 20 Sec Memory Limit: 256 MBSubmit ...
- BZOJ 3251 树上三角形:LCA【构成三角形的结论】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=3251 题意: 给你一棵树,n个节点,每个点的权值为w[i]. 接下来有m个形如(p,a,b ...