使用Google Colab训练神经网络(二)
Colaboratory 是一个 Google 研究项目,旨在帮助传播机器学习培训和研究成果。它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。Colaboratory 笔记本存储在 Google 云端硬盘 (https://drive.google.com/) 中,并且可以共享,就如同您使用 Google 文档或表格一样。Colaboratory 可免费使用。本文介绍如何使用 Google CoLaboratory 训练神经网络。
工具链接:https://colab.research.google.com/
CoLaboratory
首先,访问 CoLaboratory 网站(http://g.co/colab)(国内可能需要tz),注册后接受使用该工具的邀请。确认邮件通常需要一天时间才能返回你的邮箱。CoLaboratory 允许使用谷歌虚拟机执行机器学习任务和构建模型,无需担心计算力的问题,而且它是免费的。
打开 CoLaboratory,会出现一个「Hello, Colaboratory」文件,包含一些基本示例。建议尝试一下。
使用 CoLaboratory 可以在 Jupyter Notebook 上写代码。写好后执行 (Shift + Enter),代码单元下方就会生成输出。
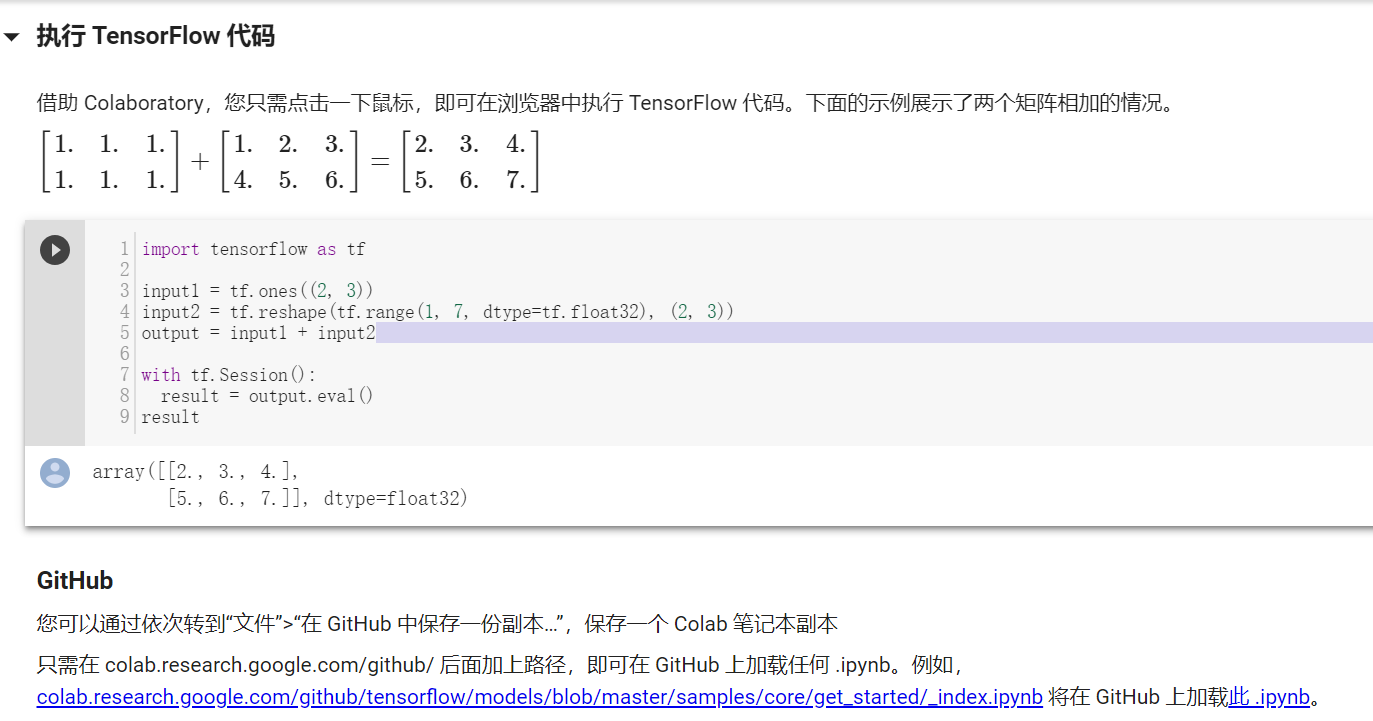
除了写代码,CoLaboratory 还有一些技巧(trick)。你可以在 notebook 中 shell 命令前加上「!」。如:!pip install -q keras。这样你就可以很大程度上控制正在使用的谷歌虚拟机。点击左上方(菜单栏下)的黑色按钮就可以找到它们的代码片段。
本文旨在展示如何使用 CoLaboratory 训练神经网络。我们将展示一个在威斯康星乳腺癌数据集上训练神经网络的示例,数据集可在 UCI Machine Learning Repository(http://archive.ics.uci.edu/ml/datasets)获取(具体的位置breast-cancer-wisconsin/wdbc.data)。本文的示例相对比较简单。
本文所用的 CoLaboratory notebook 链接:https://colab.research.google.com/notebook#fileId=1aQGl_sH4TVehK8PDBRspwI4pD16xIR0r
代码
问题:研究者获取乳房肿块的细针穿刺(FNA),然后生成数字图像。该数据集包含描述图像中细胞核特征的实例。每个实例包括诊断结果:M(恶性)或 B(良性)。我们的任务是在该数据上训练神经网络根据上述特征诊断乳腺癌。
1、下载数据
首先将数据集放置到该机器上,这样我们的 notebook 就可以访问它。你可以使用以下代码:
from google.colab import files
uploaded = files.upload()
结果:
wdbc.data(n/a) - 124103 bytes, last modified: 2019/3/5 - 100% done
Saving wdbc.data to wdbc.data
另存为breast_cancer.csv:
with open("breast_cancer.csv", 'w') as f:
f.write(uploaded[uploaded.keys()[0]])
用!ls查看结果如下:
breast_cancer.csv sample_data wdbc.data
2、数据预处理
现在数据已经在机器上了,我们使用 pandas 将其输入到项目中。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd #Importing dataset
dataset = pd.read_csv('breast_cancer.csv')
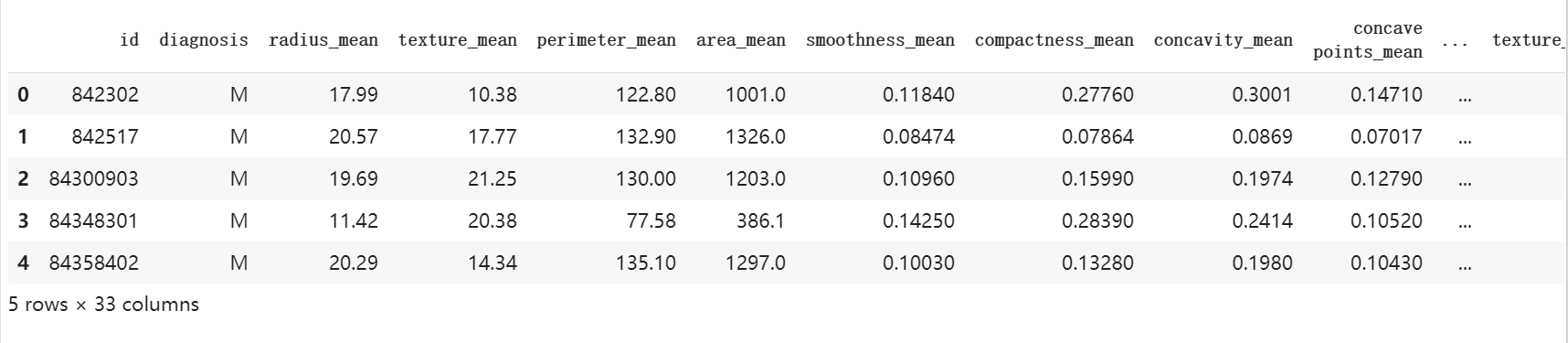
查看一下前五行:
dataset.head(5)
现在,分割因变量(Dependent Variables)和自变量(Independent Variables)。
#Seperating dependent and independent variables. X = dataset.iloc[:, 2:32].values #Note: Exclude Last column with all NaN values.
y = dataset.iloc[:, 1].values
Y 包含一列,其中的「M」和「B」分别代表「是」(恶性)和「否」(良性)。我们需要将其编码成数学形式,即「1」和「0」。可以使用 Label Encoder 类别完成该任务。
#Encoding Categorical Data
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder() y = labelencoder.fit_transform(y)
(如果数据类别多于两类,则使用 OneHotEncoder)
'''#OneHotEncoder
from sklearn.preprocessing import OneHotEncoder onehotencoder = OneHotEncoder()
y = onehotencoder.fit_transform(y).toarray()
y = y[:, 1:]'''
此时查看一下x和y:
X.shape
y.shape
结果:
(568, 30)
(568,)
现在数据已经准备好,我们将其分割成训练集和测试集。在 Scikit-Learn 中使用 train_test_split 可以轻松完成该工作。
#Splitting into Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
参数 test_size = 0.2 定义测试集比例。这里,我们将训练集设置为数据集的 80%,测试集占数据集的 20%。
3、搭建神经网络
3.1 Keras
Keras 是一种构建人工神经网络的高级 API。它使用 TensorFlow 或 Theano 后端执行内部运行。要安装 Keras,必须首先安装 TensorFlow。CoLaboratory 已经在虚拟机上安装了 TensorFlow。使用以下命令可以检查是否安装 TensorFlow:
!pip show tensorflow
你还可以使用!pip install tensorflow==1.2,安装特定版本的 TensorFlow。
另外,如果你更喜欢用 Theano 后端,可以阅读该文档:https://keras.io/backend/。
安装 Keras:
!pip install -q keras
3.2 然后导入Keras库和包
# Importing the Keras libraries and packages
import keras
from keras.models import Sequential
from keras.layers import Dense
使用 Sequential 和 Dense 类别指定神经网络的节点、连接和规格。如上所示,我们将使用这些自定义网络的参数并进行调整。
3.3 初始化神经网络
为了初始化神经网络,我们将创建一个 Sequential 类的对象。
# Initialising the ANN
classifier = Sequential()
3.4 设计神经网络
对于每个隐藏层,我们需要定义三个基本参数:units、kernel_initializer 和 activation。units 参数定义每层包含的神经元数量。Kernel_initializer 定义神经元在输入数据上运行时的初始权重(详见 https://faroit.github.io/keras-docs/1.2.2/initializations/)。activation 定义数据的激活函数。
- 输入层和第一个隐藏层:16 个具备统一初始权重的神经元,激活函数为 ReLU。此外,定义参数 input_dim = 30 作为输入层的规格。注意我们的数据集中有 30 个特征列。注:如何确定第一个隐藏层的节点数,对于初学者来说,一种简单方式是:x 和 y 的总和除以 2。如 (30+1)/2 = 15.5 ~ 16,因此,units = 16.
- 第二层:第二层和第一层一样,不过第二层没有 input_dim 参数.
- 由于我们的输出是 0 或 1,因此我们可以使用具备统一初始权重的单个单元。但是,这里我们使用 sigmoid 激活函数。
# Adding the input layer and the first hidden layer
classifier.add(Dense(units = 16, kernel_initializer = 'uniform', activation = 'relu', input_dim = 30)) # Adding the second hidden layer
classifier.add(Dense(units = 16, kernel_initializer = 'uniform', activation = 'relu')) # Adding the output layer
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
3.5 编译
# Compiling the ANN
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
3.6 拟合
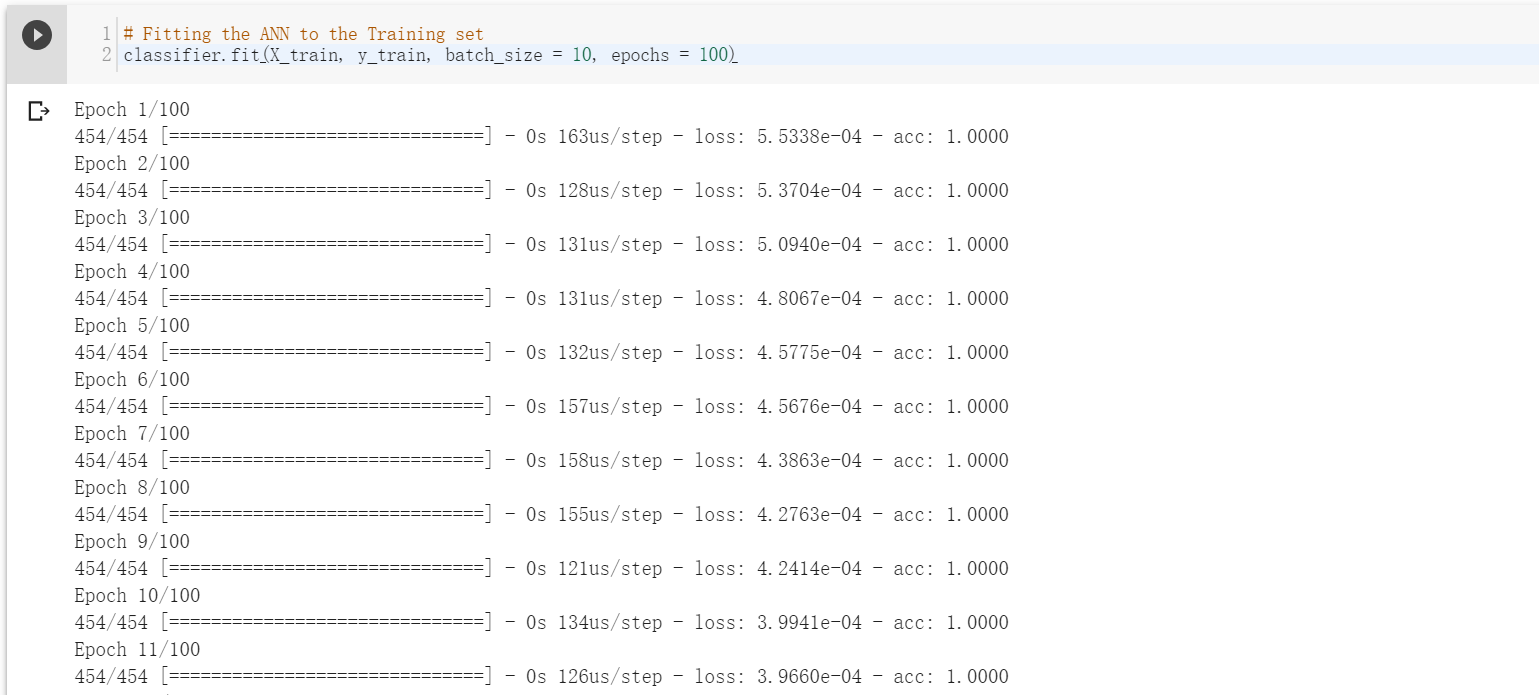
# Fitting the ANN to the Training set
classifier.fit(X_train, y_train, batch_size = 10, epochs = 100)
运行人工神经网络,发生反向传播。你将在 CoLaboratory 上看到所有处理过程,而不是在自己的电脑上。
这里 batch_size 是你希望同时处理的输入量。epoch 指数据通过神经网络一次的整个周期。它们在 Colaboratory Notebook 中显示如下:
3.7 进行预测,构建混淆矩阵
训练网络后,就可以在 X_test set 上进行预测,以检查模型在新数据上的性能。在代码单元中输入和执行 cm 查看结果。
# Predicting the Test set results
y_pred = classifier.predict(X_test)
y_pred = (y_pred > 0.5) # Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
混淆矩阵
混淆矩阵是模型做出的正确、错误预测的矩阵表征。该矩阵可供个人调查哪些预测和另一种预测混淆。这是一个 2×2 的混淆矩阵。
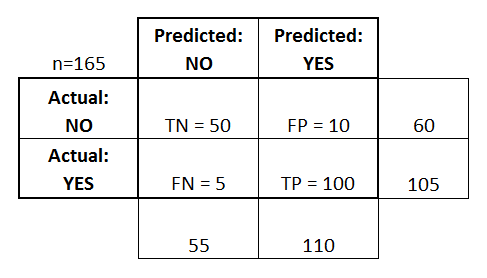
混淆矩阵如下所示[cm (Ctrl+Enter)]
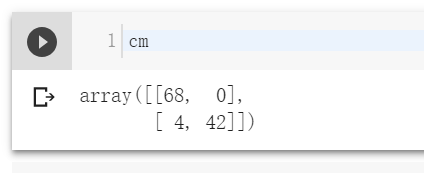
上图表示:68 个真负类、0 个假正类、4 个假负类、42 个真正类。很简单。该平方矩阵的大小随着分类类别的增加而增加。
这个示例中的准确率几乎达到 100%,只有 4 个错误预测。但是并不总是这样。有时你可能需要投入更多时间,研究模型的行为,提出更好、更复杂的解决方案。如果一个网络性能不够好,你需要调整超参数来改进模型。
参考链接:https://www.jiqizhixin.com/articles/2017-12-28-7
使用Google Colab训练神经网络(二)的更多相关文章
- 使用GOOGLE COLAB训练深度学习模型
使用 谷歌提供了免费的K80的GPU用于训练深度学习的模型.而且最赞的是以notebook的形式提供,完全可以做到开箱即用.你可以从Google driver处打开.或者这里 默认创建的是没有GPU的 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录10.13 - Google Colab连接 / 数据简单查看 / 模型训练
1. 比赛介绍 比赛地址:阿里云恶意程序检测新人赛 这个比赛和已结束的第三届阿里云安全算法挑战赛赛题类似,是一个开放的长期赛. 2. 前期准备 因为训练数据量比较大,本地CPU跑不起来,所以决定用Go ...
- Google Colab免费GPU使用教程(一)
一.前言 现在你可以开发Deep Learning Applications在Google Colaboratory,它自带免费的Tesla K80 GPU.重点是免费.免费!(国内可能需要tz) 这 ...
- stanford coursera 机器学习编程作业 exercise4--使用BP算法训练神经网络以识别阿拉伯数字(0-9)
在这篇文章中,会实现一个BP(backpropagation)算法,并将之应用到手写的阿拉伯数字(0-9)的自动识别上. 训练数据集(training set)如下:一共有5000个训练实例(trai ...
- 机器学习入门15 - 训练神经网络 (Training Neural Networks)
原文链接:https://developers.google.com/machine-learning/crash-course/training-neural-networks/ 反向传播算法是最常 ...
- Google Colab 免费GPU服务器使用教程
Google免费GPU使用教程(亲测可用) 今天突然看到一篇推文,里面讲解了如何薅资本主义羊毛,即如何免费使用Google免费提供的GPU使用权. 可以免费使用的方式就是通过Google Cola ...
- Google Colab——零成本玩转深度学习
前言 最近在学深度学习HyperLPR项目时,由于一直没有比较合适的设备训练深度学习的模型,所以在网上想找到提供模型训练,经过一段时间的搜索,最终发现了一个谷歌的产品--Google Colabora ...
- Google Colab 免费GPU服务器使用教程 挂载云端硬盘
一.前言二.Google Colab特征三.开始使用3.1在谷歌云盘上创建文件夹3.2创建Colaboratory3.3创建完成四.设置GPU运行五.运行.py文件5.1安装必要库5.2 挂载云端硬盘 ...
- Google Colab使用教程
简介Google Colaboratory是谷歌开放的云服务平台,提供免费的CPU.GPU和TPU服务器. 目前深度学习在图像和文本上的应用越来越多,不断有新的模型.新的算法获得更好的效果,然而,一方 ...
随机推荐
- ASP.NET Core MVC 2.x 全面教程_ASP.NET Core MVC 27. CICD Azure DevOps
VSTS做持续集成 后来改名叫做Azure Deveps https://azure.microsoft.com/zh-cn/services/devops/ 这是中文的地址 创建一个项目 名称.描述 ...
- 大将军UE分析
1.过关奖励,先播放特效,在显示奖励 2.鼠标移到人物身上装备,提示双击卸载 3.战场随机事件,出发开启增加buff 4.主线任务简单化,副本支线可玩性增强 5.乌泱泱几十个活动 6.升级的爽快感[升 ...
- 树莓派也跑Docker和.NET Core
树莓派是什么 树莓派就是一个卡片大小的迷你电脑. 安装系统 有了电脑,我们当然得先安装系统. 系统下载 https://www.raspberrypi.org/downloads/raspbian/ ...
- IOS11 - UINavigationItem大标题,搜索栏实现
1.新建模型 class Contact: NSObject { var name : String? var mobile : String?{ didSet{ { mobileString = m ...
- swift4.0 方法监听Selector写法总结
import UIKit class MainViewController: UITabBarController { //MARK:属性 懒加载 lazy var composeBtn = UIBu ...
- IT兄弟连 JavaWeb教程 JSTL标签的使用
假定甲方打算使用乙方开发的标签库,乙方把与标签库相关的所有文件打包成为了一个JAR文件(假定名为standard.jar),在这个JAR文件中包含以下内容: ● 标签处理类及相关的.class文件 ...
- 海思3559A QT 5.12移植(带webengine 和 opengl es)
海思SDK版本:Hi3559AV100_SDK_V2.0.1.0 编译器版本:aarch64-himix100-linux-gcc 6.3.0(这个版本有点小问题,使用前需要先清除本地化设置) $ e ...
- java面试基础问题
1.一个".java"源文件中是否可以包括多个类(不是内部类)?有什么限制? 可以有多个类,但只能有一个public的类,并且public的类名必须与文件名相一致. 2.Java有 ...
- DBUtils C3P0 阿里巴巴德鲁伊连接池工具的下载
- PostgreSQL-5-条件过滤
基本语法 SELECT column1, column2, columnN FROM table_name WHERE [search_condition] 操作符 =等于:<>不等于:! ...