Python机器学习--降维
主成分分析(PCA)



测试
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 31 14:21:51 2017 @author: Administrator
""" import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris data = load_iris()
y = data.target
X = data.data
pca = PCA(n_components=2)
reduced_X = pca.fit_transform(X) red_x, red_y = [], []
blue_x, blue_y = [], []
green_x, green_y = [], [] for i in range(len(reduced_X)):
if y[i] == 0:
red_x.append(reduced_X[i][0])
red_y.append(reduced_X[i][1])
elif y[i] == 1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
else:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1]) plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()
非负矩阵分解(NMF)
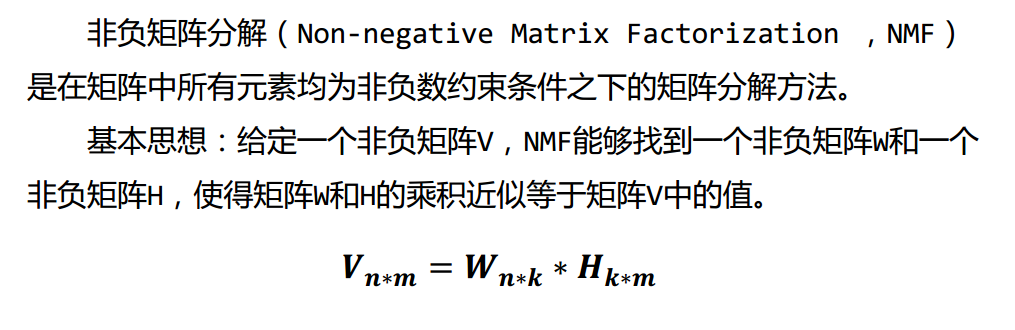

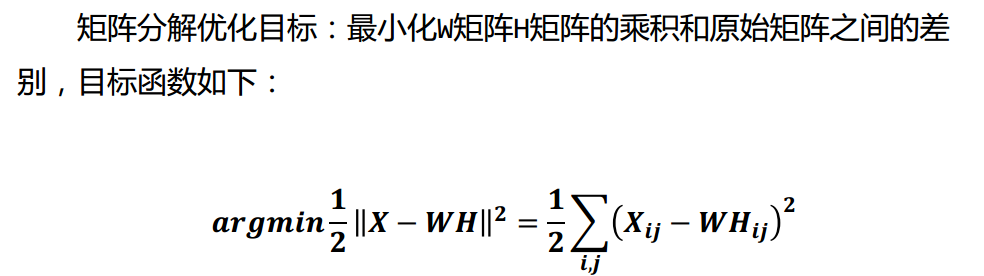



测试
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 31 14:24:26 2017 @author: Administrator
""" from numpy.random import RandomState
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_olivetti_faces
from sklearn import decomposition n_row, n_col = 2, 3
n_components = n_row * n_col
image_shape = (64, 64) ###############################################################################
# Load faces data
dataset = fetch_olivetti_faces(shuffle=True, random_state=RandomState(0))
faces = dataset.data ###############################################################################
def plot_gallery(title, images, n_col=n_col, n_row=n_row):
plt.figure(figsize=(2. * n_col, 2.26 * n_row))
plt.suptitle(title, size=16) for i, comp in enumerate(images):
plt.subplot(n_row, n_col, i + 1)
vmax = max(comp.max(), -comp.min()) plt.imshow(comp.reshape(image_shape), cmap=plt.cm.gray,
interpolation='nearest', vmin=-vmax, vmax=vmax)
plt.xticks(())
plt.yticks(())
plt.subplots_adjust(0.01, 0.05, 0.99, 0.94, 0.04, 0.) plot_gallery("First centered Olivetti faces", faces[:n_components])
############################################################################### estimators = [
('Eigenfaces - PCA using randomized SVD',
decomposition.PCA(n_components=6,whiten=True)), ('Non-negative components - NMF',
decomposition.NMF(n_components=6, init='nndsvda', tol=5e-3)) # 设置k=6
] ############################################################################### for name, estimator in estimators:
print("Extracting the top %d %s..." % (n_components, name))
print(faces.shape)
estimator.fit(faces)
components_ = estimator.components_
plot_gallery(name, components_[:n_components]) plt.show()
结果
Extracting the top 6 Eigenfaces - PCA using randomized SVD...
(400, 4096)
Extracting the top 6 Non-negative components - NMF...
(400, 4096)

Python机器学习--降维的更多相关文章
- Python机器学习:5.6 使用核PCA进行非线性映射
许多机器学习算法都有一个假设:输入数据要是线性可分的.感知机算法必须针对完全线性可分数据才能收敛.考虑到噪音,Adalien.逻辑斯蒂回归和SVM并不会要求数据完全线性可分. 但是现实生活中有大量的非 ...
- Python机器学习中文版
Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人工神经元一窥早期机器学习历史 使用Python实现感知机算法 基于Iri ...
- Python机器学习中文版目录
建议Ctrl+D保存到收藏夹,方便随时查看 人工智能(AI)学习资料库 Python机器学习简介 第一章 让计算机从数据中学习 将数据转化为知识 三类机器学习算法 第二章 训练机器学习分类算法 透过人 ...
- 只需十四步:从零开始掌握 Python 机器学习(附资源)
分享一篇来自机器之心的文章.关于机器学习的起步,讲的还是很清楚的.原文链接在:只需十四步:从零开始掌握Python机器学习(附资源) Python 可以说是现在最流行的机器学习语言,而且你也能在网上找 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- 七步精通Python机器学习--转载
作者简介: Matthew Mayo 翻译:王鹏宇 开始.这是最容易令人丧失斗志的两个字.迈出第一步通常最艰难.当可以选择的方向太多时,就更让人两腿发软了. 从哪里开始? 本文旨在通过七个步骤, ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- 只需十四步:从零开始掌握Python机器学习(附资源)
转载:只需十四步:从零开始掌握Python机器学习(附资源) Python 可以说是现在最流行的机器学习语言,而且你也能在网上找到大量的资源.你现在也在考虑从 Python 入门机器学习吗?本教程或许 ...
随机推荐
- Vuex 实际使用中的一点心得 —— 一刷新就没了
问题 在开发中,有一些全局数据,比如用户数据,系统数据等.这些数据很多组件中都会使用,我们当然可以每次使用的时候都去请求,但是出于程序员的"洁癖"."抠"等等优 ...
- CVS在update时状态status
cvs update -Ad 时,terminal 会display如下: P xx.v P xx.c ? xx.v ? xx.c A xx.v M xx.v U xx.v C xx.v 第一个字母: ...
- 9-Python基础知识-day1
Python基础知识-day1 Python 2 和Python 3 的区别: Python2 源码不标准,混乱,重复代码多:#-*-encoding:utf8 -*- 解决python2显示中文的问 ...
- Android兼容性测试GTS-环境搭建、测试执行、结果分析
GTS的全称是Google Mobile Services Test Suite,所谓的Google Mobile Services即谷歌移动服务,是谷歌开发并推动Android的动力,也是Andro ...
- idea导入jdk源码查看(xjl456852原创)
idea添加了jdk环境后,却无法查看jdk源码,只能通过idea自带的反编译查看,看起来有些不爽. 下面来说一下如何设置,导入jdk源码,查看时通过源码查看jdk. 1.点击菜单 File -> ...
- goland 快键键整理及注册
https://my.oschina.net/lemos/blog/1358731 http://idea.lanyus.com/
- 【03】const
[03]const 魔芋总结: 1,声明的是常量,一经声明,不得修改.必须声明的同时并赋值.否则报错. 2,只在声明所在的块级作用域内有效. 3,const命令声明的常量也是不提升,同样存在暂时性死区 ...
- android 之 GridView
GridView 的用法基本与ListView类似. 程序布局文件main.xml <?xml version="1.0" encoding="utf-8" ...
- STM32F407 ADC 个人笔记
1. ADC概述(STM32F4xx系列) 3 个 ADC 可分别独立使用 也可使用双重/三重模式(提高采样率) 2 个通道组 规则通道:相当于正常运行的程序 注入通道:相当于中断(可以打断规则通道的 ...
- 【LeetCode】Powerful Integers(强整数)
这道题是LeetCode里的第970道题. 题目描述: 给定两个正整数 x 和 y,如果某一整数等于 x^i + y^j,其中整数 i >= 0 且 j >= 0,那么我们认为该整数是一个 ...