RabbitMQ六:通过routingkey模拟日志
序言
本章文章进入深入了解RabbiMQ,平时项目中我们经常用到记录日志,常见的不外乎:Info、debug、warn、Error。
情境进入:先简单说一下我们需求,我们开发过程中会遇到很多日志记录,每种日志正常我们会放在不同时的文件夹(当然有的也可以合并,具体问题具体分析),现在我们就记录不同的日志,然后根据不同的类型,进行查找日志记录。
100个数内,实现1(Info) 、2(debug)、3(warn)、4(Error) 5(Info) 、6(debug)、7(warn)、8(Error)。。。。。。然后根据不同日志类型去查
备注:(如果有不太懂这几种类型的,我会在单独写一篇,对他们的简单了解,当然网上也有很多,但是我想写出自己的风格,个人如果写一篇,可能印象更深刻,以后不懂,回头看自己内容,秒懂呀,哈哈哈哈)
使用RabbitMq应该怎么设计? 可以分析一下
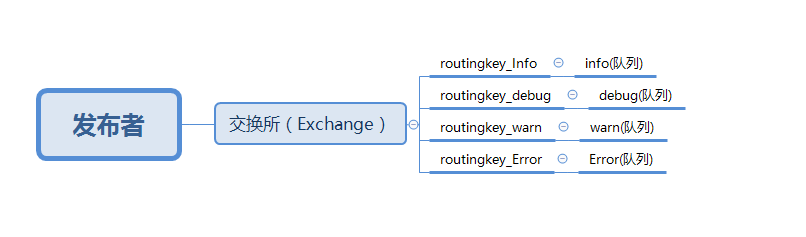
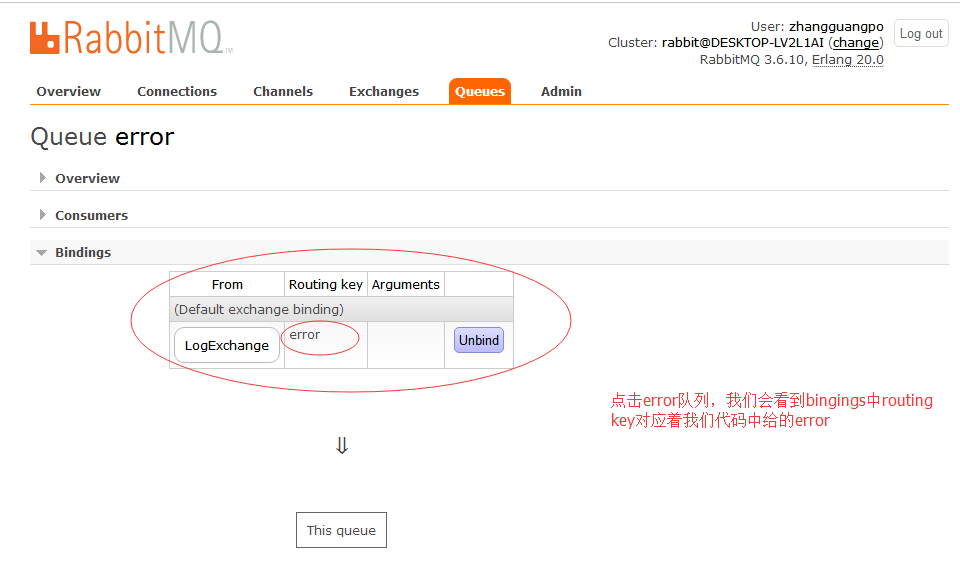
既然记录日志,那我们可以把所有日志放在一个交换机(Exchange),然后把不同的日志类型,当做每一种类型的队列, 首先我们需要一个exchange,在之前我们是在消息生产者中去声明exchange、queue以及它们的绑定关系,这显然 不严谨。 对于消息发布者而言它只负责把消息发布出去,甚至它也不知道消息是发到哪个queue(有没有类似大厨在厨房做饭,具体饭菜是哪一包间,大厨根本不问。。。), 消息通过exchange到达queue,exchange的职责非常简单,就是一边接收发布者的消息一边把这些消息推到queue中(有没有像传菜员,他只负责从大厨那获取菜,然后送给每个包间的客户。。。)。
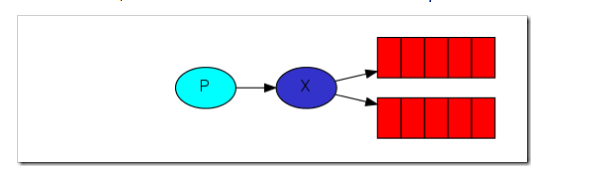
而exchange是怎么知道消息应该推到哪个queue呢,这就要通过绑定queue与exchange时的routingkey了,通过代码进行绑定并且指定routingkey,(好比传菜员是不是,需要电子菜单,准确的把菜送到包间。。。。。)
下面有一张关系图,p(发布者) ---> x(exchange) bindding(绑定关系也就是我们的routingkey) 红色代表着queue
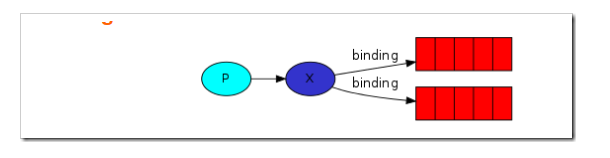
下面也算是我们编程的思路,如果你对前几篇文章稍微了解,想必,这一眼就能看出来,好了,废话少说,下面我就直接上干活。。。。。。。。。。
干货(代码)
发布者 代码
/// <summary>
/// 日志处理(routingKey实现日志处理)
/// </summary>
/// <param name="args"></param>
/// 需求简述: 100个数内,实现1(Info) 、2(debug)、3(warn)、4(Error) 5(Info) 、6(debug)、7(warn)、8(Error)。。。。。。然后根据不同日志类型去查
static void Main(string[] args)
{
//这里的代码我们就不多说了,看前面的博客
using (var channel = HelpConnection.GetConnection().CreateModel())
{
//声明交换机 direct模式:交换机名称,模式,持久耐用,自动删除,null
channel.ExchangeDeclare("LogExchange", "direct", true, false, null);
//先定义包含所有日志类型的数组
string[] logname = { "info", "debug", "warn", "error" };
// 创建队列和绑定关系
for (int i = ; i < logname.Length; i++)
{
channel.QueueDeclare(logname[i], true, false, false, null);
//进行绑定
channel.QueueBind(logname[i], "LogExchange", logname[i], null);
}
//参数定义
string msgBody = string.Empty;
int index = ;
string routingkey = string.Empty;
// 发布
for (int i = ; i < ; i++)
{
routingkey = logname[index++];
msgBody = i.ToString() + routingkey;
index = index == ? : index;
// var routingkey = i % 2 == 0 ? "info" : i % 3 == 0 ? "debug" : "error";
var msg = Encoding.UTF8.GetBytes(msgBody);
Console.WriteLine(msgBody);
channel.BasicPublish("LogExchange", routingKey: routingkey, basicProperties: null, body: msg);
}
}
Console.WriteLine("发布成功!!!");
Console.ReadKey();
}
效果图
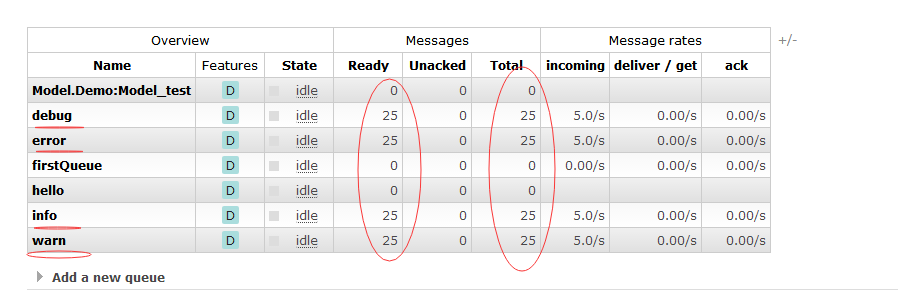
消费者代码
static void Main(string[] args)
{
bool flag = true;
string level = "";
while (flag)
{
Console.WriteLine("请指定要接收的消息级别");
level = Console.ReadLine();
if (level == "info" || level == "error" || level == "debug")
{
using (var channel = HelpConnection.GetConnection().CreateModel())
{
//声明交换机 direct模式
channel.ExchangeDeclare("LogExchange", "direct", true, false, null);
//根据声明使用的队列
// var queueName = level == "info" ? "Log_else" : level == "debug" ? "Log_else" : "Log_error";
channel.QueueDeclare(level, true, false, false, null);
//进行绑定
channel.QueueBind(level, "LogExchange", level, null);
//创建consumbers
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (sender, e) =>
{
var msg = Encoding.UTF8.GetString(e.Body);
Console.WriteLine(msg);
};
//进行消费
channel.BasicConsume(level, true, consumer);
Console.ReadKey();
}
}
else
Console.Write("仅支持info、debug与error级别");
}
}
效果图
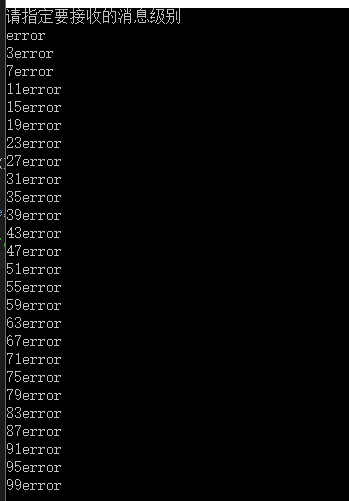
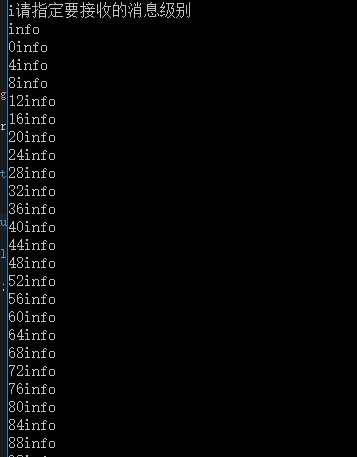
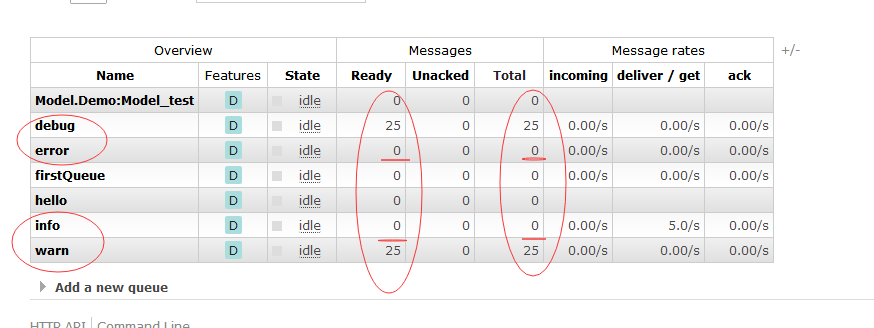
总结
上面文章有学习远友 编程梦 的文章,以上内容仅仅是个人理解和学习,如果有不对的地方或者描述的地方,欢迎拍砖扶正。。。。。。
没想到,我已经写第六篇了,代码入门很简单,但是有些东西,自己去敲理解更深刻。。。
我中间那个小小循环,我之前就想复杂了,还是朋友的推荐,哈哈哈哈,还是实践出真谛。。。
这篇文我昨天在家按照编程梦的思想,敲一遍,一直不能执行成功,后来发现问题,解决了。。。
本篇文章在路上,想怎么把这运用更灵活,期待你博客比我更好,更灵活,哈哈哈。。。
刚刚学着写,大神请教,少喷,拍砖扶正。。。。。。。。。。。。
- 博主是利用读书、参考、引用、抄袭、复制和粘贴等多种方式打造成自己的纯镀 24k 文章,请原谅博主成为一个无耻的文档搬运工!
- 小弟刚迈入博客编写,文中如有不对,欢迎用板砖扶正,希望给你有所帮助。
RabbitMQ六:通过routingkey模拟日志的更多相关文章
- 4.Direct交换机之使用指定routingkey完成日志记录场景
标题 : 4.Direct交换机之使用指定routingkey完成日志记录场景 目录 : RabbitMQ 序号 : 4 const string logOthersQueueName = " ...
- rabbitmq更换数据文件和日志文件的存放位置
原来的默认位置是/var下 需要将这些文件更换位置 1.先创建数据文件和日志文件存放位置的目录并给权限 mkdir -p /usr/local/rabbitmq/mnesia mkdir -p /us ...
- RabbitMQ (六) 订阅者模式之路由模式 ( direct )
路由模式下,生产者发送消息时需要指定一个路由键(routingKey),交换机只会把消息转发给包含该路由键的队列 这里,我们改变一下声明交换机的方式. 我们通过管理后台添加一个交换机. 添加后,生产者 ...
- RabbitMQ 入门 (Go) - 3. 模拟传感器,生成数据并发布
现在,我们需要模拟传感器,生成数据,并发布到 RabbitMQ. 建立传感器项目 在 GOPATH src 下建立文件夹 sensors,使用 go mod init 初始化,并创建 main.go. ...
- Kafka技术内幕 读书笔记之(六) 存储层——日志的读写
-Kafka是一个分布式的( distributed ).分区的( partitioned ).复制的( replicated )提交日志( commitlog )服务 . “分布式”是所有分布式系统 ...
- 【第六章】MySQL日志文件管理
1.日志文件管理概述: 配置文件:/etc/my.cnf 作用:MySQL日志文件是用来记录MySQL数据库客户端连接情况.SQL语句的执行情况以及错误信息告示. 分类:MySQL日志文件分为4种:错 ...
- Android源代码解析之(六)-->Log日志
转载请标明出处:一片枫叶的专栏 首先说点题外话,对于想学android framework源代码的同学,事实上能够在github中fork一份,详细地址:platform_frameworks_bas ...
- Dubbo学习系列之十六(ELK海量日志分析框架)
外卖公司如何匹配骑手和订单?淘宝如何进行商品推荐?或者读者兴趣匹配?还有海量数据存储搜索.实时日志分析.应用程序监控等场景,Elasticsearch或许可以提供一些思路,作为业界最具影响力的海量搜索 ...
- [HTML] websocket的模拟日志监控界面
模拟命令行的界面效果,使用swoole作为websocket的服务,重新做了下html的界面效果 <html> <head> <title>SwLog Montio ...
随机推荐
- Android KK后为何工厂模式下无法adb 无法重新启动机器 ?
前言 欢迎大家我分享和推荐好用的代码段~~ 声明 欢迎转载,但请保留文章原始出处: CSDN:http://www.csdn.net ...
- IEnumerator<TItem>和IEnumerator Java 抽象类和普通类、接口的区别——看完你就顿悟了
IEnumerable 其原型至少可以说有15年历史,或者更长,它是通过 IEnumerator 来定义的,而后者中使用装箱的 object 方式来定义,也就是弱类型的.弱类型不但会有性能问题,最主要 ...
- 数据结构与算法问题 AVL二叉平衡树
AVL树是带有平衡条件的二叉查找树. 这个平衡条件必须保持,并且它必须保证树的深度是O(logN). 一棵AVL树是其每一个节点的左子树和右子树的高度最多差1的二叉查找树. (空树的高度定义为-1). ...
- leveldb学习:DBimpl
leveldb将数据库的有关操作都定义在了DB类,它负责整个系统功能组件的连接和调用.是整个系统的脊柱. level::DB是一个接口类,真正的实如今DBimpl类. 作者在文档impl.html中描 ...
- grep命令最经常使用的功能总结
1. grep最简单的用法,匹配一个词:grep word filename 2. 能够从多个文件里匹配:grep word filename1 filenam2 filename3 3. 能够使用正 ...
- HTML的DOM和浏览器的BOM
DOM和BOM的区别 HTML DOM 的 document 是 BOM 的 window 对象的属性之一: 通过可编程的对象模型,JavaScript 获得了足够的能力来创建动态的 HTML. Ja ...
- 使用spring框架时,使用xml还是注解
1 xml的优缺点 1.1 优点 解耦合,方便维护.xml不入侵代码,方便代码阅读. 1.2 缺点 开发速度慢. 2 注解的优缺点 2.1 优点 能够加快开发速度,因为它将常用的主体逻辑隐藏在注解中了 ...
- Day1 BFS算法的学习和训练
因为自己的原因,之前没有坚持做算法的相应学习,总是觉得太难就半途而废,真的算是一个遗憾了,所以现在开始,定一个30天入门学习算法计划. 我是根据<算法图解>的顺序进行安排的,自己对 ...
- python库学习笔记——BeautifulSoup处理子标签、后代标签、兄弟标签和父标签
首先,我们来看一个简单的网页https://www.pythonscraping.com/pages/page3.html,打开后: 右键"检查"(谷歌浏览器)查看元素: 用导航树 ...
- 并不对劲的bzoj4012:loj2116:p3241: [HNOI2015]开店
题目大意 有一棵\(n\)(\(n\leq1.5*10^5\))个节点的二叉树,有点权\(x\),边权\(w\),\(q\)(\(q\leq2*10^5\))组询问,每组询问给出\(u,l,r\),求 ...