*****Python之进程线程*****
Python之进程线程
Python的threading模块
并发编程:
操作系统:位于底层硬件与应用软件之间的一层。
工作方式:向下管理硬件,向上提供接口。
进程:资源管理单位(容器)
线程:最小执行单位
Python的多线程:由于GIL,导致同一时间,同一时刻,只能有一个线程在运行。
t.join():线程对象t未执行完,会阻塞你的主线程。
全局解释器锁GIL:加在CPython解释器上。
计算密集型:一直在使用CPU
IO:存在大量的IO操作
总结:
对于计算密集型任务:Python的多线程没用
对于IO密集型任务:Python的多线程有用
Python使用多核:开进程,
弊端:开销大,切换复杂
重点:协程+多进程
IO多路复用
线程:
# 调用方式1 # import threading
# import time
#
# def tingge():
# print("听歌")
# time.sleep(3)
# print("听歌结束")
#
# def xieboke():
# print("写博客")
# time.sleep(5)
# print("写博客结束")
#
# print(time.time()-s)
#
# s=time.time()
#
# t1=threading.Thread(target=tingge)
# t2=threading.Thread(target=xieboke)
#
# t1.start()
# t2.start() # 调用方式2
# import threading
# import time
#
# class MyThread(threading.Thread):
#
# def __init__(self,num):
# threading.Thread.__init__(self)
# self.num=num
#
# def run(self):
# print("running on number:%s" %self.num)
# time.sleep(3) # t1=MyThread(56)
# t2=MyThread(78)
#
# t1.start()
# t2.start()
#
# print("ending")
import threading
from time import ctime,sleep
import time def Music(name): print ("Begin listening to {name}. {time}".format(name=name,time=ctime()))
sleep(3)
print(threading.activeCount())
print(threading.enumerate())
print("end listening {time}".format(time=ctime())) def Blog(title): print ("Begin recording the {title}. {time}".format(title=title,time=ctime()))
sleep(5)
print('end recording {time}'.format(time=ctime())) threads = [] t1 = threading.Thread(target=Music,args=('FILL ME',),name="sub_thread")
t2 = threading.Thread(target=Blog,args=('',)) threads.append(t1)
threads.append(t2) if __name__ == '__main__': t1.setDaemon(True) # daemon:监听 for t in threads: t.start() print ("all over %s" %ctime())
GIL锁:
import time def cal(n):
sum=0
for i in range(n):
sum += i s=time.time() import threading t1=threading.Thread(target=cal,args=(50000000,))
t2=threading.Thread(target=cal,args=(50000000,)) t1.start()
t2.start()
t1.join()
t2.join() # cal(50000000)
# cal(50000000) print("time",time.time()-s)
JOIN和Daemon:
# import threading
# from time import ctime,sleep
# import time
#
# def Music(name):
#
# print ("Begin listening to {name}. {time}".format(name=name,time=ctime()))
# sleep(3)
# print("end listening {time}".format(time=ctime()))
#
# def Blog(title):
#
# print ("Begin recording the {title}. {time}".format(title=title,time=ctime()))
# sleep(5)
# print('end recording {time}'.format(time=ctime()))
#
#
# threads = []
#
# t1 = threading.Thread(target=Music,args=('FILL ME',))
# t2 = threading.Thread(target=Blog,args=('python',))
#
# threads.append(t1)
# threads.append(t2)
#
# if __name__ == '__main__': #t2.setDaemon(True)
# t2.setDaemon(True) # for t in threads:
#
# t.start() # for t in threads:
# t.join() # t1.start()
# t1.join()
# t2.start()
# t2.join() # print ("all over %s" %ctime())
死锁和递归锁(RLock):
RLock内部维护里一个计数器,与同步锁相比,可以多次release和acquire。 加锁是维护公共数据。
import threading
import time # mutexA = threading.Lock()
# mutexB = threading.Lock() Rlock=threading.RLock() class MyThread(threading.Thread): def __init__(self):
threading.Thread.__init__(self) def run(self): self.fun1()
self.fun2() def fun1(self): Rlock.acquire() # 如果锁被占用,则阻塞在这里,等待锁的释放 print ("I am %s , get res: %s---%s" %(self.name, "ResA",time.time())) Rlock.acquire() # count=2
print ("I am %s , get res: %s---%s" %(self.name, "ResB",time.time()))
Rlock.release() #count-1 Rlock.release() #count-1 =0 def fun2(self):
Rlock.acquire() # count=1
print ("I am %s , get res: %s---%s" %(self.name, "ResB",time.time()))
time.sleep(0.2) Rlock.acquire() # count=2
print ("I am %s , get res: %s---%s" %(self.name, "ResA",time.time()))
Rlock.release() Rlock.release() # count=0 if __name__ == "__main__": print("start---------------------------%s"%time.time()) for i in range(0, 10): my_thread = MyThread()
my_thread.start()
同步锁:
import time
import threading def subNum(): global num #在每个线程中都获取这个全局变量
# num-=1
print("ok")
lock.acquire() #上锁
temp=num
time.sleep(0.1)
num =temp-1 # 对此公共变量进行-1操作
lock.release() #解锁 num = 100 #设定一个共享变量
thread_list = [] lock=threading.Lock() for i in range(100):
t = threading.Thread(target=subNum)
t.start()
thread_list.append(t)
# t.join() for t in thread_list: #等待所有线程执行完毕
t.join() print('Result: ', num)
反射:
# #继承Thread式创建
#
# import threading
# import time
#
# class MyThread(threading.Thread):
#
# def __init__(self,num):
# threading.Thread.__init__(self)
# self.num=num
#
# def run(self):
# print("running on number:%s" %self.num)
# time.sleep(3)
#
# t1=MyThread(56)
# t2=MyThread(78)
#
# t1.start()
# t2.start()
# print("ending")
import time
class Card:
bank="工行"
def __init__(self,card_number,own_name,money,card_date):
self.card_number=card_number
self.own_name=own_name
self.money=money
self.card_date=card_date
def view(self):
print("账户信息,%s欢迎登录"%(self.bank),self.card_number,self.own_name,self.money,self.card_date)
def take(self,take_money):
mum=self.money-take_money
print("你一共取了%s,余额为%s",take_money,mum) c1=Card("","lzh",10000,time.asctime())
# print(c1.__dict__)#为什么我们可以用字符串操作类下的数据属性和函数属性,因为它们都是以字典的形式存在
print(hasattr(c1,"bank"))#hasattr,以字符串的形式获取类下的属性名,如果存在返回真
print(getattr(c1,"take"))#getattr,得到类下的一个函数属性,如果存在返回一个绑定的函数方法
print(getattr(c1,"take1","没有这个方法"))#getattr,如果没有指定的属性,则报错,getattr还可以添加一个自定义的报错值
#当添加这个值后,getattr方法会返回这个定义值
setattr(c1,"addr","沙河分行")#该方法添加类的数据属性
setattr(c1,"bank","爱存不存")#此处可以修改类中的数据属性值
print(c1.bank)
print(c1.addr)
delattr(c1,"bank")
print(c1.__dict__)
#简单的应用示例,我们可以通过用户输入字符串的形式确定类这个对象中是否有这个操作,
# 如果有,就执行,显示结果,没有就不做任何操作
if hasattr(c1,"view"):
func=getattr(c1,"view")
res=func()
print(res)
else:
pass
event对象:理解为标识位,True和False就好。False将阻塞线程。用set方法,event.set()将event的False状态改为True。
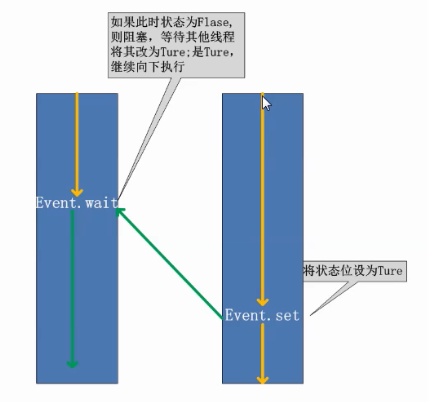
import threading
import time
import logging logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s',) def worker(event):
logging.debug('Waiting for redis ready...') while not event.isSet():
logging.debug("wait.......")
event.wait(3) # if flag=False阻塞,等待flag=true继续执行 logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1) def main(): readis_ready = threading.Event() # flag=False
t1 = threading.Thread(target=worker, args=(readis_ready,), name='t1')
t1.start() t2 = threading.Thread(target=worker, args=(readis_ready,), name='t2')
t2.start() logging.debug('first of all, check redis server, make sure it is OK, and then trigger the redis ready event') time.sleep(6) # simulate the check progress
readis_ready.set() # flag=Ture if __name__=="__main__":
main()
信号量:
import threading
import time semaphore = threading.Semaphore(5) def func(): semaphore.acquire()
print (threading.currentThread().getName() + ' get semaphore')
time.sleep(2)
semaphore.release() for i in range(20):
t1 = threading.Thread(target=func)
t1.start()
进程模块:multiprocessing
#coding:utf8
from multiprocessing import Process
import time def counter():
i = 0
for _ in range(40000000):
i = i + 1 return True def main(): l=[]
start_time = time.time()
#
# for _ in range(2):
# t=Process(target=counter)
# t.start()
# l.append(t)
# #t.join()
#
# for t in l:
# t.join() # counter()
# counter() end_time = time.time()
print("Total time: {}".format(end_time - start_time)) if __name__ == '__main__': main()
# from multiprocessing import Process
#
#
# import time
#
#
# def f(name):
#
# print('hello', name,time.ctime())
# time.sleep(1)
#
# if __name__ == '__main__':
# p_list=[]
#
# for i in range(3):
# p = Process(target=f, args=('alvin:%s'%i,))
# p_list.append(p)
# p.start()
#
#
# # for i in p_list:
# # p.join()
#
# print('end')
from multiprocessing import Process
import os
import time def info(name): print("name:",name)
print('parent process:', os.getppid())
print('process id:', os.getpid())
print("------------------") def foo(name): info(name)
time.sleep(50) if __name__ == '__main__': info('main process line') p1 = Process(target=info, args=('alvin',))
p2 = Process(target=foo, args=('egon',))
p1.start()
p2.start() p1.join()
p2.join() print("ending")
time.sleep(100)
协程:
协程的优点,由于单线程,所以就不用再切换。
不在有锁的概念。
import time
# 可以实现并发
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] ←← Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
next(c)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] →→ Producing %s...' % n)
cr = c.send(n)
print('[PRODUCER] Consumer return: %s' % cr)
c.close()
if __name__=='__main__':
c = consumer()
produce(c)
greenlet模块:
# from greenlet import greenlet
#
#
# def test1():
# print(12)
#
# gr2.switch()
# print(34)
# gr2.switch()
#
#
# def test2():
# print(56)
# gr1.switch()
# print(78)
#
#
# gr1 = greenlet(test1)
# gr2 = greenlet(test2)
#
# gr1.switch() #gevent模块 # import gevent
# import time
#
# def foo():
# print("running in foo")
# gevent.sleep(2)
# print("switch to foo again")
#
# def bar():
# print("switch to bar")
# gevent.sleep(5)
# print("switch to bar again")
#
# start=time.time()
#
# gevent.joinall(
# [gevent.spawn(foo),
# gevent.spawn(bar)]
# )
#
# print(time.time()-start) from gevent import monkey
monkey.patch_all() import gevent
from urllib import request
import time def f(url):
print('GET: %s' % url)
resp = request.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url)) start=time.time() # gevent.joinall([
# gevent.spawn(f, 'https://itk.org/'),
# gevent.spawn(f, 'https://www.github.com/'),
# gevent.spawn(f, 'https://zhihu.com/'),
# ]) f('https://itk.org/')
f('https://www.github.com/')
f('https://zhihu.com/') print(time.time()-start)
test:
# class A:
# def __fa(self):
# print('from A')
# def test(self):
# self.__fa() #_A__fa
#
# class B(A):
# def __fa(self):
# print('from B')
#
# b=B()
# b.test() #用来计算类被实例化的次数
# def get_no_(cls_obj):
# return cls_obj.times_inst
#通常情况下,类实例是解释器自动调用类的__init__()来构造的,通常情况下,类实例是解释器自动调用类的__init__()来构造的
class Exm_cls:
#实例化次数的初始值为0
times_inst = 0
#类被实例化一次,就+1
def __init__(self):
Exm_cls.times_inst +=1
#在内部定义这个函数,并且把他绑定到类
@classmethod
def get_no_(cls):
return cls.times_inst
@staticmethod
def show_type():
fn = classmethod(Exm_cls.get_no_)
print(type(fn))
exm1 = Exm_cls()
exm2 = Exm_cls()
print(Exm_cls.get_no_())
print(Exm_cls.show_type())
# print(get_no_(Exm_cls))
*****Python之进程线程*****的更多相关文章
- python进阶-------进程线程(二)
Python中的进程线程(二) 一.python中的"锁" 1.GIL锁(全局解释锁) 含义: Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(G ...
- python进阶------进程线程(一)
Python中的进程线程 一.进程线程的概念 1.1进程: 进程就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成.我们编写的程序用来描述进程要完成哪些功能以及 ...
- python进阶------进程线程(四)
Python中的协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到其 ...
- python进阶------进程线程(三)
python中的进程 1.multiprocessing模块 由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进 ...
- python的进程/线程/协程
1.python的多线程 多线程就是在同一时刻执行多个不同的程序,然而python中的多线程并不能真正的实现并行,这是由于cpython解释器中的GIL(全局解释器锁)捣的鬼,这把锁保证了同一时刻只有 ...
- Python(进程线程)
一 理论基础: ''' 一 操作系统的作用: 1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口 2:管理.调度进程,并且将多个进程对硬件的竞争变得有序 二 多道技术: 1.产生背景:针对单核,实现并发 ...
- python进阶——进程/线程/协程
1 python线程 python中Threading模块用于提供线程相关的操作,线程是应用程序中执行的最小单元. #!/usr/bin/env python # -*- coding:utf-8 - ...
- python进阶------进程线程(五)
Python中的IO模型 同步(synchronous) IO和异步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分别是什么,到底有什么区别 ...
- Python中进程线程协程小结
进程与线程的概念 进程 程序仅仅只是一堆代码而已,而进程指的是程序的运行过程.需要强调的是:同一个程序执行两次,那也是两个进程. 进程:资源管理单位(容器). 线程:最小执行单位,管理线程的是进程. ...
随机推荐
- bzoj 2178 圆的面积并【simpson积分】
直接套simpson,f可以直接把圆排序后扫一遍所有圆,这样维护一个区间就可以避免空段. 然而一定要去掉被其他圆完全覆盖的圆,否则会TLE #include<iostream> #incl ...
- quickpow || 快速幂
洛谷例题 推荐自行脑补:百度百科 如果 ,那么 : 前言:快速幂就是快速算底数的n次幂.其时间复杂度为 O(log₂N), 与朴素的O(N)相比效率有了极大的提高. 拿题目样例 Input :2 1 ...
- A - Supercentral Point CodeForces - 165A
One day Vasya painted a Cartesian coordinate system on a piece of paper and marked some set of point ...
- Python添加自己的模块路径
进入Python编辑环境后可以,通过Python的sys.path属性获得当前搜索路径的配置,可以看到之前我们设置的路径已经在当前搜索路径中了. 然后通过sys.path.append('F:\Pyt ...
- CF446C [DZY loves Fibonacci]
Description Transmission Gate 你需要维护一个长度为\(n \leq 300000\) 的数列,兹词两个操作: 1.给一个区间加上一个fibonacci数列,规定\(f[0 ...
- [转]访问 OData 服务 (WCF Data Services)
本文转自:http://msdn.microsoft.com/zh-SG/library/dd728283(v=vs.103) WCF 数据服务 支持开放式数据协议 (OData) 将数据作为包含可通 ...
- AJPFX总结IO流中的缓冲思想
缓冲思想 (因为内存的运算速度要远大于硬盘的原酸速度,所以只要降低硬盘的读写次数,就可以提高效率) 1. 字节流一次读写一个数组的速度明显比一次读写一个字节的速度快很多, 2. 这是加 ...
- subprocess模块和sys模块
1.import sys # sys.path # sys.argv # 用来接收python解释器执行py文件后跟的参数#例如:python cp.py argv1 argv2 arg3#sys.a ...
- poj2886 Who Gets the Most Candies?
思路: 先打反素数表,即可确定因子最多的那个数.然后模拟踢人的过程确定对应的人名.模拟的过程使用线段树优化加速. 实现: #include <cstdio> #include <cs ...
- 免费大数据搜索引擎 xunsearch 实践
以前在IBM做后端开发时,也接触过关于缓存技术,当时给了n多文档来学习,后面由于其他紧急的项目,一直没有着手去仔细研究这个技术,即时后来做Commerce的时候,后台用了n多缓存技术,需要build ...