AbstractRoutingDataSource动态选择数据源
当我们项目变大后,有时候需要多个数据源,接下来我们讲一种能等动态切换数据源的例子。
盗一下图:
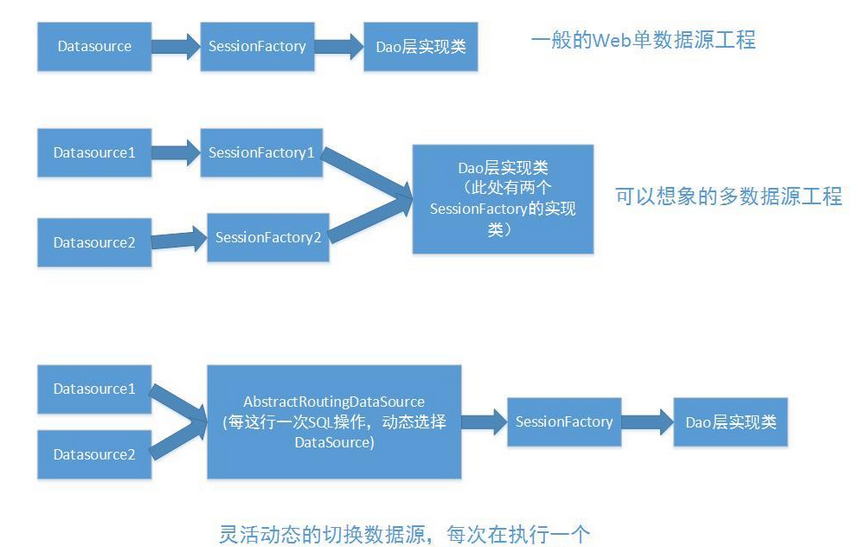
- 单数据源的场景(一般的Web项目工程这样配置进行处理,就已经比较能够满足我们的业务需求)
- 多数据源多SessionFactory这样的场景,估计作为刚刚开始想象想处理在使用框架的情况下处理业务,配置多个SessionFactory,然后在Dao层中对于特定的请求,通过特定的SessionFactory即可处理实现这样的业务需求
- 使用AbstractRoutingDataSource 的实现类,进行灵活的切换,可以通过AOP或者手动编程设置当前的DataSource,不用修改我们编写的对于继承HibernateSupportDao的实现类的修改,这样的编写方式比较好
我们这次讲的是第三种,第二种也可以实现,相对来说也比较简单。
第一步:写AbstractRoutingDataSource的实现类
package com.inspur.tax.common.utils; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource; /**
* @ClassName ThreadLocalRountingDataSource
* @Author caozx
* @Description //TODO $
* @Date $ $
**/
public class ThreadLocalRountingDataSource extends AbstractRoutingDataSource { @Override
protected Object determineCurrentLookupKey() {
// 获取数据源
return DataSourceTypeManager.getDataSource();
}
}
第二步:设置动态选择的Datasource,这里用到了ThreadLocal。
package com.inspur.tax.common.utils; /**
* @ClassName DataSourceTypeManager
* @Author caozx
* @Description //TODO $
* @Date $ $
**/
public class DataSourceTypeManager {
/**
* 注意:数据源标识保存在线程变量中,避免多线程操作数据源时互相干扰
*/
private static final ThreadLocal<String> THREAD_DATA_SOURCE = new ThreadLocal<String>(); public static String getDataSource() {
return THREAD_DATA_SOURCE.get();
} public static void setDataSource(String dataSource) {
THREAD_DATA_SOURCE.set(dataSource);
} public static void clear() {
THREAD_DATA_SOURCE.remove();
}
}
第三步:在Spring核心容器中配置配置数据源
<?xml version="1.0" encoding="UTF-8"?>
<!-- wbw 2016.8.22 -->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/jdbc
http://www.springframework.org/schema/jdbc/spring-jdbc-3.2.xsd"> <bean id="dataSource_mysql" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close"> <property name="url" value="${dataSource.mysql.url}" />
<property name="username" value="${dataSource.mysql.username}" />
<property name="password" value="${dataSource.mysql.password}" /> <!-- 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j
防御sql注入的filter:wall -->
<property name="filters" value="stat" /> <!-- 最大连接池数量(缺省值:8) -->
<property name="maxActive" value="20" />
<!-- 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时(缺省值:0) -->
<property name="initialSize" value="1" />
<!-- 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 -->
<property name="maxWait" value="60000" />
<!-- 最小连接池数量 -->
<property name="minIdle" value="1" /> <!-- 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接
2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 (缺省值:1分钟) -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 连接保持空闲而不被驱逐的最长时间(缺省值:30分钟) -->
<property name="minEvictableIdleTimeMillis" value="300000" /> <!-- 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。(缺省值:false) -->
<property name="testWhileIdle" value="true" />
<!-- 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。(缺省值:true) -->
<property name="testOnBorrow" value="false" />
<!-- 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能(缺省值:false) -->
<property name="testOnReturn" value="false" /> <!-- 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 -->
<property name="validationQuery" value="SELECT 1" /> <!-- 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。(缺省值:fasle) -->
<property name="poolPreparedStatements" value="false" />
<!-- 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100(缺省值:-1) -->
<property name="maxOpenPreparedStatements" value="-1" /> <!-- 在上面的配置中,通常你需要配置url、username、password,maxActive这三项 -->
</bean> <bean id="dataSource_oracle" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close"> <property name="url" value="${dataSource.oracle.url}" />
<property name="username" value="${dataSource.oracle.username}" />
<property name="password" value="${dataSource.oracle.password}" /> <!-- 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j
防御sql注入的filter:wall -->
<property name="filters" value="stat" /> <!-- 最大连接池数量(缺省值:8) -->
<property name="maxActive" value="20" />
<!-- 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时(缺省值:0) -->
<property name="initialSize" value="1" />
<!-- 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 -->
<property name="maxWait" value="60000" />
<!-- 最小连接池数量 -->
<property name="minIdle" value="1" /> <!-- 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接
2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 (缺省值:1分钟) -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 连接保持空闲而不被驱逐的最长时间(缺省值:30分钟) -->
<property name="minEvictableIdleTimeMillis" value="300000" /> <!-- 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。(缺省值:false) -->
<property name="testWhileIdle" value="true" />
<!-- 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。(缺省值:true) -->
<property name="testOnBorrow" value="false" />
<!-- 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能(缺省值:false) -->
<property name="testOnReturn" value="false" /> <!-- 用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会其作用。 -->
<property name="validationQuery" value="SELECT 1 FROM DUAL" /> <!-- 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。(缺省值:fasle) -->
<property name="poolPreparedStatements" value="true" />
<!-- 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100(缺省值:-1) -->
<property name="maxOpenPreparedStatements" value="100" /> <!-- 在上面的配置中,通常你需要配置url、username、password,maxActive这三项 -->
</bean> <bean id="dataSource" class="com.inspur.tax.common.utils.ThreadLocalRountingDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<entry key="master" value-ref="dataSource_oracle"/>
<entry key="slave" value-ref="dataSource_mysql"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSource_oracle"></property>
</bean>
</beans>
第四步:直接在调用dao层之前使用:
@Override
public Map<String, String> getYyssqk(String qxswjguandm) {
DataSourceTypeManager.setDataSource("slave");
System.out.println(DataSourceTypeManager.getDataSource());
Map<String,Object> params = new HashMap<String, Object>();
params.put("qxswjguandm", qxswjguandm);
Map<String, String> qnMap = sskjjMapper.getYyssqk(params);
params.remove("tb");
Map<String, String> bnMap = sskjjMapper.getYyssqk(params);
DecimalFormat df = new DecimalFormat(",##0.00");
if(Double.parseDouble(qnMap.get("LJ_YYSR"))==0){
注意代码中的红色部分,这就切换到了slave所对应的数据源。注意在代码最后进行清除,重新设置到默认的数据源。
DataSourceTypeManager.clear()
进行到这里就实现了动态选择数据源,是不是很简单,有没有觉得有点问题呢?没错,每次选择都得执行代码DataSourceTypeManager.setDataSource("slave"),我们可以用aop的注解的方式哟,直接在方法上添加注解(对于方法体内来回切换的那种就老老实实手写吧)。
第五步:写注解
package com.inspur.tax.common.utils; import java.lang.annotation.*; @Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DynamicSwitchDataSource {
String value() default "";
}
第六步:写切面类,前置通知和后置通知
package com.inspur.tax.common.utils; import java.lang.reflect.Method; import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* @ClassName DataSourceAspect
* @Author caozx
* @Description //TODO $
* @Date $ $
**/
@Aspect
public class DataSourceAspect { private final static Logger log = LoggerFactory.getLogger(DataSourceAspect.class); @Pointcut("@annotation(com.inspur.tax.common.utils.DynamicSwitchDataSource)")
private void pointCut(){} @Before("pointCut()")
public void beforeMethod(JoinPoint jp){
try {
//获取抽象方法(接口的或抽象类的方法)
Method method = ((MethodSignature) jp.getSignature()).getMethod(); //这个是接口方法的注解,没有所以为null
//DynamicSwitchDataSource annotationClass = method.getAnnotation(DynamicSwitchDataSource.class); //获取当前类的对象
Class<?> clazz = jp.getTarget().getClass();
//获取实现类的方法
method = clazz.getMethod(method.getName(), method.getParameterTypes());
//获取方法上的注解
DynamicSwitchDataSource annotationClass = method.getAnnotation(DynamicSwitchDataSource.class);
if (annotationClass == null) {
//获取类上面的注解
annotationClass = jp.getTarget().getClass().getAnnotation(DynamicSwitchDataSource.class);
if (annotationClass == null) return;
}
//获取注解上的数据源的值的信息
String dataSourceKey = annotationClass.value();
if (dataSourceKey != null) { //给当前的执行SQL的操作设置特殊的数据源的信息
DataSourceTypeManager.setDataSource(dataSourceKey);
}
log.info("AOP动态切换数据源");
}catch (Exception e){
log.info(e.getMessage());
}
} @After("pointCut()")
public void after(JoinPoint jp){
DataSourceTypeManager.clear();
log.info("后置通知");
}
}
第七步:调用
@Override
@DynamicSwitchDataSource("master")
public Map<String, String> getYyssqk(String qxswjguandm) {
System.out.println(DataSourceTypeManager.getDataSource());
Map<String,Object> params = new HashMap<String, Object>();
params.put("qxswjguandm", qxswjguandm);
AbstractRoutingDataSource动态选择数据源的更多相关文章
- 【开发笔记】- AbstractRoutingDataSource动态数据源切换,AOP实现动态数据源切换
AbstractRoutingDataSource动态数据源切换 上周末,室友通宵达旦的敲代码处理他的多数据源的问题,搞的非常的紧张,也和我聊了聊天,大概的了解了他的业务的需求.一般的情况下我们都是使 ...
- AbstractRoutingDataSource动态数据源切换,AOP实现动态数据源切换
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/u012881904/article/de ...
- AbstractRoutingDataSource动态数据源切换
操作数据一般都是在DAO层进行处理,可以选择直接使用JDBC进行编程(http://blog.csdn.net/yanzi1225627/article/details/26950615/) 或者是使 ...
- springboot动态多数据源
参考文章:https://www.cnblogs.com/hehehaha/p/6147096.html 前言 目标是springboot工程支持多个MySQL数据源,在代码层面上,同一个SQL(Ma ...
- 基于AbstractRoutingDataSource实现动态切换数据源
基于AbstractRoutingDataSource实现动态切换数据源 /** * DataSource注解接口 */ @Target({ElementType.TYPE, ElementTyp ...
- Spring3 整合MyBatis3 配置多数据源 动态选择SqlSessionFactory
一.摘要 上两篇文章分别介绍了Spring3.3 整合 Hibernate3.MyBatis3.2 配置多数据源/动态切换数据源 方法 和 Spring3 整合Hibernate3.5 动态切换Ses ...
- Spring3.3 整合 Hibernate3、MyBatis3.2 配置多数据源/动态切换数据源 方法
一.开篇 这里整合分别采用了Hibernate和MyBatis两大持久层框架,Hibernate主要完成增删改功能和一些单一的对象查询功能,MyBatis主要负责查询功能.所以在出来数据库方言的时候基 ...
- hibernate动态切换数据源
起因: 公司的当前产品,主要是两个项目集成的,一个是java项目,还有一个是php项目,两个项目用的是不同的数据源,但都是mysql数据库,因为java这边的开发工作已经基本完成了,而php那边任务还 ...
- spring 动态创建数据源
项目需求如下,公司对外提供服务,公司本身有个主库,另外公司会为每个新客户创建一个数据库,客户的数据库地址,用户名,密码,都保存在主数据库中.由于不断有新的客户加入,所以要求,项目根据主数据库中的信息, ...
随机推荐
- A1. JVM 内存区域
[概述] 在这篇笔记中,需要描述虚拟机中的内存是如何划分的,哪部分区域.什么样的代码和操作可能导致内存溢出异常.虽然 Java 有垃圾处理机制,但是如果生产环境在出现内存溢出异常时,由于开发人员不熟悉 ...
- Listview异步加载图片之优化篇
在APP应用中,listview的异步加载图片方式能够带来很好的用户体验,同时也是考量程序性能的一个重要指标.关于listview的异步加载,网上其实很多示例了,中心思想都差不多,不过很多版本或是有b ...
- 四角递推(CF Working out,动态规划递推)
题目:假如有A,B两个人,在一个m*n的矩阵,然后A在(1,1),B在(m,1),A要走到(m,n),B要走到(1,n),两人走的过程中可以捡起格子上的数字,而且两人速度不一样,可以同时到一个点(哪怕 ...
- 洛谷 1328 生活大爆炸版石头剪刀布(NOIp2014提高组)
[题解] 简单粗暴的模拟题. #include<cstdio> #include<algorithm> #include<cstring> #define LL l ...
- [bzoj3209][花神的数论题] (数位dp+费马小定理)
Description 背景众所周知,花神多年来凭借无边的神力狂虐各大 OJ.OI.CF.TC …… 当然也包括 CH 啦.描述话说花神这天又来讲课了.课后照例有超级难的神题啦…… 我等蒟蒻又遭殃了. ...
- Python基础—面向对象(初级篇)
一.什么是面向对象编程 面向对象编程(Object Oriented Programming,OOP,面向对象程序设计),python语言比较灵活即支持面向对象编程也支持面向函数式编程. 面向过程编程 ...
- Tclientdate的排序
CDS_common.IndexDefs.Clear; CDS_common.AddIndex('JSPH','JSPH',[],'JSPH'); CDS_common.A ...
- HTML5中Canvas概述
一.HTML5 Canvas历史 Canvas的概念最初是由苹果公司提出的,用于在Mac OS X WebKit中创建控制板部件(dashboard widget).在Canvas出现之前,开发人员若 ...
- Java基础学习总结(82)——Java泛型实例教程
1.为什么需要泛型 泛型在Java中有很重要的地位,网上很多文章罗列各种理论,不便于理解,本篇将立足于代码介绍.总结了关于泛型的知识.希望能给你带来一些帮助. 先看下面的代码: List list = ...
- Navicat使用技巧
1.有时按快捷键Ctrl+F搜某条数据的时候搜不到,但是能用sql查出来,这是怎么回事? Ctrl+F只能搜本页数据,不在本页的数据搜不到,navicat每页只显示1000条数据.在数据多的时候nav ...