Python 之有道翻译数据抓取
import requests
import time def you_dao():
key = input("请输入要翻译的内容:")
# key = "哈哈"
# 构建url链接
# url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
# 这里要去掉?号前面的_o,不然会进行加密算法,导致失败
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
salt = int(time.time() * 10000)
ts = int(salt / 10)
form_data = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": "abf857d70c24cb55263b1f624193b38b",
"ts": ts,
"bv": "bbb3ed55971873051bc2ff740579bb49",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
json_data = requests.get(url, params=form_data, headers=headers).json()
print(json_data['translateResult'])
return json_data['translateResult'][0][0]['tgt'] if __name__ == '__main__':
you_dao()
运行效果如图:
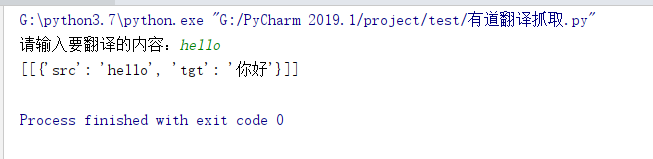
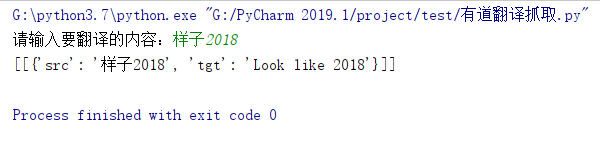
Python 之有道翻译数据抓取的更多相关文章
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- Python笔记(十一)——数据抓取例子
上班时候想看股票行情怎么办?试试这个小例子,5分钟拉去一次股票价格,预警: #coding=utf-8 import re import urllib2 import time import thre ...
- Python学习之静态页面数据抓取
1 页面信息抓取 定义getPage函数,根据传入的页码get到整个页面的html内容 getContent函数,通过正则匹配把页面中的表格部分的html内容取出 最后定义getData函数,同样是通 ...
- Python开发笔记:网络数据抓取
网络数据获取(爬取)分为两部分: 1.抓取(抓取网页) · urlib内建模块,特别是urlib.request · Requests第三方库(中小型网络爬虫的开发) · Scrapy框架(大型网络爬 ...
- Python爬虫之-动态网页数据抓取
什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
- python 入门实践之网页数据抓取
这个不错.正好入门学习使用. 1.其中用到 feedparser: 技巧:使用 Universal Feed Parser 驾驭 RSS http://www.ibm.com/developerwor ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
- 数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
随机推荐
- J2SE基础:5.面向对象的特性2
Final的使用 final在类之前 表示该类是终于类.表示该类不能再被继承. final在方法之前 表示该方法是终于方法,该方法不能被不论什么派生的子类覆盖. final在变量之前 表示变量的值在初 ...
- BZOJ 3007 解救小云公主 二分答案+对偶图
题目大意:给定一个矩形和矩形内的一些点.求一条左下角到右上角的路径.使全部点到这条路径的最小距离最大 最小距离最大.果断二分答案 如今问题转化成了给定矩形中的一些圆形障碍物求左下角和右上角是否连通 然 ...
- C 基础 全局变量
/** 被static修饰的局部变量 1.只有一份内存, 只会初始化一次 2.生命周期会持续到程序结束 3.static改变了局部变量的生命周期, 但是不能改变局部变量的作用域 被static修饰的全 ...
- 带你装B,带你飞的大数据时代
我接触过的大数据有: 1.美国棱镜计划 2.前几天新闻报道的,苹果公司窃取用户隐私 3.百度的用户搜素习惯统计分析 4.淘宝的用户购物习惯分析,智能推荐宝贝 5.浏览器的智能标签页 ... 最想了解的 ...
- 基于二叉搜索树的符号表和BST排序
原代码例如以下: #include <stdlib.h> #include <stdio.h> //#define Key int typedef int Key; struc ...
- Java遍历一个文件夹下的全部文件
Java工具中为我们提供了一个用于管理文件系统的类,这个类就是File类,File类与其它流类不同的是,流类关心的是文件的内容.而File类关心的是磁盘上文件的存储. 一,File类有多个构造器,经常 ...
- node.js下操作cookie
cookie,又是cookie.工作中与cookie打交道很多次,不过时间跨度也大,每总结多一次,就加深了解多一点. cookie,一定是放在浏览器中的,用于浏览器保存一些小额度的内容.每次我们去访问 ...
- 【NOI2009】Bzoj1562&Codevs1843 变换序列
目录 List Description Input Output Sample Input Sample Output HINT Solution 官方题解%莫队 Code Position: htt ...
- [BZOJ 3132] 上帝造题的七分钟
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=3132 [算法] 二维树状数组 [代码] #include<bits/stdc+ ...
- Kafka VS Flume
(1)kafka和flume都是日志系统.kafka是分布式消息中间件,自带存储,提供push和pull存取数据功能.flume分为agent(数据采集器),collector(数据简单处理和写入) ...