k[原创]Faster R-CNN论文翻译
物体检测论文翻译系列:
- R-CNN
- SPP-net
- Fast R-CNN
- Faster R-CNN
Faster R-CNN论文翻译
Faster R-CNN是互怼完了的好基友一起合作出来的巅峰之作,本文翻译的比例比较小,主要因为本paper是前述paper的一个简单改进,方法清晰,想法自然。什么想法?就是把那个一直明明应该换掉却一直被几位大神挤牙膏般地拖着不换的选择性搜索算法,即区域推荐算法。在Fast R-CNN的基础上将区域推荐换成了神经网络,而且这个神经网络和Fast R-CNN的卷积网络一起复用,大大缩短了计算时间。同时mAP又上了一个台阶,我早就说过了,他们一定是在挤牙膏。
Faster R-CNN: Towards Real-Time Object
Detection with Region Proposal Networks
摘要
1. 介绍
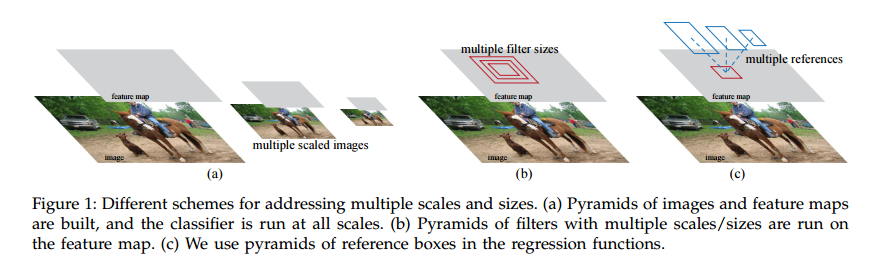
2 相关工作
3 FASTER R-CNN
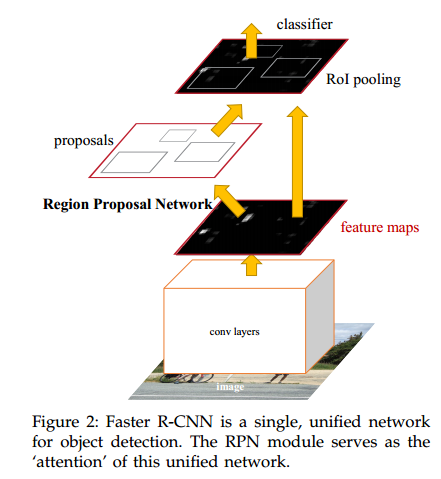
3.1 区域推荐网络
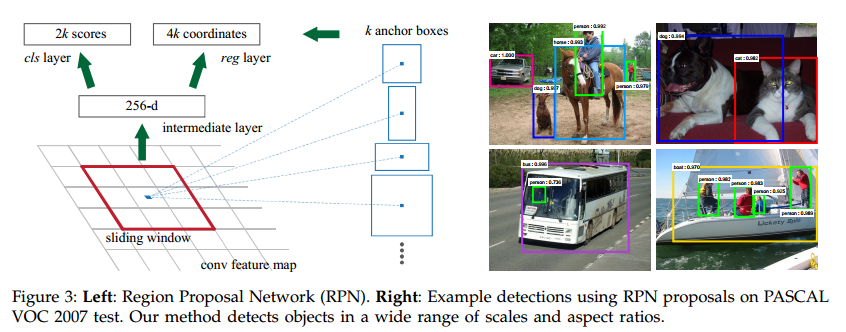
3.1.1 锚点
平移不变性锚点
多尺度锚点作为回归参照物
3.1.2 损失函数

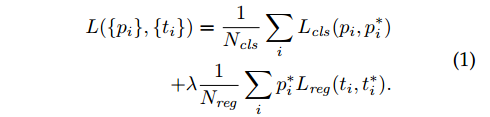

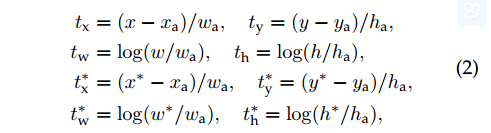
3.1.3 训练RPNs
3.2 RPN and Fast R-CNN之间共享特征
3.3 实现细节
4 EXPERIMENTS
5 CONCLUSION
参考文献
[2] R. Girshick, “Fast R-CNN,” in IEEE International Conference onComputer Vision (ICCV), 2015.
[3] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in InternationalConference on Learning Representations (ICLR), 2015.
[4] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” InternationalJournal of Computer Vision (IJCV), 2013.
[5] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich featurehierarchies for accurate object detection and semantic segmentation,” in IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2014.
[6] C. L. Zitnick and P. Dollar, “Edge boxes: Locating object ´proposals from edges,” in European Conference on ComputerVision (ECCV), 2014.
[7] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutionalnetworks for semantic segmentation,” in IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2015.
[8] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, “Object detection with discriminatively trained partbased models,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2010.
[9] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus,and Y. LeCun, “Overfeat: Integrated recognition, localizationand detection using convolutional networks,” in InternationalConference on Learning Representations (ICLR), 2014.
[10] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” inNeural Information Processing Systems (NIPS), 2015.
[11] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, andA. Zisserman, “The PASCAL Visual Object Classes Challenge2007 (VOC2007) Results,” 2007.
[12] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick, “Microsoft COCO: Com- ´mon Objects in Context,” in European Conference on ComputerVision (ECCV), 2014.
[13] S. Song and J. Xiao, “Deep sliding shapes for amodal 3d objectdetection in rgb-d images,” arXiv:1511.02300, 2015.
[14] J. Zhu, X. Chen, and A. L. Yuille, “DeePM: A deep part-basedmodel for object detection and semantic part localization,”arXiv:1511.07131, 2015.
[15] J. Dai, K. He, and J. Sun, “Instance-aware semantic segmentation via multi-task network cascades,” arXiv:1512.04412, 2015.
[16] J. Johnson, A. Karpathy, and L. Fei-Fei, “Densecap: Fullyconvolutional localization networks for dense captioning,”arXiv:1511.07571, 2015.
[17] D. Kislyuk, Y. Liu, D. Liu, E. Tzeng, and Y. Jing, “Human curation and convnets: Powering item-to-item recommendationson pinterest,” arXiv:1511.04003, 2015.
[18] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learningfor image recognition,” arXiv:1512.03385, 2015.
[19] J. Hosang, R. Benenson, and B. Schiele, “How good are detection proposals, really?” in British Machine Vision Conference(BMVC), 2014.
[20] J. Hosang, R. Benenson, P. Dollar, and B. Schiele, “What makes ´for effective detection proposals?” IEEE Transactions on PatternAnalysis and Machine Intelligence (TPAMI), 2015.
[21] N. Chavali, H. Agrawal, A. Mahendru, and D. Batra,“Object-Proposal Evaluation Protocol is ’Gameable’,” arXiv:1505.05836, 2015.
[22] J. Carreira and C. Sminchisescu, “CPMC: Automatic object segmentation using constrained parametric min-cuts,”IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI), 2012.
[23] P. Arbelaez, J. Pont-Tuset, J. T. Barron, F. Marques, and J. Malik, ´“Multiscale combinatorial grouping,” in IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2014.
[24] B. Alexe, T. Deselaers, and V. Ferrari, “Measuring the objectness of image windows,” IEEE Transactions on Pattern Analysisand Machine Intelligence (TPAMI), 2012.
[25] C. Szegedy, A. Toshev, and D. Erhan, “Deep neural networksfor object detection,” in Neural Information Processing Systems(NIPS), 2013.
[26] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, “Scalableobject detection using deep neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[27] C. Szegedy, S. Reed, D. Erhan, and D. Anguelov, “Scalable,high-quality object detection,” arXiv:1412.1441 (v1), 2015.
[28] P. O. Pinheiro, R. Collobert, and P. Dollar, “Learning tosegment object candidates,” in Neural Information ProcessingSystems (NIPS), 2015.
[29] J. Dai, K. He, and J. Sun, “Convolutional feature maskingfor joint object and stuff segmentation,” in IEEE Conference onComputer Vision and Pattern Recognition (CVPR), 2015.
[30] S. Ren, K. He, R. Girshick, X. Zhang, and J. Sun, “Object detection networks on convolutional feature maps,”arXiv:1504.06066, 2015.
[31] J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, andY. Bengio, “Attention-based models for speech recognition,”in Neural Information Processing Systems (NIPS), 2015.
[32] M. D. Zeiler and R. Fergus, “Visualizing and understandingconvolutional neural networks,” in European Conference onComputer Vision (ECCV), 2014.
[33] V. Nair and G. E. Hinton, “Rectified linear units improverestricted boltzmann machines,” in International Conference onMachine Learning (ICML), 2010.
[34] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov,D. Erhan, and A. Rabinovich, “Going deeper with convolutions,” in IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2015.
[35] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard,W. Hubbard, and L. D. Jackel, “Backpropagation applied tohandwritten zip code recognition,” Neural computation, 1989.
[36] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma,Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg,and L. Fei-Fei, “ImageNet Large Scale Visual RecognitionChallenge,” in International Journal of Computer Vision (IJCV),2015.
[37] A. Krizhevsky, I. Sutskever, and G. Hinton, “Imagenet classification with deep convolutional neural networks,” in NeuralInformation Processing Systems (NIPS), 2012.
[38] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell, “Caffe: Convolutionalarchitecture for fast feature embedding,” arXiv:1408.5093, 2014.
[39] K. Lenc and A. Vedaldi, “R-CNN minus R,” in British MachineVision Conference (BMVC), 2015.
k[原创]Faster R-CNN论文翻译的更多相关文章
- [原创]Faster R-CNN论文翻译
Faster R-CNN论文翻译 Faster R-CNN是互怼完了的好基友一起合作出来的巅峰之作,本文翻译的比例比较小,主要因为本paper是前述paper的一个简单改进,方法清晰,想法自然.什 ...
- 深度学习论文翻译解析(十三):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
论文标题:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 标题翻译:基于区域提议(Regi ...
- 深度学习论文翻译解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
论文标题:Faster R-CNN: Down the rabbit hole of modern object detection 论文作者:Zhi Tian , Weilin Huang, Ton ...
- 深度学习论文翻译解析(三):Detecting Text in Natural Image with Connectionist Text Proposal Network
论文标题:Detecting Text in Natural Image with Connectionist Text Proposal Network 论文作者:Zhi Tian , Weilin ...
- R-CNN论文翻译
R-CNN论文翻译 Rich feature hierarchies for accurate object detection and semantic segmentation 用于精确物体定位和 ...
- SSD: Single Shot MultiBoxDetector英文论文翻译
SSD英文论文翻译 SSD: Single Shot MultiBoxDetector 2017.12.08 摘要:我们提出了一种使用单个深层神经网络检测图像中对象的方法.我们的方法,名为SSD ...
- 深度学习论文翻译解析(二):An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition
论文标题:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application ...
- 论文翻译——R-CNN(目标检测开山之作)
R-CNN论文翻译 <Rich feature hierarchies for accurate object detection and semantic segmentation> 用 ...
- 【论文翻译】NIN层论文中英对照翻译--(Network In Network)
[论文翻译]NIN层论文中英对照翻译--(Network In Network) [开始时间]2018.09.27 [完成时间]2018.10.03 [论文翻译]NIN层论文中英对照翻译--(Netw ...
随机推荐
- 听SEO大神夜息分享
今天偶然听说了百度站长平台,又偶然在上面发现了夜息大神的分享(http://zhanzhang.baidu.com/college/videoinfo?id=871). 之前对于SEO的了解只限于减少 ...
- [bzoj1232][Usaco2008Nov]安慰奶牛cheer_Kruskal
安慰奶牛 cheer bzoj-1232 Usaco-2008 Nov 题目大意:给定一个n个点,m条边的无向图,点有点权,边有边权.FJ从一个点出发,每经过一个点就加上该点点权,每经历一条边就加上该 ...
- Spring Boot配置文件规则以及使用方法官方文档查找以及Spring项目的官方文档查找方法
比如要使用Spring Boot实现一个功能,最直接的方式是Google,但是往往搜索出来的都比较乱,关键是乱在不同的版本上,比如1.x版本和2.x版本的配置是不一样的.最明显区别是在使用Thymel ...
- 利用Clojure统计代码文件数量和代码行数
;; 引入clojure的io包 (use '[clojure.java.io]) ;; 遍历目录将所有符合要求的文件做为列表返回 (defn walk [dirpath pattern] (doal ...
- Username is not in the sudoers file. This incident will be reported
type sudo adduser <username> sudo where username is the name of the user you want to add in th ...
- [Vue-rx] Switch to a Function which Creates Observables with Vue.js and Rxjs
Wrapping the creation of an Observable inside of a Function allows you delay the creation of the Obs ...
- android传感器;摇一摇抽签功能
package com.kane.sensortest; import java.util.Random; import android.hardware.Sensor; import android ...
- 虚拟化(二):虚拟化及vmware workstation产品使用
虚拟化(一):虚拟化及vmware产品介绍 vmware workstation的最新版本号是10.0.2. 相信大家也都使用过,当中的简单的虚拟机的创建.删除等,都非常easy.这里就不再具体说明了 ...
- 技术架构model
- QMap QHash的选择(QString这种复杂的比较,哈希算法比map快很多)
QMap QHash有近乎相同的功能.很多资料里面介绍过他们之间的区别了.但是都没有说明在使用中如何选择他们. 实际上他们除了存储顺序的差别外,只有key操作的区别. 哈希算法是将包含较多信息的“ke ...