[读书笔记]流畅的Python(Fluent Python)
《流畅的Python》这本书是图灵科技翻译出版的一本书,作者Luciano Ramalho。
作者从Python的特性角度出发,以Python的数据模型和特殊方法为主线,主要介绍了python的集合类型(sequence、mapping、set等)、把函数作为一等对象来使用、类的构建、新的文件控制流程(生成器、上下文管理器、协程)、用描述符来从底层解释Python对象属性的存储等各个方面。
书中主要围绕Python标准库展开,不会涉及太多的标准库以外的包。虽然它们也很实用。
建议大家可以把前言多读几遍。书的结构也挺棒,每一章都有内容大纲、小结、延伸阅读、杂谈。
0x01:这本书适合谁看?
作者在前言中说:“本书的目标读者是那些正在使用 Python,又想熟悉 Python 3 的程序员。” 还有就是希望深入了解Python3新特性的人。
貌似是任何学了Python的人都可以看。
不过正如作者所说的, 我也觉得这本书的确不太适合新手看,主要是因为它并不讲解基础的内容,例如如何开始编程,而是重点讲解如何更好的使用Python。
当然新手看一看也有提升的,毕竟你希望自己有一天也成为老鸟。
那么你到底是不是新手呢?可以看一看官网教程,做一做里面的例子,如果感觉吃力,那么就是新手了。^_^
官网教程中文版http://www.pythondoc.com/pythontutorial3/index.html
英文版https://docs.python.org/3/tutorial/
打个比喻,学习Python好比学走路。
Python入门新手就是刚学会走路的小孩。编程中级水平者就是会走路。编程高手就是会走模特步的人。
0x02:作者简介
作者Luciano Ramalho是ThoughtWorks技术大拿,资深Python程序员,Python软件基金会成员。
Luciano Ramalho 从1998 年开始使用 Python,至今已经近20年。自那以后,他在巴西的几个新闻门户网站工作,使用 Python 做开发,还为巴西的媒体、银行和政府部门做 Python Web 开发培训。他经常在开发者大会上演讲,比如 PyCon US(2013)、OSCON(2002、2013 和 2014),还有多年在 PythonBrasil(在巴西举办的 PyCon)以及 FISL(南半球最大的 FLOSS 大会)上做过的 15 次演讲。Ramalho 是 Python 软件基金会的成员,还是巴西第一个众创空间 Garoa Hacker Clube 的联合创始人。他也是培训公司 Python.pro.br 的共同所有人。
0x03:写作目的
赚钱呗,呵呵。赚钱当然是目的之一,但热爱是成功的因素,不能把赚钱当成唯一目的 。
我觉得,作者在前言里提到的:“这本书不是一本完备的Python手册,而是会强调Python作为编程语言独有的特性。”
这一句话应该是作者背后的目的之一。
此外,向人们介绍如何写出高效的代码,如何利用好现有的工具而不是什么都自己造轮子,这些也是目的之一。
0x04:精彩之处
我是新手,只通读了一遍,还没有全看完。这里结合自己看到的内容,列几处个人觉得精彩的地方:
1、列表推导和生成器表达式(2.2节)
同样的功能,代码的长度不一样。
#方法1 传统的循环加赋值语句
symbols = '$¢£¥€¤'
codes = []
for symbol in symbols:
codes.append(ord(symbol)) print (codes)
#方法2 列表推导
newcodes = [ord(symbol) for symbol in symbols]
print(newcodes)
生成器表达式存在的理由之一,是它并不是一次生成所有的列表,而是在需要时才生成,就不用占用很多的空间。不过有时候,你得取得“时间和空间”的平衡。(第14章中会有更多介绍)
colors = ['black', 'white']
sizes = ['S', 'M', 'L']
for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes):
print(tshirt)
2、元组拆包
所谓元组拆包,就是把元组对应的元素分解。
平行赋值
>>> lax_coordinates = (33.9425, -118.408056)
>>> latitude, longitude = lax_coordinates # 元组拆包
>>> latitude
33.9425
>>> longitude
-118.408056
交换变量
>>> b, a = a, b
【元组拆包可以应用到任何可迭代对象上,唯一的硬性要求是,被可迭代对象中的元素数量必须要跟接受这些元素的元组的空档数一致。除非我们用* 来表示忽略多余的元素,在“用* 来处理多余的元素”一节里,我会讲到它的具体用法。Python 爱好者们很喜欢用元组拆包这个说法 ,但是可迭代元素拆包这个表达也慢慢流行了起来,比如“ PEP 3132—Extended Iterable Unpacking”(https://www.python.org/dev/peps/pep-3132/)的标题就是这么用的。】
3、一等函数(第5.1节):
这个例子中把函数作为返回值传回。作者书中是以IDLE运行写的代码。这里你可以将下面代码存为py程序尝试一下。
def factorial(n):
'''returns n!'''
return if n < else n * factorial(n-) print(factorial())
你可以尝试自己编写一段(阶乘)的函数。看看如果运行条件发生变化,两段程序运行时间有没有差异。
4、高阶函数(第5.2节)
这一节中作者举了一个按照结尾字符来排序的例子。
fruits = ['strawberry', 'fig', 'apple', 'cherry', 'raspberry', 'banana']
a = sorted(fruits, key=len)
print(a) def reverse(word):
return word[::-] b = sorted(fruits, key=reverse)
print(b)
5、变量及函数命名(第8.1节)
这一节阐述了一个重要的观念变化。“变量是标注,而不是盒子。如果你不知道引用式变量是什么,可以像这样对别人解释别名。”
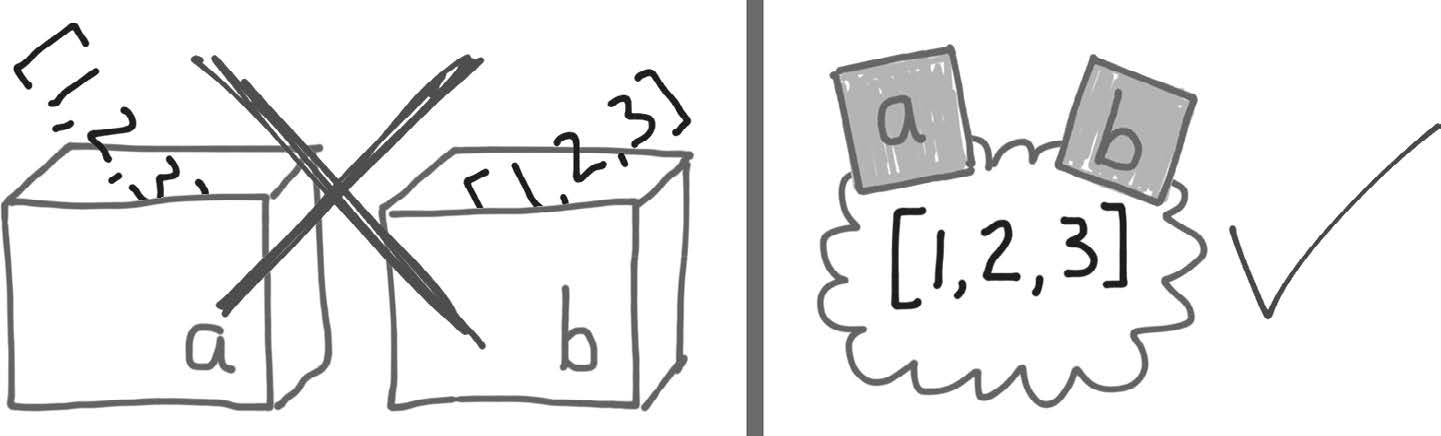
在左图中,人们认为a和b是两个盒子。而在引用式变量中,我们认为a和b的值相等,a也是b。下面的代码你可以看到alex虽然值和charle相等。
但是“alex is not charles”返回了真值(True)。
>>> charles = {'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles .
>>> lewis is charles
True
>>> id(charles), id(lewis) .
(4300473992, 4300473992)
>>> lewis['balance'] = 950 .
>>> charles
{'name': 'Charles L. Dodgson', 'balance': 950, 'born': 1832}
>>> charles = {'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles
>>> alex = {'name': 'Charles L. Dodgson', 'born': 1832, 'balance': 950} .
>>> alex == charles .
True
>>> alex is not charles .
True
6、装饰器(第7.1节、第21.2节)
书中是这样定义装饰器的。“装饰器的一大特性是,能把被装饰的函数替换成其他函数。第二个特性是,装饰器在加载模块时立即执行。”
这个概念还是不很明白,但是通过书中的例子感觉更明白了一些。在需要提前导入时运行的内容,就可以提前导入了。例如GUI开发时。
导入时和运行时是有区别的。
此外,变量是有作用域的,Python 不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量。
registry = []
def register(func):
print('running register(%s)' % func)
registry.append(func)
return func @register
def f1():
print('running f1()') @register
def f2():
print('running f2()') def f3():
print('running f3()') def main():
print('running main()')
print('registry ->', registry)
f1()
f2()
f3() if __name__=='__main__':
main()
#猜一猜结果会是什么?b的值能正确输出吗?能的话是几?
b = 6
def f2(a):
print(a)
print(b)
b = 9 f2(3)
#如果你想要让b输出为6,那么就要global声明
b = 6
def f3(a):
global b
print(a)
print(b)
b = 9 f3(3)
#如果下一行再来一个f3(3),输出会是多少?
# f3(3)
7、和硬件打交道
你了解的Python都能干什么呢?科学计算、爬虫、做web站点?在书里面搜索一下“from dis import dis”、“pingo.io”。
看看吧,python还可以和汇编、Raspberry Pi硬件进行交互。
8、观察python内部执行的网站
有的时候是不是不知道python内部到底是如何赋值的,你可以将代码输入下面网站,就可以看到了。
http://pythontutor.com/
0x05:给新手的建议
我也是个新手,这些建议记录在这里:多在Github找一些代码,不只是复制粘贴,要自己敲一遍,在python shell中执行试试。
将代码中不懂的地方自行搜索,通过加注释深入了解,然后找机会用一用。
多看看作者在前言、小结里面提到的网站。
最后结合自己的兴趣和工作实际,找个项目做一做。
0x06:书中提到的一些词汇和有用的网站
1、语法糖(Syntactic Sugar),也叫糖衣语法,是英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语。指的是,在计算机语言中添加某种语法,这种语法能使程序员更方便的使用语言开发程序,同时增强程序代码的可读性,避免出错的机会;但是这种语法对语言的功能并没有影响。
2、Python语言动画
http://pythontutor.com/
0x07:后续学习
1、另一个图灵小伙伴关于本书的笔记。 里面有本书大部分章节的提要介绍。想要深入学习时,从任一章开始,深入学习即可。
2、Python之美微信公众号。
3、申龙斌的零基础学编程系列:有小例子,挺有趣的
4、父与子的编程之旅
5、shell里面输入import this:多看看python之禅。
0x08:Python新手该看什么书
我看的这本《笨办法学Python》,基本上以养成编程习惯为主要目的。
《Python基础教程》第二版这本也不错。
最后分享一点,不要轻易吹牛自己python很熟练,时刻记得什么是熟练的定义,请参考创宇知道的技能表中“熟练的定义”小节:
http://blog.knownsec.com/Knownsec_RD_Checklist/v3.0.html
[读书笔记]流畅的Python(Fluent Python)的更多相关文章
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- 【Todo】【读书笔记】机器学习实战(Python版)
还是把这本书的读书笔记,单独拎出来吧,因为内容比较多. P38. Logistic 回归. 觉得还蛮实用的.囫囵吞枣看的.要细看.
- 《流畅的python》读书笔记,第一章:python数据模型
这本书上来就讲了魔法方法,也叫双下方法.特殊方法,通过两个例子对让读者了解了双下方法的用法,更重要的是,让我一窥Python的语言风格和给使用者的自由度. 第一个例子:一摞Python风格的纸牌: i ...
- python读书笔记-《A Byte of Python》中文第三版后半部分
编辑器:windows,linux 不要用notepad,缩进糟糕 -------------- 5.18缩进 同一层次的语句必须有相同的缩进.每一组这样的语句称为一个块. i = 5 2 prin ...
- 流畅的Python (Fluent Python) —— 第二部分01
2.1 内置序列类型概览 Python 标准库用 C 实现了丰富的序列类型,列举如下. 容器序列 list. tuple 和 collections.deque 这些序列能存放不同类型的数据. 扁平序 ...
- 流畅的Python (Fluent Python) —— 第一部分
Python 最好的品质之一是一致性. 魔术方法(magic method)是特殊方法的昵称.特殊方法也叫双下方法. 1.1 一摞Python风格的纸牌 import collections Card ...
- 流畅的Python (Fluent Python) —— 前言
本书重点: 这本书并不是一本完备的 Python 使用手册,而是会强调 Python 作为编程语言独有的特性,这些特性或者是只有 Python 才具备的,或者是在其他大众语言里很少见的. Python ...
- Web Scraping with Python读书笔记及思考
Web Scraping with Python读书笔记 标签(空格分隔): web scraping ,python 做数据抓取一定一定要明确:抓取\解析数据不是目的,目的是对数据的利用 一般的数据 ...
- 读书笔记汇总 --- 用Python写网络爬虫
本系列记录并分享:学习利用Python写网络爬虫的过程. 书目信息 Link 书名: 用Python写网络爬虫 作者: [澳]理查德 劳森(Richard Lawson) 原版名称: web scra ...
随机推荐
- python_OS 模块
os模块 用于提供系统级别的操作 os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目 ...
- viva correction statements
* List of amendments| No. | Location | Amendments ...
- LeetCode(169)Majority Element
题目 Given an array of size n, find the majority element. The majority element is the element that app ...
- Linux常用命令大全--有关磁盘空间的命令
1.mount 命令的功能是挂载文件系统,可以挂载硬盘.光盘.软盘,也可以挂载NFS网络文件系统 mount -t 设备类型 存放目录 mount IP地址:/所提供的目录 存放目录 (无) 不加任何 ...
- No unique bean of type..... Unsatisfied dependency of type
比如在XXXServiceImpl里面写了aa()方法给别的地方调用 但是自己又调用了自己 在开头写了 @Autowired Private XXX xxx; xxx.aa(); 这样重复调用自己的b ...
- MySQL索引与Index Condition Pushdown(二)
实验 先从一个简单的实验开始直观认识ICP的作用. 安装数据库 首先需要安装一个支持ICP的MariaDB或MySQL数据库.我使用的是MariaDB 5.5.34,如果是使用MySQL则需要5.6版 ...
- 2. TypeScript笔记
1. 安装node.js之后 需要测试npm命令 2.命令正常安装TypeScript 3.安装Egret egret 命令
- hdu 1565 状态压缩dp
#include<stdio.h> #include<string.h> int Max(int a,int b) { return a>b?a:b; } int dp] ...
- Tsinghua OJ Zuma
Description Let's play the game Zuma! There are a sequence of beads on a track at the right beginnin ...
- 莫队乱搞--BZOJ2038: [2009国家集训队]小Z的袜子(hose)
$n \leq 50000$的$\leq 50000$的数字序列,$m \leq 50000$个询问,每次问一个区间中随机拿两次(不放回)拿到相同数字的概率,以既约分数形式输出. 莫队入门.把询问按“ ...