【Tair】淘宝分布式NOSQL框架:Tair
Tair是淘宝的一个开源项目,它是一个分布式的key/value结构数据的解决方案。
一、基本组成
作为一个分布式系统,Tair由一个中心控制节点(config server)和一系列的服务节点(data server)组成,
1、config server
config server 负责管理所有的data server,并维护data server的状态信息;为了保证高可用(High Available),config server可通过hearbeat 以一主一备形式提供服务
client 和 config server的交互主要是为了获取数据分布的对照表,当client启动时获取到对照表后,会cache这张表,然后通过查这张表决定数据存储的节点,所以请求不需要和config server交互,这使得Tair对外的服务不依赖configserver,所以它不是传统意义上的中心节点,也并不会成为集群的瓶颈。
config server维护的对照表有一个版本号,每次新生成表,该版本号都会增加。当有data server状态发生变化(比如新增节点或者有节点不可用了)时,configserver会根据当前可用的节点重新生成对照表,并通过数据节点的心跳,将新表同步给data server。当client请求data server时,后者每次都会将自己的对照表的版本号放入response中返回给客client,client接收到response后,会将data server返回的版本号和自己的版本号比较,如果不相同,则主动和config server通信,请求新的对照表。
这使得在正常的情况下,client不需要和configserver通信,即使config server不可用了,也不会对整个集群的服务造成大的影响。有了config server,client不需要配置data server列表,也不需要处理节点的的状态变化,这使得Tair对最终用户来说使用和配置都很简单。
2、data server
data server 对外提供各种数据服务,并以心跳的形式将自身状况汇报给config server;所有的 data server 地位都是等价的。
二、存储引擎
tair 分为持久化和非持久化两种使用方式:
- 非持久化的 tair 可以看成是一个分布式缓存;
- 持久化的 tair 将数据存放于磁盘中,为了解决磁盘损坏导致数据丢失,tair 可以配置数据的备份数目。tair 自动将一份数据的不同备份放到不同的主机上,当有主机发生异常,无法正常提供服务的时候,其余的备份会继续提供服务。
三、分布式策略
1、tair 的分布采用的是一致性哈希算法
对于所有的key,分到Q个桶中,桶是负载均衡和数据迁移的基本单位。config server 根据一定的策略把每个桶指派到不同的data server上,因为数据按照key做hash算法,所以可以认为每个桶中的数据基本是平衡的,保证了桶分布的均衡性, 就保证了数据分布的均衡性。
具体说,首先计算Hash(key),得到key所对应的bucket,然后再去config server查找该bucket对应的data server,再与相应的data server进行通信。也就是说,config server维护了一张由bucket映射到data server的对照表,比如:

bucket data server
0 192.168.10.1
1 192.168.10.2
2 192.168.10.1
3 192.168.10.2
4 192.168.10.1
5 192.168.10.2
这里共6个bucket,由两台机器负责,每台机器负责3个bucket。客户端将key hash后,对6取模,找到负责的数据节点,然后和其直接通信。表的大小(行数)通常会远大于集群的节点数,这和consistent hash中的虚拟节点很相似。
假设我们加入了一台新的机器——192.168.10.3,Tair会自动调整对照表,将部分bucket交由新的节点负责,比如新的表很可能类似下表:
0 192.168.10.1
1 192.168.10.2
2 192.168.10.1
3 192.168.10.2
4 192.168.10.3
5 192.168.10.3
在老的表中,每个节点负责3个桶,当扩容后,每个节点将负责2个桶,数据被均衡的分布到所有节点上。
2、复制功能保证高可用
为了增强数据的安全性,Tair支持配置数据的备份数(COPY_COUNT)。比如你可以配置备份数为3,则每个bucket都会写在不同的3台机器上。当数据写入一个节点(通常我们称其为主节点)后,主节点会根据对照表自动将数据写入到其他备份节点,整个过程对用户是透明的。
如果有多个备份,那么对照表将包含多列,比如备份是为3,则表有4列,后面的3列都是数据存储的节点。
3、扩容和容灾的数据转移
当有新节点加入或者有节点不可用时,config server会根据当前可用的节点,重新build一张对照表。数据节点同步到新的对照表时,会自动将在新表中不由自己负责的数据迁移到新的目标节点。迁移完成后,客户端可以从config server同步到新的对照表,完成扩容或者容灾过程。整个过程对用户是透明的,服务不中断。
3.1、扩容
当系统增加data server的时候,config server根据负载,协调data server将他们控制的部分桶迁移到新的data server上,迁移完成后调整路由。
注意:
不管是发生故障还是扩容,每次路由的变更,config server都会将新的配置信息推给data server。在client访问data server的时候,会发送client缓存的路由表的版本号,如果data server发现client的版本号过旧,则会通知client去config server取一次新的路由表。如果client访问某台data server 发生了不可达的情况(该 data server可能宕机了),客户端会主动去config server取新的路由表。
3.2、迁移
当发生迁移的时候,假设data server A 要把 桶 3,4,5 迁移给data server B。因为迁移完成前,client的路由表没有变化,因此对 3, 4, 5 的访问请求都会路由到A。现在假设 3还没迁移,4 正在迁移中,5已经迁移完成,那么:
- 如果是对3的访问,则没什么特别,跟以前一样;
- 如果是对5的访问,则A会把该请求转发给B,并且将B的返回结果返回给client;
- 如果是对4的访问,在A处理,同时如果是对4的修改操作,会记录修改log,桶4迁移完成的时候,还要把log发送到B,在B上应用这些log,最终A B上对于桶4来说,数据完全一致才是真正的迁移完成;
4、生成对照表的策略
- 负载均衡优先,config server会尽量的把桶均匀的分布到各个data server上,所谓尽量是指在不违背下面的原则的条件下尽量负载均衡:每个桶必须有COPY_COUNT份数据; 一个桶的各份数据不能在同一台主机上;
- 位置安全优先,一般我们通过控制 _pos_mask(Tair的一个配置项) 来使得不同的机房具有不同的位置信息,一个桶的各份数据不能都位于相同的一个位置(不在同一个机房)。
位置优先策略还有一个问题,假如只有两个机房,机房1中有100台data server,机房2中只有1台data server。这个时候,机房2中data server的压力必然会非常大,于是这里产生了一个控制参数 _build_diff_ratio(参见安装部署文档),当机房差异比率大于这个配置值时,config server也不再build新表,机房差异比率是如何计出来的呢?首先找到机器最多的机房,不妨设使RA,data server数量是SA,那么其余的data server的数量记做SB,则机房差异比率=|SA – SB|/SA,因为一般我们线上系统配置的COPY_COUNT=3,在这个情况下,不妨设只有两个机房RA和RB,那么两个机房什么样的data server数量是均衡的范围呢? 当差异比率小于 0.5的时候是可以做到各台data server负载都完全均衡的。这里有一点要注意,假设RA机房有机器6台,RB有机器3台,那么差异比率 = 6 – 3 / 6 = 0.5,这个时候如果进行扩容,在机房A增加一台data server,扩容后的差异比率 = 7 – 3 / 7 = 0.57,也就是说,只在机器数多的机房增加data server会扩大差异比率。如果我们的_build_diff_ratio配置值是0.5,那么进行这种扩容后,config server会拒绝再继续build新表。
四、version特性
Tair中的每个数据都包含版本号,版本号在每次更新后都会递增。这个特性可以帮助防止数据的并发更新导致的问题。
Version改变的逻辑如下:
- 如果put新数据且没有设置版本号,会自动将版本设置成1;
- 如果put是更新老数据且没有版本号,或者put传来的参数版本与当前版本一致,版本号自增1;
- 如果put是更新老数据且传来的参数版本与当前版本不一致,更新失败,返回VersionError;
- put时传入的version参数为0,则强制更新成功,版本号自增1。
version分布式锁
Tair中存在该key,则认为该key所代表的锁已被lock;不存在该key,在未加锁。操作过程和上面相似。业务方可以在put的时候增加expire,已避免该锁被长期锁住。
当然业务方在选择这种策略的情况下需要考虑并处理Tair宕机带来的锁丢失的情况。
五、plugin支持
Tair还内置了一个插件容器,可以支持热插拔插件。
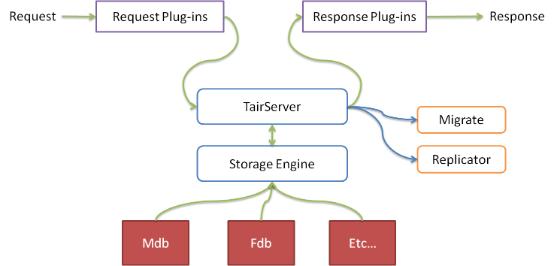
插件由config server配置,config server会将插件配置同步给各个数据节点,数据节点会负责加载/卸载相应的插件。
插件分为request和response两类,可以分别在request和response时执行相应的操作,比如在put前检查用户的quota信息等。
插件容器也让Tair在功能方便具有更好的灵活性。
【Tair】淘宝分布式NOSQL框架:Tair的更多相关文章
- 淘宝分布式NOSQL框架:Tair
Tair 分布式K-V存储方案 tair 是淘宝的一个开源项目,它是一个分布式的key/value结构数据的解决方案. 作为一个分布式系统,Tair由一个中心控制节点(config server)和一 ...
- 淘宝分布式 key/value 存储引擎Tair安装部署过程及Javaclient測试一例
文件夹 1. 简单介绍 2. 安装步骤及问题小记 3. 部署配置 4. Javaclient測试 5. 參考资料 声明 1. 以下的安装部署基于Linux系统环境:centos 6(64位),其他Li ...
- 淘宝分布式文件存储系统:TFS
TFS ——分布式文件存储系统 TFS(Taobao File System)是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问. ...
- [KISSY5系列]淘宝全终端框架 KISSY 5--从零开始使用
KISSY 是淘宝一个开源的 JavaScript 库,包含的组件有:日历.图片放大镜.卡片切换.弹出窗口.输入建议等 一.简介 KISSY 是一款跨终端.模块化.高性能.使用简单的 JavaScri ...
- 淘宝分布式配置管理服务Diamond
转载:http://blog.csdn.net/kevinlynx/article/details/40017109 在一个分布式环境中,同类型的服务往往会部署很多实例.这些实例使用了一些配置,为了更 ...
- 淘宝(taobao)HSF框架
一.背景 随着网站访问量增加,仅仅靠增加机器已不能满足系统的要求,于是需要对应用系统进行垂直拆分和水平拆分.在拆分之后,各个被拆分的模块如何通信?如何保证 性能?如何保证各个应用都以同样的方式交互?这 ...
- 淘宝开源任务调度框架tbschedule
背景 分布式任务调度是非常常见的一种应用场景,一般对可用性和性能要求不高的任务,采用单点即可,例如linux的crontab,spring的quarz,但是如果要求部署多个节点,达到高可用的效果,上面 ...
- 淘宝tairKV分布式
Tair是什么 Tair是由淘宝开发的key/value方案,系统默认支持基于内存和文件的存储引擎,对应于通常我们所说的缓存和持久化存储,这里可以获取更多关于tair的信息,淘宝团队介绍,Tair在淘 ...
- 淘宝可伸缩高性能互联网架构HSF(转)
文章转自http://blog.csdn.net/hpf911/article/details/14165865 时间过得很快,来淘宝已经两个月了,在这两个月的时间里,自己也感受颇深.下面就结合淘宝目 ...
随机推荐
- centos7 host修改
首先要说明,hostname和hosts文件没有必然联系,有不明白的同学可以先自行查阅资料了解hostname和hosts文件的关系.这里简要说明一下. hosts文件是dns服务的前身,网络刚开始出 ...
- Elasticsearch的Java API做类似SQL的group by聚合。
https://www.cnblogs.com/kangoroo/p/8033955.html
- Codeforces 631D Messenger【KMP】
题意: 给定由字符串块(字符及连续出现的个数)组成的字符串t,s,求t串中有多少个s. 分析: KMP 这题唯一需要思考的地方就是如何处理字符串块.第一想到是把他们都展开然后进行KMP,可是展开后实在 ...
- hibernate_Criteria_分页_去重
触发原因:实体类间存在一对多关系,并且在一这方加载多的时候用的加载模式是eager. 解决方法:1.非分页:criteria.setResultTransformer(Criteria.DISTINC ...
- Servlet表单数据处理
以下内容引用自http://wiki.jikexueyuan.com/project/servlet/form-data.html: 当需要从浏览器到Web服务器传递一些信息并最终传回到后台程序时,一 ...
- Errors running builder 'JavaScript Validator' on
eclipse编译提示Errors running builder 'JavaScript Validator' on 解决方法见下图 去掉 'JavaScript Validator' 即可
- Zookeeper学习 & Paxos
首先,Zookeeper是基于Paxos来进行分布式选举管理的,Paxos的内容可以参考我另一篇文章:http://www.cnblogs.com/charlesblc/p/6037004.html ...
- Mysql中错误日志、binlog日志、查询日志、慢查询日志简单介绍
前言 数据库的日志是帮助数据库管理员,追踪分析数据库以前发生的各种事件的有力根据.mysql中提供了错误日志.binlog日志(二进制日志).查处日志.慢查询日志.在此,我力求解决下面问题:各个日志的 ...
- Django学习系列之Form表单结合ajax
Forms结合ajax Forms的验证流程: 定义用户输入规则的类,字段的值必须等于html中name属性的值(pwd= forms.CharField(required=True)=<i ...
- 010 ACL
Router>en Router#config t Enter configuration commands, one per line. End with CNTL/Z. Router(co ...