Learning to Rank之Ranking SVM 简介
排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank简介)。LTR有三种主要的方法:PointWise,PairWise,ListWise。Ranking SVM算法是PointWise方法的一种,由R. Herbrich等人在2000提出, T. Joachims介绍了一种基于用户Clickthrough数据使用Ranking SVM来进行排序的方法(SIGKDD, 2002)。
1. Ranking SVM的主要思想
Ranking SVM是一种Pointwise的排序算法, 给定查询q, 文档d1>d2>d3(亦即文档d1比文档d2相关, 文档d2比文档d3相关, x1, x2, x3分别是d1, d2, d3的特征)。为了使用机器学习的方法进行排序,我们将排序转化为一个分类问题。我们定义新的训练样本, 令x1-x2, x1-x3, x2-x3为正样本,令x2-x1, x3-x1, x3-x2为负样本, 然后训练一个二分类器(支持向量机)来对这些新的训练样本进行分类,如下图所示:
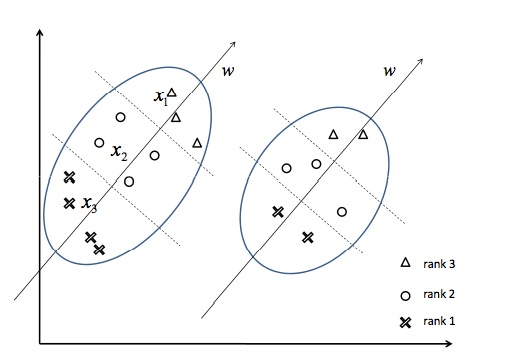
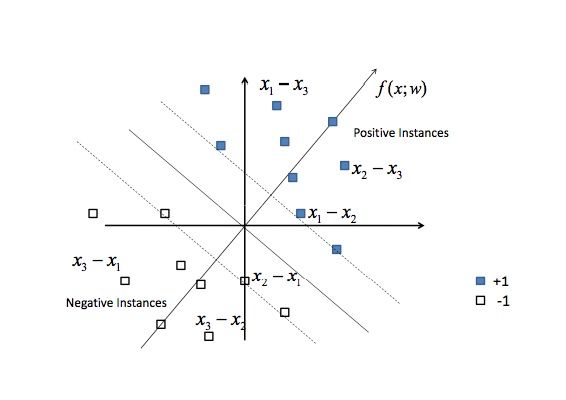
左图中每个椭圆代表一个查询, 椭圆内的点代表那些要计算和该查询的相关度的文档, 三角代表很相关, 圆圈代表一般相关, 叉号代表不相关。我们把左图中的单个的文档转换成右图中的文档对(di, dj), 实心方块代表正样本, 亦即di>dj, 空心方块代表负样本, 亦即di<dj。
2. Ranking SVM
将排序问题转化为分类问题之后, 我们就可以使用常用的机器学习方法解决该问题。 Ranking SVM使用SVM来进行分类:
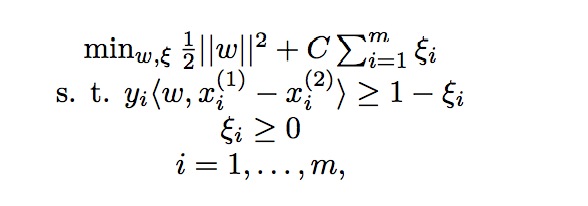
其中w为参数向量, x为文档的特征,y为文档对之间的相对相关性, ξ为松弛变量。
3. 使用Clickthrough数据作为训练数据
T. Joachims提出了一种非常巧妙的方法, 来使用Clickthrough数据作为Ranking SVM的训练数据。
假设给定一个查询"Support Vector Machine", 搜索引擎的返回结果为

其中1, 3, 7三个结果被用户点击过, 其他的则没有。因为返回的结果本身是有序的, 用户更倾向于点击排在前面的结果, 所以用户的点击行为本身是有偏(Bias)的。为了从有偏的点击数据中获得文档的相关信息, 我们认为: 如果一个用户点击了a而没有点击b, 但是b在排序结果中的位置高于a, 则a>b。
所以上面的用户点击行为意味着: 3>2, 7>2, 7>4, 7>5, 7>6。
4. Ranking SVM的开源实现
H. Joachims的主页上有Ranking SVM的开源实现。
数据的格式与LIBSVM的输入格式比较相似, 第一列代表文档的相关性, 值越大代表越相关, 第二列代表查询, 后面的代表特征
3 qid:1 1:1 2:1 3:0 4:0.2 5:0 # 1A
2 qid:1 1:0 2:0 3:1 4:0.1 5:1 # 1B
1 qid:1 1:0 2:1 3:0 4:0.4 5:0 # 1C
1 qid:1 1:0 2:0 3:1 4:0.3 5:0 # 1D
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2A
2 qid:2 1:1 2:0 3:1 4:0.4 5:0 # 2B
1 qid:2 1:0 2:0 3:1 4:0.1 5:0 # 2C
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2D
2 qid:3 1:0 2:0 3:1 4:0.1 5:1 # 3A
3 qid:3 1:1 2:1 3:0 4:0.3 5:0 # 3B
4 qid:3 1:1 2:0 3:0 4:0.4 5:1 # 3C
1 qid:3 1:0 2:1 3:1 4:0.5 5:0 # 3D
训练模型和对测试数据进行排序的代码分别为:
./svm_rank_learn path/to/train path/to/model
./svm_classify path/to/test path/to/model path/to/rank_result
参考文献:
[1]. R. Herbrich, T. Graepel, and K. Obermayer. Large margin rank boundaries for ordinal regression. In Advances in Large Margin Classifiers, 2000.
[2]. T. Joachims. Optimizing Search Engines using Clickthrough Data. SIGKDD, 2002.
[3]. Hang Li. A Short Introduction to Learning to Rank.
[4]. Tie-yan Liu. Learning to Rank for Information Retrieval.
[5]. Learning to Rank简介
Learning to Rank之Ranking SVM 简介的更多相关文章
- 【机器学习】Learning to Rank之Ranking SVM 简介
Learning to Rank之Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning t ...
- Kemaswill 机器学习 数据挖掘 推荐系统 Ranking SVM 简介
Ranking SVM 简介 排序一直是信息检索的核心问题之一,Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Le ...
- Learning to Rank之RankNet算法简介
排序一直是信息检索的核心问题之一, Learning to Rank(简称LTR)用机器学习的思想来解决排序问题(关于Learning to Rank的简介请见我的博文Learning to Rank ...
- Robust Tracking via Weakly Supervised Ranking SVM
参考文献:Yancheng Bai and Ming Tang. Robust Tracking via Weakly Supervised Ranking SVM Abstract 通常的算法:ut ...
- [Machine Learning] Learning to rank算法简介
声明:以下内容根据潘的博客和crackcell's dustbin进行整理,尊重原著,向两位作者致谢! 1 现有的排序模型 排序(Ranking)一直是信息检索的核心研究问题,有大量的成熟的方法,主要 ...
- Learning to Rank 简介
转自:http://www.cnblogs.com/kemaswill/archive/2013/06/01/3109497.html,感谢分享! 本文将对L2R做一个比较深入的介绍,主要参考了刘铁岩 ...
- 【机器学习】Learning to Rank 简介
Learning to Rank 简介 去年实习时,因为项目需要,接触了一下Learning to Rank(以下简称L2R),感觉很有意思,也有很大的应用价值.L2R将机器学习的技术很好的应用到了排 ...
- Learning to Rank简介
Learning to Rank是采用机器学习算法,通过训练模型来解决排序问题,在Information Retrieval,Natural Language Processing,Data Mini ...
- Learning to Rank算法介绍:RankSVM 和 IR SVM
之前的博客:http://www.cnblogs.com/bentuwuying/p/6681943.html中简单介绍了Learning to Rank的基本原理,也讲到了Learning to R ...
随机推荐
- Linux netstat 命令
1. netstat命令用于显示系统的网络信息,包括网络连接 .路由表 .接口状态2. 一般我们使用 netstat 来查看本机开启了哪些端口,查看有哪些客户端连接 常见用法如下: [root@loc ...
- Mybatis中的foreach
<delete id="deleteByParam"> DELETE FROM YZ_SECURITIES_CURRENCY WHERE ID IN <forea ...
- MySQL 分组后取每组前N条数据
与oracle的 rownumber() over(partition by xxx order by xxx )语句类似,即:对表分组后排序 创建测试emp表 1 2 3 4 5 6 7 8 9 ...
- 图片asp木马的制作方法[转]
一个网站里面除了asp文件,再就数图片文件最多了,它让我们的网页"美丽动人"嘻嘻,但是你有没有想到过这里面暗藏的杀机,图片也可以是asp木马. 一个网站里面除了asp文件,再就数图 ...
- 【ecshop】 完全清除版权信息
完整去掉版权和后门的方法: 去ECSHOP版权,去官方后门,完整版 作者:阿牛 ECShop是一款B2C独立网店系统,适合企业及个人快速构建个性化网上商店.系统开源但不免费,是基于PHP语言及MYSQ ...
- linux常用的一些访问目录
救命三键(Ctrl+Alt+Delete) /var/log 如果是网络服务的问题时,请到 这个目录里头去查阅一下 log file (登录档): /etc/rc.local 修改挂载 ...
- 邮件欺诈与SPF防御
一.邮件欺诈: 众所周知,现在邮件的发件人是自己生成的,其实发件域名也是可以自己生成的.例如,A得知B组织的邮箱域(前提是B组织邮箱域没有配置SPF),那么A可以自己起一个邮箱服务器,配置相同的域名. ...
- linux显示文件列表命令ls,使用ls --help列出所有命令参数
ls命令的相关参数 在提示符下输入ls --help ,屏幕会显示该命令的使用格式及参数信息: 先介绍一下ls命令的主要参数: -a 列出目录下的所有文件,包括以 . 开头的隐含文件. -A 显示除 ...
- java8新增的日期时间包
Clock clock=Clock.systemUTC(); System.out.println("当前时刻为:"+clock.instant()); System.out.pr ...
- 170705、springboot编程之自定义properties
spring boot使用application.properties默认了很多配置.但需要自己添加一些配置的时候,可以这样用,如下! 在application.properties文件中增加信息 1 ...