memcached内存管理机制分析
memached是高性能分布式内存对象系统,通过在内存中存储数据对象来减少对磁盘的数据读取次数,提高服务速度。
从业务需求出发。我们通过一条命令(如set)将一条键值对(key,value)插入memcached后,需要:
1、对该键值数据的高效索引;
(memcached通过哈希表来对键值数据进行管理,具体的实现中采用链接法来处理hash冲突问题。)
2、系统可能会频繁的创建新数据和删除旧数据,需要高效的内存管理;
(最简单的思路是来了新的数据就malloc内存,将新数据保存在这段新分配的内存中,当数据要被删除时就把这段内存free掉。但是频繁的malloc和free将会导致系统的内存碎片 问题,加重系统内存管理的负担。同时malloc和free作为系统调用,在时间方面也存在一定开销。Memcached的解决方式是创建内存池来管理内存分配,具体实现思路是采用Slab Allocator作为内存分配器。)
3、系统应该能够自行删除长期不使用的缓存数据。
( memcached给每个数据记录过期时间,并将同一个slab class的所有数据通过LRU算法进行组织,当插入新数据时通过检查LRU链表对超时的旧数据进行删除。)
数据结构
item:为键值数据的实际储存结构。item主要由两个部分组成:
第一个部分是公共属性部分,包括连接其它 item 的指针 (next,prev,h_next),还有最近访问时间(time), 过期的时间(exptime)等,结构长度固定;
第二部分是item的数据部分,由 CAS, key, suffix, value 组成,由于实际的键值数据长度不确定,因此该部分的结构长度不固定。
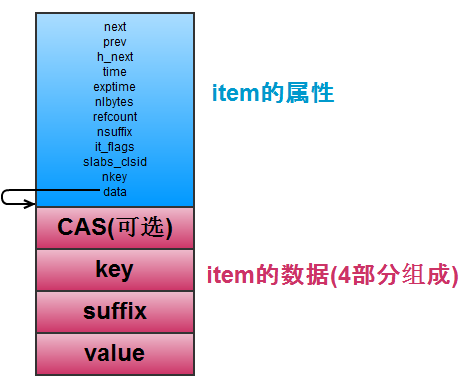
Chunk:由申请的连续内存块平均切分而成,比如申请的1M连续内存块,可以被切分成11个88bytes的chunk内存小块。Chunk是实际分配给item的内存空间,Memcached会维护多个不同大小的chunk内存块,若某个item需要100bytes的内存空间,系统将会取出一个最接近且大于100bytes大小的chunk分配给该item作为内存空间。
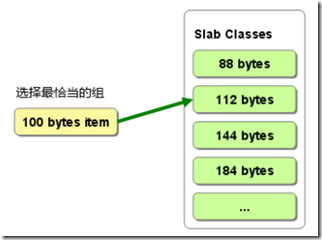
比如:item公共属性部分需要48bytes内存空间,数据部分需要52bytes内存空间,该item一共需要100bytes连续内存空间。该memcached分别维护了88bytes、112 bytes、144 bytes和184 bytes大小的chunk块群。最接近且大于该item所需内存大小的是size为112bytes的chunk块。因此我们取出一个尚未被使用的112 bytes 的chunk块,并将该item中的数据保存到该chunk的内存空间中。此时该chunk中将有12bytes剩余内存将作为碎片被暂时浪费。
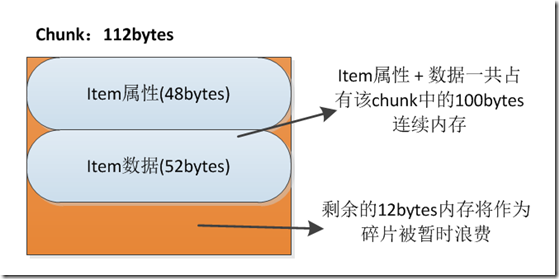
Slab Class:管理特定大小的 chunk 的集合。Memcached每次默认分配的一个连续内存块为1M大小,它们被切分为不同大小的chunk。但是不同chunk的需求量不同,有的情况下某些大小的chunk只需一个连续内存块切分的数量即可满足业务需要,但有的大小的chunk需求量比较大,需要分配更多的连续内存块来进行切分。这些切分为相同大小的chunk块群,都由对应的slab class进行管理。
memcached会指定一个最小的chunk大小,同时设置一个增长因子。系统依次创建管理随增长因子增长且保持字节对齐的chunk大小的slab class。比如最小chunk大小为88bytes,增长因子为1.25,则系统将会分别创建管理88bytes大小、112bytes大小、144bytes大小的chunk的slab class。
typedef struct {
unsigned int size; //该 slabclass 的 chunk 大小
unsigned int perslab; //表示每个 slab 可以切分成多少个 chunk,如果slab为1M,则perslab = 1M/size
void *slots; //回收到的item链表
unsigned int sl_curr; //当前链表中有多少个回收而来的空闲chunk
unsigned int slabs; //该class一共分配了多少chunk
void **slab_list; //list数组用于维护chunk.
unsigned int list_size; /* size of prev array */
unsigned int killing; /* index+1 of dying slab, or zero if none */
size_t requested; /* The number of requested bytes */
} slabclass_t;
内存初始化
Memcached的内存初始化方式分为两种,分别为预分配方式和按需分配方式。Memcached默认采用按需分配方式。
预分配方式,memcached会在启动时通过malloc申请64M的连续内存(可配置),然后memcached根据初始chunk大小和增长因子创建管理不同chunk大小的slab class,每个slab class依次从之前申请的64M内存中获取1个1M的连续内存块,并将该内存块切分为对应大小的chunk块并进行管理,直到申请的内存用完为止。
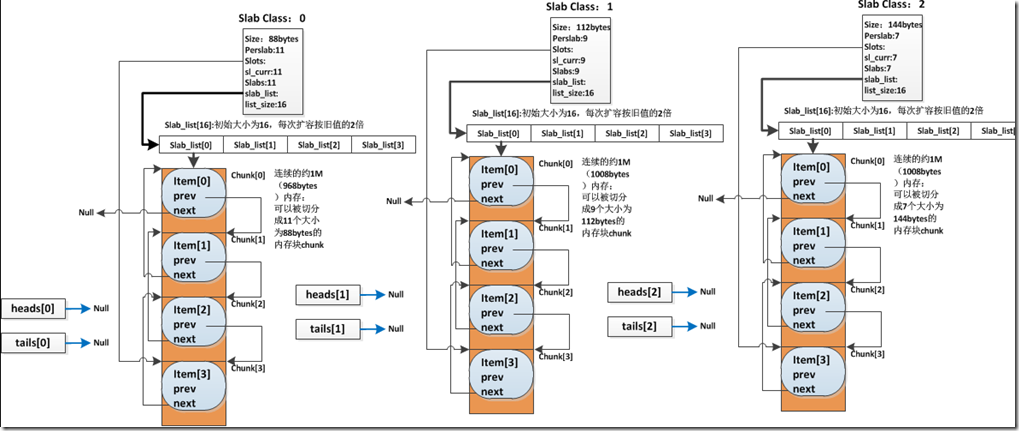
当有实际数据待储存到该slab下的chunk时,Memcached首先会判断该slab是否有过期的item待回收使用,如果没有再判断是否有空闲的chunk,如果还没有,才会给该slab分配1M连续内存。这时slab将会对这块连续内存进行切分chunk管理,并从中取出一个空闲chunk用于储存数据。
按需分配的方式,初始化阶段Memcached只会为每个slab指定对应chunk大小,并不会给slab分配实际内存。
slab内存扩容
预分配初始化中,我们给size为88bytes的slab class分配了一块约为1M的连续内存块,并将其切分为了11915个chunk。但是实际使用中,11915个chunk很可能是不够使用的。如果原有chunk全部被使用后,又有新的数据需要88bytes的chunk内存空间。此时Memcached将会对该slab进行扩容操作。
在slab中存在一个初始大小为16的slab_list数组,用于管理连续内存块。其中预分配的第一个连续内存块被挂载在slab_list[0]上。当第一个连续内存块中chunk不够用时,Memcached将会再次给该slab分配一个大小约为1M的连续内存块,并挂载在slab_list[1]上,并同样将该段连续内存切分为11915个chunk,并将这些新chunk添加到该slab的空闲双向链表中。此时该slab一共管理11915*2个chunk,其中新分配的11915个chunk为空闲chunk。

因为slab_list数组初始大小为16,理论上该slab可以挂载16个这样的连续内存,每个连续内容可切分为11915个chunk,也就是slab能够管理16*11915=190640个chunk。如果190640个chunk都不能满足这个slab的chunk需求,那么Memcached将会对slab_list通过realloc进行扩容,每次扩容的大小为原slab_list的大小的2倍。一次slab_list扩容后,该数组大小为32,将可分配32*11915个chunk。只要系统内存足够,通过slab_list的扩容和分配新的连续内存块,每个slab class可以管理无数个大小相同的chunk。
hash表实现
Memcached的hash表采用链接法实现。hashtable被分成多个桶bucket,每个item通过hash函数确定具体的bucket,然后链接到该bucket上,如果该桶中已存在链接的item(即出现了哈希冲突),则将这个item通过h_next指针形成该bucket下链接的单向链表。图中,item A和item B都被哈希映射到了bucket[1]中,它们通过h_next组织为单向链表,且bucket[1]作为链表表头。

LRU链表
每个slab中都维护了一个LRU链表,来组织该slab中已经被分配的item块,用于记录“最近最少使用”的item信息。其中heads指向链表的头节点,tails指向链表的尾节点。每当有新chunk被使用时,将会将该chunk的item添加到LRU链表头。或者有原使用的item被修改,也会将其从链表中移动到LRU链表头处。通过该机制,保证了链表头部分的的item为新创建或新修改的数据,链表尾item为该slab中储存最久的数据。
Memcached采用了惰性删除的机制,系统不会主动监视item中数据是否过期,而是在get的时候查看该item的时间戳,如果已过期就删除并将该chunk释放到空闲链表中。同时在新数据插入中,Memcached也会优先判断该slab的LRU链表尾部的item节点是否超时,如果超时的话,Memcached也会优先删除并使用已经超时的item的chunk作为新数据的储存空间。
当该slab的LRU链表尾部item节点并未超时,但是slab中无可用chunk,且无法从系统中扩容到新的内存空间时,Memcached将会直接摘取LRU链表中的最后的item,强行删除并将其空间分配给新的数据记录。Memcached可以配置为禁止使用LRU机制,这样的话当该slab中chunk耗尽且分配不到新内存时将会返回错误。
数据存储流程
哈希查找是否存在相同键值-》根据item大小选择slab class-》从过期item或空闲链表中分配item-》加入LRU链表及哈希表
数据删除流程
通过哈希表获取该键值数据item-》从哈希表中移除该item节点-》从LRU链表中移该item节点-》清空item数据并将该chunk重新添加到空闲chunk链表
memcached内存管理机制分析的更多相关文章
- Keil C动态内存管理机制分析及改进(转)
源:Keil C动态内存管理机制分析及改进 Keil C是常用的嵌入式系统编程工具,它通过init_mempool.mallloe.free等函数,提供了动态存储管理等功能.本文通过对init_mem ...
- 分布式缓存系统 Memcached 内存管理机制
在前面slab数据存储部分分析了Memecached中记录数据的具体存储机制,从中可以看到所采用的内存管理机制——slab内存管理,这也正是linux所采用的内存高效管理机制,对于Memchached ...
- 简述 Memcached 内存管理机制原理?
早期的 Memcached 内存管理方式是通过 malloc 的分配的内存,使用完后通过 free 来回收内存,这种方式容易产生内存碎片,并降低操作系统对内存的管理效 率.加重操作系统内存管理器的负担 ...
- Memcached内存管理模型分析
Memcached 是一个高性能的分布式内存对象缓存系统,它通过在内存中缓存数据和对象来减少读取数据库的次数,从而减轻RDBMS的负担,提高服务的速度.提升可扩展性.本文将基于memcached1.4 ...
- 分布式缓存技术memcached学习(三)——memcached内存管理机制
几个重要概念 Slab memcached通过slab机制进行内存的分配和回收,slab是一个内存块,它是memcached一次申请内存的最小单位,.在启动memcached的时候一般会使用参数-m指 ...
- memcached内存管理机制[未整理]
memcached默认采用的是Slab Allocator的机制分配管理内存的,在此之前,内存的分配是通过对所有的记录简单地进行malloc和free来进行的,但这种方式容易造成很多内存碎片,加重操作 ...
- 分布式缓存技术memcached学习系列(三)——memcached内存管理机制
几个重要概念 Slab memcached通过slab机制进行内存的分配和回收,slab是一个内存块,它是memcached一次申请内存的最小单位,.在启动memcached的时候一般会使用参数-m指 ...
- iOS中引用计数内存管理机制分析
在 iOS 中引用计数是内存的管理方式,虽然在 iOS5 版本中,已经支持了自动引用计数管理模式,但理解它的运行方式有助于我们了解程序的运行原理,有助于 debug 程序. 操作系统的内存管理分成堆和 ...
- Keil C动态内存管理机制分析及改进
Keil C是常用的嵌入式系统编程工具,它通过init_mempool.mallloe.free等函数,提供了动态存储管理等功能.本文通过对init_mempool.mallloe和free这3个Ke ...
随机推荐
- crontab 定时执行脚本出错,但手动执行脚本正常
原因: crontab 没有去读环境变量,需要再脚本中手动引入环境变量,可以用source 也可以用export 写死环境变量. 为了定时监控Linux系统CPU.内存.负载的使用情况,写了个Shel ...
- 《F4+2 团队项目需求分析改进》
a.分析<动态的太阳系模型项目需求规格说明书>初稿的不足. 任务概述描述的有些不具体,功能的规定不详细,在此次作业进行了修改. b.参考<构建之法>8.5节功能的定位和优先级, ...
- $.proxy用法详解
jQuery中的$.proxy官方描述为: 描述:接受一个函数,然后返回一个新函数,并且这个新函数始终保持了特定的上下文语境. 官方API: jQuery.proxy( function, conte ...
- Leetcode 50
//1开始我只是按照原来快速幂的思想,当n <0 时,n变成-n,发现当n取-INTMAX时会发生越界的问题,然后在改快速幂代码的时候逐渐了解到快速幂的本质,其实位运算对快速幂来说速度加快不了多 ...
- 使用Spring Loader或者Jrebel实现java 热部署
.其实JRebel和Spring-Loaded就是一个开发环境下的利器,skip build and redeploy process,大大提升了工作效率!而非生产环境的利器...因为线上reload ...
- FindBugs插件的安装与使用
转载:http://www.cnblogs.com/kayfans/archive/2012/06/18/2554022.html 1 什么是FindBugs FindBugs 是一个静态分析工具,它 ...
- MySQL多表关联查询与存储过程
-- **************关联查询(多表查询)**************** -- 需求:查询员工及其所在部门(显示员工姓名,部门名称) -- 1.1 交叉连接查询(不推荐.产生笛卡尔乘积 ...
- gradle基础配置
gradle构建脚本基础 gradle常用命令 //列出项目的所有属性. 这样你就可以看到插件加入的属性以及它们的默认值. gradle properties //列出项目的所有任务 gradle ...
- 【LeetCode 225_数据结构_栈_实现】Implement Stack using Queues
class Stack { public: // Push element x onto stack. void push(int x) { int len = nums.size(); nums.p ...
- 201621123006 《Java程序设计》第6周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图或相关笔记,对面向对象思想进行一个总结. 注1:关键词与内容不求多,但概念之间的联系要清晰 ...