基于R实现k-means法与k-medoids法
k-means法与k-medoids法都是基于距离判别的聚类算法。本文将使用iris数据集,在R语言中实现k-means算法与k-medoids算法。
k-means聚类

首先删去iris中的Species属性,留下剩余4列数值型变量。再利用kmeans()将数据归为3个簇
names(iris)
iris2 <- iris[,-5] #删去species一列
kmeans_result <- kmeans(iris2,3) #将数据归为3个簇
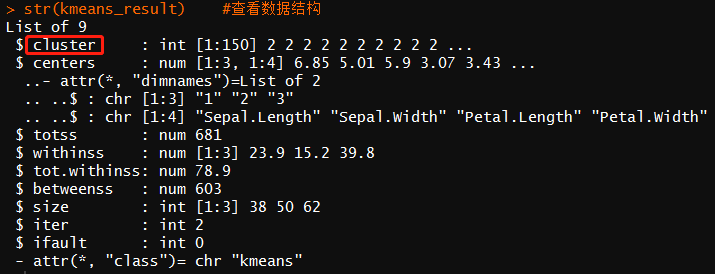
str(kmeans_result) #查看数据结构
table(iris$Species,kmeans_result$cluster) #查看聚类结果和观测值的对比

从聚类结果可看出,'versicolor‘类与'virginica’类之间存在小范围的重叠。有2个versicolor被错误归类为第一类,有14个'virginica’被归为第三类。
plot(iris2[c('Sepal.Length','Sepal.Width')],col=kmeans_result$cluster)
points(kmeans_result$centers[,c('Sepal.Length','Sepal.Width')],col=1:3,pch=10,cex=3)
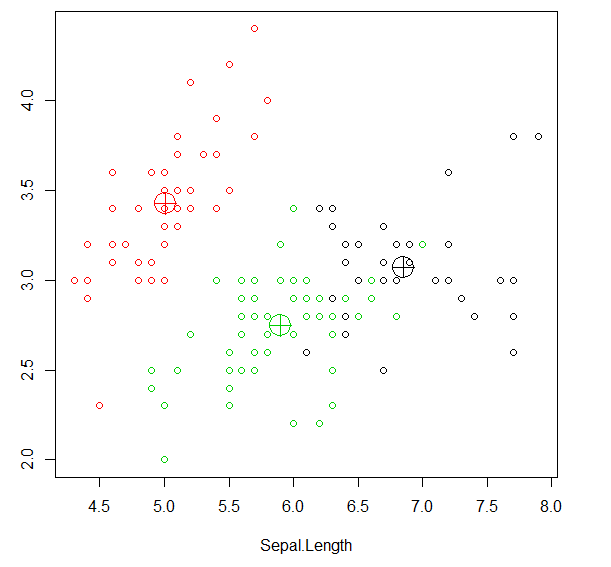
数据集有四个维度,而绘图只用了前两个维度的数据,
图中所示的一些靠近绿色中心的黑点实际在四维空间中更靠近黑色中心
需注意的是多次运行得到的K-means聚类结果可能不同,这是因为初始的簇中心是随机选择的
k-medoids聚类

先使用fpc包中的pamk()实现K-中心聚类,优点是不要求用户输入K的值
#而是自动调用pam()或函数clara()更具最优平均阴影宽度估计的聚类簇个数来划分数据
library(fpc)
pamk.result <- pamk(iris2)
str(pamk.result)
pamk.result$nc #推荐使用两个簇

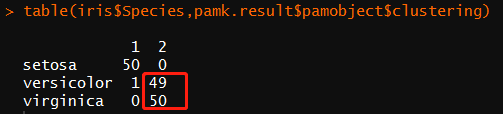
table(iris$Species,pamk.result$pamobject$clustering)

layout(matrix(c(1,2),1,2)) #图形显示为一行两列
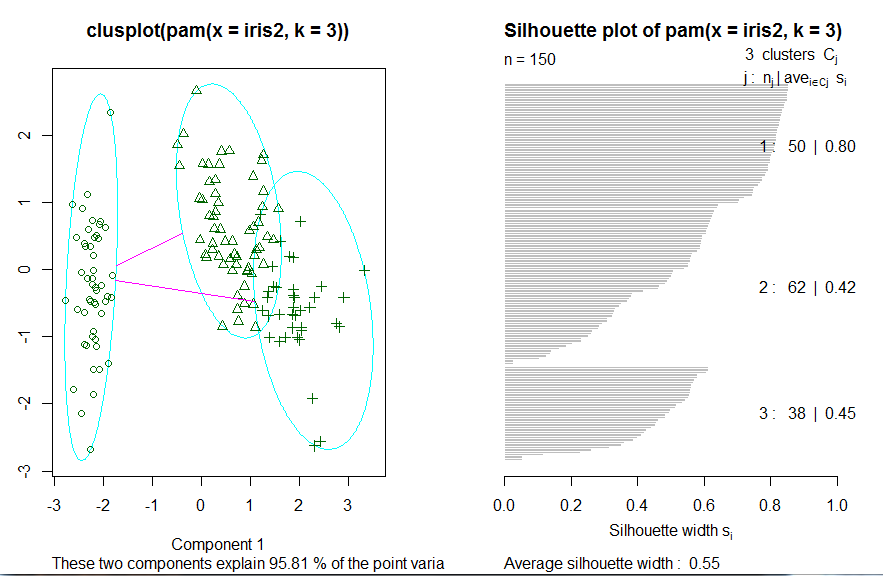
plot(pamk.result$pamobject)
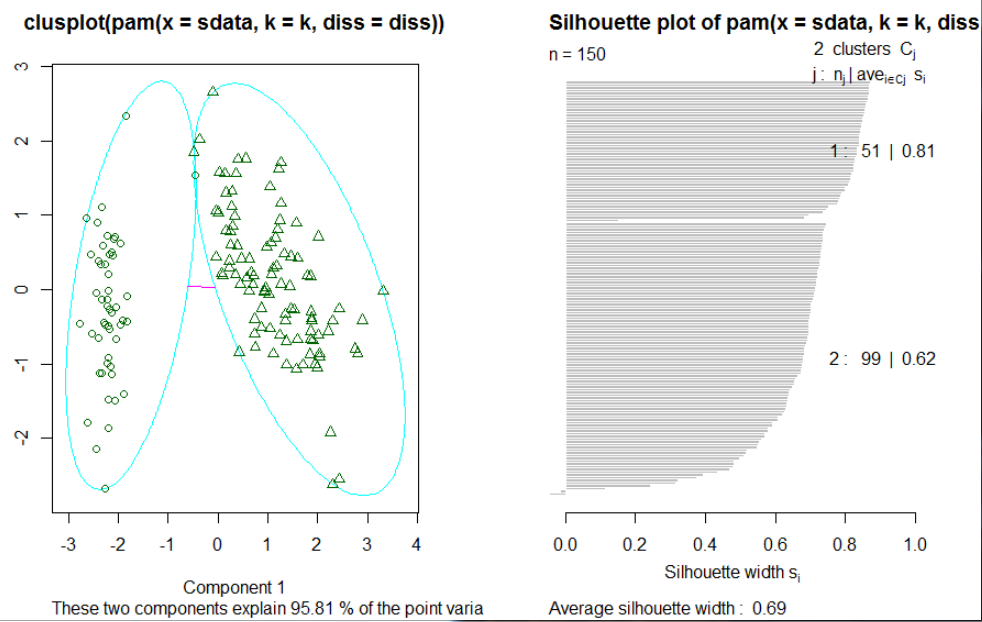
在 上 面 的 例 子 中 , 函 数 pamk() 生 成 了 两 个 簇 : 一 个 是 “ setosa ” , 另 一 个 是 “ versicolor ”
和 “ virgrnica " 的 混 合 。 在 图 6 . 2 中 , 左 边 的 图 像 为 两 个 簇 的 2 维 聚 类 图 像 ( “ clusplot " ) ,
两 个 簇 中 间 的 直 线 表 示 距 离 ; 右 边 的 图 像 显 示 了 这 两 个 簇 的 附 影 。 当 的 值 比 较 大 时 ( 接 近
1 ) 表 明 相 应 的 观 测 点 能 够 准 确 地 划 分 到 相 似 性 较 大 的 簇 中 , 当 的 值 比 较 小 时 ( 接 近 0 ) 表
明 观 测 点 位 于 这 两 个 簇 重 叠 的 部 分 。 如 果 观 测 点 的 凿 值 为 负 数 , 则 说 明 观 测 点 被 划 分 到 错 误
的 族 中 。 由 于 在 上 面 的 阴 影 图 中 , 两 个 簇 的 均 值 分 别 为 0 , 81 和 0 . 62 , 所 以 这 表 明 这 两 个
簇 的 划 分 结 果 很 好
接下来使用cluster包中的pam()函数
library(cluster)
pam.result <- pam(iris2,3)
table(pam.result$clustering,iris$Species)
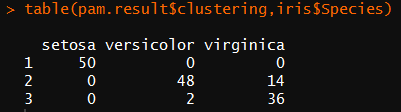
对 比 上 面 两 个 聚 类 的 结 果 , 很 难 说 函 数 pamk() 和 pam() 哪 一 个 能 获 得 更 好 的 聚 类 结 果 ,
结 果 质 量 的 好 坏 依 赖 于 目 标 问 题 以 及 领 域 知 识 和 经 验 。 在 这 个 例 子 中 , 函 数 pam() 得 到 的 聚
类 结 果 似 乎 更 好 , 这 是 因 为 它 识 别 出 3 个 不 同 的 簇 , 分 别 对 应 于 3 个 不 同 的 种 类 。 因 此 , 使
用 启 发 式 方 法 来 识 别 簇 个 数 的 函 数 pamk() 并 不 意 味 着 总 是 能 得 到 更 好 的 聚 类 结 果 。 还 需 要 注
意 的 是 , 由 于 事 先 已 经 知 道 Species 属 性 确 实 只 包 含 了 3 个 种 类 , 因 此 在 使 用 函 数 pam() 时 将
设 置 为 3 也 具 有 一 定 的 投 机 性 。
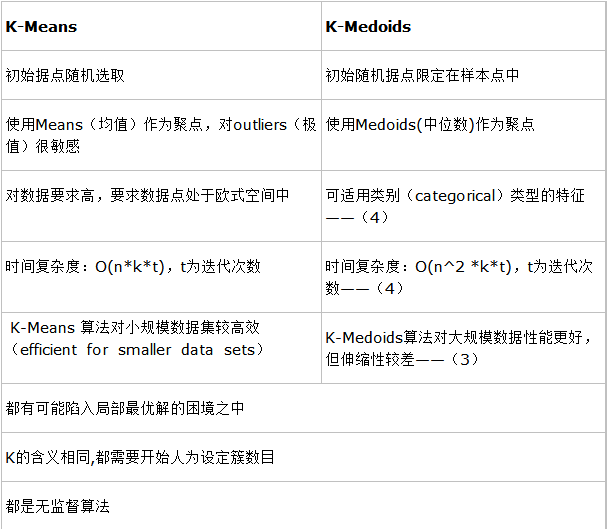
两种聚类算法的对比
层次聚类
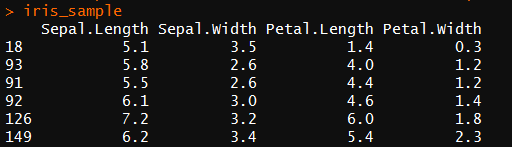
使用iris数据集,抽取40个样本
set.seed()
idx <- sample(:nrow(iris),) #抽取40个数
iris_sample <- iris[idx,-] #抽取40个样本且删去species一列
out.dist <- dist(iris_sample,method = 'euclidean')#dist()将数据转化为两点之间的距离
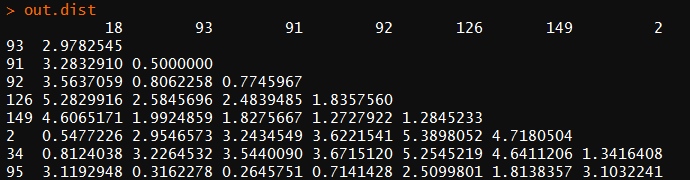

hc <- hclust(out.dist,method='average') #代入两点距离(out.dist),method='ave'指使用类平均法聚类

plot(hc,hang=-1,labels=iris$Species[idx]) #labels:根据目测值添加标签
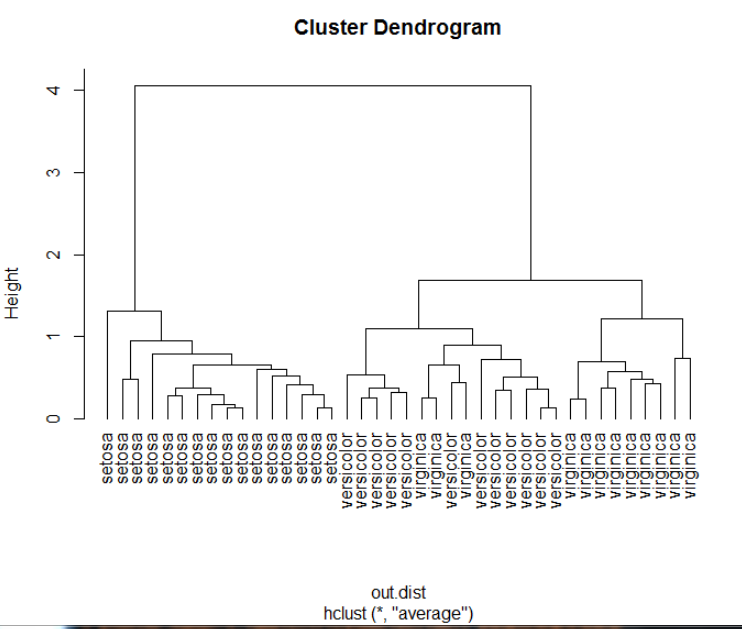
rect.hclust(hc,k=3) #归为三类
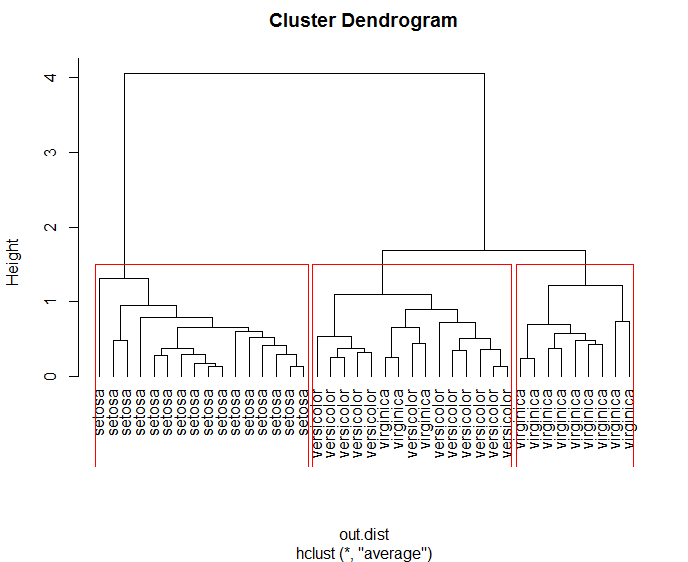
groups <- cutree(hc,k=3) #查看分类

基于密度的聚类

library(fpc)
iris2 <- iris[,-5]
ds <- dbscan(iris2,eps = 0.42,MinPts = 5) #设置可达距离和最小数目的对象点
table(ds$cluster,iris$Species)
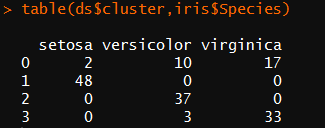
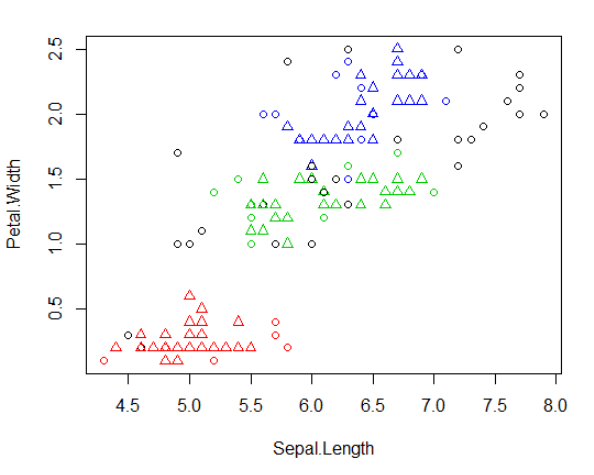
‘1’-‘3’指被识别出来的三个聚类簇,‘0’表示噪声数据或离散点,即不属于任何簇的对象,绘制的图中使用黑色小圆圈表示
plot(ds,iris2[c(1,4)]) #展示第一列和第四列的聚类结果
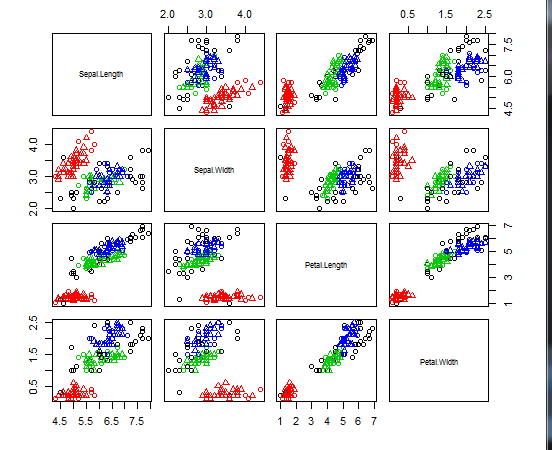
plot(ds,iris2)
基于R实现k-means法与k-medoids法的更多相关文章
- 【转】时间序列分析——基于R,王燕
<时间序列分析——基于R>王燕,读书笔记 笔记: 一.检验: 1.平稳性检验: 图检验方法: 时序图检验:该序列有明显的趋势性或周期性,则不是平稳序列 自相关图检验:(ac ...
- 统计学习导论:基于R应用——第二章习题
目前在看统计学习导论:基于R应用,觉得这本书非常适合入门,打算把课后习题全部做一遍,记录在此博客中. 第二章习题 1. (a) 当样本量n非常大,预测变量数p很小时,这样容易欠拟合,所以一个光滑度更高 ...
- 基于R语言的ARIMA模型
A IMA模型是一种著名的时间序列预测方法,主要是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型.ARIMA模型根据原序列是否平稳以及 ...
- 如何求出数组中最小(或者最大)的k个数(least k问题)
输入n个整数,如何求出其中最小的k个数? 解法1. 当然最直观的思路是将数组排序,然后就可以找出其中最小的k个数了,时间复杂度以快速排序为例,是O(nlogn): 解法2. 借助划分(Partitio ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- 快速排序/快速查找(第k个, 前k个问题)
//快速排序:Partition分割函数,三数中值分割 bool g_bInvalidInput = false; int median3(int* data, int start, int end) ...
- [Swift]LeetCode373. 查找和最小的K对数字 | Find K Pairs with Smallest Sums
You are given two integer arrays nums1 and nums2 sorted in ascending order and an integer k. Define ...
- 基于R语言的时间序列指数模型
时间序列: (或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列.时间序列分析的主要目的是根据已有的历史数据对未来进行预测.(百度百科) 主要考虑的因素: 1.长期趋势(Lon ...
- (找到最大的整数k使得n! % s^k ==0) (求n!在b进制下末尾0的个数) (区间满足个数)
题目:https://codeforces.com/contest/1114/problem/C 将b分解为若干素数乘积,记录每个素数含多少次方 b = p1^y1·p2^y2·...·pm^ym. ...
随机推荐
- 乘风破浪:LeetCode真题_019_Remove Nth Node From End of List
乘风破浪:LeetCode真题_019_Remove Nth Node From End of List 一.前言 这次总算到了链表的操作了,之后肯定会有排序算法,二叉树,排序树,图等等的操作,现在我 ...
- Alpha 冲刺报告(1/10)
Alpha 冲刺报告 队名:洛基小队 峻雄(组长) 已完成:α版要完成的第一部分的游戏内容规划 明日计划:学习脚本教程,熟悉一下相关API 剩余任务:物品背包交互脚本 困难:对于JS脚本的不熟悉:如何 ...
- BZOJ 1061 志愿者招募 最小费用流&&线性规划建模
题目链接: https://www.lydsy.com/JudgeOnline/problem.php?id=1061 题目大意: 申奥成功后,布布经过不懈努力,终于成为奥组委下属公司人力资源部门的主 ...
- flume MemoryChannel 源代码解析
1.先分析三个LinkedBlockingDeque<Event>类型的takeList,putList,queue putList: 存放的是来自source生产的数据,通过调用doP ...
- cocos2d::CCFileUtils::sharedFileUtils()->getFileData(szFile, "r", &bufferSize) 不同平台返回值不一样
string pathKey = CCFileUtils::sharedFileUtils()->fullPathForFilename(fileName); unsigned char* pB ...
- 【[CQOI2015]选数】
这道题自然是可以反演的 按照反演的套路我们先设出两个函数 \(F(n)\)表示从\([L,H]\)中任选\(N\)个数的最大公约数是\(n\)或者\(n\)的倍数的情况数 \(f(n)\)表示从\([ ...
- 根据自增ID生成不重复序列号
网上看到一个例子,源地址:https://www.aliyun.com/jiaocheng/536419.html 借鉴修改一下 实现根据long类型的用户ID生成6位随机邀请码,并且根据邀请码能算出 ...
- textarea多行文本框自适应高度
<script src="https://cdn.bootcss.com/jquery/1.8.1/jquery.js"></script> <scr ...
- Nexus修改admin密码及其添加用户
Nexus之所以修改密码,是为了安全起见,个人学习的话,本地windows或者虚拟机即可,外网服务器建议将密码修改复杂点,而且强烈建议端口不要8081,最好将其改为其他的.同样也是为了安全起见. 添加 ...
- 可视化编程中----cell的自适应高度
- (CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath{ Joke ...