正则表达式—RegEx(RegularExpressio)(一)
今日随笔,想和大家分享一下正则表达式的相关知识。
先不说概念性的东西,举一个例子再说。
验证你输入的邮政编码 ,你输入的邮政编码必须是六位的数字。
while (true)
{
Console.WriteLine("输入邮政编码");
string codeRegex = "^[0-9]{6}$";//创建正则表达式模式
string code = Console.ReadLine();
Console.WriteLine(Regex.IsMatch(code, codeRegex));//调用Regex的IsMatch方法,第一个参数是你输入要匹配的字符串,第二个参数正则表达式模式,返回的结果是一个Boolean类型
}
测试结果: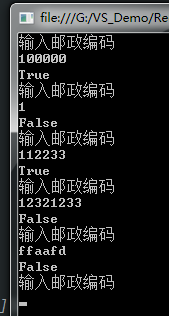
C#中,用using System.Text.RegularExpressions命名空间下的Regex类来操作正则表达式。
上个例子中调用了Regex的静态方法IsMatch,来判断输入的字符串code是否与表达式模式codeRegex 相匹配,如果匹配,则返回一个True,不匹配则返回False。
注:也可以不调用Regex的静态方法,而是 用 new关键字调用Regex的构造函数来创建一个Regex类的对象,如:Regex re = new Regex(codeRegex),其中正则表达式模式codeRegex作为构造函数的参数,然后通过re对象也可以调用 IsMatch方法:re.IsMatch(code,codeRegex)。其实通过Regex类型调用静态函数内部,也是创建了一个类型对象,通过类型对象调用IsMatch方法。
现在让我们看看 codeRegex = "^[0-9]{6}$"是个什么东东。
Microsoft称它为正则表达式模式,其中[0-9]代表的是0到9任意一个数字,属于元字符,{6}则表示前面的[0-9]必须出现6次,那么有的小伙伴就会问了,这不是已经齐了吗,0到9的任意数字出现六次,已经符合邮政编码的要求了啊,那^和$又代表的什么意思呢。
^:表示匹配输入字符串开始的位置,例如^a则表示符合匹配的字符串必须是以a开头的。
$:表示匹配输入字符串结束的位置,例如z$则表示符合匹配的字符串必须是以z结束的。
那为什么要加上这两个限定符呢,以为IsMatch检测code匹配时,它只要检测到code字符串中只要有符合codeRegex正则表达式模式的字符串段,那么它就会返回True。例如若个输入的字符串为"afdasf100000aaaaa",IsMatch返回的也是True,以为在这个字符串中,中间的100000符合codeRegex.所以你要限定的是完全匹配的话,则前后必须加上^和$。这里代表以六个任意数字为开头,并且以任意六个数字为结尾,而且中间只能有六个任意数字。
下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为:
| 字符 | 说明 |
|---|---|
|
\ |
将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,“n”匹配字符“n”。“\n”匹配换行符。序列“\\”匹配“\”,“\(”匹配“(”。 |
|
^ |
匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与“\n”或“\r”之后的位置匹配。 |
|
$ |
匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与“\n”或“\r”之前的位置匹配。 |
|
* |
零次或多次匹配前面的字符或子表达式。例如,zo* 匹配“z”和“zoo”。* 等效于 {0,}。 |
|
+ |
一次或多次匹配前面的字符或子表达式。例如,“zo+”与“zo”和“zoo”匹配,但与“z”不匹配。+ 等效于 {1,}。 |
|
? |
零次或一次匹配前面的字符或子表达式。例如,“do(es)?”匹配“do”或“does”中的“do”。? 等效于 {0,1}。 |
|
{n} |
n 是非负整数。正好匹配 n 次。例如,“o{2}”与“Bob”中的“o”不匹配,但与“food”中的两个“o”匹配。 |
|
{n,} |
n 是非负整数。至少匹配 n 次。例如,“o{2,}”不匹配“Bob”中的“o”,而匹配“foooood”中的所有 o。“o{1,}”等效于“o+”。“o{0,}”等效于“o*”。 |
|
{n,m} |
M 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,“o{1,3}”匹配“fooooood”中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。 |
|
? |
当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是“非贪心的”。“非贪心的”模式匹配搜索到的、尽可能短的字符串,而默认的“贪心的”模式匹配搜索到的、尽可能长的字符串。例如,在字符串“oooo”中,“o+?”只匹配单个“o”,而“o+”匹配所有“o”。 |
|
. |
匹配除“\n”之外的任何单个字符。若要匹配包括“\n”在内的任意字符,请使用诸如“[\s\S]”之类的模式。 |
|
(pattern) |
匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果“匹配”集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用“\(”或者“\)”。 |
|
(?:pattern) |
匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用“or”字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。 |
|
(?=pattern) |
执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配“Windows 2000”中的“Windows”,但不匹配“Windows 3.1”中的“Windows”。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
|
(?!pattern) |
执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配“Windows 3.1”中的 “Windows”,但不匹配“Windows 2000”中的“Windows”。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
|
x|y |
匹配 x 或 y。例如,'z|food' 匹配“z”或“food”。'(z|f)ood' 匹配“zood”或“food”。 |
|
[xyz] |
字符集。匹配包含的任一字符。例如,“[abc]”匹配“plain”中的“a”。 |
|
[^xyz] |
反向字符集。匹配未包含的任何字符。例如,“[^abc]”匹配“plain”中的“p”。 |
|
[a-z] |
字符范围。匹配指定范围内的任何字符。例如,“[a-z]”匹配“a”到“z”范围内的任何小写字母。 |
|
[^a-z] |
反向范围字符。匹配不在指定的范围内的任何字符。例如,“[^a-z]”匹配任何不在“a”到“z”范围内的任何字符。 |
|
\b |
匹配一个字边界,即字与空格间的位置。例如,“er\b”匹配“never”中的“er”,但不匹配“verb”中的“er”。 |
|
\B |
非字边界匹配。“er\B”匹配“verb”中的“er”,但不匹配“never”中的“er”。 |
|
\cx |
匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是“c”字符本身。 |
|
\d |
数字字符匹配。等效于 [0-9]。 |
|
\D |
非数字字符匹配。等效于 [^0-9]。 |
|
\f |
换页符匹配。等效于 \x0c 和 \cL。 |
|
\n |
换行符匹配。等效于 \x0a 和 \cJ。 |
|
\r |
匹配一个回车符。等效于 \x0d 和 \cM。 |
|
\s |
匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
|
\S |
匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 |
|
\t |
制表符匹配。与 \x09 和 \cI 等效。 |
|
\v |
垂直制表符匹配。与 \x0b 和 \cK 等效。 |
|
\w |
匹配任何字类字符,包括下划线。与“[A-Za-z0-9_]”等效。 |
|
\W |
与任何非单词字符匹配。与“[^A-Za-z0-9_]”等效。 |
|
\xn |
匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,“\x41”匹配“A”。“\x041”与“\x04”&“1”等效。允许在正则表达式中使用 ASCII 代码。 |
|
\num |
匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,“(.)\1”匹配两个连续的相同字符。 |
|
\n |
标识一个八进制转义码或反向引用。如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
|
\nm |
标识一个八进制转义码或反向引用。如果 \nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 \nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 \nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
|
\nml |
当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
|
\un |
匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
上面的元字符,就一些常用的举一些例子
.(点):表示可以匹配除了\n之外的任何单个字符,例如:x.o 那么 xao xbo xco x$o 都是匹配的。
[] :表示一个字符集,例如:[abc]表示匹配a或者b或者c都可以,[a-z]表示小写a到小写z的26个英文字母都匹配,[0-9]表示0-9人一个的一个数字都可以匹配。
* :表示零次或多次匹配前面的字符或子表达式。例如,zo* 那么 z可以,zo也可以,zooooooo还可以。
+ :表示至少出现一次 zo+ 表示:zo可以,zoooooo也可以,但是z就不匹配了。
? :表示零次或1次匹配前面的字符或子表达式。 zo?: 那么只有用 z 或者zo可以匹配。
{} :属于限定符,限定前面的字符或者表达式出现的次数 {n}:表示出现n次 {n,m}:表示出现n或者n+1次或者……一直到m次。{n,}表示至少出现n次。
[^] :反向范围字符。匹配不在指定的范围内的任何字符。例如,“[^a-z]”匹配任何不在“a”到“z”范围内的任何字符。注意^出现在[]外面代表另一个意思。
^:表示匹配输入字符串开始的位置,例如^a则表示符合匹配的字符串必须是以a开头的。
$:表示匹配输入字符串结束的位置,例如z$则表示符合匹配的字符串必须是以z结束的。
|: 表示或。这个或的优先级低。小括号,可以改变优先级。
\w :匹配任何字类字符,包括下划线。与“[A-Za-z0-9_]”等效。
\d :数字字符匹配。等效于 [0-9]。
上面是一些常用的,不全,如果想多了解一些可以gogole,一查一大把。。。
概念性的东西已经介绍的 差不多了,现在让我们做个小练习巩固一下哈。
练习 你知道什么样的字符串匹配 这三个表达式模式吗 ? "z|food" "^z|food$" "^(z|f)ood$"
1、"z|food" : z匹配吗,food? zood? abcdfoodefg? abdkjjfajfldazffjfjf?
2、"^z|food$" z匹配吗,food? zood? zaaaaaaa? asdffdsafood?
3、"^(z|f)ood$" :z匹配吗,food? zood? zaaaaaaa? asdffdsafood?
先不要看答案哦 自己多思考一下哈。。。。。。
1、这些都匹配 "z|food" 表示为,你输入的字符串中,其中只要有匹配z或者匹配food的字符串段就可以。
2、这些也都匹配 “^z|food$" :表示只要是以z开头的字符串或者以food结尾的字符串都可以匹配。
3、只要前两个匹配哦,"^(z|f)ood$":必须已zood开头并且以zood结尾 或者 已food开头并且以food结尾。
小伙伴们,你们答对了吗?笔者第一次做这个题的时候没有得满分。。。。惭愧惭愧!
对了,还要说一点 ,正则表达式只对字符串有用,如果脱离了这个范畴,就没有用了。在一点写正则表达式的最主要的就是 找规律,只有你找到规律才能写出正确的正则表达式
下面在聚一些例子
namespace RegexExpression
{
class Program
{
static void Main(string[] args)
{
#region 验证邮政编码 while (true)
{
Console.WriteLine("输入邮政编码");
string codeRegex = "^[0-9]{6}$";
string code = Console.ReadLine();
Console.WriteLine(Regex.IsMatch(code, codeRegex));
}
#endregion #region 输入10-20的数
for (int i = ; i < ; i++)
{
string str = i.ToString();
if (Regex.IsMatch(str, "^(1[0-9]|20)$"))
{
Console.WriteLine(str + " " + true);
}
else
{
Console.WriteLine(str + " " + false);
}
}
Console.ReadLine();
#endregion //写正则表达式的最主要的就是 找规律,只有你找到规律才能写出正确的正则表达式 // 练习 "z|food" "^z|food$" "^(z|f)ood$" #region 判断是否是手机号码
//010-8888888, 0100-888888, 0108888888, 01008888888, 5位数字, 13位手机号码 string regexExp = @"^((0\d{2,3}\-?\d{7,8})|(\d{11}))$";
while (true)
{
string phone = Console.ReadLine();
Console.WriteLine(Regex.IsMatch(phone, regexExp));
} #endregion #region 验证邮箱
string regexExp = @"^\w+@\w+(\.\w+){1,3}$";
while (true)
{
string email = Console.ReadLine();
Console.WriteLine(Regex.IsMatch(email, regexExp));
} #endregion #region 验证ip地址
string regexExp = @"^(\d{1,3}\.){3}\d{1,3}$";
while (true)
{
string ip = Console.ReadLine();
Console.WriteLine(Regex.IsMatch(ip, regexExp));
}
#endregion #region 验证日期
string regexExp = @"^\d{4}-(0[1-9]|1[0-2])-([012][0-9]|3[01])$";
while (true)
{
string date = Console.ReadLine();
Console.WriteLine(Regex.IsMatch(date, regexExp));
}
#endregion } }
}
今天的就到这了,下一次打算把正则表达式在各个场景中的语法和例子分享给大家,在此也希望大家给予指教,希望大家进来之后给一些点评和意见什么的,笔者哪块写的不对或者不准确,也希望大家支持,3Q。
正则表达式—RegEx(RegularExpressio)(一)的更多相关文章
- 正则表达式—RegEx(RegularExpressio)(三)
今日随笔,继续写一点关于正则表达式的 知识.前两天介绍了正则表达式验证匹配,提取等一些基本的知识,今天继续分享下它的另一个强大的应用:替换(replace). 开始之前,还是要补一下昨天的内容. 在我 ...
- 正则表达式—RegEx(RegularExpressio)(二)
今日随笔,继续写一些关于正则表达式的东西. 首先补一点昨天的内容: 昨天少说了一个贪婪模式,什么是贪婪模式,比如像+或者*这样的元字符匹配中,会以最大匹配值匹配,这句话是什么意思呢,例如: 定义一个正 ...
- (转)正则表达式—RegEx(RegularExpressio)(三)
原文地址:http://www.cnblogs.com/feng-c-x/archive/2013/09/05/3302465.html 今日随笔,继续写一点关于正则表达式的 知识.前两天介绍了正则表 ...
- C#正则表达式Regex常用匹配
使用Regex类需要引用命名空间:using System.Text.RegularExpressions; 利用Regex类实现验证 示例1:注释的代码所起的作用是相同的,不过一个是静态方法,一个是 ...
- C#正则表达式Regex类的用法
C#正则表达式Regex类的用法 更多2014/2/18 来源:C#学习浏览量:36891 学习标签: 正则表达式 Regex 本文导读:正则表达式的本质是使用一系列特殊字符模式,来表示某一类字符串, ...
- C#正则表达式Regex类
C#正则表达式Regex类的使用 C#中为正则表达式的使用提供了非常强大的功能,这就是Regex类.这个包包含于System.Text.RegularExpressions命名空间下面,而这个命名空间 ...
- (四)boost库之正则表达式regex
(四)boost库之正则表达式regex 正则表达式可以为我们带来极大的方便,有了它,再也不用为此烦恼 头文件: #include <boost/regex.hpp> 1.完全匹配 std ...
- boost 正则表达式 regex
boost 正则表达式 regex 环境安装 如果在引用boost regex出现连接错误,但是引用其他的库却没有这个错误,这是因为对于boost来说,是免编译的,但是,正则这个库 是需要单独编译 ...
- 请写出正则表达式(regex),取得下列黄色部分的字符串 TEL: 02-236-9655/9659 FAX:02-236-9654 (黄色部分即02-236-9655/9659 ) ( 测试面试题)
请写出正则表达式(regex),取得下列黄色部分的字符串 TEL: 02-236-9655/9659 FAX:02-236-9654 答: package test1; import java.uti ...
随机推荐
- Hive shell 命令
Hive shell 命令. 连接 hive shell 直接输入 hive 1.显示表 hive> show tables; OK test Time taken: 0.17 seconds, ...
- vlan pvid vid access口 trunk口
VLAN技术浅谈 http://www.h3c.com.cn/MiniSite/H3care_Club/Data_Center/Net_Reptile/The_One/Home/Catalog/ ...
- java list分组 list里面分装的都是对象 按照对象的属性来分组
http://www.iteye.com/problems/86110 —————————————————————————————————————————————————————————— List& ...
- ElasticSearch0910学习
1:es简介 es是一个分布式的搜索引擎,使用java开发,底层使用lucene. 特点:天生支持分布式的.为大数据而生的.基于restful接口. 2:es和solr对比 接口 solr:类似web ...
- 关于Cocos2d-x中数据的存储
当局分数的打印和最高分数的记录 1.首先定义一个Label类型的节点在GameScene.cpp的init方法中,设置初始分数为0 _myScore = 0; scorelabel = Label:: ...
- C++ Primer学习笔记(三) C++中函数是一种类型!!!
C++中函数是一种类型!C++中函数是一种类型!C++中函数是一种类型! 函数名就是变量!函数名就是变量!函数名就是变量! (---20160618最新消息,函数名不是变量名...囧) (---201 ...
- C# winform 获取当前路径
// 获取程序的基目录. System.AppDomain.CurrentDomain.BaseDirectory// 获取模块的完整路径.System.Diagnostics.Process.Get ...
- 使用_snscanf_s转换十六进制时引起的内存越界
//将Hex编码转换为指定编码格式的字符串 string Encoding::DecodeHexString(const string &strSrc, UINT code_page ) { ...
- MySQL(五)之DDL(数据定义语言)与六大约束
前言 前面在数据库的讲解中,其实很多东西都非常的细节,在以前的学习过程中我都是没有注意到的.可能在以后的工作中会碰到所以都是做了记录的. 接下来,我将分享的是MySQL的DDL用来对数据库及表进行操作 ...
- Solr with Apache Tomcat
配置教程 1 http://www.duntuk.com/how-install-apache-solr-46-apache-tomcat-7-use-drupal https://www.gotos ...