calcite介绍
前言
calcite是一个可以将任意数据查询转换成基于sql查询的引擎,引擎特性也有很多,比如支持sql树的解析,udf的扩展,sql执行优化器的扩展等等。目前已经被很多顶级apache项目引用,比如hive,kylin等。在这个SQL作为主流的数据查询语言大数据世界里,calcite的作用会越来越大。
理解calcite的核心流程
如图1所示。calcite核心步骤有两个,数据关系化, SQL解析执行。
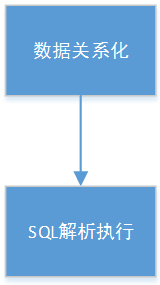
图1 calcite核心流程
数据协议关系化
要想使用sql进行查询,首先要把非结构化数据结构化,而calcite号称支持所有数据协议,则必然得将这部分内容抽象出来。
在calcite的接口中,Schema和Table是数据关系化中最重要的两个接口。Schema是对catalog或者是database的抽象,以兼容已经存在的各类数据库,Table是对表,视图,流的抽象,以兼容数据的各种场景,下面详细描述一下这两种抽象。
schema
calcite利用schema的层级关系,构造出来namespace的概念,如图2所示,schema自身是一个树形结构,这样设计的优点很明显,可以兼容所有已知和未知的数据库,基于namespace结构,schema无论是横向还是纵向都可以无限扩展。

图2 schema的namespace
在实际应用中,RootSchema是根所有schema的路径,所有注册在RootSchema上的table或者是udf都是全局的,意思就是说可以被SubSchema直接使用,而注册在SubSchema里的table或者是udf,则在使用中必须声明是哪个SubSchema拥有的。
table
table是schema的核心属性,一个schema拥有多个table,这就像一个数据库中有很多表一样。而table的概念更为广泛,为了兼容到各类数据库或者消息队列,calcite将table类型细分为TableType,基本的类似传统关系型数据库中的表或者视图,流式的Stream等。
另外对数据协议的兼容是非常重要的,像json,csv,xml等等,table抽象出了RelDataType接口,目的是将应用层的数据协议转关系化,从而可以为sql服务。
拿csv格式的数据来说,假设csv数据的每一行数据和table中的每一行一一对应,那么在关系化的过程中,必须将csv中每个字段的类型及一些元数据定义清晰,比如字段是int类型还是long类型,主键是哪个字段,外键是哪个字段等,calcite提供了几乎所有已存在的字段类型。
关于嵌套数据,calcite也考虑的很周全,提供MapSqlType或者ArraySqlType的形式来兼容这些结构。
拿json格式的数据来说,字段嵌套是很常见的,如果想把这类结构数据关系化,通常有两种选择(1)数据扁平化,将嵌套的字段提上来,形成a.b的形式(2)通过calcite引擎声明嵌套字段及规则,在使用sql查询的时候再通过calcite的表达式提取这些字段。
SQL解析执行
到了这一步,其实和传统数据库很像了,如图3所示,calcite采用了该方案来解决从sql的输入到输出。
calcite通过关系代数来实现对sql的执行,而关系代数之间通过树形结构作为载体,每一个输入的sql命令都会被转换成树形结构的关系代数也就是关系表达式树。calcite支持直接构建关系表达式树,通过RelBuilder接口。
注:关系代数,常见的有(交,并,差,投影,选择,笛卡尔积,连接)

图3
案例
完整案例
calcite提供了基于json和csv的案例,在calcite-example模块下,另外在该模块的单元测试中,有一些完整的例子。
sql解析案例
- // 可以通过SqlParser直接对sql语句作解析,返回的就是sql树。
- SqlParser sqlParser = SqlParser.create("select * from \"table\" where \"column\" > 1 limit 1");
- SqlNode sqlNode = sqlParser.parseQuery();
- if(sqlNode instanceof SqlCall){
- if(sqlNode instanceof SqlBasicCall){
- SqlBasicCall basicCall = (SqlBasicCall) sqlNode;
- System.out.println(((SqlIdentifier)basicCall.operand(0)).getSimple());
- System.out.println(((SqlNumericLiteral)basicCall.operand(1)).getValue());
- System.out.println(basicCall.getKind());
- }
- System.out.println(sqlNode.getKind()+" -> "+sqlNode.getClass());
- SqlCall call = (SqlCall) sqlNode;
- for(SqlNode node: call.getOperandList()){
- parse(node);
- }
- }
引用
// calcite官网
http://calcite.apache.org/docs/tutorial.html
// calcite github
https://github.com/apache/calcite
calcite介绍的更多相关文章
- Apache顶级项目 Calcite使用介绍
什么是Calcite Apache Calcite是一个动态数据管理框架,它具备很多典型数据库管理系统的功能,比如SQL解析.SQL校验.SQL查询优化.SQL生成以及数据连接查询等,但是又省略了一些 ...
- Phoenix核心功能原理及应用场景介绍以及Calcite 查询计划生成框架介绍
Phoenix是一个开源的HBase SQL层.它不仅可以使用标准的JDBC API替代HBase Client API创建表,插入和查询HBase,也支持二级索引.事物以及多种SQL层优化. 此系列 ...
- 【转】Kylin介绍 (很有用)
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- OLAP引擎——Kylin介绍(很有用)
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- Kylin介绍
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- 转: OLAP引擎——Kylin介绍
本文转自:http://blog.csdn.net/yu616568/article/details/48103415 ,如有侵犯,立刻删除. Kylin是ebay开发的一套OLAP系统,与Mond ...
- Apache Calcite项目简介
文章导读: 什么是Calcite? Calcite的主要功能? 如何快速使用Calcite? 什么是Calcite Apache Calcite是一个动态数据管理框架,它具备很多典型数据库管理系统的功 ...
- Kylin介绍 (很有用)
转:http://blog.csdn.net/yu616568/article/details/48103415 Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOL ...
- 春蔚专访--MaxCompute 与 Calcite 的技术和故事
摘要:2019大数据技术公开课第一季<技术人生专访>,来自阿里云计算平台事业部高级开发工程师雷春蔚向大家讲述了MaxCompute 与 Calcite 的技术和故事. 具体内容包括: 1) ...
随机推荐
- 安装Hadoop系列 — 安装SSH免密码登录
配置ssh免密码登录 1) 验证是否安装ssh:ssh -version显示如下的话则成功安装了OpenSSH_6.2p2 Ubuntu-6ubuntu0.1, OpenSSL 1.0.1e 11 ...
- 【BZOJ3958】[WF2011]Mummy Madness 二分+扫描线+线段树
[BZOJ3958][WF2011]Mummy Madness Description 在2011年ACM-ICPC World Finals上的一次游览中,你碰到了一个埃及古墓. 不幸的是,你打开了 ...
- 三维凸包求内部一点到表面的最近距离(HDU4266)
http://acm.hdu.edu.cn/showproblem.php?pid=4266 The Worm in the Apple Time Limit: 50000/20000 MS (Jav ...
- 最小树形图(hdu4966多校联赛9)
GGS-DDU Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) Total ...
- 记录web项目部署到阿里云服务器步骤
(使用 web项目.阿里云服务器.Xftp.Xshell),敬请参考和指正 1.将要部署的项目打包成WAR文件格式,可以在MyEclipse.Eclipse都可以完成打包,如下图: 2.安装Xshel ...
- loadrunner多场景的串行执行以及定时执行
方法一: 既然是脚本串行执行,那在场景设计中必然是要用多个脚本,要注意的是需要将Scenario Schedule中的Schedule by设置为Group的模式.然后按实际需要依次设置每个脚本的Sc ...
- 免费访问:谷歌搜索,Gmail邮箱,Chrome商店
分享个免费的google的服务的方法 1,插件下载: http://note.youdao.com/noteshare?id=6a3e52f8d4ccf63c751eeddd625a118d 2,使用 ...
- 强制关机导致ORA-03113
数据库启动报错:无法打开数据库. [oracle@localhost ORCL]$ sqlplus / as sysdba SQL*Plus: Release 11.2.0.4.0 Productio ...
- Benefits of Using the Spring Framework Dependency Injection 依赖注入 控制反转
小结: 1. Dependency Injection is merely one concrete example of Inversion of Control. 依赖注入是仅仅是控制反转的一个具 ...
- ES6基础教程(整理自阮一峰)
------------------------ECMAScript 6 简介------------------------ECMAScript 和 JavaScript 的关系是,前者是后者的规格 ...