(Matlab)GPU计算简介,及其与CPU计算性能的比较
6、示例Matlab代码——GPU计算与CPU计算效率的对比
1、GPU与CPU结构上的对比
原文:
Multicore machines and hyper-threading technology have enabled scientists, engineers, and financial analysts to speed up computationally intensive applications in a variety of disciplines. Today, another type of hardware promises even higher computational performance: the graphics processing unit (GPU).
Originally used to accelerate graphics rendering, GPUs are increasingly applied to scientific calculations. Unlike a traditional CPU, which includes no more than a handful of cores, a GPU has a massively parallel array of integer and floating-point processors, as well as dedicated, high-speed memory. A typical GPU comprises hundreds of these smaller processors (Figure 1).
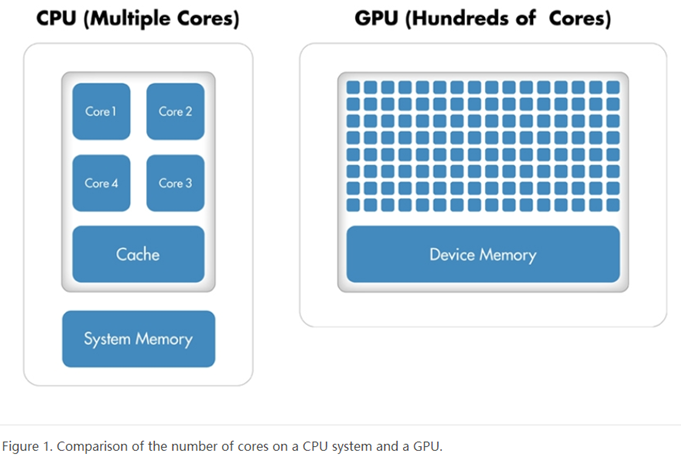
个人注解1:从上图可以看出:CPU的核心数是远远小于GPU的核心数的,虽然CPU每个核心的性能非常强大,但是典型的GPU都包含了数百个小型处理器,这些处理器是并行工作的,如果在处理大量的数据时,就会表现出相当高的效率,这就是所谓的众人拾柴火焰高。
2、GPU能加速我的应用程序吗?
原文:

个人注解2:这两个条件的第二个我觉得是进行GPU计算的大前提,正是因为任务能够碎片化,才能够充分利用GPU的物理结构,从而提高计算效率。第一个说则条件说明了GPU计算需要将数据传输给GPU显存,这一步会花一些时间,如果数据传输花费的时间比较多的话,那就不推荐使用GPU计算啦。下面是我截的图片,演示了一个GPU计算的具体流程。
至于数据传输所花费的时间是什么量级,可以通过gpuArray函数和gather函数来传递一个矩阵B来做测试,两次传输过程之间不要做任何多余的操作,将该过程循环几千次然后求出其用时的平均值;依次改变B的大小重复上面的步骤,然后将B的大小作为横轴,平均传输时间做为纵轴,plot一个图即可。
由于目前我不太用GPU计算了,各种软件没有安装,不方便给出结果,感兴趣读者的可以亲自尝试验证一下,不再赘述。
3、GPU与CPU在计算效率上的对比
原文:
To evaluate the benefits of using the GPU to solve second-order wave equations, we ran a benchmark study in which we measured the amount of time the algorithm took to execute 50 time steps for grid sizes of 64, 128, 512, 1024, and 2048 on an Intel® Xeon® Processor X5650 and then using an NVIDIA® Tesla™ C2050 GPU.
For a grid size of 2048, the algorithm shows a 7.5x decrease in compute time from more than a minute on the CPU to less than 10 seconds on the GPU (Figure 4). The log scale plot shows that the CPU is actually faster for small grid sizes. As the technology evolves and matures, however, GPU solutions are increasingly able to handle smaller problems, a trend that we expect to continue.
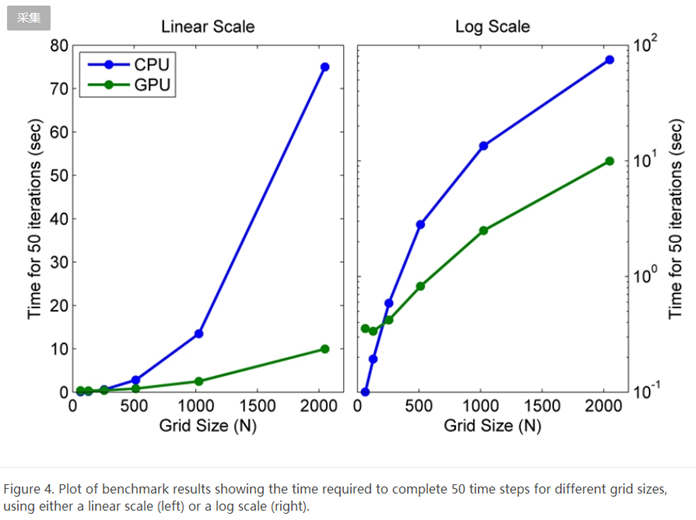
个人注解3:这个图是非常直观的,我当时就是看到这个图才知道原来GPU计算这么厉害!!! 从上图可以看出,数据量越大,GPU计算相对于CPU计算的效率越高;而在数据量较小时,CPU计算的效率是远远高于GPU计算的,我觉得应该有两个原因(仅供参考):其中一个原因是,小量的数据可能根本占用不了GPU那么多的核心,而每个核心的计算效率又相对较低,所以速度会比较慢。另外一个原因,就是上面所说的数据传输相对耗时的原因。
4、利用Matlab进行GPU计算的一般流程
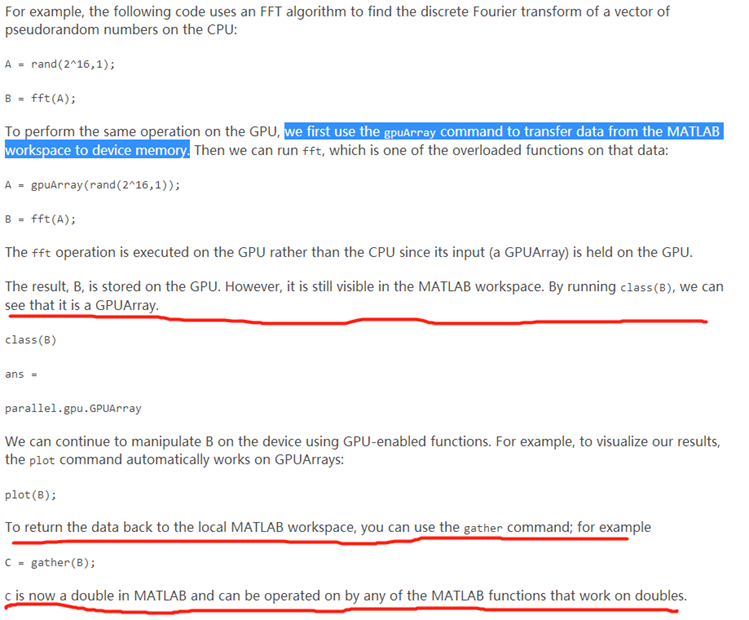
个人注解4:上图标记的地方解释了第二节所说的数据传输。
5、GPU计算的硬件、软件配置
5.1 硬件及驱动
电脑:联想扬天 M4400
系统:win 7 X64
硬件:NVIDIA GeForce GT 740M 独显2G
硬件驱动:

5.2 软件
Matlab 2015a 需要安装Parallel Computing Toolbox

VS 2013 只安装了 C++基础类
CUDA 7.5.18 只安装了Toolkit
6、示例Matlab代码——GPU计算与CPU计算效率的对比
%%首先以200*200的矩阵做加减乘除做比较
t = zeros(1,100);
A = rand(200,200);B = rand(200,200);C = rand(200,200);
for i=1:100
tic;
D=A+B;E=A.*D;F=B./(E+eps);
t(i)=toc;
end;mean(t)
%%%%ans = 2.4812e-04
t1 = gpuArray(zeros(1,100));
A1 = gpuArray(rand(200,200));
B1 = gpuArray(rand(200,200));
C1 = gpuArray(rand(200,200));
for i=1:100
tic;
D1=A1+B1;E1=A1.*D1;F1=B1./(E1+eps);
t1(i)=toc;
end;mean(t1)
%%%%ans = 1.2260e-04
%%%%%%速度快了近两倍!
%%然后将矩阵大小提高到2000*2000做实验
t = zeros(1,100);
A = rand(2000,2000);B = rand(2000,2000);C = rand(2000,2000);
for i=1:100
tic;
D=A+B;E=A.*D;F=B./(E+eps);
t(i)=toc;
end;mean(t)
%%%%ans = 0.0337
t1 = gpuArray(zeros(1,100));
A1 = gpuArray(rand(2000,2000));
B1 = gpuArray(rand(2000,2000));
C1 = gpuArray(rand(2000,2000));
for i=1:100
tic;
D1=A1+B1;E1=A1.*D1;F1=B1./(E1+eps);
t1(i)=toc;
end;mean(t1)
%%%%ans = 1.1730e-04
倍!!!
参考链接:https://ww2.mathworks.cn/company/newsletters/articles/gpu-programming-in-matlab.html
(Matlab)GPU计算简介,及其与CPU计算性能的比较的更多相关文章
- (Matlab)GPU计算及CPU计算能力的比较
%%首先以200*200的矩阵做加减乘除 做比较 t = zeros(1,100); A = rand(200,200);B = rand(200,200);C = rand(200,200); fo ...
- 从 SPIR-V 到 ISPC:将 GPU 计算转化为 CPU 计算
游戏行业越来越多地趋向于将计算工作转移到图形处理单元 (GPU) 中,导致引擎和/或工作室需要开发大量 GPU 计算着色器来处理不同的计算任务.但有时候在 CPU 上运行这些计算着色器非常方便,不必重 ...
- (一)tensorflow-gpu2.0学习笔记之开篇(cpu和gpu计算速度比较)
摘要: 1.以动态图形式计算一个简单的加法 2.cpu和gpu计算力比较(包括如何指定cpu和gpu) 3.关于gpu版本的tensorflow安装问题,可以参考另一篇博文:https://www.c ...
- GPU计算的十大质疑—GPU计算再思考
http://blog.csdn.NET/babyfacer/article/details/6902985 原文链接:http://www.hpcwire.com/hpcwire/2011-06-0 ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
- Julia:高性能 GPU 计算的编程语言
Julia:高性能 GPU 计算的编程语言 0条评论 2017-10-31 18:02 it168网站 原创 作者: 编译|田晓旭 编辑: 田晓旭 [IT168 评论]Julia是一种用于数学计 ...
- GPU计算的后CUDA时代-OpenACC(转)
在西雅图超级计算大会(SC11)上发布了新的基于指令的加速器并行编程标准,既OpenACC.这个开发标准的目的是让更多的编程人员可以用到GPU计算,同时计算结果可以跨加速器使用,甚至能用在多核CPU上 ...
- Matlab插值计算各时刻磁法勘探日变观测值
Matlab插值计算各时刻磁法勘探日变观测值 在磁法勘探中,消日变影响的改正称为日变改正.进行日变改正时必须设立日变站,观测日变情况.根据日变数据和测点观测时间,对观测数据进行改正. 在本次磁法实习中 ...
- OpenGL实现通用GPU计算概述
可能比較早一点做GPU计算的开发者会对OpenGL做通用GPU计算,随着GPU计算技术的兴起,越来越多的技术出现,比方OpenCL.CUDA.OpenAcc等,这些都是专门用来做并行计算的标准或者说接 ...
随机推荐
- url-loader与file-loader
一开始用url-loader的时候,想着为什么npm run build的时候,不能将图片打包到build images的目录下,原来,没有自己看这样的说明: loader 后面 limit 字段代表 ...
- EUI EXML内部类Skin和ItemRenderer
没认真看过...现在试试... EXMl支持内部类 两种支持做为内部类的:Skin和ItemRenderer 优点: 这种最大的好处就是皮肤如果只用一次,不需要单独写成一个exml文件,只需要写在组件 ...
- Visual Studio 2015 Enterprise - 企业版 - 简体中文
文件名称 文件大小 百度网盘下载 微软官方下载 Visual Studio 2015 Enterprise - 企业版 - 简体中文 3.89GB http://pan.baidu.com/s/1bn ...
- Mysql的存储引擎和索引
可以说数据库必须有索引,没有索引则检索过程变成了顺序查找,O(n)的时间复杂度几乎是不能忍受的.我们非常容易想象出一个只有单关键字组成的表如何使用B+树进行索引,只要将关键字存储到树的节点即可.当数据 ...
- CentOS下LVM逻辑卷管理技术解释
1.LVM逻辑卷管理技术产生的背景 企业日益变化的存储需要使得传统的磁盘分区存储显得不够灵活 2.磁盘分区存储 对于这样的三个物理分区的话,迟早有一天会被数据填满,因为它是死的,无法进行缩放. 假设下 ...
- mysql中sql注入的随笔
当使用如下登录代码时:就会引发sql注入问题 怎么注入呢? 'or 1=1 # 就可以了. 为什么呢? 首先or:在sql中是或者,只要满足前一个或后一个条件即可,只要所以不论你是 'or 1=1 # ...
- com.mysql.jdbc.Driver to com.mysql.cj.jdbc.Driver
com.mysql.jdbc.Driver tocom.mysql.cj.jdbc.Driver MySQL :: MySQL Connector/J 8.0 Developer Guide :: 4 ...
- Linux下批量管理工具pssh使用记录
pssh是一款开源的软件,使用python实现,用于批量ssh操作大批量机器:pssh是一个可以在多台服务器上执行命令的工具,同时支持拷贝文件,是同类工具中很出色的:比起for循环的做法,我更推荐使用 ...
- IP层网络安全协议(IPSec)技术原理图解——转载图片
- 使用Atom预览markdown
1.打开任意.md文件(markdown源文件)2.windows : ctrl + shift + pmac : command + shift + p这条命令跟Sublime Text是一样的,打 ...