PairRDD中算子combineByKey图解
1、combineByKey
combine 为结合意思。
作用: 将RDD[(K,V)] => RDD[(K,C)] 表示V的类型可以转成C两者可以不同类型。
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,numPartitions:Int ):RDD[(K,C)]
def combineByKey[C](createCombiner:V =>C ,mergeValue:(C,V) =>C, mergeCombiners:(C,C) =>C,partitioner:Partitioner,mapSideCombine:Boolean=true,serializer:Serializer= null):RDD[(K,C)]
第一个函数和第二个函数默认使用的是HashPartitioner、serialize为null。
这个算子还是比较复杂,解释下:
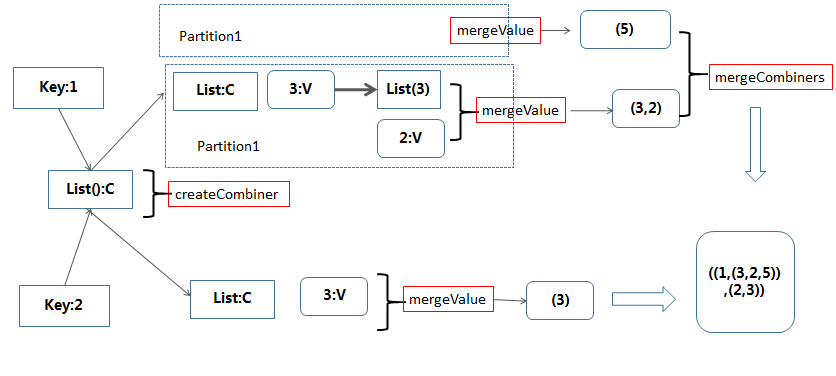
1)createCombiner:在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey第一次遇到值为k的Key(类型K),那么将对这个(k,v)调用 createCombiner函数,它的作用是将v转换为c(类型是C,聚合对象的类型,c作为局和对象的初始值)
2)mergeValue: 在遍历RDD的数据集合过程中,对于遍历到的(k,v),如果combineByKey不是第一次(或者第二次,第三次…)遇到值为k的Key(类型K),那么将对这个 (k,v)调用mergeValue函数,它的作用是将v累加到聚合对象(类型C)中,mergeValue的类型是(C,V)=>C,参数中的C遍历到此处的聚合对象,然后对v 进行聚合得到新的聚合对象值。
3)mergeCombiners:因为combineByKey是在分布式环境下执行,RDD的每个分区单独进行combineByKey操作,
最后需要对各个分区的结果进行最后的聚合,它的函数类型是(C,C)=>C,每个参数是分区聚合得到的聚合对象
例子:
scala> val data = sc.parallelize(List(("1","3"),("1","2"),("1","5"),("2","3")))
scala> val natPairRdd = data.combineByKey(List(_), (c: List[String], v: String) => v::c, (c1: List[String], c2: List[String]) => c1 ::: c2)
scala> natPairRdd.collect
res0: Array[(String, List[String])] = Array((1,List(3, 2, 5)), (2,List(3)))
PairRDD中算子combineByKey图解的更多相关文章
- PairRDD中算子aggregateByKey图解
PairRDD 有几个比较麻烦的算子,常理解了后面又忘记了,自己按照自己的理解记录好,以备查阅 1.aggregateByKey aggregate 是聚合意思,直观理解就是按照Key进行聚合. 转化 ...
- PairRDD中算子reduceByKey图解
reduceByKey 函数原型: def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) =& ...
- PairRDD中算子foldByKey图解
foldByKey 函数原型: def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] def foldByKey(zeroVal ...
- pairRDD中算子reduceByKeyLocally
原型: def reduceByKeyLocally(func: (V, V) => V): Map[K, V] 该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个 ...
- 带你学习MindSpore中算子使用方法
摘要:本文分享下MindSpore中算子的使用和遇到问题时的解决方法. 本文分享自华为云社区<[MindSpore易点通]算子使用问题与解决方法>,作者:chengxiaoli. 简介 算 ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- spark中的combineByKey函数的用法
一.函数的源码 /** * Simplified version of combineByKeyWithClassTag that hash-partitions the resulting RDD ...
- Spark中的术语图解总结
参考:http://www.raincent.com/content-85-11052-1.html 1.Application:Spark应用程序 指的是用户编写的Spark应用程序,包含了Driv ...
- ES5和ES6中的继承 图解
Javascript中的继承一直是个比较麻烦的问题,prototype.constructor.__proto__在构造函数,实例和原型之间有的 复杂的关系,不仔细捋下很难记得牢固.ES6中又新增了c ...
随机推荐
- python简单实现随机验证码
这是自己在学习pyton时写的一个随机验证码,有不对的地方欢迎指出 代码 import random def verification(): lis = '' for i in range(4): S ...
- (转)CATALINA_BASE与CATALINA_HOME的区别
到底CATALINA_HOME和CATALINA_BASE有什么区别呢,之前因为都是小打小闹的在服务器上安装一个tomcat就得了,然后根据前人的配置,将CATALINA_HOME和CATALINA_ ...
- 重要:VC DLL编程
VC DLL编程 静态链接:每个应用程序使用函数库,必须拥有一份库的备份.多个应用程序运行时,内存中就有多份函数库代码的备份. 动态连接库:多个应用程序可以共享一份函数库的备份. DLL的调用方式:即 ...
- mybatis实现多表联合查询
本文转自:http://www.cnblogs.com/xdp-gacl/p/4264440.html#!comments 一.一对一关联 1.1.提出需求 根据班级id查询班级信息(带老师的信息) ...
- 分布式缓存技术memcached学习系列(五)—— memcached java客户端的使用
Memcached的客户端简介 我们已经知道,memcached是一套分布式的缓存系统,memcached的服务端只是缓存数据的地方,并不能实现分布式,而memcached的客户端才是实现分布式的地方 ...
- 手机web——自适应网页设计(html/css控制)(转)
一. 允许网页宽度自动调整: "自适应网页设计"到底是怎么做到的?其实并不难. 首先,在网页代码的头部,加入一行viewport元标签. <meta name="v ...
- 百度定位SDK实现获取当前经纬度及位置
使用Android自带的LocationManager和Location获取位置的时候,经常会有获取的location为null的情况,并且操作起来也不是很方便,在这个Demo里我使用了百度地图API ...
- Kafka技术原理
详情请参见:http://zqhxuyuan.github.io/2016/05/26/2016-05-13-Kafka-Book-Sample
- C#封装百度Web服务API处理包含(Geocoding API,坐标转换API)
1.创建基础参数类 public static class BaiduConstParams { public const string PlaceApIv2Search = "http:/ ...
- FA_在建工程转固定资产(流程)
2014-06-08 Created By BaoXinjian