Redis 之持久化
目录
一.前言
首先,来回顾下前面文章的知识.Redis的特性之一就是读取速度快,因为它的数据是存储在内存中的,但是这样还有它的不足之处,那就是当你服务器断电时或者进程产生进退后,那么你所存储在内存中的数据也就荡然无存了,可是这样会给我们带来丢失数据的危险.而Redis正是考虑到了这一点,所以便有了持久化的功能.而持久化的作用正像它的名称一样,便是为了保持数据的持久.
Redis的持久化类型有两种,一种是全量(RDB),一种是增量(AOF),今天这篇文章中便来聊聊这两种类型的特性和他们的优缺点,以及我们在这两种类型中如何做选择.
二.持久化类型之 RDB
1.什么事RDB?
RDB是把Redis中的完整的数据生成一个快照,然后保存到硬盘当中,那么这就是一个RDB文件了,不过这个RDB文件是一个二进制的文件.当你的Redis服务重启时,它会去载入这样的RDB文件.其作用便是为了备份数据和恢复数据,当然它也是一个复制的媒介,对于Redis的主从复制正式利用这个文件来完成的.
2.触发机制
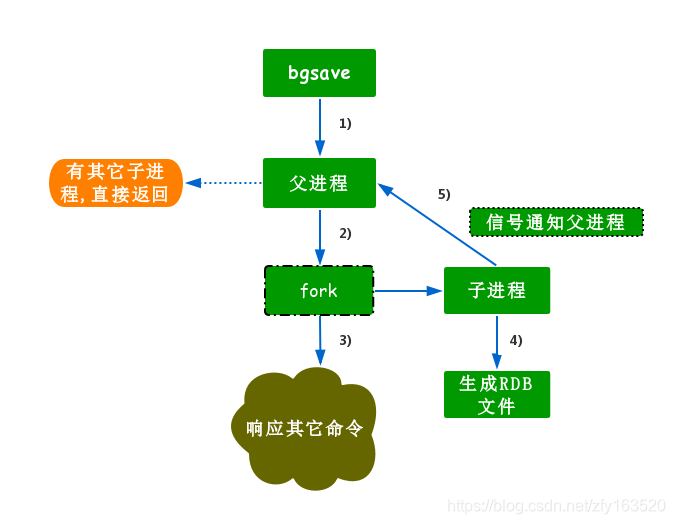
RDB的触发方式有两种,分别是:save(同步)和bgsave(异步).因为save的触发方式是同步的,那么它会阻塞当前的Redis服务器,直到RDB的过程完成为止,如果你的内存比较大的话,那么会造成长时间的阻塞,所以这在生产环境是不建议使用的.而bgsave是异步的,使用它时Redis的进程会执行fork操作来创建子进程,在RDB持久化的过程便交给子进程去负责了,完成后就回自动结束.对bgsave而言,它的阻塞只会发生在fork阶段,时间一般较短,但也有极少的情况下,会阻塞进程.
我们还需要注意以下几点:
1.save 可以在客户端显式触发,也可以在 shutdown 时自动触发;bgsave 可以在客户端显式触发,也可以通过配置由定时任务触发,也可以在 slave 节点触发.
2.默认执行 shutdown 时,如果没有开启 AOF,则自动执行 bgsave
3.因为RDB是全量的,所以每次使用RDB的时候 RDB 文件都是替换的.
3.RDB的优缺点
优点:
- RDB是紧凑压缩的二进制文件,是Redis某个时间点上的数据快照,比较适合用于备份和全量复制,例如每 6 小时执行 bgsave,保存到文件系统之类的.
- Redis 加载 RDB 恢复数据远远快于 AOF.
缺点:
- 无法实现到实时持久化/秒级持久化.因为bgsave每次都要执行fork操作子进程,这是重量级操作,执行成本过高.
- 老版本 Redis 无法兼容新版本 RDB文件.
RDB流程图:
三.持节化类型之AOF
1.什么事AOF?
AOF是一独立日志方式记录每次命令,其主要作用也是为了解决数据持久化的实时性,目前是Redis持久化的主流方式.
2.AOF的特性
- 使用AOF是需要设置配置:appendonly yes,默认是不开启的.AOF文件名是通过appendfilename配置的,默认文件名是:appendonly.aof. 保存的路径和RDB方式一致,通过dir配置指定.
- AOF每次都是append卸乳命令,因此实时性更高.
- AOF其实并不是直接把数据写入磁盘文件中,而是写在缓冲区(aof_bug)中,这也是为了提高写入效率,它可以根据不同的策略(always,everysec,no)向磁盘中做同步操作.
- 随着AOF写入的文件越来越大(因为AOF是增量的),所以需要定期对AOF进行重写,需要进行优化,称之为“重写机制”,以达到压缩的目的.
3.AOF缓冲区同步策略
AOF缓冲区同步策略,由参数 appendfsync 控制,一共3种:
1.alwayss:调用sync函数,操作同步到AOF文件,直到写入硬盘后返回,这将严重影响redis性能.(配置always时,每次都需要同步AOF文件,一般的SATA硬盘,Redis只有大约几百的TPS,显然是与Redis高性能背道而驰的,所以不建议配置)
2.everysec:调用系统write 函数,写入到缓存区后,直接返回.而fsync同步文件操作有专门的线程,每秒调用一次,推荐配置.(理论上系统宕机也就是丢失下一秒的数据)
3.no: 只执行 write OS 函数,不对AOF文件做fsync操作同步,具体同步硬盘策略由 OS 决定,通常周期最长为30秒,不推荐,数据不安全,容易丢失数据.
4.AOF重写机制
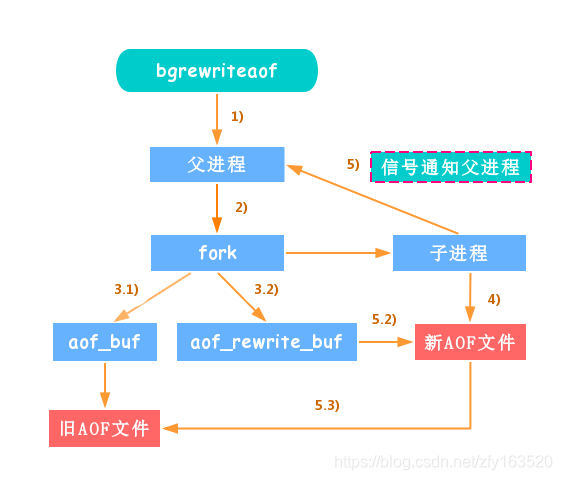
- 执行AOF重写请求,父进程fork子进程,开销等同于bgsave.
- 主进程会写到2个缓冲区,一个是原有的 “AOF 缓存区”,一个是专门为子进程准备的 “AOF 重写缓冲区”,用来保存部分新数据,防止新的AOF文件生成期间丢失这部分数据.
- 子进程根据内唇快照,按照命令合并规则写入到新的AOF文件,每次写入是批量的(写入的数据量可配置aof-rewrite-incremental-fsync),默认是30MB,防止单次刷入的数据量过多,造成阻塞.新的AOF文件写入完成后,子进程会通知父进程.
- 父进程吧AOF重写缓存区的数据写入新的AOF文件.
- 然后使用新的AOF替换老文件,至此完成重写.
重写流程图:
四.Redis 持久化类型的抉择
| 命令 | RDB | AOF |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 丢数据 | 根据策略决定 |
| 轻重 | 重 | 轻 |
RDB的最佳策略:
- 建议“关”掉RDB(这里的关用引号,是因为对于Redis的主从复制的全量复制是要我们的主节点执行一次bgsave,然后吧RDB文件传给从节点来实现一个复制的过程.)
- 集中管理(虽然RDB是一个很重的操作,但是对于数据备份是有一定作用的,如果按天/小时这样一个比较大的量级来备份数据,这样RDB是一个不错的选择,因为RDB文件比较小,这样传输速度会比较快,对于集中管理的备份比较有优势.
- 主从,从开?因为有时候需要在从节点开一下RDB,这样可以在本地去保存这样一个历史的RDB文件,这样有一定的优势但是一定要控制他的力度不要是save自动生成的频率会很频繁,这样的话从节点不进入Redis的读写,但是所有的Redis都是一个混合部署,就是单机多部署,因为RDB是一个很重的操作,可能仍然对机器本身,例如硬盘/CPU以及内存有一定的影响,所以要根据实际开发中的实际需求来进行设定
AOF的最佳策略
- “开”:缓存和存储,在大部分情况先建议打开AOF,这样能特别的体现出Redis的一个特点,就是可以实时持久化,并且在大部分情况下只会丢一秒数据,大部分情况下会设置每秒区刷新磁盘.但是例如有些时候,有些缓存的场景,完全使用Redis做缓存的功能,其实里面的数据丢失了,对系统并没有任何影响,只需要下次加载的时候从数据源重新加载进来就可以,而且它对数据源的压力也没有那么大,加入你的访问对数据源没有太大的压力,这个时候其实是可以关闭掉的.毕竟 AOF确实需要一定开销的,写缓冲区等都有一定的开销的.
- AOF重写集中管理:单机多部署的情况下AOF集中发生,就是产生大量的fork,但是机器的内存比如是16G,我们将会分配百分之六十到七十内存给Redis,剩余20-30来给fork做一个操作用的空间,但是这部分空间并不是很大的,假如集中做fork,就可能出现内存爆满,会出现swap的情况.
- everysec(每秒1是刷新)
最佳策略:小分片,缓存或者存储,监控(硬盘,内存,负载,网络),足够内存
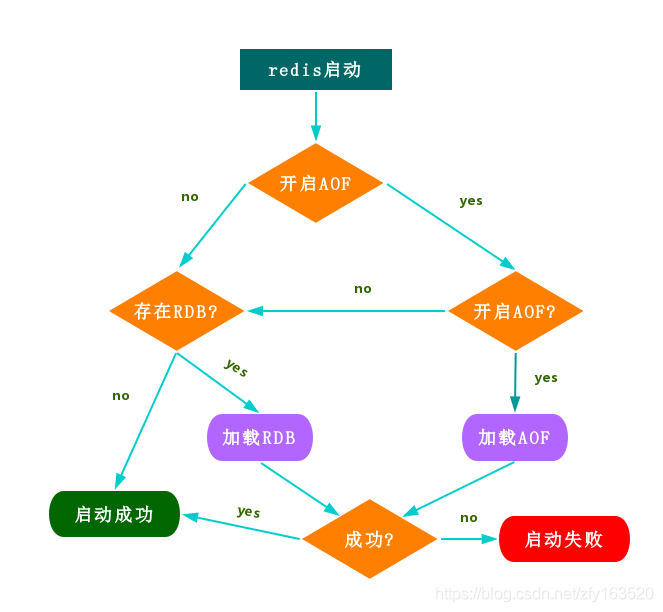
五.持久化的恢复
RDB 和 AOF 文件都可以用于服务器重启时来做数据恢复,具体恢复流程如图:
六.持久化问题的分析定位与优化
Redis持久化的功能一直是影响Redis性能的高发地,这也是我们日常工作与面试中常遇到的.
1.fork操作
当Redis做 RDB 或者 AOF 重写时,必不可少的是要进行 fork 操作,对于 大多数操作系统 来说,fork 都是一个重量级操作.虽然不会拷贝父进程所有的物理空间,但会复制父进程的空间内存页表.对于 10GB 的 Redis 进程,需要复制大约 20MB 的内存页表,因此 fork 操作耗时跟进程总内存量息息相关,如果还使用虚拟化技术,例如 Xen 虚拟机,fork 操作会更加耗时.
对于一个 Redis 实例的 OPS 在 5 万以上,如果 fork 操作耗时在秒级,那么将会拖慢几万条命令的执行,对生产环境影响明显.在正常情况下,fork操作的耗时应该是1GB/20ms左右,这个可以在 Info stats 统计中查询 latest_fork_usec 指标获取最近一次 fork 操作耗时,单位微秒.
优化方案:
- 优先使用物理机或者高效支持 fork 的虚拟化技术,避免使用 Xen.
- 控制 redis 实例最大可用内存,foek耗时跟内存量成正比,所以线上建议控制实力内存在 10GB 以内.
- 合理配置 Linux 内存分配策略,避免内存不足导致 fork 失败.
- 降低 fork操作 的频率,如适度放宽 AOF 自动触发时机,避免不必要的全量复制.
2.子进程开销和优化
fork 完毕之后,会创建子进程,子进程会负责 RDB 或者 AOF 重写,这部分过程主要涉及到 CPU,内存,硬盘三个地方的优化.
1)cpu
cpu开销分析与优化
子进程负责吧进程内的数据分批写入文件,这个写入文件的过程是 CPU 密集的过程,通常子进程对单核 CPU 利用率接近 90%. 优化方法:Redis是 CPU 密集型服务,不要绑定单核 CPU,由于子进程会非常消耗CPU,所以这样会和父 CPU 进行竞争.同时,不要和其他 CPU 密集型服务部署在一个机器上。如果部署了多个 Redis 实例,尽力保证统一时刻只有一个子进程执行重写工作.
2)内存
子进程通过 fork 操作产生,占用内存大小等同于父进程,理论上需要两倍的内存完成持久化操作,但 Linux 有复制机制 (copy on write ).父子进程会共享相同的物理内存页,当父进程处理写操作时,会把要修改的页创建对应的副本,而子进程在 fork 操作过程中,共享整个父进程内存快照. 如果重写过程中存在内存修改操作,父进程负责创建所修改内存页的副本.这里就是内存消耗的地方. 优化方法:和cpu一样,如果部署多个Redis实例,尽量保证同一时刻只有一个子进程在工作;避免大量写入时做子进程重写操作,这样会导致父进程维护大量的快照副本,造成内存消耗.
3)硬盘开销分析
进程主要职责是将 RDB 或者 AOF 文件写入硬盘进行持久化,势必造成对硬盘造成压力,可通过工具例如 iostat,iotop 等工具分析重写期间硬盘负载情况.
优化方法:
(a).不要和其他高硬盘负载的服务放在一台机器上,例如 MQ,存储服务.
(b)AOF 重写时会消耗大量硬盘 IO,可以开启配置 no-appendfsync-on-rewrite,默认关闭。表示在 AOF 重写期间不做 fsync 操作.
(c)当开启 AOF 的 Redis 在高并发场景下,如果使用普通机械硬盘,每秒的写速率是 100MB左右,这时,Redis 的性能瓶颈在硬盘上,建议使用 SSD.
(d)对于单机配置多个 Redis 实例的情况,可以配置不同实例分盘存储 AOF 文件,分摊硬盘的写入压力.
3. AOF 追加阻塞
当开启 AOF 持久化时,常用的同步硬盘的策略是everysec,用于平衡性能和数据安全性.对于这种方式,Redis 使用另一条线程每秒执行 fsync 同步硬盘.当系统资源繁忙时,将造成 Redis 主线程阻塞.
如图所示:
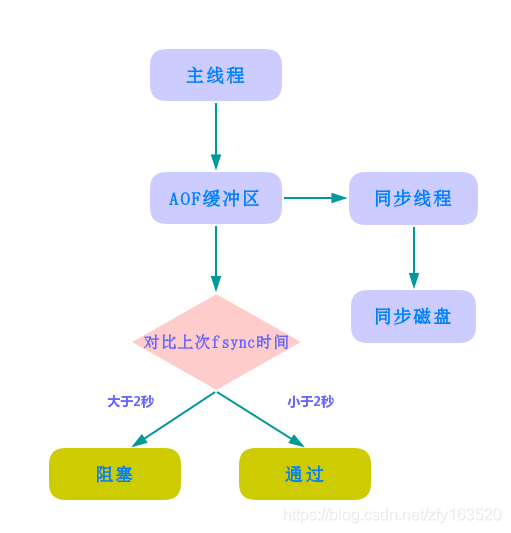
从上图中可以发现:everysec 配置最多可能丢失 2 秒数据,不是 1 秒;如果系统 fsync 缓慢,将会导致 Redis 主线程阻塞影响效率.
问题定位:
- 发生 AOF 阻塞时,会输入日志。用于记录 AOF fsync 阻塞导致拖慢 Redis 服务的行为.
- 每当 AOF 追加阻塞事件发生时,在 info Persistence 统计中,aof_delayed_fsync 指标会累加,查看这个指标方便定位 AOF 阻塞问题.
- AOF 同步最多运行 2 秒的延迟,当延迟发生时说明硬盘存在性能问题,可通过监控工具 iotop 查看,定位消耗 IO 的进程.
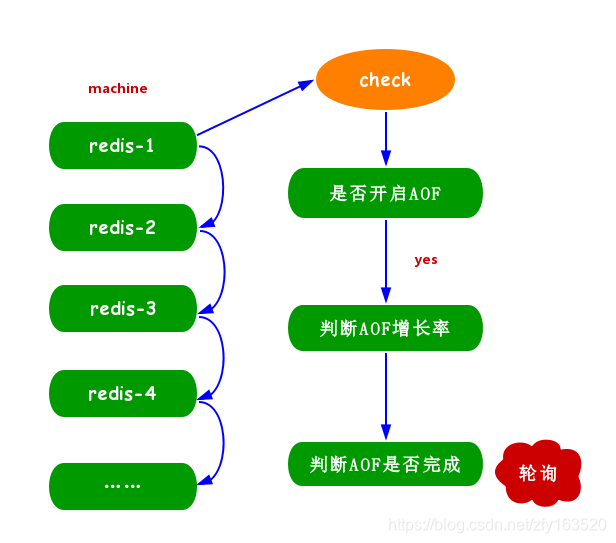
4. 单机多实例部署
Redis 单线程架构无法充分利用多核CPU,通常的做法是一台机器上部署多个实例,当多个实例开启 AOF 后,彼此之间就会产生CPU 和 IO 的竞争.
解决方法:让所有实例的 AOF 串行执行.我们通过 info Persistence 中关于 AOF 的信息写出 Shell 脚本,然后串行执行实例的 AOF 持久化.
info Persistence片段度量指标表:
|
属性名 |
属性值 |
|---|---|
| rdb_bgsave_in_progress | bgsave子进程是否正在运行 |
| rdb_current_bgsave_time_sec | 当前运行bgsave的时间,-1表示未运行 |
| aof_enabled | 是否开启AOF功能 |
| aof_rewrite_in_progress | AOF重写子进程是否正在运行 |
| aof_rewrite_scheduled | 在bgsave结束后是否运行AOF重写 |
| aof_current_rewrite_time_sec | 当前运行AOF重写的时间,-1表示未运行 |
| aof_current_size | AOF文件当前字节数 |
| aof_base_size | AOF上次重写rewrite字节数 |
基于以上指标,可以通过外部轮询控制AOF的重写操作的执行,整个过程如图:
七.回顾总结
本文讲了 Redis 的持久化相关功能,例如持久化的类型,持久化每种类型的优缺点,Redis 持久化类型的选择,持久化湿如何恢复的,还有持久化问题的分析定位与优化.
参考:《redis开发与运维》,《深入分布式缓存》
版权声明:尊重博主原创文章,转载请注明出处 https://www.cnblogs.com/hsdy
Redis 之持久化的更多相关文章
- Redis总结(四)Redis 的持久化
前面已经总结了Redis 的安装和使用今天讲下Redis 的持久化. redis跟memcached类似,都是内存数据库,不过redis支持数据持久化,也就是说redis可以将内存中的数据同步到磁盘来 ...
- Redis的持久化的两种方式drbd以及aof日志方式
redis的持久化配置: 主要包括两种方式:1.快照 2 日志 来看一下redis的rdb的配置选项和它的工作原理: save 900 1 // 表示的是900s内,有1条写入,则产生快照 save ...
- redis启用持久化
redis的持久化有rdb和aof两种. rdb是记录一段时间内的操作,一盘的配置是一段时间内操作超过多少次就持久化. aof可以实现每次操作都持久化. 这里我们使用aof. 配置方式,打开redis ...
- redis + 主从 + 持久化 + 分片 + 集群 + spring集成
Redis是一个基于内存的数据库,其不仅读写速度快,每秒可以执行大约110000的写操作,81000的读取操作,而且其支持存储字符串,哈希结构,链表,集合丰富的数据类型.所以得到很多开发者的青睐.加之 ...
- Redis笔记(八)Redis的持久化
Redis相比Memcached的很大一个优势是支持数据的持久化, 通常持久化的场景一个是做数据库使用,另一个是Redis在做缓存服务器时,防止缓存失效. Redis的持久化主要有快照Snapshot ...
- 深入剖析 redis AOF 持久化策略
本篇主要讲的是 AOF 持久化,了解 AOF 的数据组织方式和运作机制.redis 主要在 aof.c 中实现 AOF 的操作. 数据结构 rio redis AOF 持久化同样借助了 struct ...
- 深入剖析 redis RDB 持久化策略
简介 redis 持久化 RDB.AOF redis 提供两种持久化方式:RDB 和 AOF.redis 允许两者结合,也允许两者同时关闭. RDB 可以定时备份内存中的数据集.服务器启动的时候,可以 ...
- redis 数据持久化
1.快照(snapshots) 缺省情况情况下,Redis把数据快照存放在磁盘上的二进制文件中,文件名为dump.rdb.你可以配置Redis的持久化策略,例如数据集中每N秒钟有超过M次更新,就将数据 ...
- redis的持久化之AOF
AOF Redis 分别提供了 RDB 和 AOF 两种持久化机制: RDB 将数据库的快照(snapshot)以二进制的方式保存到磁盘中. AOF 则以协议文本的方式,将所有对数据库进行过写入的命令 ...
- redis的持久化方式RDB和AOF的区别
1.前言 最近在项目中使用到Redis做缓存,方便多个业务进程之间共享数据.由于Redis的数据都存放在内存中,如果没有配置持久化,redis重启后数据就全丢失了,于是需要开启redis的持久化功能, ...
随机推荐
- 2.MySQL 数据类型
MySQL 数据类型 MySQL中定义数据字段的类型对你数据库的优化是非常重要的. MySQL支持多种类型,大致可以分为三类:数值.日期/时间和字符串(字符)类型. 数值类型 MySQL支持所有标准S ...
- java线程操作
目录 前言 创建多线程的方式 1继承thread抽象类 2实现Runnable接口 3实现Callable接口 匿名内部类 线程池 线程安全 同步代码块 同步方法 锁机制 线程状态 前言 进程:内存运 ...
- Oracle replace()函数
往Oracle 中导入数据时,有一个列导入的数据应该时‘2017-04-17’ 的格式,结果导入的数据为 ‘2017/04/17’格式的,1000多条记录要一条条改基本不可能. 于是想到了replac ...
- 学习笔记:如何阻止Web应用存储敏感数据
在某些情况下,自定义Web应用会保存敏感(专有)数据到用户的缓存文件夹中.如果不重新架构该应用,使用Sysinternals SDelete的注销脚本是否可以确保数据完全被删除且没有任何可恢复残留呢? ...
- SQL函数应用-DATEPART()
作用:DATEPART() 函数用于返回日期/时间的单独部分,比如年.月.日.小时.分钟等等. 语法格式:DATEPART(datepart,date) 参数说明: datepart 是指定应返回的日 ...
- oracle的乐观锁和悲观锁
一.问题引出 1. 假设当当网上用户下单买了本书,这时数据库中有条订单号为001的订单,其中有个status字段是’有效’,表示该订单是有效的: 2. 后台管理人员查询到这条001的订单,并且看到状态 ...
- 【分享·微信支付】 C# MVC 微信支付教程系列之公众号支付
微信支付教程系列之公众号支付 今天,我们接着讲微信支付的系列教程,前面,我们讲了这个微信红包和扫码支付.现在,我们讲讲这个公众号支付.公众号支付的应用环境常见的用户通过公众号,然后 ...
- Android开发精彩博文收藏——UI界面类
本文收集整理Android开发中关于UI界面的相关精华博文,共大家参考!本文不定期更新! 1. Android使用Fragment来实现TabHost的功能(解决切换Fragment状态不保存)以及各 ...
- [翻译] Shimmer
Shimmer Shimmer is an easy way to add a shimmering effect to any view in your app. It's useful as an ...
- except but
He didn't speak anything but Greek... 他只会说希腊语.The crew of the ship gave them nothing but bread to ea ...