lucene字典实现原理
http://www.cnblogs.com/LBSer/p/4119841.html
1 lucene字典
使用lucene进行查询不可避免都会使用到其提供的字典功能,即根据给定的term找到该term所对应的倒排文档id列表等信息。实际上lucene索引文件后缀名为tim和tip的文件实现的就是lucene的字典功能。
怎么实现一个字典呢?我们马上想到排序数组,即term字典是一个已经按字母顺序排序好的数组,数组每一项存放着term和对应的倒排文档id列表。每次载入索引的时候只要将term数组载入内存,通过二分查找即可。这种方法查询时间复杂度为Log(N),N指的是term数目,占用的空间大小是O(N*str(term))。排序数组的缺点是消耗内存,即需要完整存储每一个term,当term数目多达上千万时,占用的内存将不可接受。
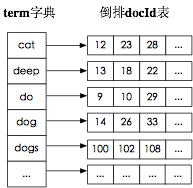
2 常用字典数据结构
很多数据结构均能完成字典功能,总结如下。
| 数据结构 | 优缺点 |
| 排序列表Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,内存消耗大,几乎是原始数据的三倍 |
| Skip List | 跳跃表,可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景(Skip List介绍) |
| Trie | 适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存(数据结构之trie树) |
| Double Array Trie | 适合做中文词典,内存占用小,很多分词工具均采用此种算法(深入双数组Trie) |
| Ternary Search Tree | 三叉树,每一个node有3个节点,兼具省空间和查询快的优点(Ternary Search Tree) |
| Finite State Transducers (FST) | 一种有限状态转移机,Lucene 4有开源实现,并大量使用 |
3 FST原理简析
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。
下面简单描述下FST的构造过程(工具演示:http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it%21)。我们对“cat”、 “deep”、 “do”、 “dog” 、“dogs”这5个单词进行插入构建FST(注:必须已排序)。
1)插入“cat”
插入cat,每个字母形成一条边,其中t边指向终点。

2)插入“deep”
与前一个单词“cat”进行最大前缀匹配,发现没有匹配则直接插入,P边指向终点。

3)插入“do”
与前一个单词“deep”进行最大前缀匹配,发现是d,则在d边后增加新边o,o边指向终点。

4)插入“dog”
与前一个单词“do”进行最大前缀匹配,发现是do,则在o边后增加新边g,g边指向终点。

5)插入“dogs”
与前一个单词“dog”进行最大前缀匹配,发现是dog,则在g后增加新边s,s边指向终点。

最终我们得到了如上一个有向无环图。利用该结构可以很方便的进行查询,如给定一个term “dog”,我们可以通过上述结构很方便的查询存不存在,甚至我们在构建过程中可以将单词与某一数字、单词进行关联,从而实现key-value的映射。
4 FST使用与性能评测
我们可以将FST当做Key-Value数据结构来进行使用,特别在对内存开销要求少的应用场景。Lucene已经为我们提供了开源的FST工具,下面的代码是使用说明。
public static void main(String[] args) {
try {
String inputValues[] = {"cat", "deep", "do", "dog", "dogs"};
long outputValues[] = {5, 7, 17, 18, 21};
PositiveIntOutputs outputs = PositiveIntOutputs.getSingleton(true);
Builder<Long> builder = new Builder<Long>(FST.INPUT_TYPE.BYTE1, outputs);
BytesRef scratchBytes = new BytesRef();
IntsRef scratchInts = new IntsRef();
for (int i = 0; i < inputValues.length; i++) {
scratchBytes.copyChars(inputValues[i]);
builder.add(Util.toIntsRef(scratchBytes, scratchInts), outputValues[i]);
}
FST<Long> fst = builder.finish();
Long value = Util.get(fst, new BytesRef("dog"));
System.out.println(value); //
} catch (Exception e) {
;
}
}
FST压缩率一般在3倍~20倍之间,相对于TreeMap/HashMap的膨胀3倍,内存节省就有9倍到60倍!(摘自:把自动机用作 Key-Value 存储),那FST在性能方面真的能满足要求吗?
下面是我在苹果笔记本(i7处理器)进行的简单测试,性能虽不如TreeMap和HashMap,但也算良好,能够满足大部分应用的需求。

参考文献
http://sbp810050504.blog.51cto.com/2799422/1361551
http://blog.sina.com.cn/s/blog_4bec92980101hvdd.html
http://blog.mikemccandless.com/2013/06/build-your-own-finite-state-transducer.html
检索实践文章系列:
lucene如何通过docId快速查找field字段以及最近距离等信息?
lucene字典实现原理的更多相关文章
- lucene字典实现原理——FST
转自:http://www.cnblogs.com/LBSer/p/4119841.html 1 lucene字典 使用lucene进行查询不可避免都会使用到其提供的字典功能,即根据给定的term找到 ...
- lucene字典实现原理(转)
原文:https://www.cnblogs.com/LBSer/p/4119841.html 1 lucene字典 使用lucene进行查询不可避免都会使用到其提供的字典功能,即根据给定的term找 ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- iOS 字典实现原理
在目前的开发中,NSDictionary是经常被使用,不过很少人会研究字典NSDictionary底层的实现,下面我们来一起看一下NSDictionary的实现原理. 一.字典原理 字典通过使用- ( ...
- 03.什么是Lucene全文检索的原理01
全文检索的原理:查询速度快,精准度高,可以根据相关度进行排序.它的原理是:先把内容分词,分词之后建索引. Lucene是apache下的一个开放源代码的全文检索引擎工具包. 提供了完整的查询引擎和索引 ...
- 42 (OC)* 字典实现原理--哈希原理
一.NSDictionary使用原理 1.NSDictionary(字典)是使用 hash表来实现key和value之间的映射和存储的,hash函数设计的好坏影响着数据的查找访问效率. - (void ...
- lucene索引文件大小优化小结
http://www.cnblogs.com/LBSer/p/4068864.html 随着业务快速发展,基于lucene的索引文件zip压缩后也接近了GB量级,而保持索引文件大小为一个可以接受的范围 ...
- lucene join解决父子关系索引
http://www.cnblogs.com/LBSer/p/4417074.html 1 背景 以商家(Poi)维度来展示各种服务(比如团购(deal).直连)正变得越来越流行(图1a), 比如目前 ...
- lucene如何通过docId快速查找field字段以及最近距离等信息?
http://www.cnblogs.com/LBSer/p/4419052.html 1 问题描述 我们的检索排序服务往往需要结合个性化算法来进行重排序,一般来说分两步:1)进行粗排序,这一过程由检 ...
随机推荐
- Linux内核模块简介
一. 摘要 这篇文章主要介绍了Linux内核模块的相关概念,以及简单的模块开发过程.主要从模块开发中的常用指令.内核模块程序的结构.模块使用计数以及模块的编译等角度对内核模块进行介绍.在Linux系统 ...
- Mahout源码分析之 -- QR矩阵分解
一.算法原理 请参考我在大学时写的<QR方法求矩阵全部特征值>,其包含原理.实例及C语言实现:http://www.docin.com/p-114587383.html 二.源码分析 这里 ...
- java线程的理解
java thread类都是native方法实现的,所以没有用平台无关的方法实现,怎么实现的呢? 线程的实现: 第一种:使用内核线程实现. 内核线程就是直接使用操作系统内核支持的线程,由内核完成切换. ...
- eclipse4.x 启动之后, "Initializing Java Tooling" 卡住问题解决
eclipse4.x 启动之后, "Initializing Java Tooling(1%)",其他操作均被阻塞,导致无法正常工作, 解决方案: 删除当前工作目录下的worksp ...
- JAVA通过HTTP访问:Post+Get方式(转)
public class TestGetPost { /** * 向指定URL发送GET方法的请求 * @param url 发送请求的URL * @param param 请求参数,请求参数应该是n ...
- 退役?OR 继续
今天突然想了好多.上次CB那么决绝的退役,还有其他的一些东西.觉得大家说的都挺对的.看待问题的方式不同,然后或多或少就变了.预备役的事情就是想能不能不让大家因为上不了场退役. 想起以前的自己那么坚决的 ...
- [转] 你是as3老鸟吗?但是有些你可能目前都不知道的东西
你是as3老鸟吗?如果以下内容对你有莫大的帮助,请顶下! 一:加载swf库中的图片 new 的过程就是图片解压缩的过程.处于 Class 状态时,图片占用的内存和 SWF 文件中这个图片占用的磁盘空间 ...
- oracle备忘
一.explain plan a)explain plan for select ... select * from table(dbms_xplan.display()); function dis ...
- ObjC.class-cluster
class cluster In a class cluster, only an abstract superclass is public. Allocating an instance actu ...
- 20145225《Java程序设计》 第4周学习总结
20145225<Java程序设计> 第4周学习总结 教材学习内容总结 第六章 继承与多态 6.1继承 继承共同行为:存在着重复,可把相同的程序代码提升(pull up)为父类.exten ...