Flink 剖析
1.概述
在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷。今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一。那么,接下来,笔者为大家介绍Flink 的相关内容。
2.内容
2.1 What's Flink
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们它们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。 Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
Flink 是一款新的大数据处理引擎,目标是统一不同来源的数据处理。这个目标看起来和 Spark 和类似。这两套系统都在尝试建立一个统一的平台可以运行批量,流式,交互式,图处理,机器学习等应用。所以,Flink 和 Spark 的目标差异并不大,他们最主要的区别在于实现的细节。
下面附上 Flink 技术栈的一个总览,如下图所示:
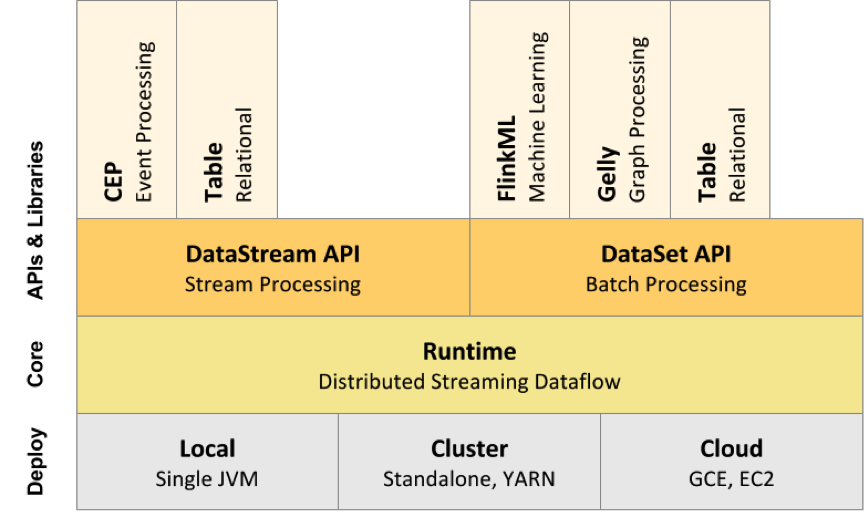
2.2 Compare
了解 Flink 的作用和优缺点,需要有一个参照物,这里,笔者以它与 Spark 来对比阐述。从抽象层,内存管理,语言实现,以及 API 和 SQL 等方面来赘述。
2.2.1 Abstraction
接触过 Spark 的同学,应该比较熟悉,在处理批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming,然其世纪还是 RDD,所以本质上还是 RDD 抽象而来。但是,在 Flink 中,批处理用 DataSet,对于流处理,有 DataStreams。思想类似,但却有所不同:其一,DataSet 在运行时表现为 Runtime Plans,而在 Spark 中,RDD 在运行时表现为 Java Objects。在 Flink 中有 Logical Plan ,这和 Spark 中的 DataFrames 类似。因而,在 Flink 中,若是使用这类 API ,会被优先来优化(即:自动优化迭代)。如下图所示:
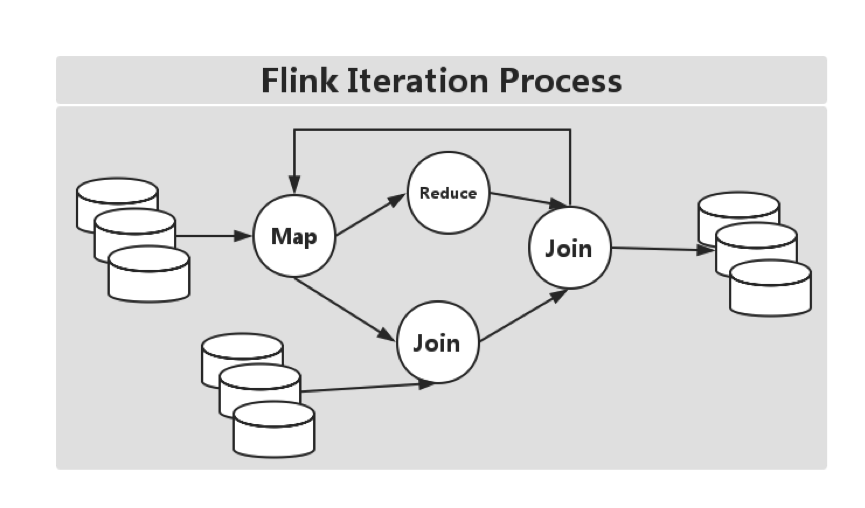
然而,在 Spark 中,RDD 就没有这块的相关优化,如下图所示::
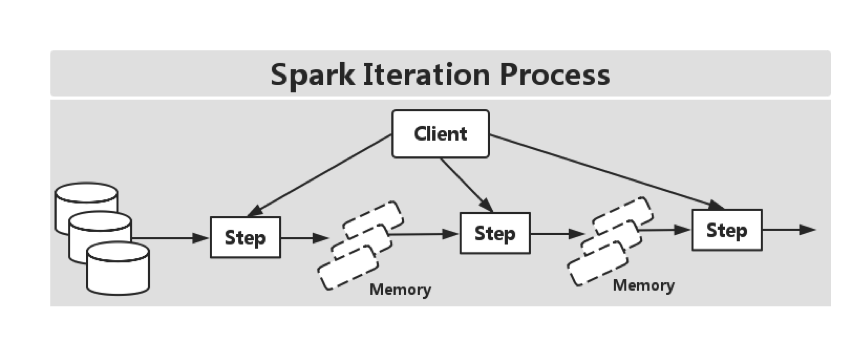
另外,DataSet 和 DataStream 是相对独立的 API,在 Spark 中,所有不同的 API,比如 Streaming,DataFrame 都是基于 RDD 抽象的。然而在 Flink 中,DataSet 和 DataStream 是同一个公用引擎之上的两个独立的抽象。所以,不能把这两者的行为合并在一起操作,目前官方正在处理这种问题,详见[FLINK-2320]
2.2.2 Memory
在之前的版本(1.5以前),Spark 延用 Java 的内存管理来做数据缓存,这样很容易导致 OOM 或者 GC。之后,Spark 开始转向另外更加友好和精准的控制内存,即:Tungsten 项目。然而,对于 Flink 来说,从一开始就坚持使用自己控制内存。Flink 除把数据存在自己管理的内存之外,还直接操作二进制数据。在 Spark 1.5之后的版本开始,所有的 DataFrame 操作都是直接作用于 Tungsten 的二进制数据上。
PS:Tungsten 项目将是 Spark 自诞生以来内核级别的最大改动,以大幅度提升 Spark 应用程序的内存和 CPU 利用率为目标,旨在最大程度上利用硬件性能。该项目包括了三个方面的改进:
- 内存管理和二进制处理:更加明确的管理内存,消除 JVM 对象模型和垃圾回收开销。
- 缓存友好计算:使用算法和数据结构来实现内存分级结构。
- 代码生成:使用代码生成来利用新型编译器和 CPU。
2.2.3 Program
Spark 使用 Scala 来实现的,它提供了 Java,Python 以及 R 语言的编程接口。而对于 Flink 来说,它是使用 Java 实现的,提供 Scala 编程 API。从编程语言的角度来看,Spark 略显丰富一些。
2.2.4 API
Spark 和 Flink 两者都倾向于使用 Scala 来实现对应的业务。对比两者的 WordCount 示例,很类似。如下所示,分别为 RDD 和 DataSet API 的示例代码:
- RDD
// Spark WordCount
object WordCount {
def main(args: Array[String]) {
val env = new SparkContext("local","WordCount")
val data = List("hi","spark cluster","hi","spark")
val dataSet = env.parallelize(data)
val words = dataSet.flatMap(value => value.split("\\s+"))
val mappedWords = words.map(value => (value,1))
val sum = mappedWords.reduceByKey(_+_)
println(sum.collect())
}
}
- DataSet
// Flink WordCount
object WordCount {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
val data = List("hello","flink cluster","hello")
val dataSet = env.fromCollection(data)
val words = dataSet.flatMap(value => value.split("\\s+"))
val mappedWords = words.map(value => (value,1))
val grouped = mappedWords.groupBy(0)
val sum = grouped.sum(1)
println(sum.collect())
}
}
对于 Streaming,Spark 把它看成更快的批处理,而 Flink 把批处理看成 Streaming 的特殊例子,差异如下:其一,在实时计算问题上,Flink 提供了基于每个事件的流式处理机制,所以它可以被认为是一个真正意义上的流式计算,类似于 Storm 的计算模型。而对于 Spark 来说,不是基于事件粒度的,而是用小批量来模拟流式,也就是多个事件的集合。所以,Spark 被认为是一个接近实时的处理系统。虽然,大部分应用实时是可以接受的,但对于很多应用需要基于事件级别的流式计算。因而,会选择 Storm 而不是 Spark Streaming,现在,Flink 也许是一个不错的选择。
2.2.5 SQL
目前,Spark SQL 是其组件中较为活跃的一部分,它提供了类似于 Hive SQL 来查询结构化数据,API 依然很成熟。对于 Flink 来说,截至到目前 1.0 版本,只支持 Flink Table API,官方在 Flink 1.1 版本中会添加 SQL 的接口支持。[Flink 1.1 SQL 详情计划]
3.Features
Flink 包含一下特性:
- 高吞吐 & 低延时
- 支持 Event Time & 乱序事件
- 状态计算的 Exactly-Once 语义
- 高度灵活的流式窗口
- 带反压的连续流模型
- 容错性
- 流处理和批处理共用一个引擎
- 内存管理
- 迭代 & 增量迭代
- 程序调优
- 流处理应用
- 批处理应用
- 类库生态
- 广泛集成
3.1 高吞吐 & 低延时
Flink 的流处理引擎只需要很少配置就能实现高吞吐率和低延迟。下图展示了一个分布式计数的任务的性能,包括了流数据 shuffle 过程。

3.2 支持 Event Time & 乱序事件
Flink 支持了流处理和 Event Time 语义的窗口机制。Event time 使得计算乱序到达的事件或可能延迟到达的事件更加简单。如下图所示:

3.3 状态计算的 exactly-once 语义
流程序可以在计算过程中维护自定义状态。Flink 的 checkpointing 机制保证了即时在故障发生下也能保障状态的 exactly once 语义。
3.4 高度灵活的流式窗口
Flink 支持在时间窗口,统计窗口,session 窗口,以及数据驱动的窗口,窗口可以通过灵活的触发条件来定制,以支持复杂的流计算模式。
3.5 带反压的连续流模型
数据流应用执行的是不间断的(常驻)operators。Flink streaming 在运行时有着天然的流控:慢的数据 sink 节点会反压(backpressure)快的数据源(sources)。
3.6 容错性
Flink 的容错机制是基于 Chandy-Lamport distributed snapshots 来实现的。这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。
3.7 流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。如下图所示:

3.8 内存管理
Flink 在 JVM 中实现了自己的内存管理。应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。
3.9 迭代和增量迭代
Flink 具有迭代计算的专门支持(比如在机器学习和图计算中)。增量迭代可以利用依赖计算来更快地收敛。如下图所示:
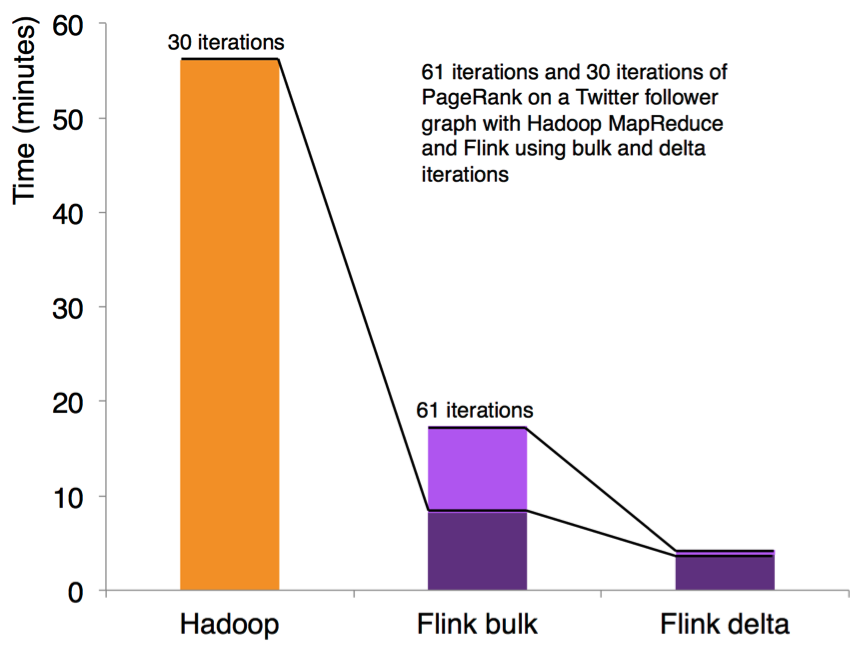
3.10 程序调优
批处理程序会自动地优化一些场景,比如避免一些昂贵的操作(如 shuffles 和 sorts),还有缓存一些中间数据。
3.11 流处理应用
DataStream API 支持了数据流上的函数式转换,可以使用自定义的状态和灵活的窗口。下面示例展示了如何以滑动窗口的方式统计文本数据流中单词出现的次数。
case class Word(word: String, freq: Long) val texts: DataStream[String] = ... val counts = text
.flatMap { line => line.split("\\W+") }
.map { token => Word(token, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("freq")
3.12 批处理应用
Flink 的 DataSet API 可以使你用 Java 或 Scala 写出漂亮的、类型安全的、可维护的代码。它支持广泛的数据类型,不仅仅是 key/value 对,以及丰富的 operators。下面示例展示了图计算中 PageRank 算法的一个核心循环。
case class Page(pageId: Long, rank: Double)
case class Adjacency(id: Long, neighbors: Array[Long]) val result = initialRanks.iterate(30) { pages =>
pages.join(adjacency).where("pageId").equalTo("pageId") { (page, adj, out : Collector[Page]) => {
out.collect(Page(page.id, 0.15 / numPages)) for (n <- adj.neighbors) {
out.collect(Page(n, 0.85*page.rank/adj.neighbors.length))
}
}
}
.groupBy("pageId").sum("rank")
}
3.13 类库生态
Flink 栈中提供了很多高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理。当前类库还在 beta 状态,并且在大力发展。
3.14 广泛集成
Flink 与开源大数据处理生态系统中的许多项目都有集成。Flink 可以运行在 YARN 上,与 HDFS 协同工作,从 Kafka 中读取流数据,可以执行 Hadoop 程序代码,可以连接多种数据存储系统。如下图所示:

4.总结
以上,便是对 Flink 做一个简要的剖析认识,至于如何使用 Flink,以及其编译,安装,部署,运行等流程,较为简单,这里就不多做赘述了,大家可以在 Flink 的官网,阅读其 QuickStart 即可,[访问地址]。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Flink 剖析的更多相关文章
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- Flink初始
flink初始 flink是什么 为什么使用flink flink的基础概念 flink剖析 实例 flink是什么 flink是一个用于有界和无界数据流进行有状态的计算框架. flink提供了不同级 ...
- Flink 集群运行原理兼部署及Yarn运行模式深入剖析
1 Flink的前世今生(生态很重要) 原文:https://blog.csdn.net/shenshouniu/article/details/84439459 很多人可能都是在 2015 年才听到 ...
- Flink源码分析 - 剖析一个简单的Flink程序
本篇文章首发于头条号Flink程序是如何执行的?通过源码来剖析一个简单的Flink程序,欢迎关注头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech) ...
- 从"UDF不应有状态" 切入来剖析Flink SQL代码生成
从"UDF不应有状态" 切入来剖析Flink SQL代码生成 目录 从"UDF不应有状态" 切入来剖析Flink SQL代码生成 0x00 摘要 0x01 概述 ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- Flink SQL 核心概念剖析与编程案例实战
本次,我们从 0 开始逐步剖析 Flink SQL 的来龙去脉以及核心概念,并附带完整的示例程序,希望对大家有帮助! 本文大纲 一.快速体验 Flink SQL 为了快速搭建环境体验 Flink SQ ...
- Flink Runtime核心机制剖析(转)
本文主要介绍 Flink Runtime 的作业执行的核心机制.本文将首先介绍 Flink Runtime 的整体架构以及 Job 的基本执行流程,然后介绍在这个过程,Flink 是怎么进行资源管理. ...
- 咱们从头到尾讲一次 Flink 网络流控和反压剖析
本文根据 Apache Flink 系列直播整理而成,由 Apache Flink Contributor.OPPO 大数据平台研发负责人张俊老师分享.主要内容如下: 网络流控的概念与背景 TCP的流 ...
随机推荐
- LINQ to SQL大全
LINQ to SQL语句 (1)之Where Where操作 适用场景:实现过滤,查询等功能. 说明:与SQL命令中的Where作用相似,都是起到范围限定也就是过滤作用的,而判断条件就是它后面所接的 ...
- Magcodes.WeiChat——自定义CustomCreationConverter之实现微信自定义菜单的序列化
微信自定义菜单接口是一个比较麻烦的接口,往往开发的小伙伴们看到下面的这段返回JSON,整个人就会不好了: {"menu":{"button":[{" ...
- Magicodes.WeiChat——自定义knockoutjs template、component实现微信自定义菜单
本人一向比较喜欢折腾,玩了这么久的knockoutjs,总觉得不够劲,于是又开始准备折腾自己了. 最近在完善Magicodes.WeiChat微信开发框架时,发现之前做的自定义菜单这块太不给力了,而各 ...
- [游戏模版12] Win32 稳定定时
>_<:The last time,we learned how to use timer to make the picture run and change show,but some ...
- [游戏学习27] MFC 匀速运动
>_<:理解上一个时间函数的概念和用法,本节的实现也比较简单 >_<:就是简单的绘图+时间函数 >_<:TicTac.h #define EX 1 //该点左鼠标 ...
- 找出字符串中第一个不重复的字符(JavaScript实现)
如题~ 此算法仅供参考,小菜基本不懂高深的算法,只能用最朴实的思想去表达. //找出字符串中第一个不重复的字符 // firstUniqueChar("vdctdvc"); --& ...
- python常用sql语句
#coding=utf-8 import MySQLdb conn = MySQLdb.Connect(host = '127.0.0.1',port=3306,user='root',passwd= ...
- Node + Express + Mysql的CMS小结
因为之前用过上述的组合完成过很多系统,而这一次是为了实现一个帮助系统的静态网页发布.因为很久不写,重点说遇到的几个坑: 1.库版本的问题 比如mysql连接数据库一直报错,因为系统重装过,所以重新安装 ...
- React学习资料
以下是我整理的React学习资料,包括:React基础.Redux.reat-router, redux middleware, higher order components, React验证等, ...
- Swift - UIView的无损截图
Swift - UIView的无损截图 效果 源码 // // UIView+ScreensShot.swift // Swift-Animations // // Created by YouXia ...