通过JDBC连接hive
hive是大数据技术簇中进行数据仓库应用的基础组件,是其它类似数据仓库应用的对比基准。基础的数据操作我们可以通过脚本方式以hive-client进行处理。若需要开发应用程序,则需要使用hive的jdbc驱动进行连接。本文以hive wiki上示例为基础,详细讲解了如何使用jdbc连接hive数据库。hive wiki原文地址:
https://cwiki.apache.org/confluence/display/Hive/HiveClient
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-JDBC
首先hive必须以服务方式启动,我们平台选用hdp平台,hdp2.2平台默认启动时hive server2 模式。hiveserver2是比hiveserver更高级的服务模式,提供了hiveserver不能提供的并发控制、安全机制等高级功能。服务器启动以不同模式启动,客户端代码的编码方式也略有不同,具体见代码。
服务启动完成之后,在eclipse环境中编辑代码。代码如下:
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager; public class HiveJdbcClient { /*hiverserver 版本使用此驱动*/ //private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
/*hiverserver2 版本使用此驱动*/
private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
} /*hiverserver 版本jdbc url格式*/
//Connection con = DriverManager.getConnection("jdbc:hive://hostip:10000/default", "", ""); /*hiverserver2 版本jdbc url格式*/
Connection con = DriverManager.getConnection("jdbc:hive2://hostip:10000/default", "hive", "hive");
Statement stmt = con.createStatement();
//参数设置测试
//boolean resHivePropertyTest = stmt
// .execute("SET tez.runtime.io.sort.mb = 128"); boolean resHivePropertyTest = stmt
.execute("set hive.execution.engine=tez");
System.out.println(resHivePropertyTest); String tableName = "testHiveDriverTable";
stmt.executeQuery("drop table " + tableName);
ResultSet res = stmt.executeQuery("create table " + tableName + " (key int, value string)"); //show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
} //describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
} // load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
String filepath = "/tmp/a.txt";
sql = "load data local inpath '" + filepath + "' into table " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql); // select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
} // regular hive query
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
} } }
可以将如下jar包放在eclipse buildpath,可以在启动时放在classpath路径。
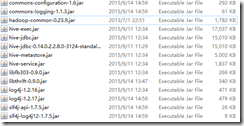
其中jdbcdriver可用hive-jdbc.jar,这样的话,其他的jar也必须包含,或者用jdbc-standalone jar包,用此jar包其他jar包就可以不用包含。其中hadoop-common包一定要包含。
执行后等待结果正确运行。若出现异常,则根据提示进行解决。提示不明确的几个异常的解决方案如下:
1. 假如classpath或者buildpath中不包含hadoop-common-0.23.9.jar,出现如下错误
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
at org.apache.hive.jdbc.HiveConnection.createBinaryTransport(HiveConnection.java:393)
at org.apache.hive.jdbc.HiveConnection.openTransport(HiveConnection.java:187)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:163)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:105)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at HiveJdbcClient.main(HiveJdbcClient.java:28)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 7 more
2. HIVE JDBC连接服务器卡死:
假如使用hiveserver 版本JDBCdriver 连接hiverserver2,将可能出现此问题,具体在JDBCDriver连接上之后根据协议要求请求hiveserver2返回数据时,hiveserver2不返回任何数据,因此JDBC driver将卡死不返回。
3. TezTask出错,返回错误号1.
Exception in thread "main" java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.tez.TezTask
at org.apache.hive.jdbc.HiveStatement.execute(HiveStatement.java:296)
at org.apache.hive.jdbc.HiveStatement.executeQuery(HiveStatement.java:392)
at HiveJdbcClient.main(HiveJdbcClient.java:40)
错误号1代表用户认证失败,在连接时必须指定用户名密码,有可能通过服务器设置可以不需要用户认证就可以执行,hdp默认安装配置用户名密码是hive,hive
3. TezTask出错,返回错误号2.
TaskAttempt 3 failed, info=[Error: Failure while running task:java.lang.IllegalArgumentException: tez.runtime.io.sort.mb 256 should be larger than 0 and should be less than the available task memory (MB):133
at com.google.common.base.Preconditions.checkArgument(Preconditions.java:88)
at org.apache.tez.runtime.library.common.sort.impl.ExternalSorter.getInitialMemoryRequirement(ExternalSorter.java:291)
at org.apache.tez.runtime.library.output.OrderedPartitionedKVOutput.initialize(OrderedPartitionedKVOutput.java:95)
at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask$InitializeOutputCallable.call(LogicalIOProcessorRuntimeTask.java:430)
at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask$InitializeOutputCallable.call(LogicalIOProcessorRuntimeTask.java:409)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
]], Vertex failed as one or more tasks failed. failedTasks:1, Vertex vertex_1441168955561_1508_2_00 [Map 1] killed/failed due to:null]
Vertex killed, vertexName=Reducer 2, vertexId=vertex_1441168955561_1508_2_01, diagnostics=[Vertex received Kill while in RUNNING state., Vertex killed as other vertex failed. failedTasks:0, Vertex vertex_1441168955561_1508_2_01 [Reducer 2] killed/failed due to:null]
DAG failed due to vertex failure. failedVertices:1 killedVertices:1
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask
code 2,代表错误是参数错误,一般是指对应的值不合适,以上堆栈指示tez.runtime.io.sort.mb参数256比可用内存大,因此修改配置文件或者执行查询之前先设置其大小即可。
通过以上设置以及参数修正之后,应用程序就能正确的使用jdbc连接hive数据库。
另可以用squirrel-sql GUI客户端管理hivedb,驱动设置方式与代码中对应jar包、驱动类、url等使用同样方式设置,测试成功建立好alias就可以开始连接hive,可以比较方便的管理和操作hive数据库。
通过JDBC连接hive的更多相关文章
- Hive(3)-meta store和hdfs详解,以及JDBC连接Hive
一. Meta Store 使用mysql客户端登录hadoop100的mysql,可以看到库中多了一个metastore 现在尤其要关注这三个表 DBS表,存储的是Hive的数据库 TBLS表,存储 ...
- 大数据学习day28-----hive03------1. null值处理,子串,拼接,类型转换 2.行转列,列转行 3. 窗口函数(over,lead,lag等函数) 4.rank(行号函数)5. json解析函数 6.jdbc连接hive,企业级调优
1. null值处理,子串,拼接,类型转换 (1) 空字段赋值(null值处理) 当表中的某个字段为null时,比如奖金,当你要统计一个人的总工资时,字段为null的值就无法处理,这个时候就可以使用N ...
- Kettle jdbc连接hive出现问题
jdbc连接时报如下错误: Error connecting to database [k] : org.pentaho.di.core.exception.KettleDatabaseExcepti ...
- Java使用JDBC连接Hive
最近一段时间,处理过一个问题,那就是hive jdbc的连接问题,其实也不是大问题,就是url写的不对,导致无法连接.问题在于HiveServer2增加了别的安全验证,导致正常的情况下,传递的参数无法 ...
- JDBC连接Hive数据库
一.依赖 pom <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncodi ...
- java使用JDBC连接hive(使用beeline与hiveserver2)
首先虚拟机上已经安装好hive. 下面是连接hive需要的操作. 一.配置. 1.查找虚拟机的ip 输入 ifconfig 2.配置文件 (1)配置hadoop目录下的core-site.xml和hd ...
- Hive记录-Impala jdbc连接hive和kudu参考
1.配置环境Eclipse和JDK 2.加载hive jar包或者impala jar包 备注:从CDH集群里面拷贝出来 下载地址:https://www.cloudera.com/downloads ...
- Zeppelin 用jdbc连接hive报错
日志: Could not establish connection to jdbc:hive2://192.168.0.51:10000: Required field 'serverProtoco ...
- 基于CDH5.x 下面使用eclipse 操作hive 。使用java通过jdbc连接HIVESERVICE 创建表
基于CDH5.x 下面使用eclipse 操作hive .使用java通过jdbc连接HIVESERVICE 创建表 import java.sql.Connection; import java.s ...
随机推荐
- 用RPM包安装MySQL的默认安装路径问题
在安装PHP时候要对一些配置选项进行设置,其中就有:--with-mysql[=DIR]:包含MySQL扩展,[=DIR]指定mysql安装目录,省略[=DIR]则为默认位置/usr--with-my ...
- Heap:左式堆的应用例(任意序列变单调性最小价值)
首先来说一下什么是左式堆: A:左式堆是专门用来解优先队列合并的麻烦(任意二叉堆的合并都必须重新合并,O(N)的时间). 左式堆的性质: 1.定义零路经长:节点从没有两个两个儿子节点的路经长,把NUL ...
- Mysql 5.6.17-win64.zip配置
第一大步:下载. a.俗话说:“巧妇难为无米之炊”嘛!我这里用的是 ZIP Archive 版的,win7 64位的机器支持这个,所以我建议都用这个.因为这个简单嘛,而且还干净. 地址见图 拉倒最下面 ...
- 如何给Eclipse中添加库(jar包)
折腾Eclipse时,经常会遇到这种情况: 缺少某个库,找到之后,需要将该库,jar包,加入到当前项目,使得代码中的import xxx得以正常导入. 举例: [已解决]Eclipse的java代码出 ...
- export 解决环境变量的问题!!!!
export PATH="/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin:/root/bin" 如果/et ...
- linux之间文件传输问题
如果linux服务器使用了秘钥登陆,可以先关闭秘钥登陆 http://blog.chinaunix.net/uid-23634108-id-2393471.html 然后:scp -P 端口号 no ...
- 3.Factory Method 工厂方法模式(创建型模式)
1.定义: 定义一个用于创建对象的接口,让子类决定实例化哪一个类.Factory Method使得一个类的实例化延迟到子类. 2.实现代码如下: /// <summary> /// 工厂方 ...
- java环境变量配置(转)
java环境变量配置 windows xp下配置JDK环境变量: 1.安装JDK,安装过程中可以自定义安装目录等信息,例如我们选择安装目录为D:\java\jdk1.5.0_08: 2.安装完成后,右 ...
- 【HTML5】表单属性
* autocomplete autocomplete 属性规定 form 或 input 域应该拥有自动完成功能. 注释:autocomplete 适用于 <form> 标签,以及以下类 ...
- 输入框提示文字js
<input style="margin-right: 0px; padding-right: 0px;" class="text" required=& ...