【温故而知新-Javascript】使用 Document 对象
Document 对象时通往DOM功能的入口,它向你提供了当前文档的信息,以及一组可供探索、导航、搜索或操作结构与内容的功能。
我们通过全局变量document访问Document对象,它是浏览器为我们创建的关键对象之一。Document对象提供了文档的整体信息,并让你能够访问模型里的各个对象。简单示例如下:
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- </head>
- <body>
- <p id="first">
- 15岁的时候再得到那个5岁的时候热爱的布娃娃,65岁的时候终于有钱买25岁的时候热爱的那条裙子,又有什么意义。
- 什么都可以从头再来,只有青春不能。那么多事情,跟青春绑在一起就是美好,离开青春,就是傻冒。
- </p>
- <p id="second">
- 你的特别不是因为你在创业,不是因为你进了牛企,不是因为你的牛offer,而是因为你就是你,坚信自己的特别,坚信自己的内心,勇敢做自己。
- IT DOESN'T MATTER WHERE YOU ARE, IT MATTERS WHO YOU ARE.
- </p>
- <script>
- document.writeln("<pre>URL: "+document.URL);
- var elems = document.getElementsByTagName("p");
- for(var i=0; i<elems.length; i++){
- document.writeln("Element ID: "+elems[i].id);
- elems[i].style.border = "medium double black";
- elems[i].style.padding = "4px";
- }
- document.write("</pre>");
- </script>
- </body>
- </html>
我们能对Document对象做的最基本操作之一就是获取当前正在处理的HTML文档信息。这就是脚本的第一行所做的:
- document.writeln("<pre>URL: "+document.URL);
此例中,读取了 document.URL 属性的值,它返回的是当前文档的URL。浏览器就是用这个URL载入此脚本所属文档的。
这句语句还调用了writeln方法:
- document.writeln("<pre>URL: "+document.URL);
此方法会将内容附加到HTML文档的末尾。此例中,写入了pre元素的开始标签和URL属性的值。这就是一个非常简单的修改DOM范例,意思是我已经改变了文档的结构。
接下来,从文档中选择了一些元素:
- var elems = document.getElementsByTagName("p");
getElementsByTagName 选择属于某一给定类型的所有元素,此例中是p元素。任何包含在文档里的p元素都会被该方法返回,并被存放在一个elems的变量里。所有元素都是由HTMLElement对象代表的,它提供了基本的功能以代表HTML元素。getElementsByTagName方法返回的结果是HTMLElement对象所组成的一个集合。
有了可以处理的HTMLElement对象集合之后,使用了一个for循环来列举集合里的内容,处理浏览器从HTML文档里找出的各个p元素:
- for(var i=0; i<elems.length; i++){
- document.writeln("Element ID: "+elems[i].id);
- elems[i].style.border = "medium double black";
- elems[i].style.padding = "4px";
- }
对集合里的每个HTMLElement,会读取它的id属性来获取id 值,然使用 document.writeln 方法吧结果附加到之前生成的pre元素的内容上:
- for(var i=0; i<elems.length; i++){
- document.writeln("Element ID: "+elems[i].id);
- elems[i].style.border = "medium double black";
- elems[i].style.padding = "4px";
- }
id属性是HTMLElement定义的众多属性之一。你可以使用这些属性来获取某个元素的信息,也可以对其进行修改(改动会同时应用到它所代表的HTML元素上)。此例中,使用了style属性来改变CSS border和padding 属性的值:
- for(var i=0; i<elems.length; i++){
- document.writeln("Element ID: "+elems[i].id);
- elems[i].style.border = "medium double black";
- elems[i].style.padding = "4px";
- }
这些改动为每个圆度都创建了一个内嵌样式,这些元素都是之前用getElementsByTagName 方法找到的。当修改某个对象时,浏览器会立即把改动应用到对应的元素上,此例中是给这些p元素添加内边距和边框。
脚本的最后一行写入了pre元素的结束标签,就是在脚本开头初始化的那个元素。这里用的是write方法,但不会给添加到文档里的字符串附上行结束字符。这两种方法区别不大,除非编写的内容是预格式化的,或者使用非标准的空白处理方式。
使用pre元素就意思味着writeln方法所添加的行结束符字符会被用来构建内容。从下面的显示效果图可以看到文档排列的效果:

1. 使用 Document 元数据
下表介绍了可以用来获取文档元数据的属性。

1.1 获取文档信息
可以使用元数据属性来获取一些有用的文档信息。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- </head>
- <body>
- <script>
- document.writeln("<pre>");
- document.writeln("document.title);
- document.write("</pre>");
- </script>
- </body>
- </html>

理解怪异模式
compatMode 属性告诉你浏览器是如何处理文档内容的。现如今存在着大量的非标准HTML,浏览器则试图显示出这类网页,哪怕它们并不遵循HTML规范。一些这样的内容依赖于浏览器的独特功能,而这些功能来源于浏览器依靠自身特点(而非遵循标准)进行竞争的年代。compatMode属性会返回两个值中的一个,如下表所示:

1.2 使用Location 对象
document.location 属性返回一个Location 对象,这个对象提供了细粒度的文档地址信息,也允许导航到其他文档上。下表介绍了Location对象里的函数和属性:

document.location 属性最简单的用途就是获取当前文档的地址信息。
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>使用Location 对象</title>
- </head>
- <body>
- <script>
- document.writeln("<pre>")
- document.writeln("protocol: "+ document.location.protocol);
- document.writeln("host: "+ document.location.host);
- document.writeln("href: "+ document.location.href);
- document.writeln("hostname: "+ document.location.hostname);
- document.writeln("port: "+ document.location.port);
- document.writeln("pathname: "+ document.location.pathname);
- document.writeln("search: "+ document.location.search);
- document.writeln("hash: "+ document.location.hash);
- document.write("</pre>");
- </script>
- </body>
- </html>
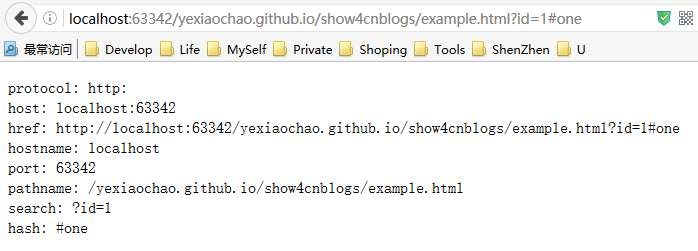
PS:当端口号为HTTP默认的80时,属性不会返回值
使用Location对象导航到其他地方
还可以使用Location对象(通过document.location属性)来导航到其他地方。具体的显示方式有好几种。首先,可以为之前示例用到的某个属性指派新值。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- </head>
- <body>
- <p id="first">
- 15岁的时候再得到那个5岁的时候热爱的布娃娃,65岁的时候终于有钱买25岁的时候热爱的那条裙子,又有什么意义。
- 什么都可以从头再来,只有青春不能。那么多事情,跟青春绑在一起就是美好,离开青春,就是傻冒。
- </p>
- <button id="pressme">Press Me</button>
- <p id="second">
- 你的特别不是因为你在创业,不是因为你进了牛企,不是因为你的牛offer,而是因为你就是你,坚信自己的特别,坚信自己的内心,勇敢做自己。
- IT DOESN'T MATTER WHERE YOU ARE, IT MATTERS WHO YOU ARE.
- </p>
- <img id="banana" src="imgs/banana-small.png" alt="small banna" />
- <script>
- document.getElementById("pressme").onclick = function(){
- document.location.hash = "banana";
- }
- </script>
- </body>
- </html>
此例中包含一个button元素,当它被点击时会给document.location.hash 属性指派一个新值。通过一个事件把按钮和点击时只需的JavaScript函数关联起来。这就是onclick属性的作用。
这一改动会让浏览器导航到某一id属性值匹配hash值的元素上,这这个案例里是img元素。从下面的效果图可以看到导航的效果:

虽然只是导航到了相同文档的不同位置,但也可以用Location对象的属性来导航到其他文档。不过,这种做法通常是用href属性实现的,因为可以设置完整的URL。也可以使用Location对象定义的一些方法。
assign和replace方法的区别在于,replace会把当前文档从浏览器历史中移除,这就意味着如果用户点击了后退按钮,浏览器就会跳过当前文档,就像它从未访问过该文档一样。下面的例子展示了如何使用assign方法。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- </head>
- <body>
- <button id="pressme">Press Me</button>
- <script>
- document.getElementById("pressme").onclick = function(){
- document.location.assign("http://yexiaochao.github.io")
- }
- </script>
- </body>
- </html>
当用户点击button元素时,浏览器会导航到指定的URL上,在这个示例中是 http://yexiaochao.github.io 。
1.3 读取和写入cookie
cookie 属性让你可以读取、添加和更新文档所关联的 cookie。下面例子对此进行了演示:
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- </head>
- <body>
- <p id="cookiedata"></p>
- <button id="write">Add Coojie</button>
- <button id="update">Update Cookie</button>
- <script>
- var cookieCount = 0;
- document.getElementById("write").onclick = createCookie;
- document.getElementById("update").onclick = updateCookie;
- function readCookies(){
- document.getElementById("cookiedata").innerHTML = document.cookie;
- }
- function createCookie(){
- cookieCount++;
- document.cookie =cookieCount;
- readCookies();
- }
- function updateCookie(){
- document.cookie = "Cookie_"+cookieCount+"=Update_"+cookieCount;
- readCookies();
- }
- </script>
- </body>
- </html>
cookie 属性的工作方式稍微有点古怪。当读取该属性的值时,会得到与文档相关联的所有cookie。cookie是形式为name=value的名称/值对。如果存在多个cookie,那么cookie属性会把它们作为结果返回,之间以分号相隔,如 name1=value1;name2=value2。
与之相对,当想要创建新的cookie时,要指派新的cookie时,要指派一个新的名称/值对作为cookie属性的值,它将会添加到文档的cookie集合。一次只能设置一个cookie。如果设置的值和现有的某个cookie具备相同的名称部分,那么就会用值部分更新那个cookie。
为了演示这一点,代码中包含了一段脚本来读取、创新和更新cookie。 readCookies 函数读取document.cookie 属性的值,并将结果设置为某个段落(p)元素的内容。
这个文档里有两个button元素。当Add Cookie按钮被点击时,createCookie函数会给cookie属性指派一个新值,这个值会被添加到cookie集合中。Update Cookie按钮会调用updateCookie函数。这个函数给某个现有的cookie提供一个新值。从下图可以看到这段脚本的效果:

从效果图中可以看到,添加了三个cookie,其中一个已经被更新为某个新值。虽然添加cookie的默认形式是name=value,但可以额外应用一些数据来改变cookie的处理方式。下表介绍了这些额外数据:

这些额外的项目可以被附加到名称/值对的后面,以分号分隔,就像这样:
- document.cookie = "MyCookie=MyValue;max-age=10";
1.4 理解就绪状态
document.readyState 属性提供了加载和解析HTML文档过程中当前处于哪个阶段的信息。请记住,在默认情况下浏览器会在遇到文档里的script元素时立即执行脚本,但可以使用defer属性推迟脚本的执行。正如我们在一些例子所见到的,可以使用Javascript的事件系统来独立执行各个函数,作为对文档变化或用户操作的反馈。
在所有这些情况下,了解浏览器加载和处理HTML到了哪个阶段可能会很有用。readyState属性会返回三个不同的值。

随着浏览器逐步加载和处理文档,readyState属性的值从loading转为 interactive,再转为complete。这个属性和readystatechange事件结合使用时用处最大,该事件会在每次readyState属性的值发生变化时触发。
下面代码展示了如何同时使用这两个事件和属性来完成一项常见任务。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- <script>
- document.onreadystatechange = function(){
- if (document.readyState == "interactive"){
- document.getElementById("pressme").onclick = function(){
- document.getElementById("results").innerHTML = "Button Pressed";
- }
- }
- }
- </script>
- </head>
- <body>
- <button id="pressme">Press Me</button>
- <pre id="results"></pre>
- </body>
- </html>
这段脚本使用文档就绪状态来推迟一个函数的执行,直到文档进入interactive 阶段。脚本代码要求能够找到在脚本执行时尚未被浏览器载入的文档元素。通过推迟脚本执行直至文档加载完成,就能确认这些元素是可以找到的。这种方式可以作为把script元素放到文档末尾的替代。
1.5 获取DOM的实现情况
document.implementation 属性提供了浏览器对DOM功能的实现信息。这个属性返回一个DOMImplementation 对象,它包含一个 hasFeature 方法,可以使用这个方法来判断哪些DOM功能已实现。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- </head>
- <body>
- <script>
- var features = ["Core","HTML","CSS","Selectors-API"];
- var levels = ["1.0","2.0","3.0"];
- document.writeln("<pre>")
- for(var i = 0; i < features.length; i++){
- document.writeln("Checking for features: "+features[i]);
- for (var j=0; j<levels.length; j++){
- document.write(features[i]+" Level "+levels[j]+": ");
- document.writeln(document.implementation.hasFeature(features[i],levels[j]))
- }
- }
- document.write("</pre>");
- </script>
- </body>
- </html>
这段脚本检测了若干不同的DOM功能,以及所定义的功能等级。它并不像看上去那么有用。首先,浏览器并不总是能正确报告它们实现的功能。某些功能实现并不会通过hasFeature方法进行报告,而另一些报告了却根本没有实现。其次,浏览器报告了某项功能并不意味着它的实现方式是有用的。虽然这个问题不如以前严重,但DOM的实现是存在一些差别的,
如果你打算编写能在所有主流浏览器上工作的代码(你也应该这样想),那么hasFeature方法的用处不大。你应该选择在测试阶段全面检查代码,在需要的时候测试支持情况和备用措施,同时也可以考虑使用某个JavaScript库(例如jQuery),它可以消除不同DOM实现之间的差别。
2. 获取 HTML 元素文档
Document 对象的一大关键功能是作为一个入口,能访问代表文档里各个元素的对象。可以用几种不同的方法来执行这个任务。有些属性会返回代表特定文档元素类型的对象,有些方法能很方便地运用条件搜索来找到匹配的元素,还可以将DOM视为一棵树并沿着它的结构进行导航。
2.1 使用属性获取元素对象
Document对象提供了一组属性,它们会返回代表文档中特定元素或元素类型的对象。

上表里描述的大多数都返回一个HTMLCollection 对象。DOM就是用这种方式来表示一组代表元素的对象集合。下面代码演示了访问集合内对象的两种方法。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- <style>
- pre { border: medium double black;}
- </style>
- </head>
- <body>
- <pre id="results"></pre>
- <img id="lemon" src="imgs/lemon.png" alt="Lemon" />
- <img src="imgs/apple.png" id="apple" alt="apple" />
- <img src="imgs/banana-small.png" alt="small banana" id="banana">
- <script>
- var resultsElement = document.getElementById("results");
- var elems = document.images;
- for(var i=0;i<elems.length;i++){
- resultsElement.innerHTML += "Imgage Element: "+elems[i].id +"\n";
- }
- var srcValue = elems.namedItem("apple").src;
- resultsElement.innerHTML += "Src for apple element is: "+ srcValue + "\n";
- </script>
- </body>
- </html>
第一种使用HTMLCollection 对象的方法是将它视为一个数组。它的length 属性会返回集合里的项目数量,它还支持使用标准的 JavaScript 数组索引标记(element[i]这种表示方法)来直接访问集合里的各个对象。此例中用 document.images 属性获得了一个 HTMLCollection, 它包含了所有代表文档里 img 元素的对象。
第二种方法是使用 namedItem 方法,它会返回集合里带有指定id或name属性值的项目。此例中使用了namedItem方法来获取代表某个特定img元素的对象,该元素的id属性值为apple。
此例效果图如下:

2.2 搜索元素
Document 对象定义了许多方法,可以用它们搜索文档里的元素。

这些方法中的一些方法会返回多个元素。在表里它们展现为返回一个HTMLElement对象数组,但严格来说并非如此。事实上,这些方法返回一个NodeList,它是底层DOM规范的一部分,处理的是通用结构文档格式,而不仅仅是HTML。但是,对这些用途而言,可以将它们视为数组,把注意力集中在HTML5上。
这些搜索方法可以被分成两类。下面代码演示了其中一类,即名称 getElement开头的那些方法。
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Example</title>
- <style>
- pre { border: medium double black;}
- </style>
- </head>
- <body>
- <pre id="results"></pre>
- <img id="lemon" class="fruits" name="apple" src="imgs/lemon.png" alt="Lemon" />
- <p>
- There are lots of different kinds of fruits - there are over 500 varieties of bananas alone.
- By the time we add the countless types of apples, oranges, and other well-known fruit,
- we are faced with thousands of choices.
- </p>
- <img id="apple" class="fruits" name="apple" src="imgs/apple.png" alt="apple" />
- <p>
- One of the most interesting aspects of fruit is the variety available in each country.
- I live near London, in an area which is know for its apples.
- </p>
- <img id="banana" src="imgs/banana-small.png" alt="small banana">
- <script>
- var resultElement = document.getElementById("results");
- var pElems = document.getElementsByTagName("p");
- resultElement.innerHTML += "There are " + pElems.length + " p elements\n";
- var fruitsElems = document.getElementsByClassName("fruits");
- resultElement.innerHTML += "There are "+ fruitsElems.length + " elements in the fruits class\n";
- var nameElems = document.getElementsByName("apple");
- resultElement.innerHTML += "There are " + nameElems.length + " elements with the name 'apple'";
- </script>
- </body>
- </html>
在使用 getElementById方法时,如果找不到带有指定id值的元素,浏览器就会返回null。与之相对,其他的方法总是会返回一个HTMLElement对象数组,但如果找不到匹配,length属性就会返回0。
用CSS选择器进行搜索
使用CSS选择器是一种有用的替代性搜索方式。选择器可以在文档里找到范围更广的元素。
修改前面示例的JavaScript代码如下:
- <script>
- var resultsElement = document.getElementById("results");
- var elems = document.querySelectorAll("p,img#apple");
- resultsElement.innerHTML += "The selector matched "+ elems.length + " elements\n"
- </script>
此例中使用了一个选择器,它会匹配所有的p元素和id值为apple的img元素。用其他document方法很难达到同样的效果。
2.4 合并进行链式搜索
DOM的一个实用功能是几乎所有Document对象实现的搜索方法同时也能被HTMLElement对象实现(一个例外),这使得可以合并进行链式搜索。唯一的例外是getElementById方法,只有Document对象才能使用它。下面代码展示了链式搜索:
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>合并进行链式搜索</title>
- <style>
- pre { border: medium double green;}
- </style>
- </head>
- <body>
- <pre id="results"></pre>
- <p id="tblock">
- There are lots of different kinds of fruit - there are over 500 varieties of <span id="banana">banana</span> alone.
- Bt the time we add the countless types of <span id="apple">apples</span>, <span id="orange">oranges</span>,
- and other well-known fruit, we are faced with thousands of choices.
- </p>
- <script>
- var resultsElement = document.getElementById("results");
- var elems = document.getElementById("tblock").getElementsByTagName("span");
- resultsElement.innerHTML += "There are " + elems.length + " span elements\n";
- var elems2 = document.getElementById("tblock").querySelectorAll("span");
- resultsElement.innerHTML += "There are " + elems2.length + " span elements (Mix)\n";
- var selElems = document.querySelectorAll("#tblock > span");
- resultsElement.innerHTML += "There are " + selElems.length + " span elements (CSS)\n";
- </script>
- </body>
- </html>
此例中有两次链式搜索,这两次都从getElementById方法开始(它会返回之后进行处理的单个对象)。第一次链接中,使用getElementsByTagName方法链接了一个搜索;在第一次链接中,则通过querySelectorAll方法使用了一个非常简单的CSS选择器。这些链接都返回了一个span元素的集合,它们都位于id为tblock的p元素之内。
当然,也可以通过单独给Document对象应用CCS选择器方法来实现同样的效果,但是这一功能在某些情况下会很方便,比如处理由脚本中的其他函数(或第三方脚本)所生成的HTMLElement对象。此例显示效果如下:

3. 在DOM树里导航
另一种搜索方法是将DOM视为一棵树,然后在它的层级结构里导航。所有的DOM对象都支持一组属性和方法来做到这点。

下面代码展示了一段脚本,它可以导航到文档各处,并在一个pre元素里显示当前所选元素的信息。
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>在DOM树里导航</title>
- <style>
- pre { border: medium double green;}
- </style>
- </head>
- <body>
- <pre id="results"></pre>
- <p id="tblock">
- There are lots of different kinds of fruit - there are over 500 varieties of <span id="banana">banana</span> alone.
- Bt the time we add the countless types of <span id="apple">apples</span>, <span id="orange">oranges</span>,
- and other well-known fruit, we are faced with thousands of choices.
- </p>
- <img id="apple" class="fruits images" name="apple" src="../imgs/apple.png" alt="apple" />
- <img id="banana" src="../imgs/banana-small.png" alt="small banana" />
- <p>
- One of most interesting aspects of fruit is the variety available in each country.
- I live near London, in an area which is known for its apple.
- </p>
- <p>
- <button id="parent">Parent</button>
- <button id="child">First Child</button>
- <button id="prev">Prev Sibling</button>
- <button id="next">Next Sibling</button>
- </p>
- <script>
- var resultsElem = document.getElementById("results");
- var element = document.getElementById("tblock");
- var buttons = document.getElementsByTagName("button");
- for(var i = 0; i < buttons.length; i++){
- buttons[i].onclick = handleButtonClick;
- }
- processNewElement(element);
- function handleButtonClick(e){
- if(element.style){
- element.style.backgroundColor = "white";
- }
- if(e.target.id == "parent" && element != document.body){
- element = element.parentNode;
- }else if(e.target.id == "child" && element.hasChildNodes()){
- element = element.firstChild;
- }else if(e.target.id == "prev" && element.previousSibling){
- element = element.previousSibling;
- }else if(e.target.id == "next" && element.nextSibling){
- element = element.nextSibling;
- }
- processNewElement(element);
- if(element.style){
- element.style.backgroundColor = "lightgrey";
- }
- }
- function processNewElement(elem){
- resultsElem.innerHTML = "Element type: " + elem + "\n";
- resultsElem.innerHTML += "Element id: " + elem.id + "\n";
- resultsElem.innerHTML += "Has child nodes: " + elem.hasChildNodes() + "\n";
- if(elem.previousSibling){
- resultsElem.innerHTML += ("Prev sibling is: " + elem.previousSibling + "\n");
- }else {
- resultsElem.innerHTML += "No prev sibling\n";
- }
- if (elem.nextSibling){
- resultsElem.innerHTML += "Next sibling is " + elem.nextSibling + "\n";
- }else {
- resultsElem.innerHTML += "No next sibling\n";
- }
- }
- </script>
- </body>
- </html>
这段脚本的重要之处用粗体进行显示,它们是实际进行导航操作的部分。脚本的其余部分则是在做准备工作,处理按钮点击以及显示当前所选元素的信息。

来源:《HTML5权威指南》(《The Definitive Guide to HTML5》)
【温故而知新-Javascript】使用 Document 对象的更多相关文章
- 用JAVA编写浏览器内核之实现javascript的document对象与内置方法
原创文章.转载请注明. 阅读本文之前,您须要对浏览器怎样载入javascript有一定了解. 当然,对java与javascript本身也须要了解. 本文首先介绍浏览器载入并执行javascript的 ...
- javascript之document对象
一.修改网页元素 当使用document提供的方法和Element的属性得到网页元素之后,就可以对元素的内容进行修改,如下例所示的“全选/全不选”的实现. 例3-17 <html> < ...
- JavaScript之document对象使用
1.document 对象常用的有三种: A.document.getElementById:通过html元素的Id,来获取html对象.适用于单个的html元素. B.document.getEle ...
- Javascript的document对象
对象属性 document.title //设置文档标题等价于HTML的<title>标签 document.bgColor / ...
- javascript DOM document对象
document对象代表整个html文档 用来访问页面所有元素最复杂的一个dom对象 也是window对象的一个子对象. 对于dom编程中,一个html就会当成一个dom树dom会把所有的html元素 ...
- JavaScript 之 document对象
对象属性document.title //设置文档标题等价于HTML的title标签document.bgColor //设置页面背景色document.fgColor //设置前景色(文本颜色)do ...
- JavaScript 客户端JavaScript之Document对象中的表单和表单元素
Form对象 代表一个HTML表单(document可以有多个表单元素) 表单访问 document.form[document.forms.length-1] 访问表单元素 document.for ...
- JavaScript Window.document对象
一.找到元素: docunment.getElementById("id"):根据id找,最多找一个: var a =docunment.getElementById(&qu ...
- Javascript之document对象用法(很重要)
一.找到元素 document.getElementById("id"):根据id找层,最多找一个 var a=document.getElementById("id&q ...
- javascript中document对象的属性和方法
document.documentElement; document.firstChild;document.childNodes[0];// 取得对<html>的引用document.b ...
随机推荐
- IIS理解
WEB开发基础 1IIS原理 IIS的本质其实就是一个sorket的服务器,浏览器就是一个sorket的客户端,浏览器发送请求信息给IIS,IIS返回信息给浏览器显示,就这么简单. 1http.sys ...
- Java、Hibernate(JPA)注解大全
1.@Entity(name=”EntityName”) 必须,name为可选,对应数据库中一的个表 2.@Table(name=””,catalog=””,schema=””) 可选,通常和@Ent ...
- 使用layout_weight设置控件占屏幕百分比
水平LinearLayout中如果A,B两个控件都是layout_weight="1",那么控件在水平方向占比为A的layout_width+1/2空闲空间,B的layout_wi ...
- 两种设计模式(2)==>>"单例"
所谓“单例”: 单例模式是一种常用的软件设计模式.在它的核心结构中只包含一个被称为单例的特殊类.通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资 ...
- 利用多写Redis实现分布式锁原理与实现分析(转)
利用多写Redis实现分布式锁原理与实现分析 一.关于分布式锁 关于分布式锁,可能绝大部分人都会或多或少涉及到. 我举二个例子:场景一:从前端界面发起一笔支付请求,如果前端没有做防重处理,那么可能 ...
- 【GOF23设计模式】责任链模式
来源:http://www.bjsxt.com/ 一.[GOF23设计模式]_责任链模式.公文审批.供应链系统的采购审批.异常链.过滤器和拦截器调用过程 package com.test.chainO ...
- 安装SQL Server Management Studio Express错误码是29506
解决方法:1:新建一个记事本,输入msiexec /i path\SQLServer2005_SSMSEE.msi 然后另存为.cmd格式.2:右单击刚刚创建的那个.CMD文件,选择“以管理员身份运行 ...
- 破解入门【OllyDebug爆破程序】
逆向破解这块我也是个刚起步的小菜,入门都还算不上吧,看了点基础教程,先动手练习一下增加点兴趣.嘿嘿 工具: peid //查壳工具 OllyDebug //反汇编.动态调试工具 ...
- SharePoint 2013开发环境准备一些小事项
开发慢慢向着SharePoint 2013迁移,环境也开始慢慢准备起来了.由于FAST Search的集成,和缓存服务的加入,SharePoint 2013对开发机器要求的不是一般的高.这里介绍一下如 ...
- MQTT for UWP
老规矩,先简单介绍下MQTT: MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分.该协 ...