Linux下利用CGroup控制CPU、内存以及IO的操作记录
前面详细介绍了mongodb的副本集和分片的原理,这里就不赘述了。下面记录Mongodb副本集+分片集群环境部署过程:
MongoDB Sharding Cluster,需要三种角色:
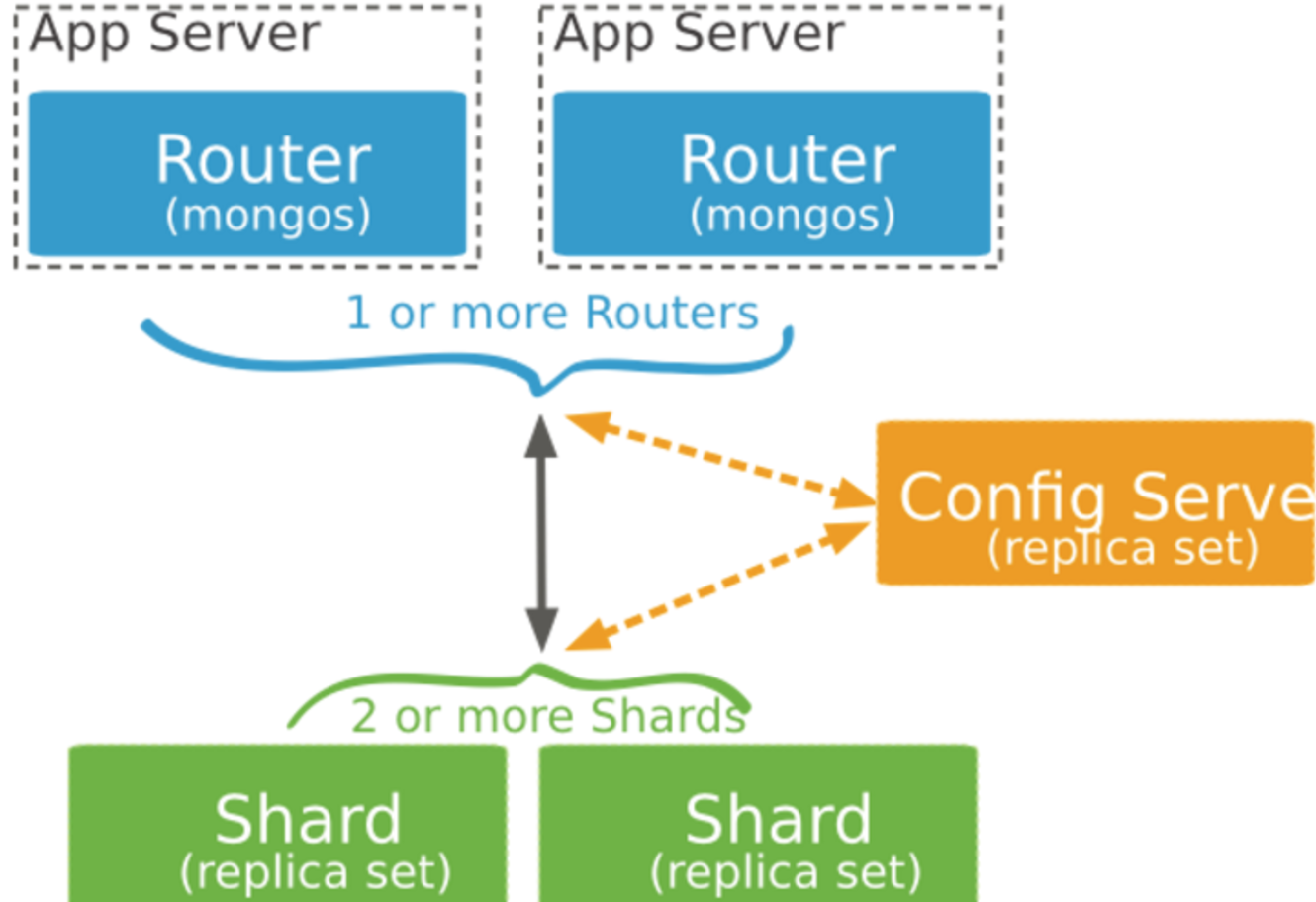
Shard Server: mongod 实例,用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个relica set承担,防止主机单点故障
Config Server: mongod 实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。
Route Server: mongos 实例,前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
机器信息:
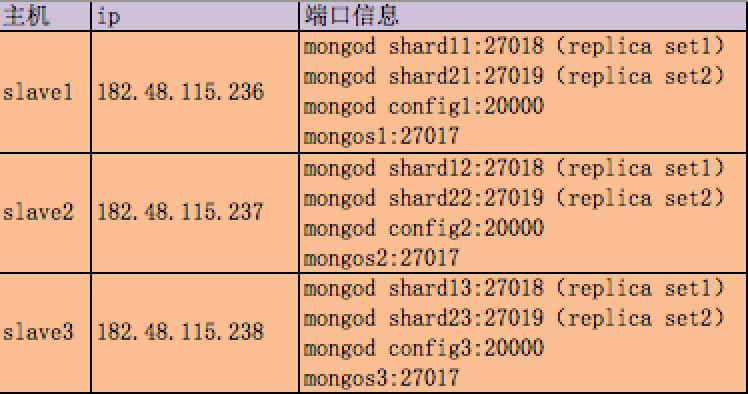
分别在3台机器运行一个mongod实例(称为mongod shard11,mongod shard12,mongod shard13)组织replica set1,作为cluster的shard1
分别在3台机器运行一个mongod实例(称为mongod shard21,mongod shard22,mongod shard23)组织replica set2,作为cluster的shard2
每台机器运行一个mongod实例,作为3个config server
每台机器运行一个mongos进程,用于客户端连接
1)安装mongodb (3台机器都要操作)
下载地址:https://pan.baidu.com/s/1hsoVcpQ 提取密码:6zp4
[root@slave1 src]# cd
[root@slave1 ~]# cd /usr/local/src/
[root@slave1 src]# ll mongodb-linux-x86_64-rhel62-3.0.6.tgz
[root@slave1 src]# tar -zvxf mongodb-linux-x86_64-rhel62-3.0.6.tgz
[root@slave1 src]# mv mongodb-linux-x86_64-rhel62-3.0.6 mongodb 2)创建sharding数据目录
根据本例sharding架构图所示,在各台sever上创建shard数据文件目录
slave1
[root@slave1 src]# mkdir /home/services/
[root@slave1 src]# mv mongodb /home/services/
[root@slave1 src]# cd /home/services/mongodb/
[root@slave1 mongodb]# mkdir -p data/shard11
[root@slave1 mongodb]# mkdir -p data/shard21 slave2
[root@slave2 src]# mkdir /home/services/
[root@slave2 src]# mv mongodb /home/services/
[root@slave2 src]# cd /home/services/mongodb/
[root@slave2 mongodb]# mkdir -p data/shard12
[root@slave2 mongodb]# mkdir -p data/shard22 slave3
[root@slave3 src]# mkdir /home/services/
[root@slave3 src]# mv mongodb /home/services/
[root@slave3 src]# cd /home/services/mongodb/
[root@slave3 mongodb]# mkdir -p data/shard13
[root@slave3 mongodb]# mkdir -p data/shard23 3)配置relica sets
3.1)配置shard1所用到的replica sets 1:
slave1
[root@slave1 ~]# /home/services/mongodb/bin/mongod --shardsvr --replSet shard1 --port 27018 --dbpath /home/services/mongodb/data/shard11 --oplogSize 100 --logpath /home/services/mongodb/data/shard11.log --logappend --fork slave2
[root@slave2 ~]# /home/services/mongodb/bin/mongod --shardsvr --replSet shard1 --port 27018 --dbpath /home/services/mongodb/data/shard12 --oplogSize 100 --logpath /home/services/mongodb/data/shard12.log --logappend --fork slave3
[root@slave3 ~]# /home/services/mongodb/bin/mongod --shardsvr --replSet shard1 --port 27018 --dbpath /home/services/mongodb/data/shard13 --oplogSize 100 --logpath /home/services/mongodb/data/shard13.log --logappend --fork 检车各个机器上的mongod进程是否正常起来了(ps -ef|grep mongod),27018端口是否正常起来了 3.2)初始化replica set 1
从3台机器中任意找一台,连接mongod
[root@slave1 ~]# /home/services/mongodb/bin/mongo --port 27018
......
> config = {"_id" : "shard1","members" : [{"_id" : 0,"host" : "182.48.115.236:27018"},{"_id" : 1,"host" : "182.48.115.237:27018"},{"_id" : 2,"host" : "182.48.115.238:27018"}]}
{
"_id" : "shard1",
"members" : [
{
"_id" : 0,
"host" : "182.48.115.236:27018"
},
{
"_id" : 1,
"host" : "182.48.115.237:27018"
},
{
"_id" : 2,
"host" : "182.48.115.238:27018"
}
]
}
> rs.initiate(config);
{ "ok" : 1 } 3.3)配置shard2所用到的replica sets 2:
slave1
[root@slave1 ~]# /home/services/mongodb//bin/mongod --shardsvr --replSet shard2 --port 27019 --dbpath /home/services/mongodb/data/shard21 --oplogSize 100 --logpath /home/services/mongodb/data/shard21.log --logappend --fork slave2
[root@slave2 ~]# /home/services/mongodb//bin/mongod --shardsvr --replSet shard2 --port 27019 --dbpath /home/services/mongodb/data/shard22 --oplogSize 100 --logpath /home/services/mongodb/data/shard22.log --logappend --fork slave3
[root@slave3 ~]# /home/services/mongodb//bin/mongod --shardsvr --replSet shard2 --port 27019 --dbpath /home/services/mongodb/data/shard23 --oplogSize 100 --logpath /home/services/mongodb/data/shard23.log --logappend --fork 3.4)初始化replica set 2
从3台机器中任意找一台,连接mongod
[root@slave1 ~]# /home/services/mongodb/bin/mongo --port 27019
......
> config = {"_id" : "shard2","members" : [{"_id" : 0,"host" : "182.48.115.236:27019"},{"_id" : 1,"host" : "182.48.115.237:27019"},{"_id" : 2,"host" : "182.48.115.238:27019"}]}
{
"_id" : "shard2",
"members" : [
{
"_id" : 0,
"host" : "182.48.115.236:27019"
},
{
"_id" : 1,
"host" : "182.48.115.237:27019"
},
{
"_id" : 2,
"host" : "182.48.115.238:27019"
}
]
}
> rs.initiate(config);
{ "ok" : 1 } 4)配置三台config server
slave1
[root@slave1 ~]# mkdir -p /home/services/mongodb/data/config
[root@slave1 ~]# /home/services/mongodb//bin/mongod --configsvr --dbpath /home/services/mongodb/data/config --port 20000 --logpath /home/services/mongodb/data/config.log --logappend --fork slave2
[root@slave2 ~]# mkdir -p /home/services/mongodb/data/config
[root@slave2 ~]# /home/services/mongodb//bin/mongod --configsvr --dbpath /home/services/mongodb/data/config --port 20000 --logpath /home/services/mongodb/data/config.log --logappend --fork slave3
[root@slave3 ~]# mkdir -p /home/services/mongodb/data/config
[root@slave3 ~]# /home/services/mongodb//bin/mongod --configsvr --dbpath /home/services/mongodb/data/config --port 20000 --logpath /home/services/mongodb/data/config.log --logappend --fork 5)配置mongs
在三台机器上分别执行:
slave1
[root@slave1 ~]# /home/services/mongodb/bin/mongos --configdb 182.48.115.236:20000,182.48.115.237:20000,182.48.115.238:20000 --port 27017 --chunkSize 5 --logpath /home/services/mongodb/data/mongos.log --logappend --fork slave2
[root@slave2 ~]# /home/services/mongodb/bin/mongos --configdb 182.48.115.236:20000,182.48.115.237:20000,182.48.115.238:20000 --port 27017 --chunkSize 5 --logpath /home/services/mongodb/data/mongos.log --logappend --fork slave3
[root@slave3 ~]# /home/services/mongodb/bin/mongos --configdb 182.48.115.236:20000,182.48.115.237:20000,182.48.115.238:20000 --port 27017 --chunkSize 5 --logpath /home/services/mongodb/data/mongos.log --logappend --fork 注意:新版版的mongodb的mongos命令里就不识别--chunkSize参数了 6)配置分片集群(Configuring the Shard Cluster)
从3台机器中任意找一台,连接mongod,并切换到admin数据库做以下配置 6.1)连接到mongs,并切换到admin
[root@slave1 ~]# /home/services/mongodb/bin/mongo 182.48.115.236:27017/admin
......
mongos> db
admin
mongos> 6.2)加入shards分区
如里shard是单台服务器,用"db.runCommand( { addshard : “[:]” } )"这样的命令加入
如果shard是replica sets,用"replicaSetName/[:port][,serverhostname2[:port],…]"这样的格式表示,例如本例执行:
mongos> db.runCommand( { addshard:"shard1/182.48.115.236:27018,182.48.115.237:27018,182.48.115.238:27018",name:"s1",maxsize:20480});
{ "shardAdded" : "s1", "ok" : 1 }
mongos> db.runCommand( { addshard:"shard2/182.48.115.236:27019,182.48.115.237:27019,182.48.115.238:27019",name:"s2",maxsize:20480});
{ "shardAdded" : "s2", "ok" : 1 } 注意:
可选参数
Name:用于指定每个shard的名字,不指定的话系统将自动分配
maxSize:指定各个shard可使用的最大磁盘空间,单位megabytes 6.3)Listing shards
mongos> db.runCommand( { listshards : 1 } )
{
"shards" : [
{
"_id" : "s1",
"host" : "shard1/182.48.115.236:27018,182.48.115.237:27018,182.48.115.238:27018"
},
{
"_id" : "s2",
"host" : "shard2/182.48.115.236:27019,182.48.115.237:27019,182.48.115.238:27019"
}
],
"ok" : 1
}
mongos> 上面命令列出了以上二个添加的shards,表示shards已经配置成功 6.4)激活数据库分片
命令:
db.runCommand( { enablesharding : “” } );
通过执行以上命令,可以让数据库跨shard,如果不执行这步,数据库只会存放在一个shard,一旦激活数据库分片,数据库中不同的collection将被存放在不同的shard上,
但一个collection仍旧存放在同一个shard上,要使单个collection也分片,还需单独对collection作些操作 Collecton分片
要使单个collection也分片存储,需要给collection指定一个分片key,通过以下命令操作:
db.runCommand( { shardcollection : “”,key : }); 注意:
a)分片的collection系统会自动创建一个索引(也可用户提前创建好)
b)分片的collection只能有一个在分片key上的唯一索引,其它唯一索引不被允许 本案例:
mongos> db.runCommand({enablesharding:"test2"});
{ "ok" : 1 }
mongos> db.runCommand( { shardcollection : "test2.books", key : { id : 1 } } );
{ "collectionsharded" : "test2.books", "ok" : 1 }
mongos> use test2
switched to db test2
mongos> db.stats();
{
"raw" : {
"shard1/182.48.115.236:27018,182.48.115.237:27018,182.48.115.238:27018" : {
"db" : "test2",
"collections" : 3,
"objects" : 6,
"avgObjSize" : 69.33333333333333,
"dataSize" : 416,
"storageSize" : 20480,
"numExtents" : 3,
"indexes" : 2,
"indexSize" : 16352,
"fileSize" : 67108864,
"nsSizeMB" : 16,
"extentFreeList" : {
"num" : 0,
"totalSize" : 0
},
"dataFileVersion" : {
"major" : 4,
"minor" : 22
},
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("586286596422d63aa9f9f000")
}
},
"shard2/182.48.115.236:27019,182.48.115.237:27019,182.48.115.238:27019" : {
"db" : "test2",
"collections" : 0,
"objects" : 0,
"avgObjSize" : 0,
"dataSize" : 0,
"storageSize" : 0,
"numExtents" : 0,
"indexes" : 0,
"indexSize" : 0,
"fileSize" : 0,
"ok" : 1
}
},
"objects" : 6,
"avgObjSize" : 69,
"dataSize" : 416,
"storageSize" : 20480,
"numExtents" : 3,
"indexes" : 2,
"indexSize" : 16352,
"fileSize" : 67108864,
"extentFreeList" : {
"num" : 0,
"totalSize" : 0
},
"ok" : 1
}
mongos> db.books.stats();
{
"sharded" : true,
"paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard coded to 1.0 for c ompatibility only.",
"userFlags" : 1,
"capped" : false,
"ns" : "test2.books",
"count" : 0,
"numExtents" : 1,
"size" : 0,
"storageSize" : 8192,
"totalIndexSize" : 16352,
"indexSizes" : {
"_id_" : 8176,
"id_1" : 8176
},
"avgObjSize" : 0,
"nindexes" : 2,
"nchunks" : 1,
"shards" : {
"s1" : {
"ns" : "test2.books",
"count" : 0,
"size" : 0,
"numExtents" : 1,
"storageSize" : 8192,
"lastExtentSize" : 8192,
"paddingFactor" : 1,
"paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard co ded to 1.0 for compatibility only.",
"userFlags" : 1,
"capped" : false,
"nindexes" : 2,
"totalIndexSize" : 16352,
"indexSizes" : {
"_id_" : 8176,
"id_1" : 8176
},
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("586286596422d63aa9f9f000")
}
}
},
"ok" : 1
} 7)测试
mongos> for (var i = 1; i <= 20000; i++) db.books.save({id:i,name:"12345678",sex:"male",age:27,value:"test"});
WriteResult({ "nInserted" : 1 })
mongos> db.books.stats();
{
"sharded" : true,
"paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard coded to 1.0 for compatibility only.",
"userFlags" : 1,
"capped" : false,
"ns" : "test2.books",
"count" : 20000,
"numExtents" : 10,
"size" : 2240000,
"storageSize" : 5586944,
"totalIndexSize" : 1250928,
"indexSizes" : {
"_id_" : 670432,
"id_1" : 580496
},
"avgObjSize" : 112,
"nindexes" : 2,
"nchunks" : 5,
"shards" : {
"s1" : {
"ns" : "test2.books",
"count" : 12300,
"size" : 1377600,
"avgObjSize" : 112,
"numExtents" : 5,
"storageSize" : 2793472,
"lastExtentSize" : 2097152,
"paddingFactor" : 1,
"paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard coded to 1.0 for compatibility only.",
"userFlags" : 1,
"capped" : false,
"nindexes" : 2,
"totalIndexSize" : 760368,
"indexSizes" : {
"_id_" : 408800,
"id_1" : 351568
},
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("586286596422d63aa9f9f000")
}
},
"s2" : {
"ns" : "test2.books",
"count" : 7700,
"size" : 862400,
"avgObjSize" : 112,
"numExtents" : 5,
"storageSize" : 2793472,
"lastExtentSize" : 2097152,
"paddingFactor" : 1,
"paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard coded to 1.0 for compatibility only.",
"userFlags" : 1,
"capped" : false,
"nindexes" : 2,
"totalIndexSize" : 490560,
"indexSizes" : {
"_id_" : 261632,
"id_1" : 228928
},
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(0, 0),
"electionId" : ObjectId("58628704f916bb05014c5ea7")
}
}
},
"ok" : 1
}
Linux下利用CGroup控制CPU、内存以及IO的操作记录的更多相关文章
- 性能测试分析过程(三)linux下查看最消耗CPU/内存的进程
linux下查看最消耗CPU 内存的进程 1.CPU占用最多的前10个进程: ps auxw|head -1;ps auxw|sort -rn -k3|head -10 2.内存消耗最多的前10 ...
- Linux下利用Valgrind工具进行内存泄露检测和性能分析
from http://www.linuxidc.com/Linux/2012-06/63754.htm Valgrind通常用来成分析程序性能及程序中的内存泄露错误 一 Valgrind工具集简绍 ...
- Linux下查看内核、CPU、内存及各组件版本的命令和方法
Linux下查看内核.CPU.内存及各组件版本的命令和方法 Linux查看内核版本: uname -a more /etc/*release ...
- Linux下php-fpm进程过多导致内存耗尽问题
这篇文章主要介绍了解决Linux下php-fpm进程过多导致内存耗尽问题,需要的朋友可以参考下 最近,发现个人博客的Linux服务器,数据库服务经常挂掉,导致需要重启,才能正常访问,极其恶心,于是 ...
- 【java】 linux下利用nohup后台运行jar文件包程序
Linux 运行jar包命令如下: 方式一: java -jar XXX.jar 特点:当前ssh窗口被锁定,可按CTRL + C打断程序运行,或直接关闭窗口,程序退出 那如何让窗口不锁定? 方式二 ...
- linux下查询进程占用的内存方法总结
linux下查询进程占用的内存方法总结,假设现在有一个「php-cgi」的进程 ,进程id为「25282」.现在想要查询该进程占用的内存大小.linux命令行下有很多的工具进行查看,现总结常见的几种方 ...
- Linux下分析某个进程CPU占用率高的原因
Linux下分析某个进程CPU占用率高的原因 通过top命令找出消耗资源高的线程id,利用strace命令查看该线程所有系统调用 1.top 查到占用cpu高的进程pid 2.查看该pid的线程 ...
- 【ARM-Linux开发】【CUDA开发】【视频开发】关于Linux下利用GPU对视频进行硬件加速转码的方案
最近一直在研究Linux下利用GPU进行硬件加速转码的方案,折腾了很久,至今没有找到比较理想的硬加速转码方案.似乎网上讨论这一方案的文章也特别少,这个过程中也进行了各种尝试,遇到很多具体问题,以下便对 ...
- Linux下用命令查看CPU ID以及厂家等信息
Linux下用命令查看CPU ID // 获得CPU IDdmidecode -t 4 | grep ID |sort -u |awk -F': ' '{print $2}' // 获得磁盘IDfdi ...
随机推荐
- ArcGIS制图之Maplex自动点抽稀
制图工作中,大量密集点显示是最常遇到的问题.其特点是分布可能不均匀.数据点比较密集,容易造成空间上的重叠,影响制图美观.那么,如果美观而详细的显示制图呢? 主要原理 Maplex中对标注有很好的显示控 ...
- 获取经过跳转后的url地址
粗略一算,不写code已经好几个月了. 昨日受兄弟所托,为他写了一个小小的程序. 程序功能: 自动获取跳转后的Url地址 如下图所示: (newUrl.txt为转换后的地址信息...) 实现过程: 每 ...
- 部分博文目录索引(C语言+算法)
今天将本博客的部分文章建立一个索引,方便大家进行阅读,当然每一类别中的文章都会持续的添加和更新(PS:博文主要使用C语言) 博客地址:http://www.cnblogs.com/archimedes ...
- OC--第一个程序
#import <Foundation/Foundation.h> //导入foundation.h文件 // C语言函数声明 void MyFun(BOOL bol); int main ...
- iOS开发之网络编程--XCode7 更新以来需要手动设置的内容
XCode7 更新以来,默认是不允许加载一些http网络请求,是因为现在网络大部分使用更安全的https协议头. 所以,iOS网络编程如果出现请求无效,事先考虑是否设置一下了以下操作:
- C++语言出现的bug
输出语句不管是C语言的printf();还是cout << "" << endl; 在循环语句中会出现一个bug: 下面是不正常的两种情况: 下面是正常的: ...
- Windows Server 2008 R2怎样设置自动登陆
Windows Server 2008 R2是一款服务器操作系统,提升了虚拟化.系统管理弹性.网络存取方式,以及信息安全等领域的应用,Windows Server 2008 R2也是第一个只提供64位 ...
- 日常工作生活中的做人做事道理[持续更新ing]
1.凡是预则立,不预则废 2.不能用特殊案例说明事情本身的发展规律 3.任务不能拖,需主动出击,想方设法完成 4.工作要有细致化的沟通和安排 5.解决问题和安排任务可以逆向思维的去想 6.问题要举一反 ...
- Requirejs2.0笔记
API http://requirejs.org/ RequireJS 插件 http://requirejs.org/docs/api.html#plugins ①require.js脚本的异步加载 ...
- Support for AMD usage of jwplayer (require js)
使用require js 模块化代码时,其中播放器用的是jwplayer7.x 然后载入jwplayer.js后总是报license无效(license已经加入),最后在jwplayer官网论坛里找到 ...