数据结构Java实现03----单向链表的插入和删除
文本主要内容:
- 链表结构
- 单链表代码实现
- 单链表的效率分析
一、链表结构: (物理存储结构上不连续,逻辑上连续;大小不固定)
概念:
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
数据域:存数数据元素信息的域。
指针域:存储直接后继位置的域。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型:
根据链表的构造方式的不同可以分为:
- 单向链表
- 单向循环链表
- 双向循环链表
二、单链表:
概念:
链表的每个结点中只包含一个指针域,叫做单链表(即构成链表的每个结点只有一个指向直接后继结点的指针)
单链表中每个结点的结构:

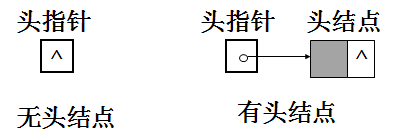
1、头指针和头结点:
单链表有带头结点结构和不带头结点结构两种。
“链表中第一个结点的存储位置叫做头指针”,如果链表有头结点,那么头指针就是指向头结点的指针。
头指针所指的不存放数据元素的第一个结点称作头结点(头结点指向首元结点)。头结点的数据域一般不放数据(当然有些情况下也可存放链表的长度、用做监视哨等)
存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。
如下图所示:
不带头结点的单链表如下:
带头结点的单链表如下图:
关于头指针和头结点的概念区分,可以参考如下博客:
http://blog.csdn.net/hitwhylz/article/details/12305021
2、不带头结点的单链表的插入操作:
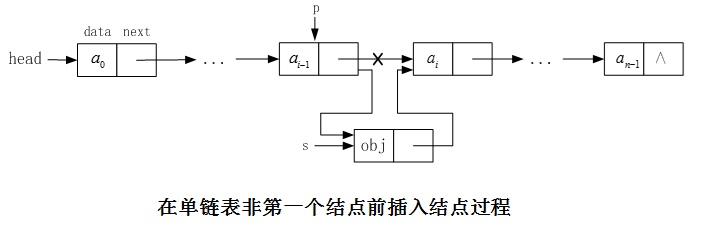
上图中,是不带头结点的单链表的插入操作。如果我们在非第一个结点前进行插入操作,只需要a(i-1)的指针域指向s,然后将s的指针域指向a(i)就行了;如果我们在第一个结点前进行插入操作,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。
因此,算法对这两种情况就要分别设计实现方法。
3、带头结点的单链表的插入操作:(操作统一,推荐)
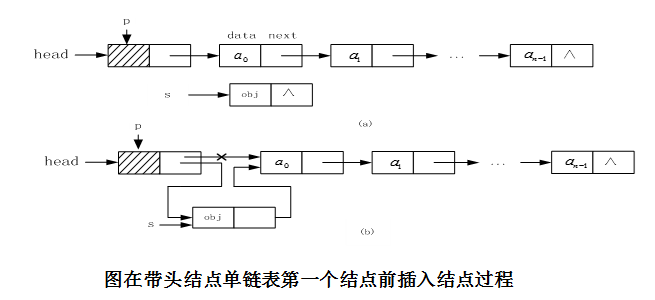
上图中,如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值(改变头结点的指针域),而头指针head的值不变。
因此,算法实现方法比较简单,其操作与对其它结点的操作统一。
问题1:头结点的好处:
头结点即在链表的首元结点之前附设的一个结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理,编程更方便。
问题2:如何表示空表:
无头结点时,当头指针的值为空时表示空表;
有头结点时,当头结点的指针域为空时表示空表。
如下图所示:
问题3:头结点的数据域内装的是什么?
头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值。
三、单项链表的代码实现:
1、结点类:
单链表是由一个一个结点组成的,因此,要设计单链表类,必须先设计结点类。结点类的成员变量有两个:一个是数据元素,另一个是表示下一个结点的对象引用(即指针)。
步骤如下:
(1)头结点的构造(设置指针域即可)
(2)非头结点的构造
(3)获得当前结点的指针域
(4)获得当前结点数据域的值
(5)设置当前结点的指针域
(6)设置当前结点数据域的值
注:类似于get和set方法,成员变量是数据域和指针域。
代码实现:
(1)List.java:(链表本身也是线性表,只不过物理存储上不连续)
//线性表接口
public interface List {
//获得线性表长度
public int size(); //判断线性表是否为空
public boolean isEmpty(); //插入元素
public void insert(int index, Object obj) throws Exception; //删除元素
public void delete(int index) throws Exception; //获取指定位置的元素
public Object get(int index) throws Exception;
}
(2)Node.java:结点类
//结点类
public class Node { Object element; //数据域
Node next; //指针域 //头结点的构造方法
public Node(Node nextval) {
this.next = nextval;
} //非头结点的构造方法
public Node(Object obj, Node nextval) {
this.element = obj;
this.next = nextval;
} //获得当前结点的指针域
public Node getNext() {
return this.next;
} //获得当前结点数据域的值
public Object getElement() {
return this.element;
}
//设置当前结点的指针域
public void setNext(Node nextval) {
this.next = nextval;
} //设置当前结点数据域的值
public void setElement(Object obj) {
this.element = obj;
} public String toString() {
return this.element.toString();
}
}
2、单链表类:
单链表类的成员变量至少要有两个:一个是头指针,另一个是单链表中的数据元素个数。但是,如果再增加一个表示单链表当前结点位置的成员变量,则有些成员函数的设计将更加方便。
代码实现:
(3)LinkList.java:单向链表类(核心代码)
//单向链表类
public class LinkList implements List { Node head; //头指针
Node current;//当前结点对象
int size;//结点个数 //初始化一个空链表
public LinkList()
{
//初始化头结点,让头指针指向头结点。并且让当前结点对象等于头结点。
this.head = current = new Node(null);
this.size =0;//单向链表,初始长度为零。
} //定位函数,实现当前操作对象的前一个结点,也就是让当前结点对象定位到要操作结点的前一个结点。
//比如我们要在a2这个节点之前进行插入操作,那就先要把当前节点对象定位到a1这个节点,然后修改a1节点的指针域
public void index(int index) throws Exception
{
if(index <-1 || index > size -1)
{
throw new Exception("参数错误!");
}
//说明在头结点之后操作。
if(index==-1) //因为第一个数据元素结点的下标是0,那么头结点的下标自然就是-1了。
return;
current = head.next;
int j=0;//循环变量
while(current != null&&j<index)
{
current = current.next;
j++;
} } @Override
public void delete(int index) throws Exception {
// TODO Auto-generated method stub
//判断链表是否为空
if(isEmpty())
{
throw new Exception("链表为空,无法删除!");
}
if(index <0 ||index >size)
{
throw new Exception("参数错误!");
}
index(index-1);//定位到要操作结点的前一个结点对象。
current.setNext(current.next.next);
size--;
} @Override
public Object get(int index) throws Exception {
// TODO Auto-generated method stub
if(index <-1 || index >size-1)
{
throw new Exception("参数非法!");
}
index(index); return current.getElement();
} @Override
public void insert(int index, Object obj) throws Exception {
// TODO Auto-generated method stub
if(index <0 ||index >size)
{
throw new Exception("参数错误!");
}
index(index-1);//定位到要操作结点的前一个结点对象。
current.setNext(new Node(obj,current.next));
size++;
} @Override
public boolean isEmpty() {
// TODO Auto-generated method stub
return size==0;
} @Override
public int size() {
// TODO Auto-generated method stub
return this.size;
} }
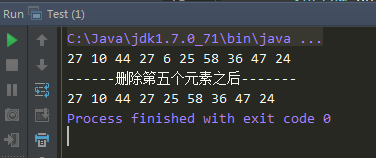
3、测试类:(单链表的应用)
使用单链表建立一个线性表,依次输入十个0-99之间的随机数,删除第5个元素,打印输出该线性表。
(4)Test.java:
public class Test {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
LinkList list = new LinkList();
for (int i = 0; i < 10; i++) {
int temp = ((int) (Math.random() * 100)) % 100;
list.insert(i, temp);
System.out.print(temp + " ");
}
list.delete(4);
System.out.println("\n------删除第五个元素之后-------");
for (int i = 0; i < list.size; i++) {
System.out.print(list.get(i) + " ");
}
}
}
运行效果:
四、开发可用的链表:
对于链表实现,Node类是整个操作的关键,但是首先来研究一下之前程序的问题:Node是一个单独的类,那么这样的类是可以被用户直接使用的,但是这个类由用户直接去使用,没有任何的意义,即:Node这个类有用,但是不能让用户去用,只能让LinkList类去调用,内部类Node中完成。
于是,我们需要把Node类定义为内部类,并且在Node类中去完成addNode和delNote等操作。使用内部类的最大好处是可以和外部类进行私有操作的互相访问。
注:内部类访问的特点是:内部类可以直接访问外部类的成员,包括私有;外部类要访问内部类的成员,必须先创建对象。
1、增加数据:
- public Boolean add(数据 对象)
代码实现:
(1)LinkList.java:(核心代码)
public class LinkList {
private Node root; //定义一个根节点
//方法:增加节点
public boolean add(String data) {
if (data == null) { // 如果添加的是一个空数据,那增加失败
return false;
}
// 将数据封装为节点,目的:节点有next可以处理关系
Node newNode = new Node(data);
// 链表的关键就在于根节点
if (root == null) { //如果根节点是空的,那么新添加的节点就是根节点。(第一次调用add方法时,根节点当然是空的了)
root = newNode;
} else {
root.addNode(newNode);
}
return true;
}
//定义一个节点内部类(假设要保存的数据类型是字符串)
//比较好的做法是,将Node定义为内部类,在这里面去完成增删、等功能,然后由LinkList去调用增、删的功能
class Node {
private String data;
private Node next; //next表示:下一个节点对象(单链表中)
public Node(String data) {
this.data = data;
}
public void addNode(Node newNode) {
//下面这段用到了递归,需要反复理解
if (this.next == null) { // 递归的出口:如果当前节点之后没有节点,说明我可以在这个节点后面添加新节点
this.next = newNode; //添加新节点
} else {
this.next.addNode(newNode); //向下继续判断,直到当前节点之后没有节点为止
}
}
}
}
代码解释:
14行:如果我们第一次调用add方法,那根结点肯定是空的,此时add的是根节点。
当继续调用add方法时,此时是往根节点后面添加数据,需要用到递归(42行),这个递归需要在内部类中去完成。递归这段代码需要去反复理解。
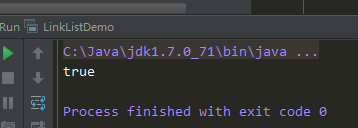
(2)LinkListDemo.java:
public class LinkListDemo {
public static void main(String[] args) {
LinkList list = new LinkList();
boolean flag = list.add("haha");
System.out.println(flag);
}
}
运行效果:
2、增加多个数据:
- public boolean addAll(数据 对象 [] )
上面的操作是每次增加了一个对象,那么如果现在要求增加多个对象呢,例如:增加对象数组。可以采用循环数组的方式,每次都调用add()方法。
在上面的(1)LinkList.java中加入如下代码:
//方法:增加一组数据
public boolean addAll(String data[]) { // 一组数据
for (int x = 0 ; x < data.length ; x ++) {
if (!this.add(data[x])) { // 只要有一次添加不成功,那就是添加失败
return false ;
}
}
return true ;
}
3、统计数据个数:
- public int size()
在一个链表之中,会保存多个数据(每一个数据都被封装为Node类对象),那么要想取得这些保存元素的个数,可以增加一个size()方法完成。
具体做法如下:
在上面的(1)LinkList.java中增加一个统计的属性count:
private int size ; // 统计个数
当用户每一次调用add()方法增加新数据的时候应该做出统计:(下方第18行代码)
//添加节点
public boolean add(String data) { if (data == null) { // 如果添加的是一个空数据,那增加失败
return false;
} // 将数据封装为节点,目的:节点有next可以处理关系
Node newNode = new Node(data);
// 链表的关键就在于根节点
if (root == null) { //如果根节点是空的,那么新添加的节点就是根节点。(第一次调用add方法时,根节点当然是空的了)
root = newNode;
} else {
root.addNode(newNode); } this.size++;
return true; }
而size()方法就是简单的将count这个变量的内容返回:
//获取数据的长度
public int size() {
return this.size;
}
4、判断是否是空链表:
- public boolean isEmpty()
所谓的空链表指的是链表之中不保存任何的数据,实际上这个null可以通过两种方式判断:一种判断链表的根节点是否为null,另外一个是判断保存元素的个数是否为0。
在LinkList.java中添加如下代码:
//判断是否为空链表
public boolean isEmpty() {
return this.size == 0;
}
5、查找数据是否存在:
- public boolean contains(数据 对象)
现在如果要想查询某个数据是否存在,那么基本的操作原理:逐个盘查,盘查的具体实现还是应该交给Node类去处理,但是在盘查之前必须有一个前提:有数据存在。
在LinkList.java中添加查询的操作:
//查询数据是否存在
public boolean contains(String data) { // 查找数据
// 根节点没有数据,查找的也没有数据
if (this.root == null || data == null) {
return false; // 不需要进行查找了
}
return this.root.containsNode(data); // 交给Node类处理
}
紧接着,在Node类之中,完成具体的查询,查询的流程:
判断当前节点的内容是否满足于查询内容,如果满足返回true;
如果当前节点的内容不满足,则向后继续查,如果已经没有后续节点了,则返回false。
代码实现:
//判断节点是否存在
public boolean containsNode(String data) { // 查找数据
if (data.equals(this.data)) { // 与当前节点数据吻合
return true;
} else { // 与当前节点数据不吻合
if (this.next != null) { // 还有下一个节点
return this.next.containsNode(data);
} else { // 没有后续节点
return false; // 查找不到
}
}
}
6、删除数据:
- public boolean remove(数据 对象)
在LinkList.java中加入如下代码:
//方法:删除数据
public boolean remove(String data) { //要删除的节点,假设每个节点的data都不一样 if (!this.contains(data)) { //要删除的数据不存在
return false;
} if (root != null) {
if (root.data.equals(data)) { //说明根节点就是需要删除的节点
root = root.next; //让根节点的下一个节点成为根节点,自然就把根节点顶掉了嘛(不像数组那样,要将后面的数据在内存中整体挪一位)
} else { //否则
root.removeNode(data);
}
}
size--;
return true; }
注意第2代码中,我们是假设删除的这个String字符串是唯一的,不然就没法删除了。
删除时,我们需要从根节点开始判断,如果根节点是需要删除的节点,那就直接删除,此时下一个节点变成了根节点。
然后,在Node类中做节点的删除:
//删除节点
public void removeNode(String data) {
if (this.next != null) {
if (this.next.data.equals(data)) {
this.next = this.next.next;
} else {
this.next.removeNode(data);
}
} }
7、输出所有节点:
在LinkList.java中加入如下代码:
//输出所有节点
public void print() {
if (root != null) {
System.out.print(root.data);
root.printNode();
System.out.println();
}
}
然后,在Node类中做节点的输出:
//输出所有节点
public void printNode() {
if (this.next != null) {
System.out.print("-->" + this.next.data);
this.next.printNode();
}
}
8、取出全部数据:
- public 数据 [] toArray()
对于链表的这种数据结构,最为关键的是两个操作:删除、取得全部数据。
在LinkList类之中需要定义一个操作数组的脚标:
private int foot = 0; // 操作返回数组的脚标
在LinkList类中定义返回数组,必须以属性的形式出现,只有这样,Node类才可以访问这个数组并进行操作:
private String [] retData ; // 返回数组
在LinkList类之中增加toArray()的方法:
//方法:获取全部数据
public String[] toArray() {
if (this.size == 0) {
return null; // 没有数据
}
this.foot = 0; // 清零
this.retData = new String[this.size]; // 开辟数组大小
this.root.toArrayNode();
return this.retData;
}
修改Node类的操作,增加toArrayNode()方法:
//获取全部数据
public void toArrayNode() {
LinkList.this.retData[LinkList.this.foot++] = this.data;
if (this.next != null) {
this.next.toArrayNode();
}
}
不过,按照以上的方式进行开发,每一次调用toArray()方法,都要重复的进行数据的遍历,如果在数据没有修改的情况下,这种做法是一种非常差的做法,最好的做法是增加一个修改标记,如果发现数据增加了或删除的话,表示要重新遍历数据。
private boolean changeFlag = true ;
// changeFlag == true:数据被更改了,则需要重新遍历
// changeFlag == false:数据没有更改,不需要重新遍历
然后,我们修改LinkList类中的toArray()方法:(其他代码保持不变)
//方法:获取全部数据
public String[] toArray() {
if (this.size == 0) {
return null; // 没有数据
}
this.foot = 0; // 清零
if (this.changeFlag == true) { // 内容被修改了,需要重新取
this.retData = new String[this.size]; // 开辟数组大小
this.root.toArrayNode();
}
return this.retData;
}
9、根据索引位置取得数据:
- public 数据 get(int index)
在一个链表之中会有多个节点保存数据,现在要求可以取得指定节点位置上的数据。但是在进行这一操作的过程之中,有一个小问题:如果要取得数据的索引超过了数据的保存个数,那么是无法取得的。
在LinkList类之中,增加一个get()方法:
//方法:根据索引取得数据
public String get(int index) {
if (index > this.size) { // 超过个数
return null; // 返回null
}
this.foot = 0; // 操作foot来定义脚标
return this.root.getNode(index);
}
在Node类之中配置getNode()方法:
//根据索引位置获取数据
public String getNode(int index) {
if (LinkList.this.foot++ == index) { // 当前索引为查找数值
return this.data;
} else {
return this.next.getNode(index);
}
}
10、清空链表:
- public void clear()
所有的链表被root拽着,这个时候如果root为null,那么后面的数据都会断开,就表示都成了垃圾:
//清空链表
public void clear() {
this.root = null;
this.size = 0;
}
总结:
上面的10条方法中,LinkList的完整代码如下:
/**
* Created by smyhvae on 2015/8/27.
*/ public class LinkList { private int size;
private Node root; //定义一个根节点 private int foot = 0; // 操作返回数组的脚标
private String[] retData; // 返回数组
private boolean changeFlag = true;
// changeFlag == true:数据被更改了,则需要重新遍历
// changeFlag == false:数据没有更改,不需要重新遍历 //添加数据
public boolean add(String data) { if (data == null) { // 如果添加的是一个空数据,那增加失败
return false;
} // 将数据封装为节点,目的:节点有next可以处理关系
Node newNode = new Node(data);
// 链表的关键就在于根节点
if (root == null) { //如果根节点是空的,那么新添加的节点就是根节点。(第一次调用add方法时,根节点当然是空的了)
root = newNode;
} else {
root.addNode(newNode); } this.size++;
return true; } //方法:增加一组数据
public boolean addAll(String data[]) { // 一组数据
for (int x = 0; x < data.length; x++) {
if (!this.add(data[x])) { // 只要有一次添加不成功,那就是添加失败
return false;
}
}
return true;
} //方法:删除数据
public boolean remove(String data) { //要删除的节点,假设每个节点的data都不一样 if (!this.contains(data)) { //要删除的数据不存在
return false;
} if (root != null) {
if (root.data.equals(data)) { //说明根节点就是需要删除的节点
root = root.next; //让根节点的下一个节点成为根节点,自然就把根节点顶掉了嘛(不像数组那样,要将后面的数据在内存中整体挪一位)
} else { //否则
root.removeNode(data);
}
}
size--;
return true; } //输出所有节点
public void print() {
if (root != null) {
System.out.print(root.data);
root.printNode();
System.out.println();
}
} //方法:获取全部数据
public String[] toArray() {
if (this.size == 0) {
return null; // 没有数据
}
this.foot = 0; // 清零
this.retData = new String[this.size]; // 开辟数组大小
this.root.toArrayNode();
return this.retData;
} //获取数据的长度
public int size() {
return this.size;
} //判断是否为空链表
public boolean isEmpty() {
return this.size == 0;
} //清空链表
public void clear() {
this.root = null;
this.size = 0;
} //查询数据是否存在
public boolean contains(String data) { // 查找数据
// 根节点没有数据,查找的也没有数据
if (this.root == null || data == null) {
return false; // 不需要进行查找了
}
return this.root.containsNode(data); // 交给Node类处理
} //方法:根据索引取得数据
public String get(int index) {
if (index > this.size) { // 超过个数
return null; // 返回null
}
this.foot = 0; // 操作foot来定义脚标
return this.root.getNode(index);
} //定义一个节点内部类(假设要保存的数据类型是字符串)
//比较好的做法是,将Node定义为内部类,在这里面去完成增删、等功能,然后由LinkList去调用增、删的功能
class Node {
private String data;
private Node next; //next表示:下一个节点对象(单链表中) public Node(String data) {
this.data = data;
} //添加节点
public void addNode(Node newNode) { //下面这段用到了递归,需要反复理解
if (this.next == null) { // 递归的出口:如果当前节点之后没有节点,说明我可以在这个节点后面添加新节点
this.next = newNode; //添加新节点
} else {
this.next.addNode(newNode); //向下继续判断,直到当前节点之后没有节点为止 }
} //判断节点是否存在
public boolean containsNode(String data) { // 查找数据
if (data.equals(this.data)) { // 与当前节点数据吻合
return true;
} else { // 与当前节点数据不吻合
if (this.next != null) { // 还有下一个节点
return this.next.containsNode(data);
} else { // 没有后续节点
return false; // 查找不到
}
}
} //删除节点
public void removeNode(String data) {
if (this.next != null) {
if (this.next.data.equals(data)) {
this.next = this.next.next;
} else {
this.next.removeNode(data);
}
} } //输出所有节点
public void printNode() {
if (this.next != null) {
System.out.print("-->" + this.next.data);
this.next.printNode();
}
} //获取全部数据
public void toArrayNode() {
LinkList.this.retData[LinkList.this.foot++] = this.data;
if (this.next != null) {
this.next.toArrayNode();
}
} //根据索引位置获取数据
public String getNode(int index) {
if (LinkList.this.foot++ == index) { // 当前索引为查找数值
return this.data;
} else {
return this.next.getNode(index);
}
} }
}
四、单链表的效率分析:
在单链表的任何位置上插入数据元素的概率相等时,在单链表中插入一个数据元素时比较数据元素的平均次数为:
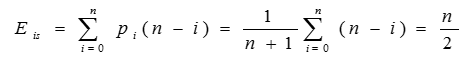
删除单链表的一个数据元素时比较数据元素的平均次数为:
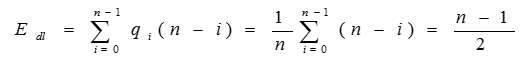
因此,单链表插入和删除操作的时间复杂度均为O(n)。另外,单链表读取数据元素操作的时间复杂度也为O(n)。
2、顺序表和单链表的比较:
顺序表:
优点:主要优点是支持随机读取,以及内存空间利用效率高;
缺点:主要缺点是需要预先给出数组的最大数据元素个数,而这通常很难准确作到。当实际的数据元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
单链表:
优点:主要优点是不需要预先给出数据元素的最大个数。另外,单链表插入和删除操作时不需要移动数据元素;
缺点:主要缺点是每个结点中要有一个指针,因此单链表的空间利用率略低于顺序表的。另外,单链表不支持随机读取,单链表取数据元素操作的时间复杂度为O(n);而顺序表支持随机读取,顺序表取数据元素操作的时间复杂度为O(1)。
数据结构Java实现03----单向链表的插入和删除的更多相关文章
- 数据结构Java实现02----单向链表的插入和删除
文本主要内容: 链表结构 单链表代码实现 单链表的效率分析 一.链表结构: (物理存储结构上不连续,逻辑上连续:大小不固定) 概念: 链式存储结构是基于指针实现的.我们把一个数据 ...
- 数据结构Java实现04----循环链表、仿真链表
单向循环链表 双向循环链表 仿真链表 一.单向循环链表: 1.概念: 单向循环链表是单链表的另一种形式,其结构特点是链表中最后一个结点的指针不再是结束标记,而是指向整个链表的第一个结点,从而使单链表形 ...
- 【线性表基础】顺序表和单链表的插入、删除等基本操作【Java版】
本文表述了线性表及其基本操作的代码[Java实现] 参考书籍 :<数据结构 --Java语言描述>/刘小晶 ,杜选主编 线性表需要的基本功能有:动态地增长或收缩:对线性表的任何数据元素进行 ...
- 数据结构和算法之单向链表二:获取倒数第K个节点
我们在做算法的时候或多或少都会遇到这样的问题,那就是我们需要获取某一个数据集的倒数或者正数第几个数据.那么今天我们来看一下这个问题,怎么去获取倒数第K个节点.我们拿到这个问题的时候自然而然会想到我们让 ...
- 面试之路(10)-BAT面试之java实现单链表的插入和删除
链表的结构: 链表在空间是不连续的,包括: 数据域(用于存储数据) 指针域(用于存储下一个node的指针) 单项链表的代码实现: 节点类 构造函数 数据域的get,set方法 指针域的get,set方 ...
- 数据结构之 线性表---单链表操作A (删除链表中的指定元素)
数据结构上机测试2-1:单链表操作A Time Limit: 1000MS Memory limit: 4096K 题目描述 输入n个整数,先按照数据输入的顺序建立一个带头结点的单链表,再输入一个数据 ...
- Java实现 LeetCode 380 常数时间插入、删除和获取随机元素
380. 常数时间插入.删除和获取随机元素 设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构. insert(val):当元素 val 不存在时,向集合中插入该项. remove( ...
- Java 获取Word中的所有插入和删除修订
在 Word 文档中启用跟踪更改功能后,会记录文档中的所有编辑行为,例如插入.删除.替换和格式更改.对插入或删除的内容,可通过本文中介绍的方法来获取. 引入Jar 方法1 手动引入:将 Free Sp ...
- 纯数据结构Java实现(3/11)(链表)
题外话: 篇幅停了一下,特意去看看其他人写的类似的内容:然后发现类似博主喜欢画图,喜欢讲解原理. (于是我就在想了,理解数据结构的确需要画图,但我的文章写给懂得人看,只配少量图即可,省事儿) 下面正题 ...
随机推荐
- Fundamentals of speech signal processing
PDF版资料下载:链接:http://pan.baidu.com/s/1hrKntkw 密码:f2y9
- [Architecture Design] 3-Layer基础架构
[Architecture Design] 3-Layer基础架构 三层式体系结构 只要是软件从业人员,不管是不是本科系出身的,相信对于三层式体系结构一定都不陌生.在三层式体系结构中,将软件开发所产出 ...
- angular 指令——时钟范例
<html> <head> <meta charset='utf-8'> <title>模块化</title> <script typ ...
- Mybatis学习记录(五)----Mybatis的动态SQL
1. 什么是动态sql mybatis核心 对sql语句进行灵活操作,通过表达式进行判断,对sql进行灵活拼接.组装. 1.1 需求 用户信息综合查询列表和用户信息查询列表总数这两个statemen ...
- Sharepoint学习笔记—习题系列--70-573习题解析 -(Q48-Q50)
Question 48You create a user control named MySearchBox.ascx.You plan to change the native search con ...
- Universal-Image-Loader完全解析(上)
Universal-Image-Loader完全解析(上) 基本介绍及使用 大家平时做项目的时候,或多或少都会接触到异步加载图片,或者大量加载图片的问题,而加载图片时候经常会遇到各种问题,如oom,图 ...
- 【原】error C2679: binary '<<' : no operator found which takes a right-hand operand of type 'std::string'
今天遇到一个非常难以排查的BUG,谷歌度娘都问过了依旧无解,最后自己重新尝试之后找到解决方案: 先看一下报错信息: 1>.\lenz.cpp(2197) error C2679: binary ...
- iOS 你将会遇到的
1.解释ARC原理,ARC引入之后,iOS增加了几个修饰符,分别是什么?并解释何时应该使用? 2.给你一个可变数组aMutableArray,请写出你认为较好的算法代码. 3.UITableView是 ...
- android学习笔记 Service
Service(服务): 长期后台运行的没有界面的组件 android应用什么地方需要用到服务? 天气预报:后台的连接服务器的逻辑,每隔一段时间获取最新的天气信息.股票显示:后台的连接服务器的逻辑,每 ...
- 高仿700Bike的界面图片
下面展示本人高仿项目"700Bike"的已经完成的界面: