Linux网络编程(学习笔记)
文中python代码来自老师的教学代码,感谢我的老师~~
1. linux网络数据处理过程:
网卡->协议栈->网络
1)应用层输出数据
socket层->协议层->接口层
2)应用层接收数据
内核层(接口层->协议层->插口层)->用户空间的用户应用
2.socket是什么
socket类似jdbc,是一种接口,每种操作系统有不同的实现方式。
调用顺序:
1) socket(服务器、客户端)

2) bind(服务器)

3) listen(服务器)

4) accept(服务器)
在listen后调用,取出队列里第一个连接请求,并创建另一个和sockfd有相同属性的套接字。

5) connect调用(客户端)

3.主机字节序与网络字节序
1)主机字节序
指数据存储的模式(大端模式、小端模式)
2)网络字节序
按大端模式传输数据。
网络存在不同的操作系统,数据存储方式可能是大端也可能是小端模式。为实现正常通信,需要实现网络字节序和主机字节序之间的转换。
3)字节序转换函数

4. socket stream服务
SOKC_STREAM代表数据流,即采用TCP传输协议。

模拟客户端发送数据,服务端接收数据
#客户端
import socket
HOST="127.0.0.1"
PORT=6666
print("connect to server :",HOST,"port=",PORT)
client=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
client.connect((HOST,PORT))
while True:
cmd = input("please input , # to exit: ")
if cmd == "#" :
break
client.send(bytes(cmd,"utf-8"))
data=client.recv(100)
print("recv from server:",data)
client.close()
#服务端
#在主进程中使用recv,当客户端一直保持连接而不发送数据时,可能导致卡在recv这一步无法继续执行下去;
#因此一般使用一个独立的子进程接收消息
HOST="0.0.0.0"
PORT=6666
print("server list at port=",PORT)
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind((HOST,PORT))
server.listen(5)
while True:
print("waiting client....")
conn,address = server.accept()
print("receive a connection from client:",address)
while True:
data=conn.recv(100)
if not data:
print("connection close by client")
break
print(data)
conn.send(data[::-1])
server.close()
5. TCP的粘包与分包
前置知识:Nagle算法
Nagle算法:如果发送端欲多次发送包含少量字符的数据包(一般情况下,后面统一称长度小于MSS的数据包为小包,与此相对,称长度等于MSS的数据包为大包,为了某些对比说明,还有中包,即长度比小包长,但又不足一个MSS的包),则发送端会先将第一个小包发送出去,而将后面到达的少量字符数据都缓存起来而不立即发送,直到收到接收端对前一个数据包报文段的ACK确认、或当前字符属于紧急数据,或者积攒到了一定数量的数据(比如缓存的字符数据已经达到数据包报文段的最大长度)等多种情况才将其组成一个较大的数据包发送出去。
1)粘包与分包是什么:
TCP面向流,没有分界。操作系统在发送TCP数据时,会通过缓冲区来进行优化。
- 如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这就形成了粘包问题。
- 如果一次请求发送的数据量比较大,超过了缓冲区大小,TCP就会将其拆分为多次发送,这就是拆包。

2)粘包与分包产生的原因
5.2.1粘包原因
TCP:由于TCP协议本身的机制(面向连接可靠的协议,三次握手四次挥手)客户段与服务端会建立一个链接,数据在链接不断开的情况下,可以持续不断地将多个数据包发往服务端,相当于一个流,但是如果发送的网络数据包太小,那么他本身会启用Nagle算法(当然是可配置是否启用)对较小的数据包进行合并(基于此,TCP的网络延迟要UDP的高些,因为需要合并延时发送)然后再发送(超时或者包大小足够)。
因此,服务端在接收到消息(数据流)的时候就无法区分哪些数据包是客户端自己分开发送的,这样产生了粘包;还有一种情况,服务端在接收到数据后,然后放到缓冲区中,如果消息没有被及时从缓存区取走,下次在取数据的时候可能就会出现一次取出多个数据包的情况,造成粘包现象
UDP:作为无连接的不可靠协议(适合频繁发送较小的数据包),UDP不会对数据包进行合并发送(没有Nagle算法之说)。发送端需要发送什么数据,直接就发出去了。既然UDP不会对数据合并,每一个数据包都是完整的(数据+UDP头+IP头等等发一次数据封装一次)也就没有粘包一说了。
5.2.2分包原因
- IP分片传输(MTU>1500)
- 一个包可能被分成了多次传输
- 传输过程中丢失部分包
- TCP流量控制
3)解决办法
5.3.1采用分隔符
在封装要发送的数据包的时候,采用固定的字符作为结尾符(但前面的数据中不能含有结尾符)。在接收方接收到数据包后,如果发现结尾标识,手动将粘包分开;
如果一个包中没有出现结尾符,认为出现了分包,则等待下个包中出现后 组合成一个完整的数据包,这种方式适合于文本传输的数据,如采用/r/n之类的分隔符;
5.3.2在数据包中添加长度
在数据包中的固定位置封装数据包的长度信息(或可计算数据包总长度的信息),服务器接收到数据后,先是解析包长度,然后根据包长度截取数据包。
可能出现的问题:如果客户端第一个数据包数据长度封装的有错误,那么很可能就会导致后面接收到的所有数据包都解析出错(由于TCP建立连接后流式传输机制),只有客户端关闭连接后重新打开才可以消除此问题。
解决方案:对数据长度进行校验,适时地对接收到的有问题的包进行人为的丢弃处理(客户端有自动重发机制,故而在应用层不会导致数据的不完整性);
6. Socket数据包服务
采用UDP协议,流程与stream服务相似。

#老师的客户端代码
import socket
ip_port = ('127.0.0.1',9999)
print("connect to server:",ip_port)
client = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
client.connect(ip_port)
while True:
message=input("please input, # to exit:")
if message =="#":
break
client.send(message.encode("utf-8"))
data=client.recv(100)
print("client recv:",data)
client.close()
#老师的服务端代码
import socket
ip_port = ('0.0.0.0',9999)
server = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
print("udp server at:",ip_port)
server.bind(ip_port)
while True:
data,addr = server.recvfrom(1024)
print("recev from client",addr," data=",data)
server.sendto(data,addr)
server.close()
7. 多路复用
1)select多路复用
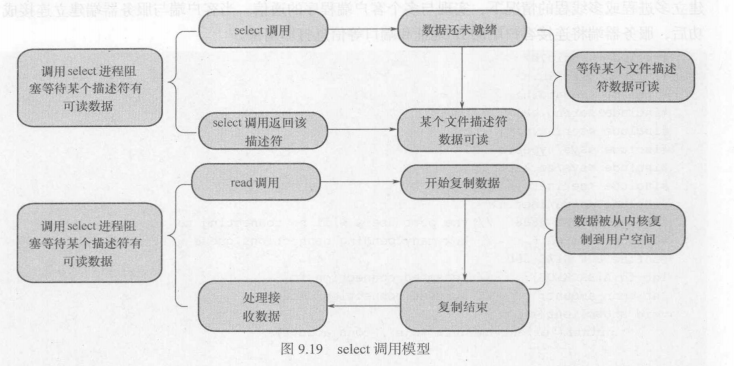
select是通过系统调用来监视一组由多个文件描述符组成的数组,通过调用select()返回结果,数组中就绪的文件描述符会被内核标记出来,然后进程就可以获得这些文件描述符,然后进行相应的读写操作。
select的实际执行过程如下:
1、select需要提供要监控的数组,然后由用户态拷贝到内核态。
2、内核态线性循环监控数组,每次都需要遍历整个数组。
3、内核发现文件描述符状态符合操作结果,将其返回。
所以对于我们监控的socket都要设置为非阻塞的,只有这样才能保证不会被阻塞。
import socket
import select
HOST="0.0.0.0"
PORT=6666
print("server list at port=",PORT)
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind((HOST,PORT))
server.listen(5)
rd_sets=[server]
print("waiting client....")
while True:
#pool rd_sets in 1 second
#监听rd_sets中的元素,把【有变化】的放入rl中
#如果有人连接server,则rl=[server]
rl,wl,el=select.select(rd_sets,[],[],1)
for client in rl:
if client == server: #表示有新用户连到本服务
conn,address = server.accept() #取到客户端套接字
rd_sets.append(conn) #加入readlist
print("receive a connection from client:",address)
else:
data=client.recv(1024) #有老用户发消息
if not data:
rd_sets.remove(client) #如果用户中断连接,则移除句柄。remove client from readlist
print("connection close by client",client.getpeername())
break
print("client=",client.getpeername(),"data=",data) #用户正常发送信息
client.send(data[::-1])
server.close()
2)epoll系统调用
7.2.1 select与poll的缺点:
(1)单个进程能够监视的文件描述符的数量存在最大限制,通常是1024,当然可以更改数量(在linux内核头文件中,有这样的定义:#define __FD_SETSIZE 1024),但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差。
(2)内核和用户空间之间的内存拷贝问题,因为我们每次调用select和poll时。都会填写相应的位数组和其他的参数,select和poll需要复制大量的句柄数据结构到内核空间进行监听,监听完成后需要把发生事件句柄再拷贝到用户空间,会产生巨大的开销。
(3)select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件。poll和select一样,都是轮询。
(4)select和poll的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select和poll调用还是会将这些文件描述符通知进程。同一个事件,数据没有读完,会多次触发,效率低。
7.2.2 epoll原理及优势
epoll的实现机制与select/poll机制完全不同,它们的缺点在epoll上不复存在
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百个TCP连接是活跃的(事实上大部分场景都是这种情况),如何实现这样的高并发?
在select / poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完成后,再将句柄数据拷贝到用户空间,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此select/poll一般只能处理几千的并发连接
epoll的设计和实现与select完全不同,epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用B+树实现,磁盘IO消耗低,效率很高)
把原先的select/poll调用分成以下3个部分:
调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
调用epoll_ctl向epoll对象中添加这100万个连接的套接字,以红黑树的形式组织,增删查是
\[O(log2n)
\]调用epoll_wait收集发生的事件的fd资源,发生事件的fd会从红黑树上拷贝到双向链表,用于返回给用户。用户拿到的就只有发生事件的文件描述符了
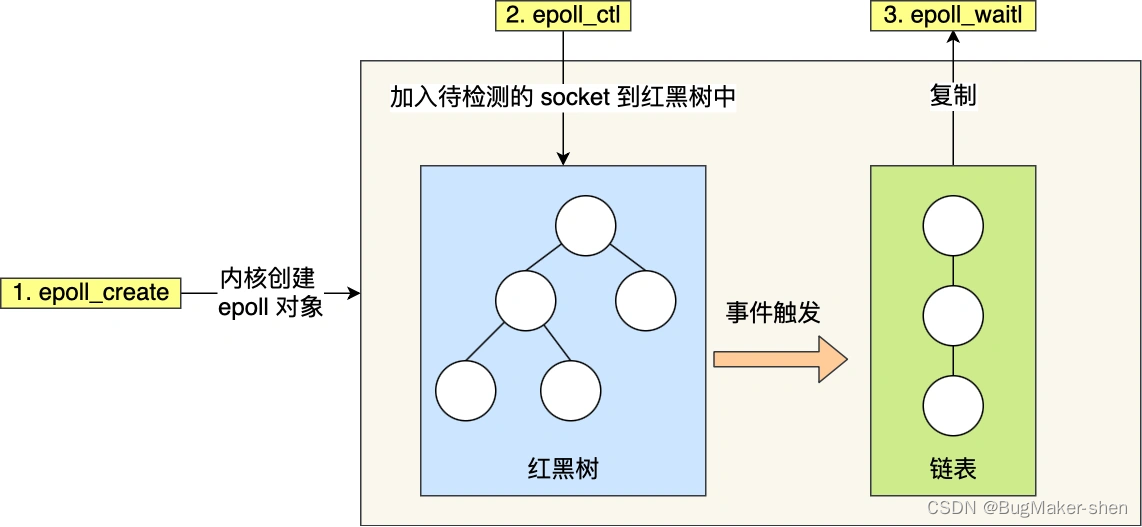
epoll以上部分原文链接:https://blog.csdn.net/qq_42500831/article/details/124126248
7.2.3 关于epoll的“内存共享”(原创)
1)上周,老师在授课中提到,书本中这个epoll所谓的 “共享内存” 可能存疑。于是作者上网查找了相关资料以及源码,发现不少博客提到:
- epoll使用的是共享内存的方式,即用户态和内核态都指向了就绪链表,所以就避免了内存拷贝消耗
- epoll是共享内存,拷贝都不用,相对来说应该会更快。epoll是通过内核与用户空间mmap同一块内存实现的。
但在知乎等平台有不少不同的声音,表示epoll并不存在所谓的“共享内存”,仍然需要进行从内核空间到用户空间的复制。
2)通过翻阅eventpoll.c源码发现,在开头的注释中已经指出,会进行从内核到用户空间的事件传递:
/*
*During the event transfer loop (from kernel to
* user space) we could end up sleeping due a copy_to_user(), so
* we need a lock that will allow us to sleep.
*/
在static int ep_poll函数中,存在Try to transfer events to user space.即存在内核到用户空间的传递:
if (eavail) {
/*
* Try to transfer events to user space. In case we get
* 0 events and there's still timeout left over, we go
* trying again in search of more luck.
*/
res = ep_send_events(ep, events, maxevents);
if (res)
return res;
}
在epoll_wait的实现中,__put_user的功能为内核拷贝到用户空间:
if (revents) {
/* 将当前的事件和用户传入的数据都copy给用户空间,
* 就是epoll_wait()后应用程序能读到的那一堆数据. */
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
/* 如果copy过程中发生错误, 会中断链表的扫描,
* 并把当前发生错误的epitem重新插入到ready list.
* 剩下的没处理的epitem也不会丢弃, 在ep_scan_ready_list()
* 中它们也会被重新插入到ready list */
list_add(&epi->rdllink, head);
return eventcnt ? eventcnt : -EFAULT;
}
3)结论
由上可知,epoll所谓的内核与用户空间通过mmap方式“共享内存”,是错误的。
------------2023.5.23更新----------
3) epoll工作流程图
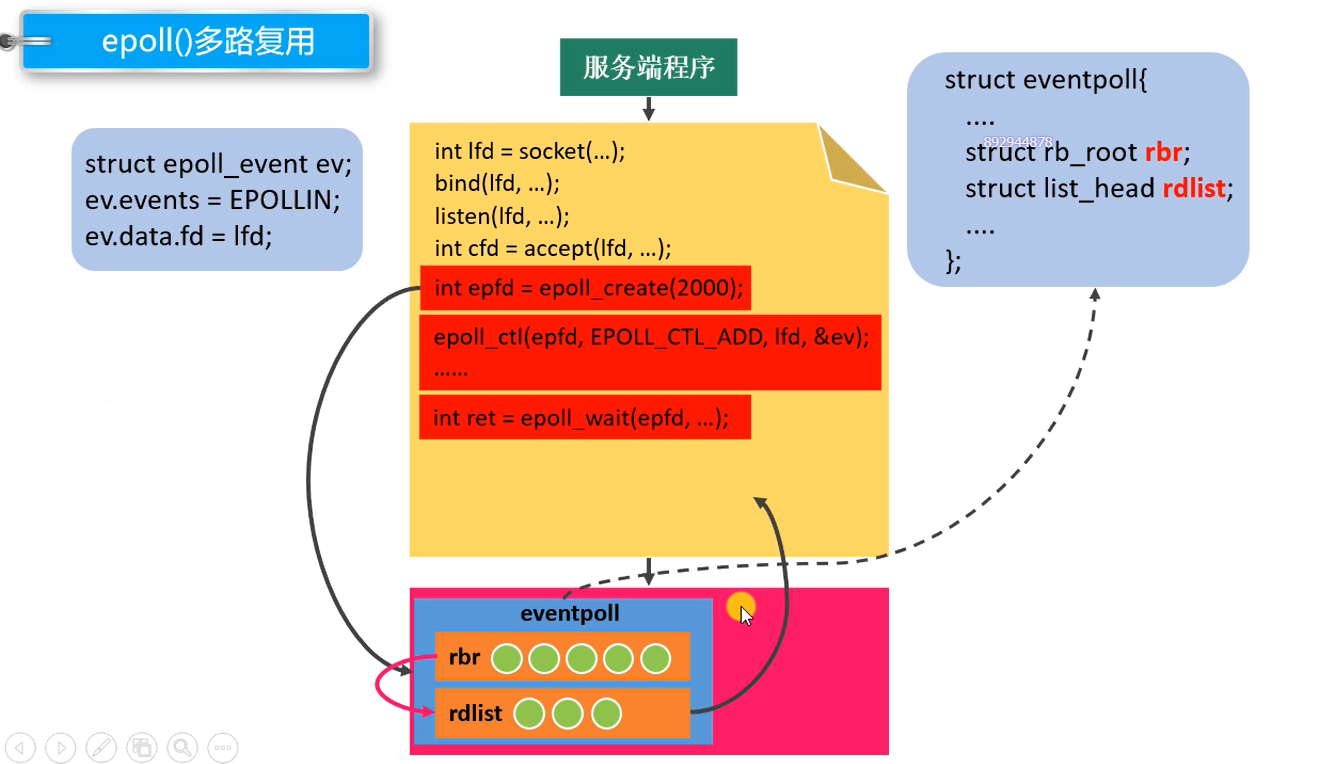
可以看到,rd,即存放epoll事件的红黑树被直接创建在内核中。在这一步,select与poll需要进行从用户空间到内核的拷贝。相比之下,epoll可以少拷贝一次。
当事件就绪,被放入就绪队列rdlist后,rdlist中的内容将从内核被拷贝到用户空间。即2)中的 epoll_wait()源码。此处存在内核到用户空间的拷贝。
7.2.4 epoll实例
#与select部分的类似
import socket
import select
HOST="0.0.0.0"
PORT=6666
print("server list at port=",PORT)
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind((HOST,PORT))
server.listen(5)
client_dict={}
epoll_obj=select.epoll()
epoll_obj.register(server.fileno(),select.EPOLLIN|select.EPOLLET)
print("waiting client....")
while True:
#print("waiting client....")
rl=epoll_obj.poll()
for fd,event in rl:
if fd == server.fileno():
conn,address = server.accept()
epoll_obj.register(conn.fileno(),select.EPOLLIN|select.EPOLLET)
client_dict[conn.fileno()]=conn
print("receive a connection from client:",address)
else:
client=client_dict[fd]
data=client.recv(1024)
if not data:
print("connection close by client,",client.getpeername())
epoll_obj.unregister(fd)
client_dict.pop(fd)
client.close()
break
print("client=",client.getpeername(),"data=",data)
client.send(data[::-1])
server.close()
8. linux网络并发编程
1)模型介绍
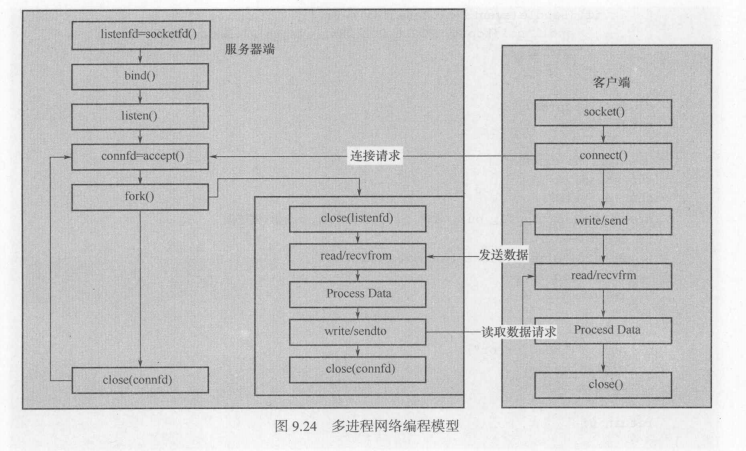
父进程实现socket的建立、绑定和监听,当有新的客户端连接请求时,新建立一个子进程与该连接传输数据。
父进程主要工作如下:
1)创建服务端socket并监听;
2)接收客户端连接请求;
3)创建子进程处理请求。
子进程主要工作如下:
1)处理客户端请求并作出应答;
2)每个子进程处理一个客户端请求;
3)当请求较多时创建较多子进程。
2)代码实例
遇到一个新的客户端连接请求,创建一个新的子进程的例子:
即主进程像一个前台,来一个客人,就为该客人分配好一个服务窗口。
import socket
import os
import signal
#HOST="127.0.0.1"
HOST="0.0.0.0"
PORT=6666
def handle_request(conn,addr):
print("receive a connection from client:",address)
while True:
data=conn.recv(100)
if not data:
print("connection close by client",address)
break
print("address=",address,"data=",data)
conn.send(data[::-1])
conn.close()
def handle_sigchld(signum,frame):
while True:
try:
pid,status=os.waitpid(-1,os.WNOHANG) # wait any child do not block
except OSError:
return
print("terminate child pid=",pid)
#---------main--------------------
print("server list at port=",PORT)
signal.signal(signal.SIGCHLD,handle_sigchld) #用信号配合waitpid处理僵尸进程
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind((HOST,PORT))
server.listen(10)
while True:
print("waiting client....")
conn,address = server.accept()
pid=os.fork()
if pid ==0 : #child
server.close() #close child copy
handle_request(conn,address)
os._exit(0)
else: #parent
conn.close() # close parent copy and waiting next conn...
server.close()
进程池例子:
主进程事先分配好五个服务窗口,客人来到时,由首先抢到客人的服务窗口对客人进行服务。
#进程池的例子
import socket
import os
import signal
HOST="0.0.0.0"
PORT=6666
def handle_request(server):
while True:
conn,addr=server.accept() #此处可能导致惊群效应,消耗资源;上面提到的epoll也会有惊群效应
while True:
data=conn.recv(100)
if not data:
print("connection close by client",address)
break
print("address=",address,"data=",data)
conn.send(data[::-1])
def handle_sigchld(signum,frame):
while True:
try:
pid,status=os.waitpid(-1,os.WNOHANG) # wait any child do not block
except OSError:
return
print("terminate child pid=",pid)
#---------main--------------------
print("server list at port=",PORT)
signal.signal(signal.SIGCHLD,handle_sigchld)
server=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
server.bind((HOST,PORT))
server.listen(10)
print("waiting client....")
for i in range(5):
pid=os.fork()
if pid ==0 : #child
server.close() #close child copy
handle_request()
os._exit(0)
while True:
pid,status=os.waitpid(-1,0) # wait any child do not block
3)惊群效应的解决(简略)
linux新版内核中,在阻塞队列中引入了WQ_FLAG_EXCLUSIVE标识,可以用它来解决惊群问题,基本思路是在进入到阻塞队列的时候给线程加上一个WQ_FLAG_EXCLUSIVE标识,当阻塞事件解除后,唤醒阻塞队列中的线程时,会依次遍历阻塞队列:遍历时如果阻塞队列中的线程没有WQ_FLAG_EXCLUSIVE标识,那就直接唤醒;当遇到第一个带有WQ_FLAG_EXCLUSIVE的线程时,同样去唤醒该线程,然后结束遍历。这样就保证了一次就绪事件发生,就只会唤醒一个WQ_FLAG_EXCLUSIVE标识的线程。
accept()的惊群就是这么解决的,因为调用accept()而被阻塞的线程,进入阻塞队列的时候,就会被打上WQ_FLAG_EXCLUSIVE标识,这样当客户端连接请求到来的时候,就只会有一个因accept而阻塞的线程被唤醒,从而避免惊群问题。
Linux网络编程(学习笔记)的更多相关文章
- linux网络编程学习笔记之四 -----多-threaded服务器
对于使用过程中并发.通过实现更轻量级线程. 每个线程都是一个独立的逻辑流. 主题是CPU在执行调度的最小独立单位,这个过程是资源分配单元.当然,这是在微内核操作系统说.总之,这是唯一的一个操作系统内核 ...
- linux网络编程学习笔记之五 -----并发机制与线程�
进程线程分配方式 简述下常见的进程和线程分配方式:(好吧,我仅仅是举几个样例作为笔记...并发的水太深了,不敢妄谈...) 1.进程线程预分配 简言之,当I/O开销大于计算开销且并发量较大时,为了节省 ...
- linux网络编程学习笔记之三 -----多进程并发服务端
首先是fork()函数.移步APUE 8.3. 比較清晰的解释能够參考http://blog.csdn.net/lingdxuyan/article/details/4993883和http://w ...
- linux网络编程学习笔记之二 -----错误异常处理和各种碎碎(更新中)
errno 在unix系统中对大部分系统调用非正常返回时,通常返回值为-1.并设置全局变量errno(errno.h),如socket(), bind(), accept(), listen(). e ...
- 转 网络编程学习笔记一:Socket编程
题外话 前几天和朋友聊天,朋友问我怎么最近不写博客了,一个是因为最近在忙着公司使用的一些控件的开发,浏览器兼容性搞死人:但主要是因为这段时间一直在看html5的东西,看到web socket时觉得很有 ...
- Linux Shell编程学习笔记——目录(附笔记资源下载)
LinuxShell编程学习笔记目录附笔记资源下载 目录(?)[-] 写在前面 第一部分 Shell基础编程 第二部分 Linux Shell高级编程技巧 资源下载 写在前面 最近花了些时间学习She ...
- Linux网络编程学习计划
由于网络编程是很重要的一块,自己这一块也比较欠缺,只知道一些皮毛,从今天开始系统学习<Linux网络编程>一书,全书分为十四个章节: 第一章 概论 P1-16 第二章 UNIX ...
- Linux网络编程学习路线
转载自:https://blog.csdn.net/lianghe_work/article 一.网络应用层编程 1.Linux网络编程01——网络协议入门 2.Linux网络编程02——无连接和 ...
- Linux C网络编程学习笔记
Linux C网络编程总结报告 一.Linux C 网络编程知识介绍: 网络程序和普通的程序有一个最大的区别是网络程序是由两个部分组成的--客户端和服务器端. 客户端:(client) 在网络程序中, ...
- 网络编程学习笔记-linux常用的网络命令
网络参数设置命令 所有时刻如果你想要做好自己的网络参数设置,包括IP参数.路由参数和无线网络等,就得要了解下面这些相关的命令才行.其中Route及ip这两条命令是比较重要的.当然,比较早期的用法,我们 ...
随机推荐
- 软件开发定律:海勒姆定律(Hyrum's Law)
hi,我是熵减,见字如面. 在软件开发中,你是否遇到过这种情况: 你正在开发一个购物车的功能,需要在用户添加商品到购物车时,将商品的信息存储到数据库中.你设计了一个简单的方法,如下所示: public ...
- CentOS8 搭建zabbix监控系统
哈喽,有些时间没有更新公众号.今日更新一下. 安装MySQL数据库 # 安装wget [root@cby ~]# dnf install wget -y # 下载MySQL源 [root@cby ~] ...
- CRC(Cyclic Redundancy Check)
CRC(循环冗余校验) [参考资料] https://en.wikipedia.org/wiki/Cyclic_redundancy_check https://wiki.segger.com/CRC ...
- 一款能“干掉” ChatGPT 的应用「GitHub 热点速览」
据说有了它,ChatGPT 就可以靠边站了.因为 Auto-GPT 能更加主动地完成你给他的指定任务,不用做更多的人为干涉,它的推理能力比 ChatGPT 更强,有人用它解放双手做了个 React 网 ...
- HashMap实现原理和自动扩容
HashMap实现原理: JDK1.7:数组+单向链表(头插) 在并发情况下头插可能出现循环链表(死循环)问题.原因:因为头插,在新数组中链表的元素顺序发生了变化, 如上图,假设线程1在扩容,刚刚调整 ...
- 如何通过C#/VB.NET 代码调整PDF文档的页边距
PDF边距是页面主要内容区域和页面边缘之间的距离.与Word页边距不同,PDF文档的页边距很难更改.因为Adobe没有提供操作页边距的直接方法.但是,您可以通过缩放页面内容来改变页边距.本文将介绍如何 ...
- C# Nuget版本号排序
Nuget包版本号和我们软件应用版本号一样,不过因为稳定性等的考虑,组件版本有更高的要求.预发布版本使用频率更高 版本号介绍,详见我朋友胡承老司机的博客:Nuget包的版本规范 (qq.com) 我这 ...
- 一天吃透SpringBoot面试八股文
Springboot的优点 内置servlet容器,不需要在服务器部署 tomcat.只需要将项目打成 jar 包,使用 java -jar xxx.jar一键式启动项目 SpringBoot提供了s ...
- Prism Sample 17-BasicRegionNavigation
本例是基础的导航应用 在窗口中布局了2个按钮,一个区域 <DockPanel LastChildFill="True"> <StackPanel Orientat ...
- jQuery实现swipe事件
// jQuery.event.swipe // 0.5 // Stephen Band // Dependencies // jQuery.event.move 1.2 // One of swip ...