日志架构演进:从集中式到分布式的Kubernetes日志策略
当我们没有使用云原生方案部署应用时采用的日志方案往往是 ELK 技术栈。
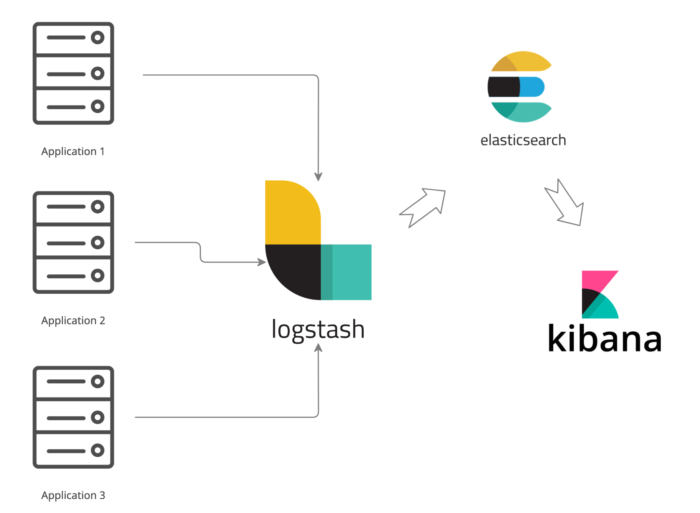
这套技术方案比较成熟,稳定性也很高,所以几乎成为了当时的标配。
可是随着我们使用 kubernetes 步入云原生的时代后, kubernetes 把以往的操作系统上的许多底层都屏蔽,再由他提供了一些标准接口。
同时在 kubernetes 中的日志来源也比传统虚拟机多,比如可能有容器、kubernetes 自身的事件、日志等。
我们的日志采集方案也得与时俱进,kubernetes 的官方博客有介绍提供一下几种方案:
节点采集
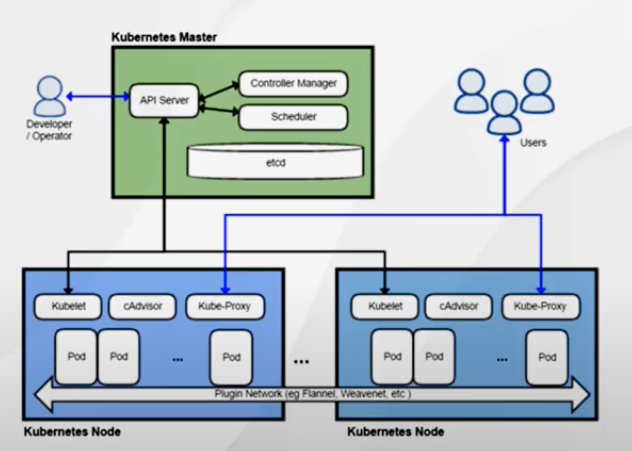
第一种方案是在节点中采集日志,我们知道 kubernetes 是分为 master 调度节点以及 worker 工作节点;我们的应用都是运行在 worker 节点中的。
在 kubernetes 环境中更推荐使用标准的 stdout/stderr 作为日志输出,这样 kubernetes 更方便做统一处理。
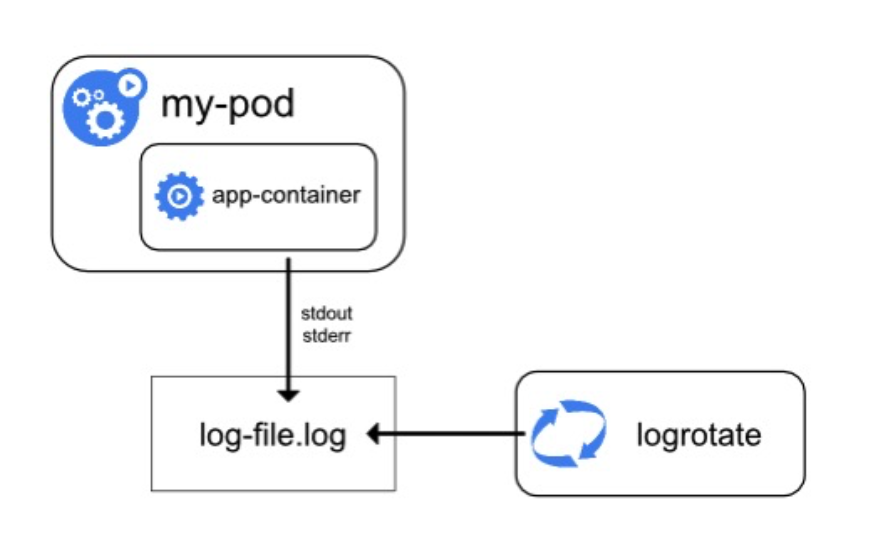
以我们的 docker 运行时为例,默认情况下我们的标准输入文件会写入到 /var/log 目录中。
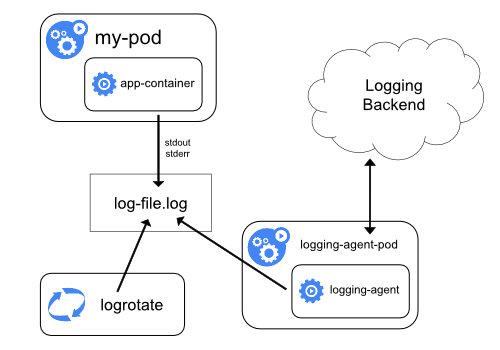
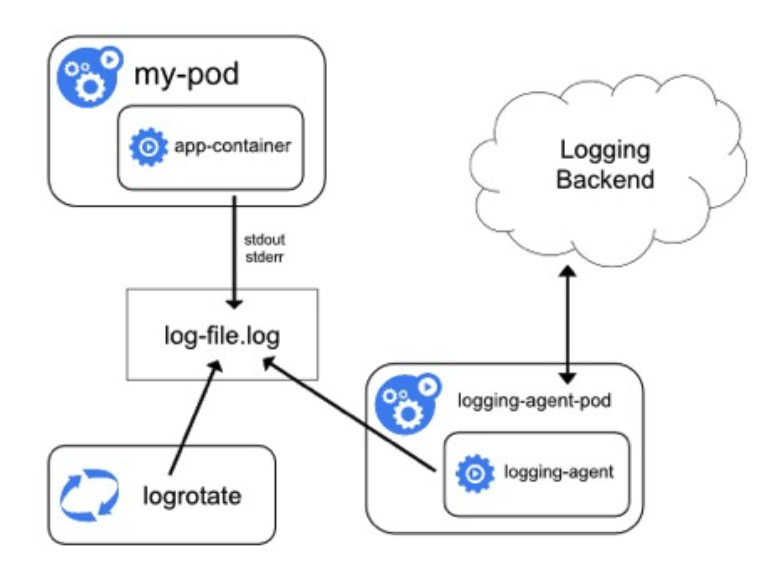
如上图所示:我们可以在 kubernetes 的每一个 worker 节点中部署一个 DaemonSet 类型的采集器(filebeat 等),再由他去采集该节点下 /var/log 的日志,最终由他将日志采集后发往日志处理的后端,比如 elasticsearch 等组件中。
这种方案的好处是资源占用较低,往往是有多少个 worker 节点就可以部署多少个采集器。
而且和业务的耦合度低,业务和采集器不管谁进行重启或升级互相都不会产生影响。
但缺点也比较明显,整个节点的日志采集瓶颈都在这个采集器这里了,如果某些 worker 节点的 Pod 数量不均衡,或者是本身日志产生也不平均时就会出现明显的负债不平衡。
而且也无法针对某些日志高峰场景进行调优(毕竟所有的 Pod 都是使用的一个日志采集器)。
所以节点级的日志采集更适用与该 worker 节点负债较低的时候使用,也更容易维护。
Sidecar 代理模式
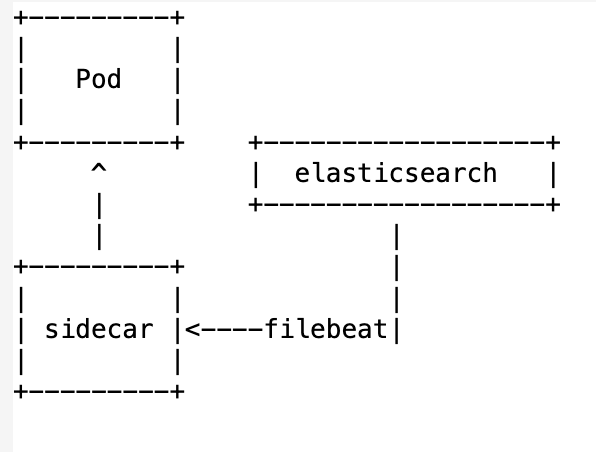
第二种相对于第一种可以理解为由集中式的日志采集分散到各个应用 Pod 中自行采集。
需要为每一个业务 Pod 挂载一个边车(sidecar)进行日志采集,由于边车和业务 Pod 共享的是一个存储,所以可以很方便的读取到日志。
由于它是和应用挂载在一起的,所以资源占用自然会比节点采集更多,同理耦合度也增加了,采集组件的升级可能还会影响的业务 Pod。
但同样的带来好处就是可以针对单个 Pod 更精细的控制采集方案。
比如对于一些日志写入频繁的应用,可以将 filebeat 的配置提高,甚至还可以将这种高负载的日志单独写入一个 elasticsearch 中,这样可以与普通负载的日志进行资源隔离。
这个方案更适用与集群规模较大的场景,需要做一些精细化配置。
我们其实也是采用的也是这个方案,不过具体细节稍有不同。
我们没有直接使用标准输入和输出,原因如下:
日志格式没法统一,导致最终查询的时候无法做一些标准化的限制(比如我们要求每个日志都需要带业务 id、traceId 等,查询时候有这些业务指标就很容易沉淀一些标准的查询语句。)
最终我们还是采用了 Java 的老朋友,logback 配置了自己的日志格式,所有的应用都会根据这个模版进行日志输出。
同时利用日志框架的批量写入、缓冲等特性还更容易进行日志的性能调优。(只使用标准输出时对应用来说是黑盒。)
最终我们的技术方案是:
直接写入
还有一种方案是直接写入,这个其实和 kubernetes 本身就没有太多关系了。
由业务自己调用 elasticsearch 或者其他的存储组件的 API 进行写入,这种通常适用于对性能要求较高的场景,略过了中间的采集步骤,直接写入存储端。
这个我在 VictoriaLogs:一款超低占用的 ElasticSearch 替代方案中介绍过,我需要在 broker 的拦截器中埋点消息信息,从而可以生成一个消息的链路信息。
因为需要拦截消息的发送、消费的各个阶段,加上并发压力较高,所以对日志的写入性能要求还是蛮高的。
因此就需要在拦截器中直接对写入到日志存储。
这里考虑到我这里的但一场景,以及对资源的消耗,最终选取了
victoriaLog这个日志存储。
而在发送日志的时候也得用了高性能的日志发生框架,这里选取了aliyun-log-java-producer然后做了一些定制。
这个库支持以下一些功能:
- 高性能:批量发送、多线程等
- 自动重试
- 异步非阻塞
- 资源控制(可以对内存、数量进行控制)
因为这是为阿里云日志服务的一个组件,代码里硬编码了只能写入阿里的日志服务。
所以拿来稍加改造后,现在可以支持自定义发送到任意后端,只需要在初始化时自定义实现发送回调接口即可:
ProducerConfig producerConfig = new ProducerConfig();
producerConfig.setSenderArgs(new Object[]{vlogUrl, client});
producerConfig.setSender((batch, args) -> {
StringBuilder body = new StringBuilder();
for (String s : batch.getLogItemsString()) {
body.append("{\"create\":{}}");
body.append("\n");
body.append(s);
body.append("\n");
}
RequestBody requestBody =
RequestBody.create(MediaType.parse("application/json"), body.toString());
Request request =
new Request.Builder()
.url(String.format("%s/insert/elasticsearch/_bulk", args[0]))
.post(requestBody)
.build();
OkHttpClient okHttpClient = (OkHttpClient) args[1];
try (Response response = okHttpClient.newCall(request).execute()) {
if (response.isSuccessful()) {
} else {
log.error("Request failed with error code: " + response);
}
} catch (IOException e) {
log.error("Send vlogs failed", e);
throw e;
}
});
logProducer = new LogProducer(producerConfig);
考虑到这个库只是对阿里云日志服务的一个组件,加上代码已经很久没维护了,所以就没有将这部分代码提交到社区,感兴趣的评论区留言。
日志安全
日志是一个非常基础但又很敏感的功能,首先是编码规范上要避免打印一些敏感信息;比如身份证、密码等;同时对日志的访问也要最好权限控制。
在我们内部的研效平台中,对于日志、监控等功能都是和应用权限挂钩的。
简单来说就是关闭了统一查询 ES 的入口,只在应用层级提供查询,类似于:
图来自于 orbit 产品。
OpenTelemetry
当然讲到日志目前自然也逃不过 OpenTelemetry,作为当前云原生可观测性的标准也提供了对应的日志组件。
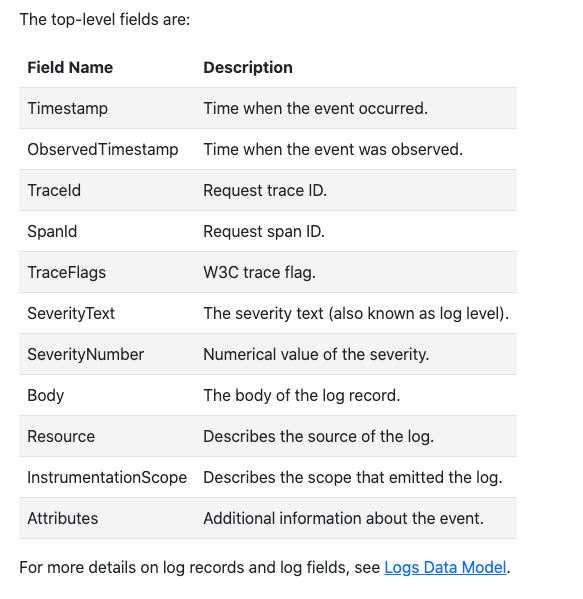
OpenTelemetry 也定义了结构化的日志格式:
{"resourceLogs":[{"resource":{"attributes":[{"key":"resource-attr","value":{"stringValue":"resource-attr-val-1"}}]},"scopeLogs":[{"scope":{},"logRecords":[{"timeUnixNano":"1581452773000000789","severityNumber":9,"severityText":"Info""body":{"stringValue":"This is a log message"},"attributes":[{"key":"app","value":{"stringValue":"server"}},{"key":"instance_num","value":{"intValue":"1"}}],"droppedAttributesCount":1,"traceId":"08040201000000000000000000000000","spanId":"0102040800000000"},{"timeUnixNano":"1581452773000000789","severityNumber":9,"severityText":"Info","body":{"stringValue":"something happened"},"attributes":[{"key":"customer","value":{"stringValue":"acme"}},{"key":"env","value":{"stringValue":"dev"}}],"droppedAttributesCount":1,"traceId":"","spanId":""}]}]}]}
我们可以配置 otel.logs.exporter=otlp (default) 可以将日志输出到 oetl-collector 中,再由他输出到后端存储中。
虽然这样 otel-collectoer 就成为瓶颈了,但我们也可以部署多个副本来降低压力。
同时也可以在应用中指定不同的 endpoint(otel.exporter.otlp.endpoint=http://127.0.0.1:4317) 来区分日志的 collector,与其他类型的 collector 做到资源隔离。
不过目前社区关于日志的实践还比较少,而且由于版本 1.0 版本 release 的时间也不算长,稳定性和之前的 filebeat 相比还得需要时间检验。
总结
理想情况下,我们需要将可观测性的三个重要组件都关联起来才能更好的排查定位问题。
比如当收到监控系统通过指标变化发出的报警时,可以通过链路追踪定位具体是哪个系统触发的问题。
之后通过 traceID 定位到具体的日志,再通过日志的上下文列出更多日志信息,这样整个链条就可以串联起来,可以极大的提高效率。
参考链接:
- https://github.com/aliyun/aliyun-log-java-producer
- https://kubernetes.io/docs/concepts/cluster-administration/logging/
- https://coding.net/help/docs/orbit/env/logs-event/intro.html
- https://opentelemetry.io/docs/concepts/signals/logs/
日志架构演进:从集中式到分布式的Kubernetes日志策略的更多相关文章
- 集中式vs分布式区别
记录一下我了解到的版本控制系统,集中式与分布式,它们之间的区别做下个人总结. 什么是集中式? 集中式开发:是将项目集中存放在中央服务器中,在工作的时候,大家只在自己电脑上操作,从同一个地方下载最新版本 ...
- 集中式vs分布式
Linus一直痛恨的CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢? 先说集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候 ...
- Git_集中式vs分布式
创建版本库 时光机穿梭 版本回退 工作区和暂存区 管理修改 撤销修改 删除文件 远程仓库 添加远程库 从远程库克隆 分支管理 创建与合并分支 解决冲突 分支管理策略 Bug分支 Feature分支 多 ...
- Git复习(一)之简介、安装、集中式和分布式
简介 Git是分布式版本控制系统,使用C语言开发的,CVS.SVN是集中式的版本控制系统,集中式的版本控制系统不但速度慢,而且必须联网才能使用. Git是分布式版本控制系统,同一个Git仓库,可以 分 ...
- 版本控制:集中式 vs 分布式
集中式 CVCS的版本库集中存放在中央服务器,而工作时都是用自己的电脑,所以要先从中央服务器取得最新的版本,然后工作完后再将自己的代码推送给中央服务器. CVS:最早的.开源.免费.由于自身设计的问题 ...
- 详细透彻解读Git与SVN的区别(集中式VS分布式)
Git是目前世界上最先进的分布式版本控制系统,其实 Git 跟 SVN一样有自己的集中式版本库或服务器,但是Git 更倾向于被使用于分布式模式,也就是每个开发人员从中心版本库/服务器上chect ou ...
- 中小型研发团队架构实践七:集中式日志ELK
一.集中式日志 日志可分为系统日志.应用日志以及业务日志,系统日志给运维人员使用,应用日志给研发人员使用,业务日志给业务操作人员使用.我们这里主要讲解应用日志,通过应用日志来了解应用的信息和状态,以及 ...
- iOS开发——源代码管理——git(分布式版本控制和集中式版本控制对比,git和SVN对比,git常用指令,搭建GitHub远程仓库,搭建oschina远程仓库 )
一.git简介 什么是git? git是一款开源的分布式版本控制工具 在世界上所有的分布式版本控制工具中,git是最快.最简单.最流行的 git的起源 作者是Linux之父:Linus Bened ...
- 集中式版本控制VS分布式版本控制
CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢? 集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所 ...
- Git学习系列之集中式版本控制系统vs分布式版本控制系统
不多说,直接上干货! Linus一直痛恨的CVS及SVN都是集中式的版本控制系统,而Git是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢? 先说集中式版本控制系统,版本库是集中存放在中央 ...
随机推荐
- .npmrc 项目的 默认安装配置
.npmrc registry=http://192.168.77.105:8081/nexus/content/groups/npm-all/
- dev-sidecar 让github 可以正常访问
dev-sidecar https://gitee.com/docmirror/dev-sidecar/releases
- 解决Windows下json.hpp中文乱码问题
文中使用的是 json 库,整个库的代码由一个单独的头文件json.hpp组成,用普通的C++11编写的.它没有库,没有子项目,没有依赖关系,没有复杂的构建系统,使用起来很方便. 先引用头文件和命名空 ...
- arch安装xfce4的时候,出现无法设置开机启动的问题
sudo systemctl enable lightdm Failed to enable unit: File /etc/systemd/system/display-manager.serv ...
- Android使用poi遇到的问题
原文:Android使用poi遇到的问题 关于Poi使用可以看这一篇[开源库推荐]#4 Poi-办公文档处理库 本篇主要讲些在Android上使用出现的问题 问题 原本是需要一个导出xlsx表格文件的 ...
- C++类的访问权限
首先明确一个类的用户有三种: 一类用户:类的成员和友元 二类用户:子类的成员及子类的友元 三类用户:外部的用户代码(通过类的对象或指针) 一个类有三种成员 private:只有一类用户可以访问priv ...
- WPF线程模型
1. 渲染系统概述 WPF 采用保留模式渲染系统 (Retained Mode Rendering System),该系统可分为 UI 线程和复合线程两个主要部分,两者协作完成 WPF 应用程序的渲染 ...
- StableSwarmUI:功能强大且易于使用的Stable Diffusion WebUI
StableSwarmUI是一个模块化和可定制的Stable Diffusion WebUI,最近发布了0.6.1-Beta版本.这个开源项目,托管在GitHub上:https://github.co ...
- 记录--vue.config.js 的完整配置(超详细)!
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前段时间,对部门的个别项目进行Vue3.0+ts框架的迁移,刚开始研究的时候也是踩坑特别多,尤其我们的项目还有些特殊的webpack配置, ...
- KingbaseES数据库安装PostGIS扩展GEOSUnaryunionPrec错误
一.问题现象: KingbaseES V008R006C007B0012数据库集群安装PostGIS扩展插件报错. create extension postgis; ERROR: could not ...