Python新手爬虫二:爬取搜狗图片(动态)
经过上一期爬取豆瓣影评成功后,感觉爬虫还不错,于是想爬点图片来玩玩...
搜狗图片地址:https://pic.sogou.com/?from=category
先上最后成功的源码(在D盘下创建souGouImg文件夹,直接直接代码即可获取):
import requests
import urllib
import json
from fake_useragent import UserAgent def getSougouImag(category,length,path):
n = length
cate = category
imgs_url = [] #定义空列表,用于保存图片url
m = 0 #用于显示图片数量
url = 'https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category='+cate+'&tag=%E5%85%A8%E9%83%A8&start=0&len='+str(n)
headers = {'user-agent':UserAgent().random} #设置UA
f = requests.get(url,headers=headers) #发送Get请求
print(f.status_code)
js = json.loads(f.text)
js = js['all_items']
for j in js:
imgs_url.append(j['thumbUrl'])
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg') #下载指定url到本地
m += 1
print('Download complete!') getSougouImag('壁纸',500,r'D:\souGouImg/')
效果图:
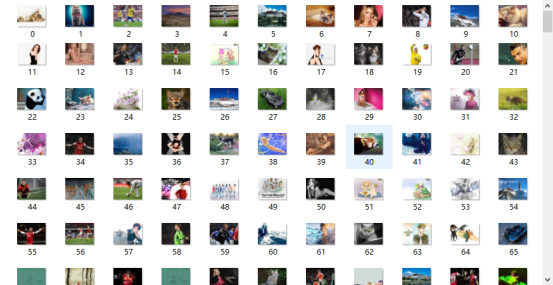
下面开始介绍作为一个新手的爬虫步骤...
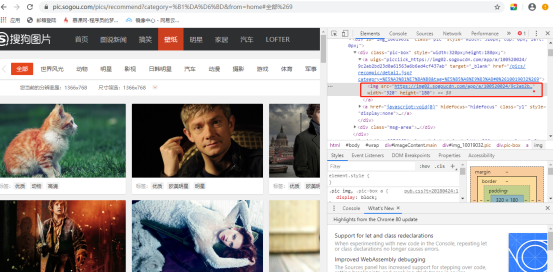
1、首先打开网页查看HTML源码
先按F12打开调试界面—>右击图片—>点击检查
会出现如下图红框中的信息,不难看出,此图片的url就是img标签中src属性的值。
如此简单?那直接获取src属性的值,再进行下载不就完全ok了?
话不多说,开干。
from bs4 import BeautifulSoup
import requests
from fake_useragent import UserAgent #ua库 url = 'https://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD&from=home#%E5%85%A8%E9%83%A8%269'
headers = {'user-agent':UserAgent().random} #设置UA
f = requests.get(url,headers=headers) #发送Get请求
print(f.status_code) #打印状态码
soup = BeautifulSoup(f.text,'lxml') #用lxml解析器解析该网页的内容
print(soup.select('img')) #筛选出所有img的标签,并打印其属性和内容
代码执行结果如下:
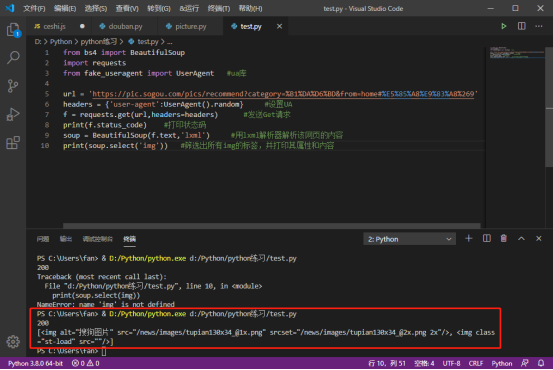
发现打印出的html并不是与网页中的一致,所有考虑,这根本不是图片的源url,于是推测图片是动态的,继续查找... 也是百度到了某个大佬的文章,才挖掘出以下搜寻方法。
2、点击NetWork—>点击XHR—>然后往下滚轮,使它加载出新的图片—>点击新加载出来的图片—>再点击右侧的Preview

发现Preview下的内容为json格式的
发现all_items,点击它发现有0.....众多数字,再点开发现有许多url,粘贴到浏览器中查看,发现这些都是图片的url(心中狂喜)
找到图片的真实URL,问题也就变得简单了。详情还是请看代码注释吧~
Python新手爬虫二:爬取搜狗图片(动态)的更多相关文章
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 【python爬虫】爬取美女图片
一,导入包文件 os:用于文件操作.这里是为了创建保存图片的目录 re:正则表达式模块.代码中包含了数据处理,因此需要导入该模块 request:请求模块.通过该模块向对方服务器发送请求获取数据包 l ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- 九 web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j ...
- Python学习 —— 爬虫入门 - 爬取Pixiv每日排行中的图片
更新于 2019-01-30 16:30:55 我另外写了一个面向 pixiv 的库:pixiver 支持通过作品 ID 获取相关信息.下载等,支持通过日期浏览各种排行榜(包括R-18),支持通过 p ...
- python爬虫之爬取百度图片
##author:wuhao##爬取指定页码的图片,如果需要爬取某一类的所有图片,整体框架不变,但需要另作分析#import urllib.requestimport urllib.parseimpo ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
随机推荐
- .Net Core WebApi 使用 JWT 验证身份
.h2 { background-color: rgba(78, 110, 242, 1); color: rgba(255, 255, 255, 1); padding: 10px } 一.注册身份 ...
- [oeasy]教您玩转python - 0005- 勇闯地下城
继续运行 回忆上次内容 上次从1行代码进化到了2行代码 yy p粘贴剪贴板中的内容 将剪贴板中的代码粘贴9999次 9999p 真的实现了万行代码梦 是真·圆梦 没有撒谎的那种 不过圆梦之后多少 ...
- 新项目加入mybatisplus,我给自己挖了个坑 org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)
org.apache.ibatis.binding.BindingException: Invalid bound statement (not found) 上述问题的解决办法:1首先看看@mapp ...
- ClickHouse的向量处理能力
ClickHouse的向量处理能力 引言 在过去,非结构化数据(如文本.图片.音频.视频)通常被认为难以在数据库中直接使用,因为这些数据类型的多样性和复杂性.然而,随着技术的发展,嵌入技术可以将非结构 ...
- LangChain的LCEL和Runnable你搞懂了吗
LangChain的LCEL估计行业内的朋友都听过,但是LCEL里的RunnablePassthrough.RunnableParallel.RunnableBranch.RunnableLambda ...
- 【C3】05 层叠与继承
本文旨在让你理解CSS的一些最基本的概念 --层叠.优先级和继承-- 这些概念决定着如何将CSS应用到HTML中,以及如何解决冲突. 尽管与课程的其他部分相比,完成这节课可能看起来没有那么直接的相关性 ...
- blender建模渲染Tips
blender渲染 灯光的三种方式 1,常规灯光:shift+A选择灯光. 2,世界环境光:右侧地球图标调整. 3,物体自发光:把渲染物体变成一个发光体来进行调节灯光. 渲染视窗的调节 ctrl+b裁 ...
- 【转载】 5:0!AI战胜人类教官,AlphaDogfight大赛落幕
原文:https://baijiahao.baidu.com/s?id=1675621109599102721&wfr=spider&for=pc ------------------ ...
- (续) gym atari游戏的环境设置问题:Breakout-v0, Breakout-v4, BreakoutNoFrameskip-v4和BreakoutDeterministic-v4的区别
根据前文(https://www.cnblogs.com/devilmaycry812839668/p/14665072.html)我们知道: 首先是v0和v4的区别:带有v0的env表示会有25%的 ...
- 【转转】 Huber Loss
原文地址: https://www.cnblogs.com/nowgood/p/Huber-Loss.html ============================================ ...