LaViT:这也行,微软提出直接用上一层的注意力权重生成当前层的注意力权重 | CVPR 2024
Less-Attention Vision Transformer利用了在多头自注意力(MHSA)块中计算的依赖关系,通过重复使用先前MSA块的注意力来绕过注意力计算,还额外增加了一个简单的保持对角性的损失函数,旨在促进注意力矩阵在表示标记之间关系方面的预期行为。该架构你能有效地捕捉了跨标记的关联,超越了基线的性能,同时在参数数量和每秒浮点运算操作(FLOPs)方面保持了计算效率。来源:晓飞的算法工程笔记 公众号
论文: You Only Need Less Attention at Each Stage in Vision Transformers

Introduction
近年来,计算机视觉经历了快速的增长和发展,主要得益于深度学习的进步以及大规模数据集的可获得性。在杰出的深度学习技术中,卷积神经网络(Convolutional Neural Networks, CNNs)被证明特别有效,在包括图像分类、目标检测和语义分割等广泛应用中展现了卓越的性能。
受到Transformer在自然语言处理领域巨大成功的启发,ViT(Vision Transformers)将每幅图像划分为一组标记。这些标记随后被编码以生成一个注意力矩阵,作为自注意力机制的基础组成部分。自注意力机制的计算复杂度随着标记数量的增加而呈平方增长,且随着图像分辨率的提高,计算负担变得更加沉重。一些研究人员尝试通过动态选择或标记修剪来减少标记冗余,以减轻注意力计算的计算负担。这些方法在性能上已证明与标准ViT相当。然而,涉及标记减少和修剪的方法需要对标记选择模块进行细致设计,可能导致关键标记的意外丢失。在本研究中,作者探索了不同的方向,并重新思考自注意力的机制。发现在注意力饱和问题中,随着ViTs层数的逐渐加深,注意力矩阵往往保持大部分不变,重复前面层中观察到的权重分配。考虑到这些因素,作者提出以下问题:
在网络的每个阶段,从开始到结束,是否真的有必要始终一致地应用自注意力机制?
在本文中,作者提出通过引入少注意力ViT(Less-Attention Vision Transformer)来修改标准ViT的基本架构。框架由原始注意力(Vanilla Attention, VA)层和少注意力(Less Attention, LA)层组成,以捕捉长范围的关系。在每个阶段,专门计算传统的自注意力,并将注意力分数存储在几个初始的原始注意力(VA)层中。在后续的层中,通过利用先前计算的注意力矩阵高效地生成注意力分数,从而减轻与自注意力机制相关的平方计算开销。此外,在跨阶段的降采样过程中,在注意力层内集成了残差连接,允许保留在早期阶段学习到的重要语义信息,同时通过替代路径传输全局上下文信息。最后,作者仔细设计了一种新颖的损失函数,从而在变换过程中保持注意力矩阵的对角性。这些关键组件使作者提出的ViT模型能够减少计算复杂性和注意力饱和,从而实现显著的性能提升,同时降低每秒浮点运算次数(FLOPs)和显著的吞吐量。
为验证作者提出的方法的有效性,在各种基准数据集上进行了全面的实验,将模型的性能与现有最先进的ViT变种(以及最近的高效ViT)进行了比较。实验结果表明,作者的方法在解决注意力饱和并在视觉识别任务中取得优越性能方面非常有效。
论文的主要贡献总结如下:
提出了一种新颖的
ViT架构,通过重新参数化前面层计算的注意力矩阵生成注意力分数,这种方法同时解决了注意力饱和和相关的计算负担。此外,提出了一种新颖的损失函数,旨在在注意力重新参数化的过程中保持注意力矩阵的对角性。作者认为这一点对维护注意力的语义完整性至关重要,确保注意力矩阵准确反映输入标记之间的相对重要性。
论文的架构在包括分类、检测和分割在内的多个视觉任务中,始终表现优异,同时在计算复杂度和内存消耗方面具有类似甚至更低的特点,胜过几种最先进的
ViTs。
Methodology
Vision Transformer
令 \(\mathbf{x} \in \mathbb{R}^{H \times W \times C}\) 表示一个输入图像,其中 \(H \times W\) 表示空间分辨率, \(C\) 表示通道数。首先通过将图像划分为 $N = \frac{HW}{p^{2}} $ 个块来对图像进行分块,其中每个块 \(P_i \in \mathbb{R}^{p \times p \times C}\left(i \in \{1, \ldots, N\} \right)\) 的大小为 \(p \times p\) 像素和 \(C\) 通道。块大小 \(p\) 是一个超参数,用于确定标记的粒度。块嵌入可以通过使用步幅和卷积核大小均等于块大小的卷积操作提取。然后,每个块通过不重叠的卷积投影到嵌入空间 \(\boldsymbol{Z} \in \mathbb{R}^{N\times{D}}\) ,其中 \(D\) 表示每个块的维度。
Multi-Head Self-Attention
首先提供一个关于处理块嵌入的经典自注意力机制的简要概述,该机制在多头自注意力块(MHSAs)的框架内工作。在第 \(l\) 个MHSA块中,输入 \(\boldsymbol{Z}_{l-1}, l \in \{1,\cdots, L\}\) 被投影为三个可学习的嵌入 \(\{\mathbf{Q,K,V}\} \in \mathbb{R}^{N \times D}\) 。多头注意力旨在从不同的视角捕捉注意力;为简单起见,选择 \(H\) 个头,每个头都是一个维度为 \(N \times \frac{D}{H}\) 的矩阵。第 \(h\) 个头的注意力矩阵 \(\mathbf{A}_h\) 可以通过以下方式计算:
\mathbf{A}_h =
\mathrm{Softmax} \left(\frac{\mathbf{Q}_h \mathbf{K}_h^\mathsf{T}}{\sqrt{d}} \right) \in \mathbb{R}^{N \times N}.
\label{eq:attn}
\end{align}
\]
\(\mathbf{A}_h, \mathbf{Q}_h\) 和 \(\mathbf{K}_h\) 分别是第 \(h\) 个头的注意力矩阵、查询和键。还将值 \(\mathbf{V}\) 分割成 \(H\) 个头。为了避免由于概率分布的锐性导致的梯度消失,将 \(\mathbf{Q}_h\) 和 \(\mathbf{K}_h\) 的内积除以 \(\sqrt{d}\) ( \(d = D/H\) )。注意力矩阵被拼接为:
\begin{split}
\mathbf{A} &= \textrm{Concat}(\mathbf{A}_1, \cdots, \mathbf{A}_h, \cdots,\mathbf{A}_H); \\
\mathbf{V} &= \textrm{Concat}(\mathbf{V}_1, \cdots, \mathbf{V}_h, \cdots,\mathbf{V}_H).
\end{split}
\label{eq:concat}
\end{equation}
\]
在空间分割的标记之间计算的注意力,可能会引导模型关注视觉数据中最有价值的标记。随后,将加权线性聚合应用于相应的值 \(\mathbf{V}\) :
\boldsymbol{Z}^{\textrm{MHSA}} = \mathbf{AV} \in \mathbb{R}^{N \times D}.
\label{eq:val-feats}
\end{align}
\]
Downsampling Operation
受到CNN中层次架构成功的启发,一些研究将层次结构引入到ViTs中。这些工作将Transformer块划分为 \(M\) 个阶段,并在每个Transformer阶段之前应用下采样操作,从而减少序列长度。在论文的研究中,作者采用了一个卷积层进行下采样操作,卷积核的大小和步幅都设置为 \(2\) 。该方法允许在每个阶段灵活调整特征图的尺度,从而建立一个与人类视觉系统的组织相一致的Transformer层次结构。
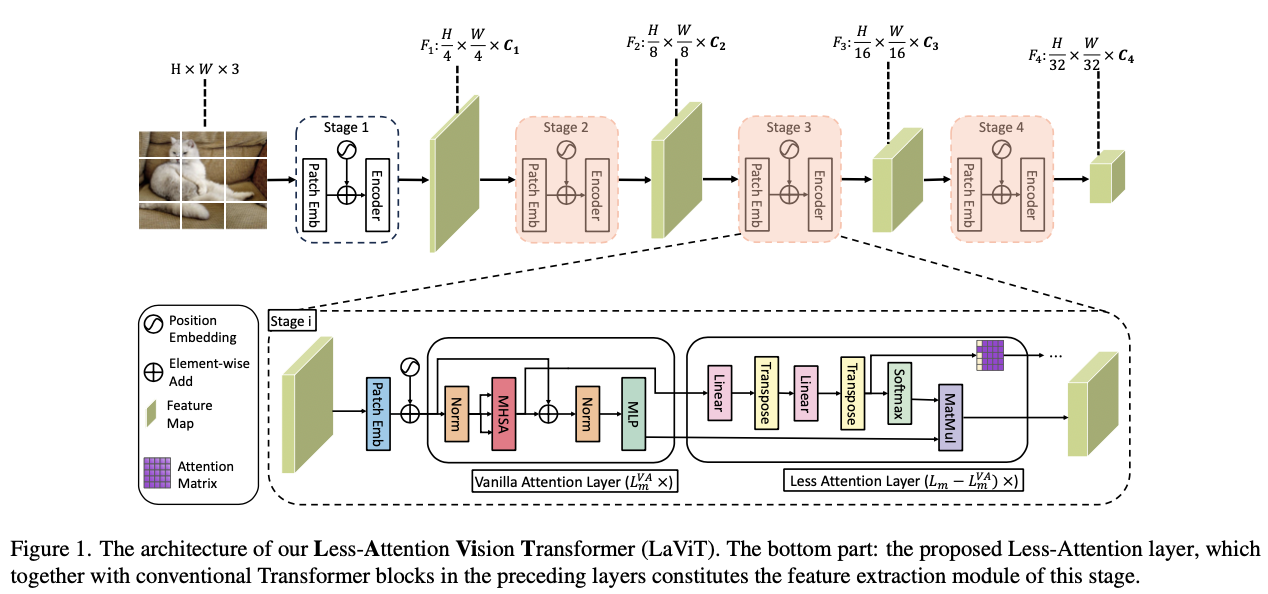
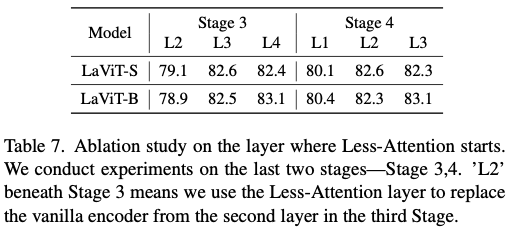
The Less-Attention Framework
整体框架如图1所示。在每个阶段,分两步提取特征表示。在最初的几个Vanilla Attention(VA) 层中,进行标准的多头自注意力(MHSA)操作,以捕捉整体的长距离依赖关系。随后,通过对存储的注意力分数应用线性变换,模拟注意力矩阵,以减少平方计算并解决接下来的低注意力(LA)层中的注意力饱和问题。在这里,将第 \(m\) 个阶段的初始 \(l\) -th VA 层的 \(\textrm{Softmax}\) 函数之前的注意力分数表示为 \(\mathbf{A}^{\text{VA},l}_m\) ,它是通过以下标准程序计算的:
\mathbf{A}^{\text{VA},l}_m = \frac{\mathbf{Q}^l_m(\mathbf{K}^l_m)^\mathsf{T}}{\sqrt{d}}, ~~ l \leq L^{\text{VA}}_m.
\label{eq:init}
\end{equation}
\]
这里, \(\mathbf{Q}_m^l\) 和 \(\mathbf{K}_m^l\) 分别表示来自第 \(m\) 个阶段第 \(l\) 层的查询和键,遵循来自前一阶段的下采样。而 \(L^{\text{VA}}_m\) 用于表示VA层的数量。在最初的原始注意力阶段之后,丢弃传统的平方MHSA,并对 \(\mathbf{A}^\textrm{VA}_m\) 应用变换,以减少注意力计算的数量。这个过程包括进行两次线性变换,中间夹一个矩阵转置操作。为了说明,对于该阶段的第 \(l\) 层( \(l > L^{\text{VA}}_m\) ,即LA层)的注意力矩阵:
\begin{aligned}
&\mathbf{A}^{l}_m = \Psi(\Theta(\mathbf{A}^{l-1}_m)^\mathsf{T})^\mathsf{T}, ~~ L^{\text{VA}}_m<l \leq L_m,\\
&\mathbf{Z}^{\text{LA},l} = \textrm{Softmax}(\mathbf{A}^l_m)\mathbf{V}^l.
\end{aligned}
\end{equation}
\]
在这个上下文中, \(\Psi\) 和 \(\Theta\) 表示维度为 \(\mathbb{R}^{N\times{N}}\) 的线性变换层。这里, \(L_m\) 和 \(L_m^{\text{VA}}\) 分别表示第 \(m\) 个阶段的层数和VA层的数量。在这两个线性层之间插入转置操作的目的是保持矩阵的相似性行为。这个步骤是必需的,因为单层中的线性变换是逐行进行的,这可能导致对角特性丧失。
Residual-based Attention Downsampling
当计算在分层ViT(ViTs)中跨阶段进行时,通常会对特征图进行下采样操作。虽然该技术减少了标记数量,但可能会导致重要上下文信息的丧失。因此,论文认为来自前一阶段学习的注意力亲和度对于当前阶段在捕捉更复杂的全局关系方面可能是有利的。受到ResNet的启发,后者引入了快捷连接以减轻特征饱和问题,作者在架构的下采样注意力计算中采用了类似的概念。通过引入一个短路连接,可以将固有的偏差引入当前的多头自注意力(MHSA)块。这使得前一阶段的注意力矩阵能够有效引导当前阶段的注意力计算,从而保留重要的上下文信息。
然而,直接将短路连接应用于注意力矩阵可能在这种情况下面临挑战,主要是由于当前阶段和前一阶段之间注意力维度的不同。为此,作者设计了一个注意力残差(AR)模块,该模块由深度卷积(DWConv)和一个 \(\textrm{Conv}_{1\times1}\) 层构成,用以在保持语义信息的同时对前一阶段的注意力图进行下采样。将前一阶段(第 \(m-1\) 阶段)的最后一个注意力矩阵(在 \(L_{m-1}\) 层)表示为 \(\textbf{A}_{m-1}^{\text{last}}\) ,将当前阶段(第 \(m\) 阶段)的下采样初始注意力矩阵表示为 \(\textbf{A}_m^\text{init}\) 。 \(\textbf{A}_{m-1}^{\text{last}}\) 的维度为 \(\mathbb{R}^{B\times{H}\times{N_{m-1}}\times{N_{m-1}}}\) ( \(N_{m-1}\) 表示第 \(m-1\) 阶段的标记数量)。将多头维度 \(H\) 视为常规图像空间中的通道维度,因此通过 \(\textrm{DWConv}\) 操作符( \(\textrm{stride}=2,\ \textrm{kernel size}=2\) ),可以在注意力下采样过程中捕获标记之间的空间依赖关系。经过 \(\textrm{DWConv}\) 变换后的输出矩阵适合当前阶段的注意力矩阵的尺寸,即 \(\mathbb{R}^{B\times{H}\times{N_m}\times{N_m}} (N_m = \frac{N_{m-1}}{2})\) 。在对注意力矩阵进行深度卷积后,再执行 \(\text{Conv}_{1\times1}\) ,以便在不同头之间交换信息。
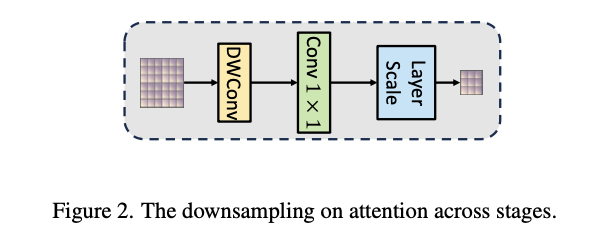
论文的注意力下采样过程如图2所示,从 \(\textbf{A}_{m-1}^\text{last}\) 到 \(\textbf{A}_{m}^\text{init}\) 的变换可以表示为:
\textbf{A}^\textrm{init}_m &= \textrm{Conv}_{1\times1}\left(\textrm{Norm}(\textrm{DWConv}(\textbf{A}^\textrm{last}_{m-1}))\right), \label{eq:residual}
\\
\mathbf{A}^{\text{VA}}_m &\gets \mathbf{A}^{\text{VA}}_m + \textrm{LS}(\textbf{A}^\textrm{init}_m) \label{eq:plus},
\end{align}
\]
其中 \(\textrm{LS}\) 是在CaiT中引入的层缩放操作符,用以缓解注意力饱和现象。 \(\mathbf{A}^{\text{VA}}_m\) 是第 \(m\) 阶段第一层的注意力得分,它是通过将标准多头自注意力(MHSA)与公式4和由公式6计算的残差相加得出的。
论文的注意力下采样模块受两个基本设计原则的指导。首先,利用 \(\text{DWConv}\) 在下采样过程中捕获空间局部关系,从而实现对注意力关系的高效压缩。其次,采用 \(\textrm{Conv}_{1\times1}\) 操作在不同头之间交换注意力信息。这一设计至关重要,因为它促进了注意力从前一阶段有效传播到后续阶段。引入残差注意力机制只需进行少量调整,通常只需在现有的ViT主干中添加几行代码。值得强调的是,这项技术可以无缝应用于各种版本的Transformer架构。唯一的前提是存储来自上一层的注意力得分,并相应地建立到该层的跳跃连接。通过综合的消融研究,该模块的重要性将得到进一步阐明。
Diagonality Preserving Loss
作者通过融入注意力变换算子,精心设计了Transformer模块,旨在减轻计算成本和注意力饱和的问题。然而,仍然存在一个紧迫的挑战——确保变换后的注意力保留跨Token之间的关系。众所周知,对注意力矩阵应用变换可能会妨碍其捕捉相似性的能力,这在很大程度上是因为线性变换以行的方式处理注意力矩阵。因此,作者设计了一种替代方法,以确保变换后的注意力矩阵保留传达Token之间关联所需的基本属性。一个常规的注意力矩阵应该具备以下两个属性,即对角性和对称性:
\begin{aligned}[b]
\mathbf{A}_{ij} &= \mathbf{A}_{ji}, \\
\mathbf{A}_{ii} &> \mathbf{A}_{ij}, \forall j \neq i.
\end{aligned}
\label{eq:property}
\end{equation}
\]
因此,设计了第 \(l\) 层的对角性保持损失,以保持这两个基本属性如下所示:
\begin{split}
{\mathcal{L}_{\textrm{DP},l}} &= \sum_{i=1}^N\sum_{j=1}^N\left|\mathbf{A}_{ij} -\mathbf{A}_{ji}\right| \\
&+ \sum_{i=1}^N((N-1)\mathbf{A}_{ii}-\sum_{j\neq i}\mathbf{A}_{j}).
\end{split}
\end{equation}
\]
在这里, \(\mathcal{L}_\textrm{DP}\) 是对角性保持损失,旨在维护公式8中注意力矩阵的属性。在所有变换层上将对角性保持损失与普通的交叉熵 (CE) 损失相结合,因此训练中的总损失可以表示为:
\begin{aligned}[b]
\mathcal{L}_\textrm{total} &= \mathcal{L}_\textrm{CE} + \sum_{m=1}^M\sum_{l=1}^{L_m}\mathcal{L}_{\textrm{DP},l}, \\
\mathcal{L}_\textrm{CE} &= \textrm{cross-entropy}(Z_\texttt{Cls}, y),
\end{aligned}
\end{equation}
\]
其中, \(Z_\texttt{Cls}\) 是最后一层表示中的分类标记。
Complexity Analysis
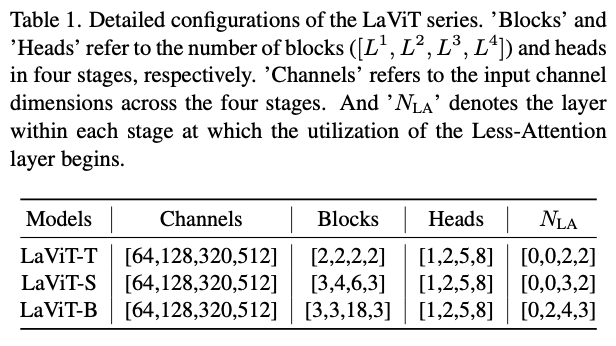
论文的架构由四个阶段组成,每个阶段包含 \(L_m\) 层。下采样层应用于每个连续阶段之间。因此,传统自注意力的计算复杂度为 \(\mathcal{O}(N_m^2{D})\) ,而相关的K-Q-V转换则带来了 \(\mathcal{O}(3N_mD^2)\) 的复杂度。相比之下,论文的方法在变换层内利用了 \(N_m\times N_m\) 的线性变换,从而避免了计算内积的需要。因此,变换层中注意力机制的计算复杂度降至 \(\mathcal{O}(N_m^2)\) ,实现了 \(D\) 的减少因子。此外,由于论文的方法在 Less-Attention中只计算查询嵌入,因此K-Q-V转换复杂度也减少了3倍。
在连续阶段之间的下采样层中,以下采样率2为例,注意力下采样层中DWConv的计算复杂度可以计算为 \(\textrm{Complexity} = 2 \times 2 \times \frac{N_m}{2} \times \frac{N_m}{2} \times D = \mathcal{O}(N_m^2D)\) 。同样,注意力残差模块中 \(\textrm{Conv}_{1\times1}\) 操作的复杂度也是 \(\mathcal{O}(N_m^2D)\) 。然而,重要的是,注意力下采样在每个阶段仅发生一次。因此,对比Less-Attention方法所实现的复杂度减少,这些操作引入的额外复杂度可以忽略不计。
Experiments
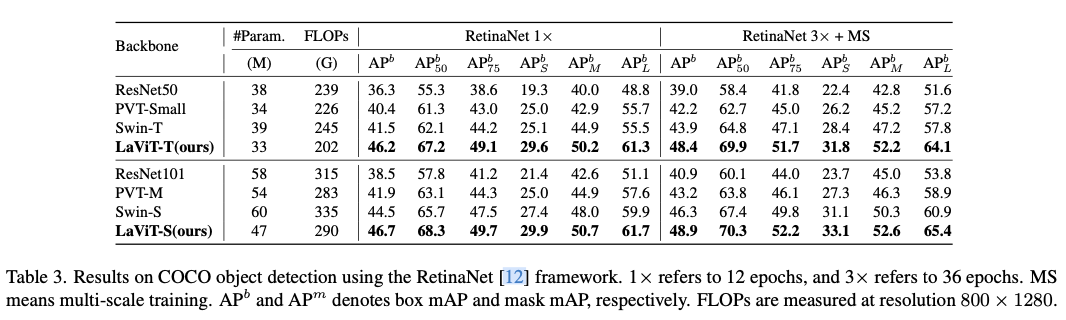
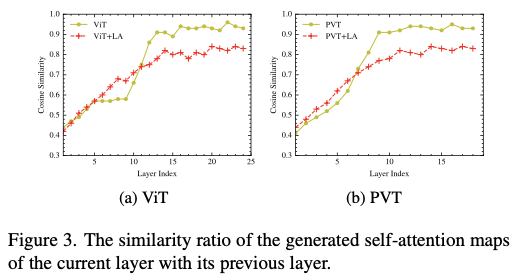
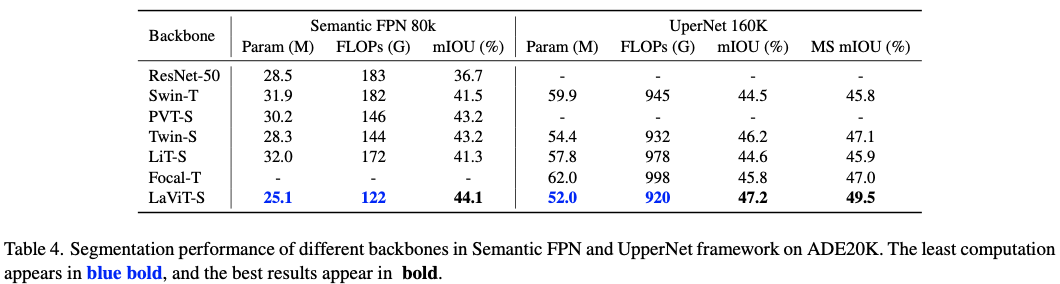
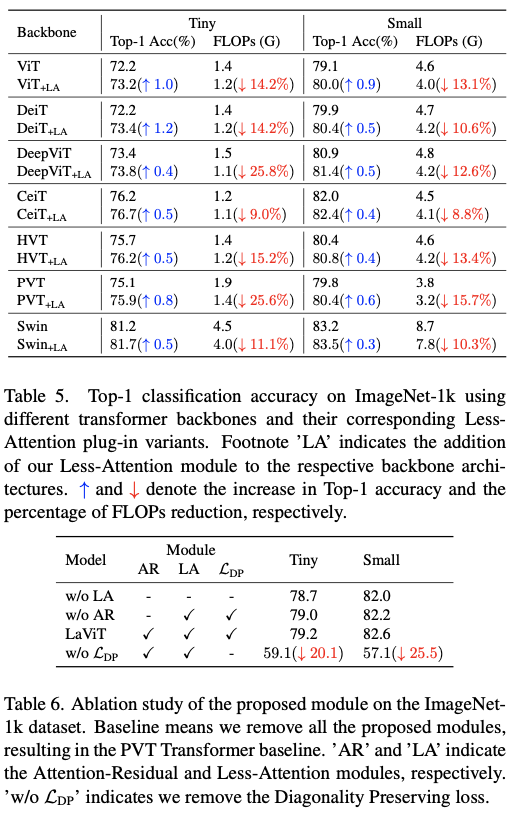
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

LaViT:这也行,微软提出直接用上一层的注意力权重生成当前层的注意力权重 | CVPR 2024的更多相关文章
- 微软官方网站线上兼容测试平台-Browser screenshots
前端开发时最不想做的就是在不同浏览器.平台和分辨率测试网页显示效果,通常这会浮现许多问题,尤其浏览器版本就可能让显示成效完全不同,也只好尽力维持让每一种设备都能正常浏览网页.修改到完全没有问题必须投入 ...
- 在开发中进入一个方法后想要到原来那行 ctrl+alt+左 回到上一步 ctrl+alt+右 回到下一步
在开发中进入一个方法后想要到原来那行 ctrl+alt+左 回到上一步ctrl+alt+右 回到下一步
- 从图像中检测和识别表格,北航&微软提出新型数据集 TableBank
纯学术 的识别表格的文章: http://hrb-br.com/5007404/20190321A0B99Y00.html https://github.com/doc-analysis/TableB ...
- 不写1行代码,在Mac上体验ASP.NET 5的最简单方法
昨天微软发布了ASP.NET 5 beta2(详见ASP.NET 5 Beta2 发布),对ASP.NET 5的好奇心又被激发了. 今天下午在Mac OS X上体验了一下ASP.NET 5,而且借助Y ...
- TFS服务器(微软源代码管理服务器)上彻底删除项目
在TFS服务器上建立了很多项目,发现在Team Explorer中,只能移除团队项目,这种移除,只是将项目从当前Team Explorer项目列表中删除,下一次Connect到TFS服务器时,或者刷新 ...
- 记一次使用命令行启动部署在tomcat上的应用
在Eclipes进行程序开发完成后,一般都会直接在Eclipse部署启动,其中的一些启动参数设置都会在其中进行,若用命令行启动,则需要手动配置. 程序开发完成后打成的war包,需要部署到Tomcat应 ...
- inux xsel 拷贝复制命令行输出放在系统剪贴板上
转载自:http://oldratlee.com/post/2012-12-23/command-output-to-clip 为什么要这么做?直接把命令的输出(比如 grep/awk/sed/fin ...
- 微软宣布在Azure上支持更多的开放技术和选择
微软和我都热爱Linux,并且就在情人节过去几天之后,我非常高兴能用几个激动人心的消息来表达这种对Linux的热爱,您将会看到在Azure上的云部署将具有更加开放的选择性和灵活性. 这些激动人心的消息 ...
- 在linux命令行中调试在OJ上的c++代码
gcc & g++现在是gnu中最主要和最流行的c & c++编译器 .g++是c++的命令,以.cpp为主,对于c语言后缀名一般为.c.这时候命令换做gcc即可. 编译器是根据gcc ...
- 帝都之行5day:还是工作上的事
前两天开始面试找工作,周一整好简历,学历不行也没办法,但还是如实写了,自己看了一下,觉得还凑合,毕竟还是有几年经验的,就开始投了 选了十来个智联推荐的企业,然后把简历设为公开,开始等消息吧…… 投递成 ...
随机推荐
- 你真的了解Java内存模型JMM吗?
哈喽,大家好,我是世杰. 本文我为大家介绍面试官经常考察的「Java内存模型JMM相关内容」 面试连环call 什么是Java内存模型(JMM)? 为什么需要JMM? Java线程的工作内存和主内存各 ...
- Tiny RDM 刚上线就收获一众好评的Redis桌面开源客户端!值得拥有!
相信对Redis有频繁操作需求的用户,大部分会选择一个顺手的图形化界面工具来代替手动命令行操作以提高效率.Tiny RDM作为一款现代化轻量级的跨平台Redis桌面客户端,为用户提供了便捷高效的Red ...
- thinkphp5 关于跨域的一些坑
1.首先在tp5的入口文件:public/index.php 在里面添加三行: // [ 应用入口文件 ] header("Access-Control-Allow-Origin:*&quo ...
- [oeasy]python0050_动态类型_静态类型_编译_运行
动态类型_静态类型 回忆上次内容 上次了解了 帮助文档的 生成 开头的三引号注释 可以生成 帮助文档 文档 可以写成网页 python3 本身 也有 在线的帮助手册 目前的程序 提高了 可读性 ...
- [oeasy]python0016_编码_encode_编号_字节_计算机
编码(encode) 回忆上次内容 上次找到了字符和字节状态之间的映射对应关系 字符对应着二进制字节 二进制字节也对应着字符 这种字节状态是用2位16进制数来表示的 hex(n)可以把数字转化为 ...
- 《Operating Systems: Three Easy Pieces》阅读记录
OSTEP virtualization 进程 process 进程 API 进程 API 相关术语 进程状态 statu 机制:受限直接执行 进程调度:介绍 调度:多级反馈队列 MLFQ 调度:比例 ...
- [UE源码] 关于使用UE待改进的一些尝试
UE从自己做了一款游戏后,发现了蓝图以及UE引擎本身的一些优缺点: 1.蓝图在一些简单的逻辑上书写方便,直观,而且编译速度快,但是也有一些其他问题: 结构体赋值后,无法二次修改 只有3种容器Array ...
- 基于Hive的大数据分析系统
1.概述 在构建大数据分析系统的过程中,我们面对着海量.多源的数据挑战,如何有效地解决这些零散数据的分析问题一直是大数据领域研究的核心关注点.大数据分析处理平台作为应对这一挑战的利器,致力于整合当前主 ...
- 是忧是喜?——微软撑腰,奥特曼重回OpenAI任CEO —— 争论点:AI发展规范化是否会损害美国在AI领域的领先地位 —— AI发展是否需要规范化
参考: https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_1027953478745543 ...
- A3C与GA3C的收敛性分析
G-A3C的代码: https://gitee.com/devilmaycry812839668/gpu_a3c 论文: <Reinforcement Learning thorugh Asyn ...