Cache和DMA一致性
DMA应该多多少少知道点吧。DMA(Direct Memory Access)是指在外接可以不用CPU干预,直接把数据传输到内存的技术。这个过程中可以把CPU解放出来,可以很好的提升系统性能。那么DMA和Cache有什么关系呢?这也需要我们关注?
需要解决什么问题
我们知道DMA可以帮我们在I/O和主存之间搬运数据,且不需要CPU参与。高速缓存是CPU和主存之间的数据交互的桥梁。而DMA如果和cache之间没有任何关系的话,可能会出现数据不一致。
例如,CPU修改了部分数据依然躺在cache中(采用写回机制)。DMA需要将数据从内存搬运到设备I/O上,如果DMA获取的数据是从主存那里,那么就会得到旧的数据。导致程序的不正常运行。这里告诉我们,DMA通过总线获取数据时,应该先检查cache是否命中,如果命中的话,数据应该来自cache而不是主存。但是是否先需要检查cache呢?这取决于硬件设计。
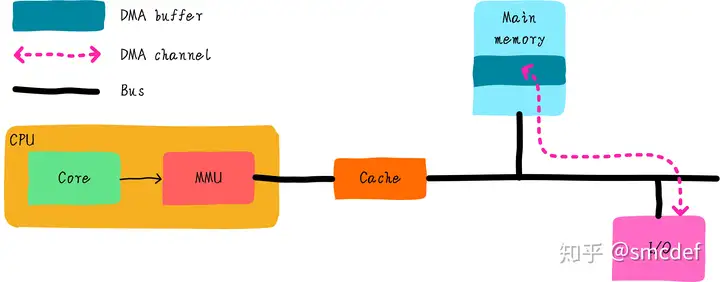
总线监视技术
还记得《Cache组织方式》文章提到的PIPT Cache吗?它是操作系统最容易管理的Cache。PIPT Cache也很容易实现总线监视技术。什么是总线监视技术呢?其实就是为了解决以上问题提出的技术,cache控制器会监视总线上的每一条内存访问,然后检查是否命中。根据命中情况做出下一步操作。我们知道DMA操作的地址是物理地址,既然cache控制器可以监视总线操作,说明系统使用的cache必须是支持物理地址查找的。而PIPT完全符合条件。
VIVT是根据虚拟地址查找cache,所以不能实现总线监视技术。VIPT可以吗?没有别名的VIPT也可以实现总线监视,但是有别名的情况的VIPT是不行的(当然硬件如果强行检查所有可能产生别名的cache line,或许也可以)。总线监视对于软件来说是透明的,软件不需要任何干涉即可避免不一致问题。但是,并不是所有的硬件都支持总线监视,同时操作系统应该兼容不同的硬件。因此在不支持总线监视的情况下,我们在软件上如何避免问题呢?
最简单的方法(nocahe)
当我们使用DMA时,首先是配置。我们需要在内存中申请一段内存当做buffer,这段内存用作需要使用DMA读取I/O设备的缓存,或者写入I/O设备的数据。为了避免cache的影响,我们可以将这段内存映射nocache,即不使用cache。映射的最小单位是4KB,因此在内存映射上至少4KB是nocahe的。这种方法简单实用,但是缺点也很明显。如果只是偶尔使用DMA,大部分都是使用数据的话,会由于nocache导致性能损失。这也是Linux系统中dma_alloc_coherent()接口的实现方法。
软件维护cache一致性
为了充分使用cache带来的好处。我们映射依然采用cache的方式。但是我们需要格外小心。根据DMA传输方向的不同,采取不同的措施。
- 如果DMA负责从I/O读取数据到内存(DMA Buffer)中,那么在DMA传输之前,可以invalid DMA Buffer地址范围的高速缓存。在DMA传输完成后,程序读取数据不会由于cache hit导致读取过时的数据。
- 如果DMA负责把内存(DMA Buffer)数据发送到I/O设备,那么在DMA传输之前,可以clean DMA Buffer地址范围的高速缓存,clean的作用是写回cache中修改的数据。在DMA传输时,不会把主存中的过时数据发送到I/O设备。
注意,在DMA传输没有完成期间CPU不要访问DMA Buffer。例如以上的第一种情况中,如果DMA传输期间CPU访问DMA Buffer,当DMA传输完成时。CPU读取的DMA Buffer由于cache hit导致取法获取最终的数据。同样,第二情况下,在DMA传输期间,如果CPU试图修改DMA Buffer,如果cache采用的是写回机制,那么最终写到I/O设备的数据依然是之前的旧数据。所以,这种使用方法编程开发人员应该格外小心。这也是Linux系统中流式DMA映射dma_map_single()接口的实现方法。
DMA Buffer对齐要求
假设我们有2个全局变量temp和buffer,buffer用作DMA缓存。初始值temp为5。temp和buffer变量毫不相关。可能buffer是当前DMA操作进程使用的变量,temp是另外一个无关进程使用的全局变量。
int temp = 5;
char buffer[64] = { 0 };
假设,cacheline大小是64字节。那么temp变量和buffer位于同一个cacheline,buffer横跨两个cacheline。

假设现在想要启动DMA从外设读取数据到buffer中。我们进行如下操作:
- 按照上一节的理论,我们先invalid buffer对应的2行cacheline。
- 启动DMA传输。
- 当DMA传输到buff[3]时,程序改写temp的值为6。temp的值和buffer[0]-buffer[60]的值会被缓存到cache中,并且标记dirty bit。
- DMA传输还在继续,当传输到buff[50]的时候,其他程序可能读取数据导致temp变量所在的cacheline需要替换,由于cacheline是dirty的。所以cacheline的数据需要写回。此时,将temp数据写回,顺便也会将buffer[0]-buffer[60]的值写回。
在第4步中,就出现了问题。由于写回导致DMA传输的部分数据(buff[3]-buffer[49])被改写(改写成了没有DMA传输前的值)。这不是我们想要的结果。因此,为了避免出现这种情况。我们应该保证DMA Buffer不会跟其他数据共享cacheline。所以我们要求DMA Buffer首地址必须cacheline对齐,并且buffer的大小也cacheline对齐。这样就不会跟其他数据共享cacheline。也就不会出现这样的问题。
Linux对DMA Buffer分配的要求
Linux中,我们要求DMA Buffer不能是从栈和全局变量分配。这个主要原因是没办法保证buffer是cacheline对齐。我们可以通过kmalloc分配DMA Buffer。这就要求某些不支持总线监视的架构必须保证kmalloc分配的内存必须是cacheline对齐。所以linux提供了一个宏,保证kmalloc分配的object最小的size。例如ARM64平台的定义如下:
#define ARCH_DMA_MINALIGN (128)
ARM64使用的cacheline大小一般是64或者128字节。为了保证分配的内存是cacheline对齐,取了最大值128。而x86_64平台则没有定义,因为x86_64硬件保证了DMA一致性。所以我们看到x86_64平台,slub管理的kmem cache最小的是kmalloc-8。而ARM64平台,slub管理的kmem cache最小的是kmalloc-128。其实ARM64平台分配小内存的代价挺高的。即使申请8字节内存,也给你分配128字节的object,确实有点浪费。
Cache和DMA一致性的更多相关文章
- ARM Linux 内核 panic 之cache 一致性 ——Cortex-A9多核cache和TLB一致性广播
ARM Linux 内核 panic 之cache 一致性 ——Cortex-A9多核cache和TLB一致性广播 Cortex-A9的多喝CPU可以接收和执行一致性广播操作,当其使能并处于SMP模式 ...
- 存储器结构、cache、DMA架构分析--【原创】
存储器的层次结构 高速缓冲存储器 cache 读cache操作 cache如果包含数据就直接从cache中读出来,因为cache速度要比内存快 如果没有包含的话,就从内存中找 ...
- 【转】DMA和cache一致性
DMA和cache一致性问题 Cache原理 CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多.缓存的出现主要是为了解决CPU ...
- DMA与cache一致性的问题
Cache和DMA本身似乎是两个毫不相关的事物.Cache被用作CPU针对内存的缓存利用程序的空间局部性和时间局部性原理,达到较高的命中率,从而避免CPU每次都必须要与相对慢速的内存交互数据来提高数据 ...
- 3.3.1 Cache一致性的基本概念
PCI设备对可Cache的存储器空间进行DMA读写的操作的过程较为复杂,有关Cache一致性的话题可以独立成书.而不同的处理器系统使用的Cache Memory的层次结构和访问机制有较大的差异,这部分 ...
- 嵌入式开发之hi3519--- pcie dma和dma cache 缓存更新sync memery
http://blog.csdn.net/likeping/article/details/42235111 linux下dma 管理 http://blog.csdn.net/skyflying20 ...
- Linux DMA访问的一致性
DMA访问的一致性 DMA对内存是直接访问的,而CPU对内存的访问有时会通过cache.不管是CPU还是DMA访问内存,都需要确保cache的一致性.本文只分析从DMA的角度,对内存的访问如何确保ca ...
- linux内存管理之DMA
说起DMA我们并不陌生,但是实际编程中去用的人不多吧,最多就是网卡驱动里的环形buffer,再有就是设备的dma,下面我们就分析分析. DMA用来在设备内存和内存之间直接数据交互.而无需cpu干预 ...
- TMS320C64x DSP L1 L2 Cache架构(1)——C64x Cache Architecture
[前沿]研究生阶段从事于DSP和FPGA技术的相关研究工作,学习并整理了大量的技术资料,包括TI公司的官方文档和网络上的详细笔记,花费了大量的时间和精力总结了前人的工作成果.无奈工作却从事于嵌入式技术 ...
- Java NIO-09-零拷贝之 DMA
DMA 的好处 在介绍DMA之前我想问大家:我们为什么要引入DMA,DMA对我们有什么好处那? 计算机系统中各种常用的数据输入/输出方法有查询方式(包括无条件及条件传送方式)和中断方式,这些方式适用于 ...
随机推荐
- a-from提交时遇到errorFields:[]验证错误(vue3)
应用场景:使用a-form组件,里面使用a-select组件:当a-select组件内的值发生改变时,调用a-form的验证表单,进而提交. 问题:提交时遇到errorFields:[]验证错误 解决 ...
- 斯坦福AI团队被质疑抄袭国产大模型
原文地址: https://mbd.baidu.com/newspage/data/landingsuper?context={"nid"%3A"news_8882699 ...
- 【转载】 Tensorflow学习笔记-模型保存与加载
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/lovelyaiq/article/det ...
- xshell打开vim后颜色异常——xshell连接ubuntu打开vim后界面覆盖一层绿色
参考原文: https://blog.csdn.net/Blank_Shen/article/details/106527312 =================================== ...
- 使用UltraISO克隆clone树莓派SD卡(注意不是复制、备份,是克隆)
搞了好长时间做了一个树莓派的SD卡,包括了一些自己安装的配置,为了防止哪天把这个SD卡搞坏掉(比如写数据时候断电,比如apt upgrade时掉电),于是考虑把这个SD卡进行克隆clone. 因为手上 ...
- npm WARN config global `--global`, `--local` are deprecated. Use `--location 的解决方法
1.背景 2.解决步骤 2.1.找到nodejs的安装路径 2.2.修改配置文件 将文件里的 prefix-g 改为 prefix --location=global 修改前: 修改后: 点击保存就解 ...
- 微服务全链路跟踪:jaeger集成hystrix
微服务全链路跟踪:grpc集成zipkin 微服务全链路跟踪:grpc集成jaeger 微服务全链路跟踪:springcloud集成jaeger 微服务全链路跟踪:jaeger集成istio,并兼容u ...
- 1分钟掌握变速效果,让你的视频快慢自如----蓝松视频编辑SDK
2. 变速调整默认速度是1X就是正常播放速度,可以通过调节滑块,实现视频中的慢镜头动作 3.只需一行代码设置播放速度/** 视频的播放速度; 范围是 0.1---10.0 默认1.0; 正 ...
- 无分号js风格注意的三个问题
建议如果一行代码是以 ( [ ` 开头的,则最好都在其前面补上一个分号. // 1.( function say() { console.log('hello world') } // ...
- Kubernetes-6:Pod生命周期介绍(init Container)
Pod生命周期 生命周期 1.API server调用kubelet下达Pod创建指令 2.容器环境初始化 3.进入Pod生命周期内(Pod开始创建) 4.Pod只要创建,就会自动生成一个pause容 ...