ElasticSearch系列——倒排索引、删除映射类型、打分机制、配置文件、常见错误
1 倒排索引
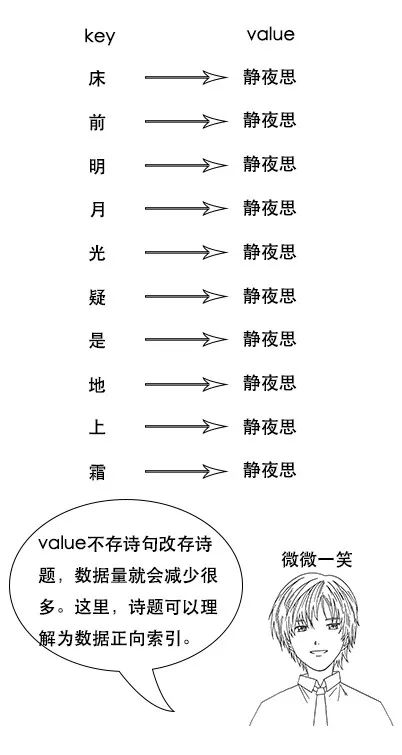
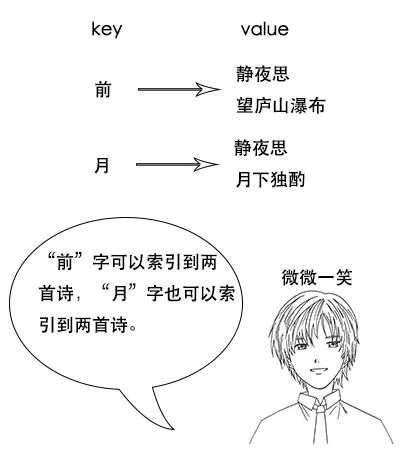
随着央视诗词大会的热播,小史开始对诗词感兴趣,最喜欢的就是飞花令的环节。

但是由于小史很久没有背过诗词了,飞一个字很难说出一句,很多之前很熟悉的诗句也想不起来。




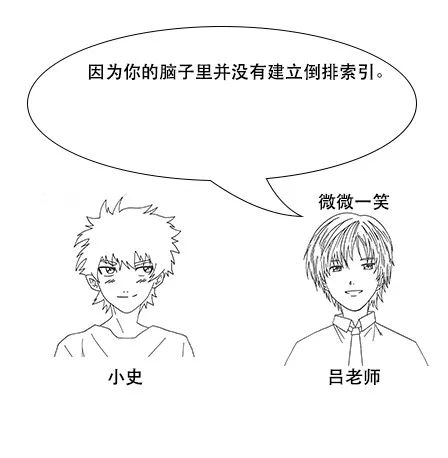

倒排索引



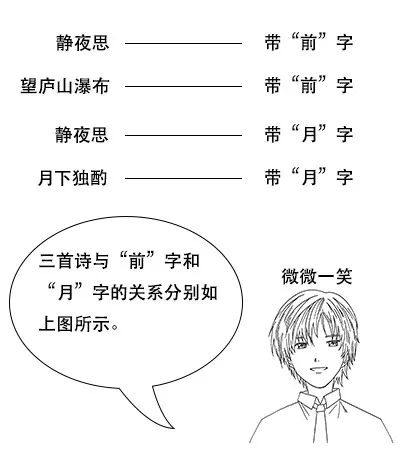
**吕老师:**但是我让你说出带“前”字的诗句,由于没有索引,你只能遍历脑海中所有诗词,当你的脑海中诗词量大的时候,就很难在短时间内得到结果了。


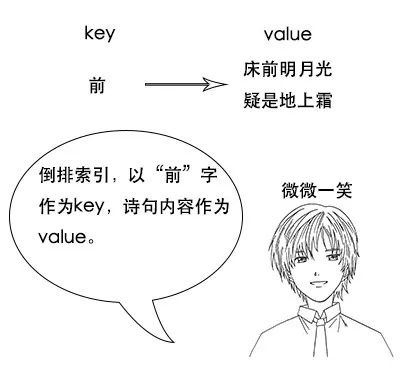



索引量爆炸

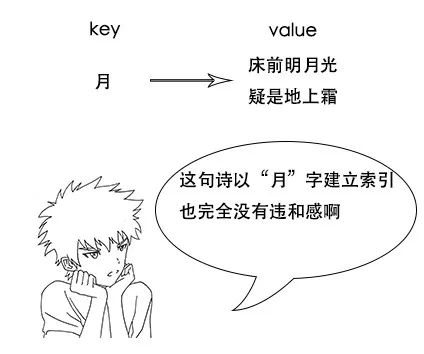











搜索引擎原理












Elasticsearch 简介





**吕老师:**但是 Lucene 还是一个库,必须要懂一点搜索引擎原理的人才能用的好,所以后来又有人基于 Lucene 进行封装,写出了 Elasticsearch。





Elasticsearch 基本概念





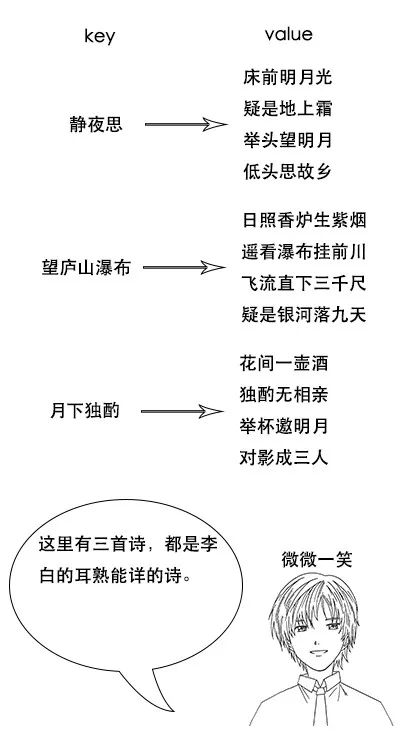
**吕老师:**类型是用来定义数据结构的,你可以认为是 MySQL 中的一张表。文档就是最终的数据了,你可以认为一个文档就是一条记录。
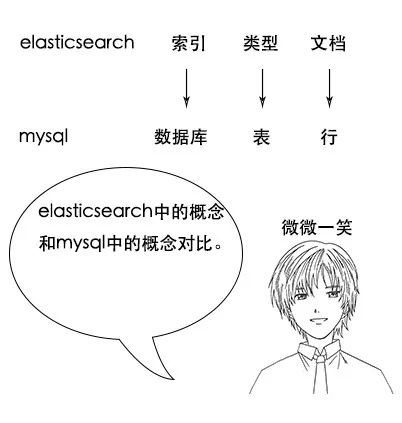


**吕老师:**比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。


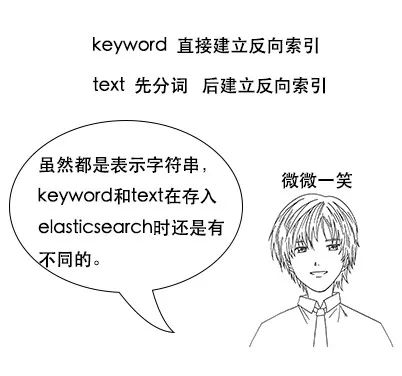
**吕老师:**这个问题问得好,这涉及到分词的问题,Keyword 类型是不会分词的,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。


**吕老师:**之前我们说过,Elasticsearch 把操作都封装成了 HTTP 的 API,我们只要给 Elasticsearch 发送 HTTP 请求就行。
比如使用 curl -XPUT ‘http://ip:port/poems’,就能建立一个名为 Poems 的索引,其他操作也是类似的。

Elasticsearch 分布式原理


**吕老师:**没错,Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因和 HDFS 是一样的,都是为了保证分布式环境下的高可用。
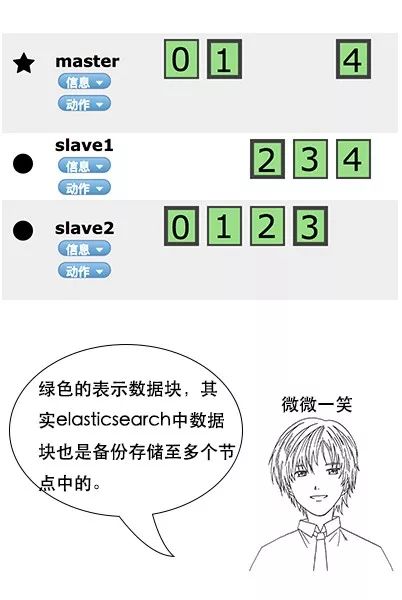


**吕老师:**没错,在 Elasticsearch 中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。

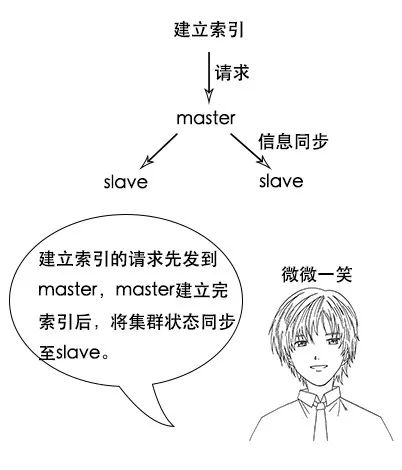

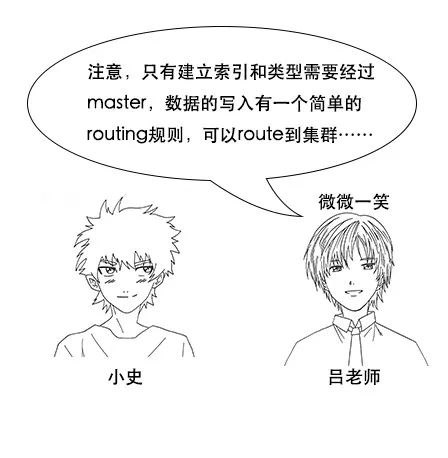
**吕老师:**注意,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。

ELK 系统


**吕老师:**其实很多公司都用 Elasticsearch 搭建 ELK 系统,也就是日志分析系统。其中 E 就是 Elasticsearch,L 是 Logstash,是一个日志收集系统,K 是 Kibana,是一个数据可视化平台。
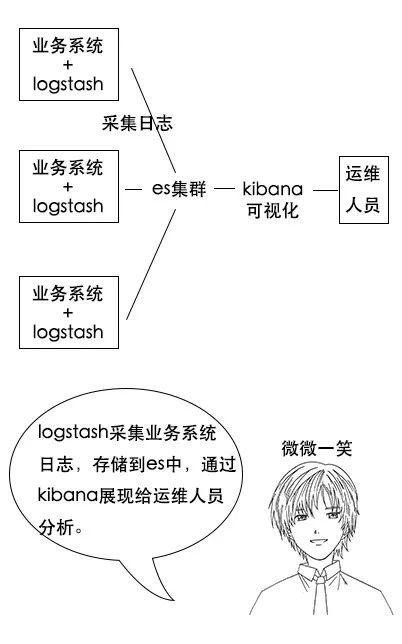


**吕老师:**分析日志的用处可大了,你想,假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?


**吕老师:**但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。


搜索引擎原理
小史学完了 Elasticsearch,在笔记本上写下了如下记录:
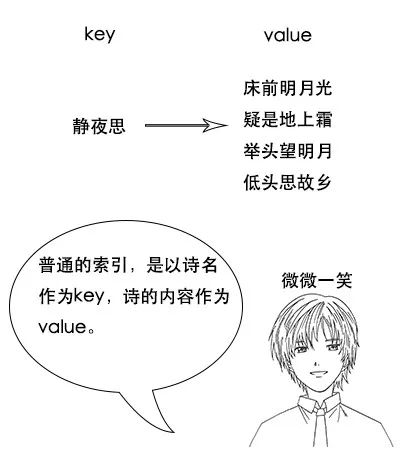
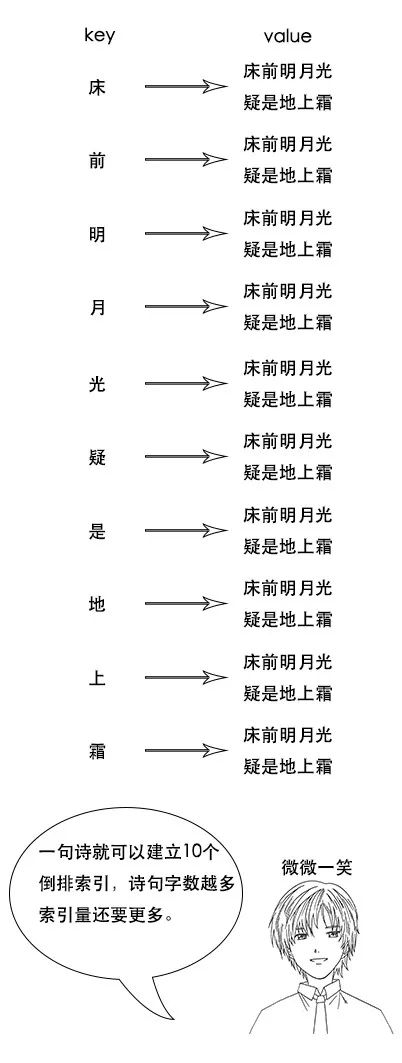
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
- 搜索引擎原理就是建立反向索引。
- Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
- Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
- Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
- Elasticsearch 一个典型应用就是 ELK 日志分析系统。
写完,又高高兴兴背诗去了。
2 删除映射类型
一 前言
官方解释:https://www.elastic.co/guide/en/elasticsearch/reference/6.0/removal-of-types.html
在elasticsearch6.0.0或更高的版本中创建索引仅能包含单个映射类型。在具有多种映射类型的5.x版本中创建的索引将继续像以前一样在elasticsearch6.x中运行。类型将在elasticsearch7.0.0中的API中弃用,并在8.0.0中完全删除。
二 什么是映射类型?
从elasticsearch发布以来,每个文档都存储在单个索引中并分配了单个映射类型。映射类型用于表示要编制索引的文档或实体的类型。例如微博(twitter)索引可能具有用户(user)类型和推文(tweet)两个类型。
每种映射类型都可以有自己的字段,因此用户(user)类型可能有full_name、user_name、email字段;而推文(tweet)类型可能有content、tweet_at字段和用户(user)类型的user_name字段。
每个文档都有一个_type包含类型名称的元字段,通过在URL中指定类型名称,搜索可以限制为一种或多种类型:
GET twitter/user,tweet/_search
{
"query":{
"match":{
"user_name":"kimchy"
}
}
}
该_type字段与文档组合_id以生成_uid字段,因此具有相同类型的文档_id可以存储在单个索引中。
映射类型也用于在文档中建立父子关系,因此类型的文档question可以是类型文档的父类answer。
扯了半天淡,一切不都是挺好的嘛?那还为啥要删除映射类型呢?
三 为什么要删除映射类型?
最初(其实到现在),为了便于理解elasticsearch的数据组织,通常拿elasticsearch和关系型数据库做对比,比如我们谈到一个es索引(index)时,通常将它比喻为类似于SQL数据库中的database,而类型(type)等同于SQL数据库中的表。
这真是一个糟糕的比喻!让我们有了错误理解。因为在SQL数据库中,表彼此独立,一个表中的字段与另一个表中具有相同名称的字段无关,而映射类型中的字段不是这种情况。
在elasticsearch的索引中,不同映射类型具有相同名称的字段在内部由相同的Lucene字段支持。换句话说,使用上面的示例,用户(user)类型中的user_name字段存储在和推文(tweet)类型中的user_name字段完全相同的字段中,而且两种类型中的user_name字段必须具有相同的映射(定义)。
当我们希望删除一个类型的日期字段和同一个索引中另一个类型的布尔字段时,这可能会导致挫败感(可以理解为删除失败)。
最重要的是,在同一索引中存储具有很少或没有共同字段的不同实体会导致稀疏数据并干扰Lucene有效压缩文档的能力。
出于这些原因,我们决定从elasticsearch中删除映射类型的概念。
四 映射类型的替代方法
4.1 将映射类型分开存储在索引中
第一种方法是每个文档类型都有一个索引,例如微博(twitter)索引中,我们可以将推文(tweet)类型和用户(user)类型分开,分别存储在独立的索引中。这样两个相互的索引就不会引起字段冲突了。
这中方法有两个好处:
- 数据更可能是密集的,因此受益于Lucene中使用的压缩技术。
- 用于全文搜索评分的词条统计将会更精确,应为同一索引中的所有文档都代表单个实体。
每个索引的大小可以根据其包含的文档数量进行适当的调整,比如我们为用户(user)类型分配较少的主分片,而为推文(tweet)类型分配较多的主分片。
4.2 自定义类型字段回到顶部
当然了,集群中可以存储多少个主分片是有限制的,我们不希望仅为几千个文档的集合而浪费整个分片。在这种情况下,我们可以实现自己的自定义type字段,该字段的工作方式与旧的_type相似。
还是上面微博(twitter)例子,最初,它的映射类型看起来是这样的:
PUT twitter
{
"mappings": {
"user":{
"properties":{
"name":{
"type":"text"
},
"user_name":{
"type":"keyword"
},
"email":{
"type":"keyword"
}
}
},
"tweet":{
"properties":{
"content":{
"type":"text"
},
"user_name":{
"type":"keyword"
},
"tweet_at":{
"type":"date"
}
}
}
}
}
PUT twitter/user/kimchy
{
"name":"狗子",
"user_name":"二狗子",
"email":"dog@twodog.com"
}
PUT twitter/tweet/1
{
"name":"kimchy",
"tweet_ad":"2019-04-30T10:26:20Z",
"content":"单身狗求包养"
}
GET twitter/tweet/_search
{
"query": {
"match": {
"user_name": "kimchy"
}
}
}
如上示例,请在5.x及以下版本测试
我们也可以通过添加自定义type字段来实现相同目的:
PUT twitter
{
"mappings": {
"doc":{
"properties":{
"type":{
"type":"keyword"
},
"name":{
"type":"text"
},
"user_name":{
"type":"keyword"
},
"email":{
"type":"text"
},
"content":{
"type":"text"
},
"tweet_at":{
"type":"date"
}
}
}
}
}
PUT twitter/doc/user-kimchy
{
"type":"user",
"name":"狗子",
"user_name":"二狗子",
"email":"dog@twodog.com"
}
PUT twitter/doc/tweet-1
{
"type":"tweet",
"user_name":"kimchy",
"tweet_at":"2019-04-30T10:26:20Z",
"content":"单身狗求包养"
}
GET twitter/_search
{
"query": {
"bool": {
"must":[
{
"match": {
"user_name": "kimchy"
}
}
],
"filter": {
"match":{
"type":"tweet"
}
}
}
}
}
上述示例6.5.4版本运行无误。
五 没有映射类型的父/子
以前,通过将一个映射类型设置为父级,将一个或多个其他映射类型设置为子级来表示父子关系。现在,没有了多类型,我们就不能再使用这种语法了。除了表示文档之间的关系方式已改为使用新的join字段之外,父子特征将继续像以前一样运行。
六 删除映射类型的计划
这个删除映射类型的计划,对于用户来说是一个很大的变化,所以我们试图让它尽可能轻松,更改将如下所示:
在elasticsearch5.6.0中:
- index.mapping.single_type:true在索引上设置将启用在6.0中强制执行的单索引类型。
- 父子的join字段替换可用于在5.6中创建索引。
在elasticsearch6.x中:
- 在5.x中创建的索引将继续在6.x中运行,就像在5.x中一样。
- 在6.x中创建的索引仅允许每个索引使用单一类型,任何字段都可以用于该类型,但必须是唯一的。
- 该
_type名称可以不再与_id组合形成_uid字段,_uid字段已成为_id字段的别名。 - 新索引不再支持旧的父/子关系,而是应该使用连接字段。
- 不推荐使用
_default_mapping类型。 - 在6.7中,索引创建、索引模板和映射API支持查询字符串参数(include_type_name),该参数仅表示请求和响应是否应该包含类型名称,默认为true,应该设置为一个显式值,以便准备升级到7.0。未设置
include_type_name将导致一个弃用警告,没有显式类型的索引将使用默认的类型名称_doc。
在elasticsearch7.x中:
- 不推荐在请求中指定类型。例如,索引文档不再需要文档类型。对于自动生成的id,新的索引API在显式ids和
POST {index_name}/_doc的情况下是PUT {index_name}/_doc/{id}。 - 索引创建,索引模板和映射API中的
include_type_name参数将默认为false,未设置参数将导致启动警告。 - 删除了
_default_mapping类型。
在elasticsearch8.x中:
- 不在支持在请求中指定类型。
include_type_name参数已删除。
七将多类型索引迁移到单一类型
Reindex API可用于将多类型索引转换为单类型索引。下面的例子可以在Elasticsearch 5.6或Elasticsearch 6.x中使用。在6.x中,不需要指定index.mapping。默认为单一类型。
7.1 每种文档类型的索引
第一个示例将微博(twitter)索引拆分为推文(tweets)索引和用户(users)索引:
PUT users
{
"mappings": {
"user":{
"properties":{
"name":{
"type":"text"
},
"user_name":{
"type":"keyword"
},
"email":{
"type":"keyword"
}
}
}
}
}
PUT tweets
{
"mappings": {
"tweet":{
"properties":{
"content":{
"type":"text"
},
"user_name":{
"type":"keyword"
},
"tweet_at":{
"type":"date"
}
}
}
}
}
POST _reindex
{
"source": {
"index":"twitter",
"type":"user"
},
"dest": {
"index":"users"
}
}
POST _reindex
{
"source": {
"index":"twitter",
"type":"tweet"
},
"dest": {
"index": "tweets"
}
}
上述代码在6.5.4版本中运行无误。
上述的示例意思是,在之前我们在微博(twitter)索引中,有两个类型(tweet和user)。现在要将两个类型分开,成为独立的索引。所以,首先先创建出各自的索引(tweets和users),然后通过POST _reindex来完成迁移工作。
7.2 自定义类型字段
第二个示例添加自自定义的type字段,并将其设置为原始值_type。它还添加了类型到id,以防有任何不同类型的文档具有冲突的id:
PUT new_twitter
{
"mappings": {
"doc":{
"properties":{
"type":{
"type":"keyword"
},
"name":{
"type":"text"
},
"user_name":{
"type":"keyword"
},
"email":{
"type":"keyword"
},
"content":{
"type":"text"
},
"tweet_at":{
"type":"date"
}
}
}
}
}
POST _reindex
{
"source": {
"index":"twitter"
},
"dest":{
"index": "new_twitter"
},
"script": {
"source": """
ctx._source.type = ctx._type;
ctx._id = ctx._type + "-" + ctx._id;
ctx._type = "doc";
"""
}
}
上述代码在6.5.4版本运行无误。
八 总结
总之,通篇看下来,如果对elasticsearch,尤其是各版本不太了解的话,这篇文档看着索然无味!重要的是看不懂,如果我们是新手,接触elasticsearch的时候,就是从6.x版本开始的,那只要记得,一个索引下面只能创建一个类型就行了,其中各字段都具有唯一性,如果在创建映射的时候,如果没有指定文档类型,那么该索引的默认索引类型是_doc,不指定文档id则会内部帮我们生成一个id字符串。其他的,who care?
3 Elasticsearch之-打分机制
一 例子
现在,讲述一个真实的故事!
故事一定是伴随着赵忠祥老师的声音开始的,雨季就要来临了,又到了动物们发情的季节了…
还记得,之前发生的作家六六吐槽xx的事情吗?对了,有图有真相!上图上图:
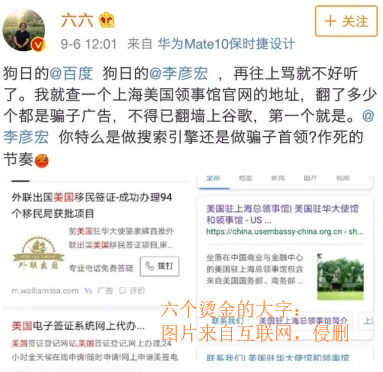
身为吃瓜群众,要从专业的角度来分析,就事论事哈:
就搜索结果本身而言,xx返回了正确的结果(是的,人家已经调整了,现在搜没问题!)。因为返回的结果中,都包含了搜索的关键字。而我们从逻辑上来看,这他娘的一堆广告算是咋回事!这个吐槽是从用户的角度出发的。很显然,返回的结果中,尤其是前几条,有时甚至是前几页,都跟我们想要的结果相差深远!
进一步说,仅仅以二元的方式来考虑文档和查询的匹配可能是有意义的,也就是百度搜索引擎返回了二元的匹配结果:是的,找到了,不,老娘没找到!虽然返回了结果,其中也包含了我们想要的结果,即便你要在大堆的广告中找正确的结果实属不易,但就像大家都习惯了广告中插播电视剧一样,习惯就好嘛!xx从x的角度出发,为广告的词条增加权重,至于那个真正的结果,我擦,你也没给我钱…
而需要xx才能访问的xx浏览器,在正确的给用户返回二元结果之前,更多的考虑文档的相关性(relevancy),因为就某个结果而言,如果A文档要比B文档更和结果相关,那么A文档在结果中就要比B文档靠前,再加上以其他的优化,最终将所有结果返回,而用户最期待的那条结果很可能排在最高位,这岂不美哉?
确定文档和查询有多么相关的过程被称为打分(scoring)。
二 文档打分的运作机制:TF-IDF
Lucene和es的打分机制是一个公式。将查询作为输入,使用不同的手段来确定每一篇文档的得分,将每一个因素最后通过公式综合起来,返回该文档的最终得分。这个综合考量的过程,就是我们希望相关的文档被优先返回的考量过程。在Lucene和es中这种相关性称为得分。
在开始计算得分之前,es使用了被搜索词条的频率和它有多常见来影响得分,从两个方面理解:
- 一个词条在某篇文档中出现的次数越多,该文档就越相关。
- 一个词条如果在不同的文档中出现的次数越多,它就越不相关!
我们称之为TF-IDF,TF是词频(term frequency),而IDF是逆文档频率(inverse document frequency)。
2.1 词频:TF
考虑一篇文档得分的首要方式,是查看一个词条在文档中出现的次数,比如某篇文章围绕es的打分展开的,那么文章中肯定会多次出现相关字眼,当查询时,我们认为该篇文档更符合,所以,这篇文档的得分会更高。
闲的蛋疼的可以Ctrl + f搜一下相关的关键词(es,得分、打分)之类的试试。
2.2 逆文档频率:IDF
相对于词频,逆文档频率稍显复杂,如果一个词条在索引中的不同文档中出现的次数越多,那么它就越不重要。
来个例子,示例地址:
The rules-which require employees to work from 9 am to 9 pm
In the weeks that followed the creation of 996.ICU in March
The 996.ICU page was soon blocked on multiple platforms including the messaging tool WeChat and the UC Browser.
假如es索引中,有上述3篇文档:
- 词条
ICU的文档频率是2,因为它出现在2篇文档中,文档的逆源自得分乘以1/DF,DF是该词条的文档频率,这就意味着,由于ICU词条拥有更高的文档频率,所以,它的权重会降低。 - 词条
the的文档频率是3,它在3篇文档中都出现了,注意:尽管the在后两篇文档出都出现两次,但是它的词频是还是3,因为,逆文档词频只检查词条是否出现在某篇文档中,而不检查它在这篇文档中出现了多少次,那是词频该干的事儿。
逆文档词频是一个重要的因素,用来平衡词条的词频。比如我们搜索the 996.ICU。单词the几乎出现在所有的文档中(中文中比如的),如果这个鬼东西要不被均衡一下,那么the的频率将完全淹没996.ICU。所以,逆文档词频就有效的均衡了the这个常见词的相关性影响。以达到实际的相关性得分将会对查询的词条有一个更准确地描述。
当词频和逆文档词频计算完成。就可以使用TF-IDF公式来计算文档的得分了。
三 Lucene评分公式
之前的讨论Lucene默认评分公式被称为TF-IDF,一个基于词频和逆文档词频的公式。Lucene实用评分公式如下:

你以为我会着重介绍这个该死的公式?!
我只能说,词条的词频越高,得分越高;相似地,索引中词条越罕见,逆文档频率越高,其中再加商调和因子和查询标准化,调和因子考虑了搜索过多少文档以及发现了多少词条;查询标准化,是试图让不同的查询结果具有可比性,这显然…很困难。
我们称这种默认的打分方法是TF-IDF和向量空间模型(vector space model)的结合。
四 其他的打分方法
除了TF-IDF结合向量空间模型的实用评分模式,是es和Lucene最为主流的评分机制,但这并不是唯一的,除了TF-IDF这种实用模型之外,其他的模型包括:
- Okapi BM25。
- 随机性分歧(Divergence from randomness),即DFR相似度。
- LM Dirichlet相似度。
- LM Jelinek Mercer相似度。
这里简要的介绍BM25几种主要设置,即k1、b和discount_overlaps:
- k1和b是数值的设置,用于调整得分是如何计算的。
- k1控制对于得分而言词频(TF)的重要性。
- b是介于
0 ~ 1之间的数值,它控制了文档篇幅对于得分的影响程度。 - 默认情况下,
k1设置为1.2,而b则被设置为0.75 discount_overlaps的设置用于告诉es,在某个字段中,多少个分词出现在同一位置,是否应该影响长度的标准化,默认值是true。
五 配置打分模型
5.1 简要配置BM25打分模型
BM25(是不是跟pm2.5好像!!!)是一种基于概率的打分框架。我们来简要的配置一下:
PUT w2
{
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"similarity": "BM25"
}
}
}
}
}
PUT w2/doc/1
{
"title":"The rules-which require employees to work from 9 am to 9 pm"
}
PUT w2/doc/2
{
"title":"In the weeks that followed the creation of 996.ICU in March"
}
PUT w2/doc/3
{
"title":"The 996.ICU page was soon blocked on multiple platforms including the messaging tool WeChat and the UC Browser."
}
GET w2/doc/_search
{
"query": {
"match": {
"title": "the 996"
}
}
}
上例是通过similarity参数来指定打分模型。至于查询,还是当数据量比较大的时候,多试几次,比较容易发现不同之处。
5.2 为BM25配置高级的settings
PUT w3
{
"settings": {
"index": {
"analysis": {
"analyzer":"ik_smart"
}
},
"similarity": {
"my_custom_similarity": {
"type": "BM25",
"k1": 1.2,
"b": 0.75,
"discount_overlaps": false
}
}
},
"mappings": {
"doc": {
"properties": {
"title": {
"type": "text",
"similarity":"my_custom_similarity"
}
}
}
}
}
PUT w3/doc/1
{
"title":"The rules-which require employees to work from 9 am to 9 pm"
}
PUT w3/doc/2
{
"title":"In the weeks that followed the creation of 996.ICU in March"
}
PUT w3/doc/3
{
"title":"The 996.ICU page was soon blocked on multiple platforms including the messaging tool WeChat and the UC Browser."
}
GET w3/doc/_search
{
"query": {
"match": {
"title": "the 996"
}
}
}
5.3 配置全局打分模型
如果我们要使用某种特定的打分模型,并且希望应用到全局,那么就在elasticsearch.yml配置文件中加入:
index.similarity.default.type: BM25
六 boosting
boosting是一个用来修改文档相关性的程序。boosting有两种类型:
- 索引的时候,比如我们在定义mappings的时候。
- 查询一篇文档的时候。
以上两种方式都可以提升一个篇文档的得分。需要注意的是:在索引期间修改的文档boosting是存储在索引中的,要想修改boosting必须重新索引该篇文档。
6.1 索引期间的boosting
啥也不说了,都在酒里!上代码:
PUT w4
{
"mappings": {
"doc": {
"properties": {
"name": {
"boost": 2.0,
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
}
一劳永逸是没错,但一般不推荐这么玩。
原因之一是因为一旦映射建立完成,那么所有name字段都会自动拥有一个boost值。要想修改这个值,那就必须重新索引文档。
另一个原因是,boost值是以降低精度的数值存储在Lucene内部的索引结构中。只有一个字节用于存储浮点型数值(存不下就损失精度了),所以,计算文档的最终得分时可能会损失精度。
最后,boost是应用与词条的。因此,再被boost的字段中如果匹配上了多个词条,就意味着计算多次的boost,这将会进一步增加字段的权重,可能会影响最终的文档得分。
现在我们再来介绍另一种方式。
6.2 查询期间的boosting
在es中,几乎所有的查询类型都支持boost,正如你想象的那些match、multi_match等等。
来个示例,在查询期间,使用match查询进行boosting:
PUT w5
{
"mappings":{
"doc":{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
PUT w5/doc/1
{
"title":"Lucene is cool",
"content": "Lucene is cool"
}
PUT w5/doc/2
{
"title":"Elasticsearch builds on top of lucene",
"content":"Elasticsearch builds on top of lucene"
}
PUT w5/doc/3
{
"title":"Elasticsearch rocks",
"content":"Elasticsearch rocks"
}
来查询:
GET w5/doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title":{
"query": "elasticserach rocks",
"boost": 2.5
}
}
},
{
"match": {
"content": "elasticserach rocks"
}
}
]
}
}
}
就对于最终得分而言,content字段,加了boost的title查询更有影响力。也只有在bool查询中,boost更有意义。
6.3 跨越多个字段的查询
boost也可以用于multi_match查询。
GET w5/doc/_search
{
"query": {
"multi_match": {
"query": "elasticserach rocks",
"fields": ["title", "content"],
"boost": 2.5
}
}
}
除此之外,我们还可以使用特殊的语法,只为特定的字段指定一个boost。通过在字段名称后添加一个^符号和boost的值。告诉es只需对那个字段进行boost:
GET w5/doc/_search
{
"query": {
"multi_match": {
"query": "elasticserach rocks",
"fields": ["title^3", "content"]
}
}
}
上例中,title字段被boost了3倍。
需要注意的是:在使用boost的时候,无论是字段或者词条,都是按照相对值来boost的,而不是乘以乘数。如果对于所有的待搜索词条boost了同样的值,那么就好像没有boost一样(废话,就像大家都同时长高一米似的)!因为Lucene会标准化boost的值。如果boost一个字段4倍,不是意味着该字段的得分就是乘以4的结果。所以,如果你的得分不是按照严格的乘法结果,也不要担心。
七 使用“解释”来理解文档是如何评分的
一切都不是你想的那样!是的,在es中,一个文档要比另一个文档更符合某个查询很可能跟我们想象的不太一样!
这一小节,我们来研究下es和Lucene内部使用了怎样的公式来计算得分。
我们通过explain=true来告诉es,你要给洒家解释一下为什么这个得分是这样的?!背后到底以有什么py交易!
比如我们来查询:
GET py1/doc/_search
{
"query": {
"match": {
"title": "北京"
}
},
"explain": true,
"_source": "title",
"size": 1
}
由于结果太长,我们这里对结果进行了过滤("size": 1返回一篇文档),只查看指定的字段("_source": "title"只返回title字段)。
看结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 24,
"max_score" : 4.9223156,
"hits" : [
{
"_shard" : "[py1][1]",
"_node" : "NRwiP9PLRFCTJA7w3H9eqA",
"_index" : "py1",
"_type" : "doc",
"_id" : "NIjS1mkBuoj17MYtV-dX",
"_score" : 4.9223156,
"_source" : {
"title" : "大写的尴尬 插混为啥在北京不受待见?"
},
"_explanation" : {
"value" : 4.9223156,
"description" : "weight(title:北京 in 36) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 4.9223156,
"description" : "score(doc=36,freq=1.0 = termFreq=1.0\n), product of:",
"details" : [
{
"value" : 4.562031,
"description" : "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details" : [
{
"value" : 4.0,
"description" : "docFreq",
"details" : [ ]
},
{
"value" : 430.0,
"description" : "docCount",
"details" : [ ]
}
]
},
{
"value" : 1.0789746,
"description" : "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details" : [
{
"value" : 1.0,
"description" : "termFreq=1.0",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "parameter k1",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "parameter b",
"details" : [ ]
},
{
"value" : 12.1790695,
"description" : "avgFieldLength",
"details" : [ ]
},
{
"value" : 10.0,
"description" : "fieldLength",
"details" : [ ]
}
]
}
]
}
]
}
}
]
}
}
在新增的_explanation字段中,可以看到value值是4.9223156,那么是怎么算出来的呢?
来分析,分词北京在描述字段(title)出现了1次,所以TF的综合得分经过"description" : "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:"计算,得分是1.0789746。
那么逆文档词频呢?根据"description" : "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:"计算得分是4.562031。
所以最终得分是:
1.0789746 * 4.562031 = 4.9223155734126
结果在四舍五入后就是4.9223156。
需要注意的是,explain的特性会给es带来额外的性能开销。所以,除了在调试时可以使用,生产环境下,应避免使用explain。
4 Elasticsearch之-配置文件
一 前言
在elasticsearch\config目录下,有三个核心的配置文件:
- elasticsearch.yml,es相关的配置。
- jvm.options,Java jvm相关参数的配置。
- log4j2.properties,日志相关的配置,因为es采用了log4j的日志框架。
这里以elasticsearch6.5.4版本为例,并且由于版本不同,配置也不太也一样,仅作参考!
二 elasticsearch.yml
2.1 Cluster
- 配置集群名称,由多个es实例组成的集群,有一个共同的名称。
cluster.name: my-application
- 集群端口设置。
transport.tcp.port: 9300
- 防止同一个shard的主副本存在同一个物理机上。
cluster.routing.allocation.same_shard.host:true
- 初始化数据恢复时,并发恢复线程的个数,默认是4个。
cluster.routing.allocation.node_initial_primaries_recoveries: 4
- 添加删除节点或者负载均衡时并发恢复线程的个数。默认是4个。
cluster.routing.allocation.node_concurrent_recoveries: 4
2.2 Node
- 节点名称配置,一个es实例其实是一个es进程,在集群中被称为节点。如果一个服务器上配置集群,各节点的名称不能重复。
node.name: node-1
- 为节点添加自定义属性,
node.attr.rack: r1
- 该节点是否有资格成为主节点,默认为true。
node.master: true
- 设置节点是否存储数据。
node.data: true
- 设置默认主分片的个数,默认为5片,需要说明的是,主分片一经分配则无法更改。
index.number_of_shards: 5
- 设置默认复制分片的个数,默认一个主分片对应一个复制分片,需要说明的是,复制分片可以手动调整。
index.number_of_replicas: 1
- 设置数据恢复时限制的带宽,默认0及不限制。
indices.recovery.max_size_per_ser: 0
- 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
indices.recovery.concurrent_streams: 5
- 设置数据恢复时限制的带宽,默认0及不限制。
indices.recovery.max_size_per_ser: 0
- 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
indices.recovery.concurrent_streams: 5
2.3 Paths
- 存储数据路径设置,多个路径以英文状态的逗号分隔,默认根目录下的
conf目录。
path.data: /path/to/data
# path.data: /path/to/data1,/path/to/data1
- 设置临时文件存储路径,默认是es目录下的work目录。
path.work: /path/to/work
- 日志文件路径,默认为根目录下的
logs目录。
path.logs: /path/to/logs
- 设置日志文件的存储路径,默认是es目录下的
logs目录。
path.logs: /path/to/logs
- 设置插件的存放路径,默认是es目录下的
plugins目录。
path.plugins: /path/to/plugins
2.4 Network
- 为es实例绑定特定的IP地址。
network.host: 192.168.0.1
上面的设置可以拆分为两个参数。
network.bind_host: 192.168.0.1 # 设置绑定的ip地址,ipv4或ipv6都可以
network.publish_host: 192.168.0.1 # 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址
- 为es实例设置特定的端口,默认为9200端口。
http.port: 9200
2.5 Discovery
- 设置是否打开多播发现节点,默认是true。
discovery.zen.ping.multicast.enabled: true
- 配置es单播发现列表,在es启动时,通过这个列表发现别的es实例,从而加入集群。
discovery.zen.ping.unicast.hosts: ["host1", "host2"]
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.3:9300", "10.0.0.6[9300-9400]"]
discovery.zen.minimum_master_nodes设置是告诉集群有多少个节点有资格成为主节点,一般的规则是集群节点数除以2(向下取整)再加一。比如3个节点集群要设置为2,这个试着是为了防止脑裂问题。- 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
discovery.zen.ping.timeout: 3s
2.6 Memory
- 启动时锁定内存,默认为true,因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过ulimit -l unlimited命令
bootstrap.memory_lock: true
- 禁止swapping交换。
bootstrap.mlockall: true
2.7 Gateway
- 设置是否压缩tcp传输时的数据。默认是false不压缩。
transport.tcp.compress: true
- 设置内容的最大容量,默认是100mb。
http.max_content_length: 100mb
- 是否使用http协议对外提供服务。默认为true。
http.enabled: false
- 设置gateway的类型,默认为本地文件系统,也可以设置分布式文件系统、Hadoop的HDFS或者AWS的都可以。
gateway.type: local
- 在完全重新启动集群之后阻塞初始恢复,直到启动N个节点为止,详情参见Recovery
gateway.recover_after_nodes: 3
- 设置初始化数据恢复进程的超时时间。默认是5分钟。
gateway.recover_after_time: 5m
- 设置该集群中节点的数量,默认为2个,一旦这N个节点启动,就会立即进行数据恢复。
gateway.expected_nodes: 2
2.8 Various
- 删除索引时需要显式名称。
action.destructive_requires_name: true
三 jvm.options
- 设置jvm堆的大小,最大值和最小值,应该是一致的,并且应该根据你的物理内存决定。
-Xms1g # 设置最小堆为1g
-Xmx1g # 设置最大堆为1g
四 log4j2.properties
这个配置文件,我们一般不修改其配置。
5 Elasticsearch之-常见错误
一 read_only_allow_delete" : “true”
当我们在向某个索引添加一条数据的时候,可能(极少情况)会碰到下面的报错:
{
"error": {
"root_cause": [
{
"type": "cluster_block_exception",
"reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
}
],
"type": "cluster_block_exception",
"reason": "blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
},
"status": 403
}
上述报错是说索引现在的状态是只读模式(read-only),如果查看该索引此时的状态:
GET z1/_settings
# 结果如下
{
"z1" : {
"settings" : {
"index" : {
"number_of_shards" : "5",
"blocks" : {
"read_only_allow_delete" : "true"
},
"provided_name" : "z1",
"creation_date" : "1556204559161",
"number_of_replicas" : "1",
"uuid" : "3PEevS9xSm-r3tw54p0o9w",
"version" : {
"created" : "6050499"
}
}
}
}
}
可以看到"read_only_allow_delete" : "true",说明此时无法插入数据,当然,我们也可以模拟出来这个错误:
PUT z1
{
"mappings": {
"doc": {
"properties": {
"title": {
"type":"text"
}
}
}
},
"settings": {
"index.blocks.read_only_allow_delete": true
}
}
PUT z1/doc/1
{
"title": "es真难学"
}
现在我们如果执行插入数据,就会报开始的错误。那么怎么解决呢?
- 清理磁盘,使占用率低于85%。
- 手动调整该项,具体参考官网
这里介绍一种,我们将该字段重新设置为:
PUT z1/_settings
{
"index.blocks.read_only_allow_delete": null
}
现在再查看该索引就正常了,也可以正常的插入数据和查询了。
二 illegal_argument_exception
有时候,在聚合中,我们会发现如下报错:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "z2",
"node": "NRwiP9PLRFCTJA7w3H9eqA",
"reason": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
],
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [age] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."
}
}
},
"status": 400
}
这是怎么回事呢?是因为,聚合查询时,指定字段不能是text类型。比如下列示例:
PUT z2/doc/1
{
"age":"18"
}
PUT z2/doc/2
{
"age":20
}
GET z2/doc/_search
{
"query": {
"match_all": {}
},
"aggs": {
"my_sum": {
"sum": {
"field": "age"
}
}
}
}
当我们向elasticsearch中,添加一条数据时(此时,如果索引存在则直接新增或者更新文档,不存在则先创建索引),首先检查该age字段的映射类型。如上示例中,我们添加第一篇文档时(z1索引不存在),elasticsearch会自动的创建索引,然后为age字段创建映射关系(es就猜此时age字段的值是什么类型,如果发现是text类型,那么存储该字段的映射类型就是text),此时age字段的值是text类型,所以,第二条插入数据,age的值也是text类型,而不是我们看到的long类型。我们可以查看一下该索引的mappings信息:
GET z2/_mapping
# mapping信息如下
{
"z2" : {
"mappings" : {
"doc" : {
"properties" : {
"age" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
上述返回结果发现,age类型是text。而该类型又不支持聚合,所以,就会报错了。解决办法就是:
- 如果选择动态创建一篇文档,映射关系取决于你添加的第一条文档的各字段都对应什么类型。而不是我们看到的那样,第一次是
text,第二次不加引号,就是long类型了不是这样的。 - 如果嫌弃上面的解决办法麻烦,那就选择手动创建映射关系。首先指定好各字段对应什么类型。后续才不至于出错。
三 Result window is too large
很多时候,我们在查询文档时,一次查询结果很可能会有很多,而elasticsearch一次返回多少条结果,由size参数决定:
GET e2/doc/_search
{
"size": 100000,
"query": {
"match_all": {}
}
}
而默认是最多范围一万条,那么当我们的请求超过一万条时(比如有十万条),就会报:
Result window is too large, from + size must be less than or equal to: [10000] but was [100000]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.
意思是一次请求返回的结果太大,可以另行参考 scroll API或者设置index.max_result_window参数手动调整size的最大默认值:
# kibana中设置
PUT e2/_settings
{
"index": {
"max_result_window": "100000"
}
}
# Python中设置
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.put_settings(index='e2', body={"index": {"max_result_window": 100000}})
如上例,我们手动调整索引e2的size参数最大默认值到十万,这时,一次查询结果只要不超过10万就都会一次返回。
注意,这个设置对于索引es的size参数是永久生效的。
ElasticSearch系列——倒排索引、删除映射类型、打分机制、配置文件、常见错误的更多相关文章
- Elasticsearch系列---倒排索引原理与分词器
概要 本篇主要讲解倒排索引的基本原理以及ES常用的几种分词器介绍. 倒排索引的建立过程 倒排索引是搜索引擎中常见的索引方法,用来存储在全文搜索下某个单词在一个文档中存储位置的映射.通过倒排索引,我们输 ...
- Elasticsearch系列---简单入门实战
概要 本篇主要介绍一下Elasticsearch Document的数据格式,在Java应用程序.关系型数据库建模的对比,介绍在Kibana平台编写Restful API完成基本的集群状态查询,Doc ...
- ElasticSearch 5学习(9)——映射和分析(string类型废弃)
在ElasticSearch中,存入文档的内容类似于传统数据每个字段一样,都会有一个指定的属性,为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成字符串值,Elasticsearc ...
- Es图形化软件使用之ElasticSearch-head、Kibana,Elasticsearch之-倒排索引操作、映射管理、文档增删改查
今日内容概要 ElasticSearch之-ElasticSearch-head ElasticSearch之-安装Kibana Elasticsearch之-倒排索引 Elasticsearch之- ...
- Elasticsearch学习系列之mapping映射
什么是映射 为了能够把日期字段处理成日期,把数字字段处理成数字,把字符串字段处理成全文本(Full-text)或精确(Exact-value)的字符串值,Elasticsearch需要知道每个字段里面 ...
- Json.Net系列教程 2.Net类型与JSON的映射关系
原文 Json.Net系列教程 2.Net类型与JSON的映射关系 首先谢谢大家的支持和关注.本章主要介绍.Net类型与JSON是如何映射的.我们知道JSON中类型基本上有三种:值类型,数组和对象.而 ...
- elasticsearch 5.x 系列之三 mapping 映射的时候的各个字段的设置
首先看来创建一个mapping 来show show: curl -XPUT "master:9200/zebra_info?pretty" -H 'Content-Type: a ...
- Elasticsearch系列---分布式架构机制讲解
概要 本篇主要介绍Elasticsearch的数据索引时的分片机制,集群发现机制,primary shard与replica shard是如何分工合作的,如何对集群扩容,以及集群的容错机制. 分片机制 ...
- .Net Discovery 系列之五--深入浅出.Net实时编译机制(上)
欢迎阅读“.Net Discovery 系列”文章,本文将分上.下两部分为大家讲解.Net JIT方面的知识,敬请雅正. JIT(Just In Time简称JIT)是.Net边运行边编译的一种机制, ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
随机推荐
- MySQL8新特性窗口函数详解
本文博主给大家详细讲解一波 MySQL8 的新特性:窗口函数,相信大伙看完一定能有所收获. 本文提供的 sql 示例都是基于 MySQL8,由博主亲自执行确保可用 博主github地址:http:// ...
- 文件系统考古 3:1994 - The SGI XFS Filesystem
在 1994 年,论文<XFS 文件系统的可扩展性>发表了.自 1984 年以来,计算机的发展速度变得更快,存储容量也增加了.值得注意的是,在这个时期出现了更多配备多个 CPU 的计算机, ...
- PostgreSQL 12 文档: 部分 I. 教程
部分 I. 教程 欢迎来到PostgreSQL教程.下面的几章将为那些新接触PostgreSQL.关系数据库概念和 SQL 语言的读者给出一个简单介绍.我们只假定读者拥有关于如何使用计算机的一般知识. ...
- 一个跨平台的`ChatGPT`悬浮窗工具
一个跨平台的ChatGPT悬浮窗工具 使用avalonia实现的ChatGPT的工具,设计成悬浮窗,并且支持插件. 如何实现悬浮窗? 在使用avalonia实现悬浮窗也是非常的简单的. 实现我们需要将 ...
- 如何使用libswscale库将YUV420P格式的图像序列转换为RGB24格式输出?
一.视频格式转换初始化 将视频中的图像帧按照一定比例缩放或指定宽高进行放大和缩小是视频编辑中最为常见的操作之一,这里我们将1920x1080的yuv图像序列转换成640x480的rgb图像序列,并输出 ...
- 从头学Java17-Stream API(一)
Stream API Stream API 是按照map/filter/reduce方法处理内存中数据的最佳工具. 本系列中的教程包含从基本概念一直到collector设计和并行流. 在流上添加中继操 ...
- C#中IsNullOrEmpty和IsNullOrWhiteSpace的使用方法有什么区别?
前言 今天我们将探讨C#中两个常用的字符串处理方法:IsNullOrEmpty和IsNullOrWhiteSpace.这两个方法在处理字符串时非常常见,但是它们之间存在一些细微的区别.在本文中,我们将 ...
- 【Python】Beautiful Soup
简介 Beautiful Soup 对象 我全部使用soup表示: Beautiful Soup 简介: 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. ...
- 图像格式及Matlab的格式转换
1. matlab图像保存说明 matlab中读取图片后保存的数据是uint8类型(8位无符号整数,即1个字节),以此方式存储的图像称作8位图像,好处相比较默认matlab数据类型双精度浮点doubl ...
- 安装mysql5.7.20,和遇到的一些错误及解决方案
下载: mysql-5.7.20是解压版免安装的,mysql-5.7.20下载地址:http://dev.mysql.com/downloads/mysql/ 2.安装 解压在你喜欢的位置 3.配置 ...