AudioLDM 2,加速!
AudioLDM 2 由刘濠赫等人在 AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining 一文中提出。 AudioLDM 2 接受文本提示作为输入并输出对应的音频,其可用于生成逼真的声效、人类语音以及音乐。
虽然生成的音频质量很高,但基于其原始实现进行推理的速度非常慢: 生成一个 10 秒的音频需要 30 秒以上的时间。慢的原因是多重的,包括其使用了多阶段建模、checkpoint 较大以及代码尚未优化等。
本文将展示如何在 Hugging Face Diffusers 库中使用 AudioLDM 2,并在此基础上探索一系列代码优化 (如半精度、Flash 注意力、图编译) 以及模型级优化 (如选择合适的调度器及反向提示)。最终我们将推理时间降低了 10 倍 多,且对输出音频质量的影响最低。本文还附有一个更精简的 Colab notebook,这里面包含所有代码但精简了很多文字部分。
最终,我们可以在短短 1 秒内生成一个 10 秒的音频!
模型概述
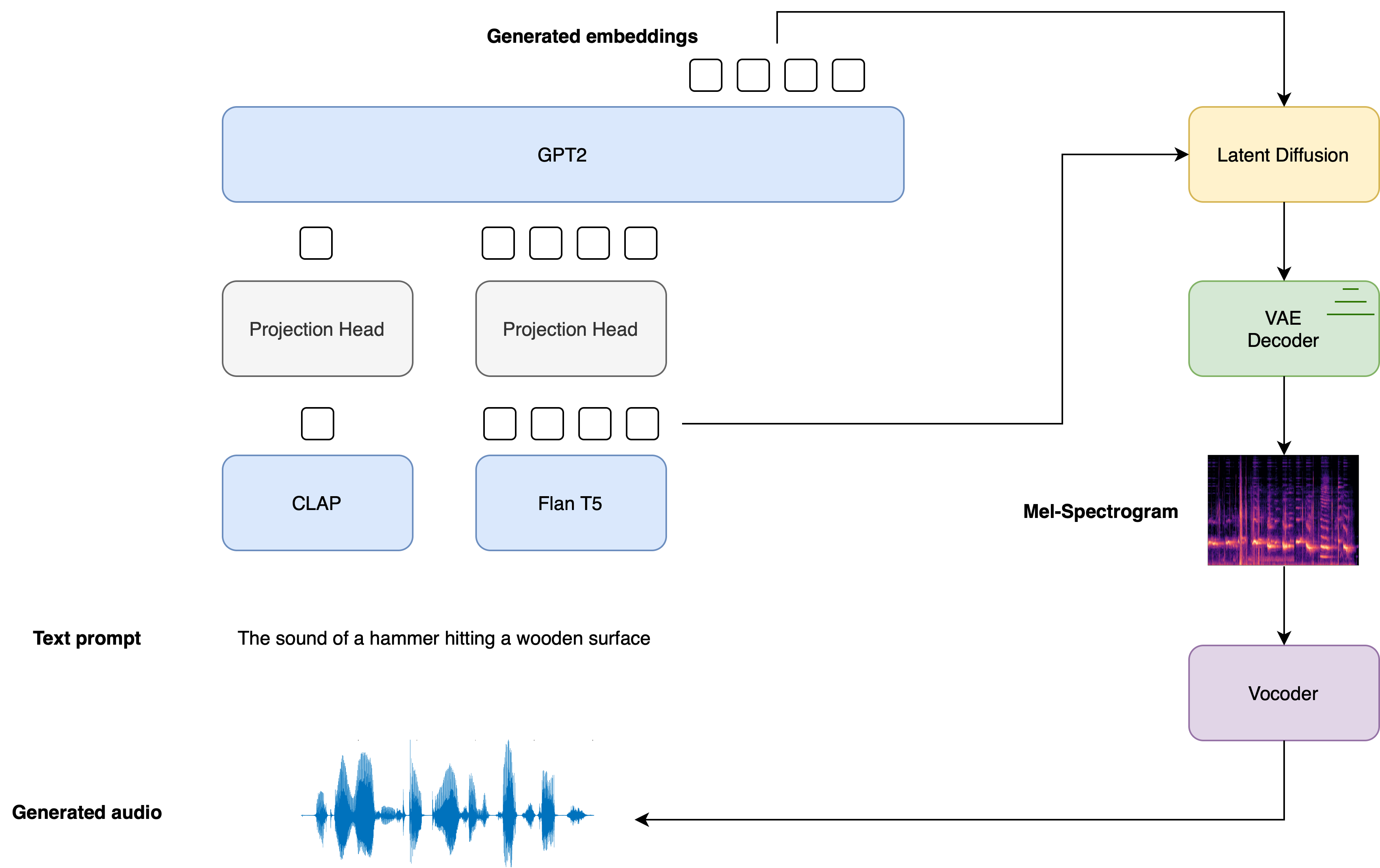
受 Stable Diffusion 的启发,AudioLDM 2 是一种文生音频的 _ 隐扩散模型 (latent diffusion model,LDM)_,其可以将文本嵌入映射成连续的音频表征。
大体的生成流程总结如下:
给定输入文本 \(\boldsymbol{x}\),使用两个文本编码器模型来计算文本嵌入: CLAP 的文本分支,以及 Flan-T5 的文本编码器。
\[\boldsymbol{E} _{1} = \text{CLAP}\left(\boldsymbol{x} \right); \quad \boldsymbol{E}_ {2} = \text{T5}\left(\boldsymbol{x}\right)
\]CLAP 文本嵌入经过训练,可以与对应的音频嵌入对齐,而 Flan-T5 嵌入可以更好地表征文本的语义。
这些文本嵌入通过各自的线性层投影到同一个嵌入空间:
\[\boldsymbol{P} _{1} = \boldsymbol{W}_ {\text{CLAP}} \boldsymbol{E} _{1}; \quad \boldsymbol{P}_ {2} = \boldsymbol{W} _{\text{T5}}\boldsymbol{E}_ {2}
\]在
diffusers实现中,这些投影由 AudioLDM2ProjectionModel 定义。使用 GPT2 语言模型 (LM) 基于 CLAP 和 Flan-T5 嵌入自回归地生成一个含有 \(N\) 个嵌入向量的新序列:
\[\tilde{\boldsymbol{E}} _{i} = \text{GPT2}\left(\boldsymbol{P}_ {1}, \boldsymbol{P} _{2}, \tilde{\boldsymbol{E}}_ {1:i-1}\right) \qquad \text{for } i=1,\dots,N
\]以生成的嵌入向量 \(\tilde{\boldsymbol{E}} _{1:N}\) 和 Flan-T5 文本嵌入 \(\boldsymbol{E}_ {2}\) 为条件,通过 LDM 的反向扩散过程对随机隐变量进行 去噪 。LDM 在反向扩散过程中运行 \(T\) 个步推理:
\[\boldsymbol{z} _{t} = \text{LDM}\left(\boldsymbol{z}_ {t-1} | \tilde{\boldsymbol{E}} _{1:N}, \boldsymbol{E}_ {2}\right) \qquad \text{for } t = 1, \dots, T
\]其中初始隐变量 \(\boldsymbol{z} _{0}\) 是从正态分布 \(\mathcal{N} \left(\boldsymbol{0}, \boldsymbol{I} \right )\) 中采样而得。 LDM 的 UNet 的独特之处在于它需要 两组 交叉注意力嵌入,来自 GPT2 语言模型的 \(\tilde{\boldsymbol{E}}_ {1:N}\) 和来自 Flan-T5 的 \(\boldsymbol{E}_{2}\),而其他大多数 LDM 只有一个交叉注意力条件。
把最终去噪后的隐变量 \(\boldsymbol{z}_{T}\) 传给 VAE 解码器以恢复梅尔谱图 \(\boldsymbol{s}\):
\[\boldsymbol{s} = \text{VAE} _{\text{dec}} \left(\boldsymbol{z}_ {T}\right)
\]梅尔谱图被传给声码器 (vocoder) 以获得输出音频波形 \(\mathbf{y}\):
\[\boldsymbol{y} = \text{Vocoder}\left(\boldsymbol{s}\right)
\]
下图展示了文本输入是如何作为条件传递给模型的,可以看到在 LDM 中两个提示嵌入均被用作了交叉注意力的条件:
有关如何训练 AudioLDM 2 模型的完整的详细信息,读者可以参阅 AudioLDM 2 论文。
Hugging Face Diffusers 提供了一个端到端的推理流水线类 AudioLDM2Pipeline 以将该模型的多阶段生成过程包装到单个可调用对象中,这样用户只需几行代码即可完成从文本生成音频的过程。
AudioLDM 2 有三个变体。其中两个 checkpoint 适用于通用的文本到音频生成任务,第三个 checkpoint 专门针对文本到音乐生成。三个官方 checkpoint 的详细信息请参见下表,这些 checkpoint 都可以在 Hugging Face Hub 上找到:
| checkpoint | 任务 | 模型大小 | 训练数据(单位:小时) |
|---|---|---|---|
| cvssp/audioldm2 | 文生音频 | 1.1B | 1150k |
| cvssp/audioldm2-music | 文生音乐 | 1.1B | 665k |
| cvssp/audioldm2-large | 文生音频 | 1.5B | 1150k |
至此,我们已经全面概述了 AudioLDM 2 生成的工作原理,接下来让我们将这一理论付诸实践!
加载流水线
我们以基础版模型 cvssp/audioldm2 为例,首先使用 .from_pretrained 方法来加载整个管道,该方法会实例化管道并加载预训练权重:
from diffusers import AudioLDM2Pipeline
model_id = "cvssp/audioldm2"
pipe = AudioLDM2Pipeline.from_pretrained(model_id)
输出:
Loading pipeline components...: 100%|███████████████████████████████████████████| 11/11 [00:01<00:00, 7.62it/s]
与 PyTorch 一样,使用 to 方法将流水线移至 GPU:
pipe.to("cuda");
现在,我们来定义一个随机数生成器并固定一个种子,我们可以通过这种方式来固定 LDM 模型中的起始隐变量从而保证结果的可复现性,并可以观察不同提示对生成过程和结果的影响:
import torch
generator = torch.Generator("cuda").manual_seed(0)
现在,我们准备好开始第一次生成了!本文中的所有实验都会使用固定的文本提示以及相同的随机种子来生成音频,并比较不同方案的延时和效果。 audio_length_in_s 参数主要控制所生成音频的长度,这里我们将其设置为默认值,即 LDM 训练时的音频长度: 10.24 秒:
prompt = "The sound of Brazilian samba drums with waves gently crashing in the background"
audio = pipe(prompt, audio_length_in_s=10.24, generator=generator).audios[0]
输出:
100%|███████████████████████████████████████████| 200/200 [00:13<00:00, 15.27it/s]
酷!我们花了大约 13 秒最终生成出了音频。我们来听一下:
from IPython.display import Audio
Audio(audio, rate=16000)
请 阅读英文原文 听取音频附件
听起来跟我们的文字提示很吻合!质量很好,但是有一些背景噪音。我们可以为流水线提供 反向提示 (negative prompt),以防止其生成的音频中含有某些不想要特征。这里,我们给模型一个反向提示,以防止模型生成低质量的音频。我们不设 audio_length_in_s 参数以使用其默认值:
negative_prompt = "Low quality, average quality."
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
输出:
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.50it/s]
使用反向提示 \({}^1\) 时,推理时间不变; 我们只需将 LDM 的无条件输入替换为反向提示即可。这意味着我们在音频质量方面获得的任何收益都是免费的。
我们听一下生成的音频:
Audio(audio, rate=16000)
请 阅读英文原文 听取音频附件
显然,整体音频质量有所改善 - 噪声更少,并且音频整体听起来更清晰。
\({}^1\) 请注意,在实践中,我们通常会看到第二次生成比第一次生成所需的推理时间有所减少。这是由于我们第一次运行计算时 CUDA 被“预热”了。因此一般进行基准测试时我们会选择第二次推理的时间作为结果。
优化 1: Flash 注意力
PyTorch 2.0 及更高版本包含了一个优化过的内存高效的注意力机制的实现,用户可通过 torch.nn.function.scaled_dot_product_attention (SDPA) 函数来调用该优化。该函数会根据输入自动使能多个内置优化,因此比普通的注意力实现运行得更快、更节省内存。总体而言,SDPA 函数的优化与 Dao 等人在论文 Fast and Memory-Efficient Exact Attention with IO-Awareness 中所提出的 flash 注意力 类似。
如果安装了 PyTorch 2.0 且 torch.nn.function.scaled_dot_product_attention 可用,Diffusers 将默认启用该函数。因此,仅需按照 官方说明 安装 torch 2.0 或更高版本,不需对流水线作任何改动,即能享受提速。
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
输出:
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.60it/s]
有关在 diffusers 中使用 SDPA 的更多详细信息,请参阅相应的 文档。
优化 2: 半精度
默认情况下, AudioLDM2Pipeline 以 float32 (全) 精度方式加载模型权重。所有模型计算也以 float32 精度执行。对推理而言,我们可以安全地将模型权重和计算转换为 float16 (半) 精度,这能改善推理时间和 GPU 内存,同时对生成质量的影响微乎其微。
我们可以通过将 from_pretrained 的 torch_dtype 参数设为 torch.float16 来加载半精度权重:
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda");
我们运行一下 float16 精度的生成,并听一下输出:
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
Audio(audio, rate=16000)
输出:
100%|███████████████████████████████████████████| 200/200 [00:09<00:00, 20.94it/s]
请 阅读英文原文 听取音频附件
音频质量与全精度生成基本没有变化,推理加速了大约 2 秒。根据我们的经验,使用具有 float16 精度的 diffusers 流水线,我们可以获得显著的推理加速而无明显的音频质量下降。因此,我们建议默认使用 float16 精度。
优化 3: Torch Compile
为了获得额外的加速,我们还可以使用新的 torch.compile 功能。由于在流水线中 UNet 通常计算成本最高,因此我们用 torch.compile 编译一下 UNet,其余子模型 (文本编码器和 VAE) 保持不变:
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
用 torch.compile 包装 UNet 后,由于编译 UNet 的开销,我们运行第一步推理时通常会很慢。所以,我们先运行一步流水线预热,这样后面真正运行的时候就快了。请注意,第一次推理的编译时间可能长达 2 分钟,请耐心等待!
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
输出:
100%|███████████████████████████████████████████| 200/200 [01:23<00:00, 2.39it/s]
很棒!现在 UNet 已编译完毕,现在可以以更快的速度运行完整的扩散过程了:
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
输出:
100%|███████████████████████████████████████████| 200/200 [00:04<00:00, 48.98it/s]
只需 4 秒即可生成!在实践中,你只需编译 UNet 一次,然后就可以为后面的所有生成赢得一个更快的推理。这意味着编译模型所花费的时间可以由后续推理时间的收益所均摊。有关 torch.compile 的更多信息及选项,请参阅 torch compile 文档。
优化 4: 调度器
还有一个选项是减少推理步数。选择更高效的调度器可以帮助减少步数,而不会牺牲输出音频质量。你可以调用 schedulers.compatibles 属性来查看哪些调度器与 AudioLDM2Pipeline 兼容:
pipe.scheduler.compatibles
输出:
[diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler]
好!现在我们有一长串的调度器备选。默认情况下,AudioLDM 2 使用 DDIMScheduler,其需要 200 个推理步才能生成高质量的音频。但是,性能更高的调度程序,例如 DPMSolverMultistepScheduler,只需 20-25 个推理步 即可获得类似的结果。
让我们看看如何将 AudioLDM 2 调度器从 DDIM 切换到 DPM Multistep 。我们需要使用 ConfigMixin.from_config() 方法以用原始 DDIMScheduler 的配置来加载 DPMSolverMultistepScheduler:
from diffusers import DPMSolverMultistepScheduler
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
让我们将推理步数设为 20,并使用新的调度器重新生成。由于 LDM 隐变量的形状未更改,因此我们不必重编译:
audio = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
输出:
100%|███████████████████████████████████████████| 20/20 [00:00<00:00, 49.14it/s]
这次只用了不到 1 秒 就生成了音频!我们听下它的生成:
Audio(audio, rate=16000)
请 阅读英文原文 听取音频附件
生成质量与原来的基本相同,但只花了原来时间的一小部分! Diffusers 流水线是“可组合”的,这个设计允许你轻松地替换调度器或其他组件以获得更高性能。
内存消耗如何?
我们想要生成的音频的长度决定了 LDM 中待去噪的隐变量的 宽度 。由于 UNet 中交叉注意力层的内存随序列长度 (宽度) 的平方而变化,因此生成非常长的音频可能会导致内存不足错误。我们还可以通过 batch size 来控制生成的样本数,进而控制内存使用。
如前所述,以 float16 半精度加载模型可以节省大量内存。使用 PyTorch 2.0 SDPA 也可以改善内存占用,但这部分改善对超长序列长度来讲可能不够。
我们来试着生成一个 2.5 分钟 (150 秒) 的音频。我们通过设置 num_waveforms_per_prompt =4 来生成 4 个候选音频。一旦 num_waveforms_per_prompt >1 ,在生成的音频和文本提示之间会有一个自动评分机制: 将音频和文本提示嵌入到 CLAP 音频文本嵌入空间中,然后根据它们的余弦相似度得分进行排名。生成的音频中第 0 个音频就是分数“最高”的音频。
由于我们更改了 UNet 中隐变量的宽度,因此我们必须使用新的隐变量形状再执行一次 torch 编译。为了节省时间,我们就不编译了,直接重新加载管道:
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda")
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
输出:
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
<ipython-input-33-c4cae6410ff5> in <cell line: 5>()
3 pipe.to("cuda")
4
----> 5 audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
23 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.95 GiB. GPU 0 has a total capacty of 14.75 GiB of which 1.66 GiB is free. Process 414660 has 13.09 GiB memory in use. Of the allocated memory 10.09 GiB is allocated by PyTorch, and 1.92 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
除非你的 GPU 显存很大,否则上面的代码可能会返回 OOM 错误。虽然 AudioLDM 2 流水线涉及多个组件,但任何时候只有当前正在使用的模型必须在 GPU 上。其余模块均可以卸载到 CPU。该技术称为“CPU 卸载”,可大大减少显存使用,且对推理时间的影响很小。
我们可以使用函数 enable_model_cpu_offload() 在流水线上启用 CPU 卸载:
pipe.enable_model_cpu_offload()
调用 API 生成音频的方式与以前相同:
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
输出:
100%|███████████████████████████████████████████| 20/20 [00:36<00:00, 1.82s/it]
这样,我们就可以生成 4 个各为 150 秒的样本,所有这些都在一次流水线调用中完成!大版的 AudioLDM 2 checkpoint 比基础版的 checkpoint 总内存使用量更高,因为 UNet 的大小相差两倍多 (750M 参数与 350M 参数相比),因此这种节省内存的技巧对大版的 checkpoint 特别有用。
总结
在本文中,我们展示了 Diffusers 开箱即用的四种优化方法,并将 AudioLDM 2 的生成时间从 14 秒缩短到不到 1 秒。我们还重点介绍了如何使用内存节省技巧 (例如半精度和 CPU 卸载) 来减少长音频样本或大 checkpoint 场景下的峰值显存使用量。
本文作者 Sanchit Gandhi 非常感谢 Vaibhav Srivastav 和 Sayak Paul 的建设性意见。频谱图图像来自于 Getting to Know the Mel Spectrogram 一文,波形图来自于 Aalto Speech Processing 一文。
英文原文: https://hf.co/blog/audioldm2
原文作者: Sanchit Gandhi
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
AudioLDM 2,加速!的更多相关文章
- 百度MIP移动页面加速——不只是CDN
MIP是用CDN做加速的么?准确答案是:是,但不只是. MIP全称Mobile Instant Pages,移动网页加速器,是百度提出的页面加速解决方案.MIP从前端渲染和页面网络传输两方面进行优化, ...
- 【初码干货】使用阿里云对Web开发中的资源文件进行CDN加速的深入研究和实践
提示:阅读本文需提前了解的相关知识 1.阿里云(https://www.aliyun.com) 2.阿里云CDN(https://www.aliyun.com/product/cdn) 3.阿里云OS ...
- 阿里云系列——6.给你的域名使用CDN加速(详细步骤+简单配置)
网站部署之~阿里云系列汇总 http://www.cnblogs.com/dunitian/p/4958462.html 进入管理页面:https://home.console.aliyun.com/ ...
- Signalr系列之虚拟目录详解与应用中的CDN加速实战
目录 对SignalR不了解的人可以直接移步下面的目录 SignalR系列目录 前言 前段时间一直有人问我 在用SignalR 2.0开发客服系统[系列1:实现群发通讯]这篇文章中的"/Si ...
- docker学习(2) mac中docker-machine使用vmware fusion以及配置国内镜像加速
一.前言 先回顾下上一节创建docker-machine的过程,默认情况下docker toolbox中的docker-machine使用virtual box创建虚拟机,KI首次启动时创建虚拟机的过 ...
- [转]加速Android Studio/Gradle构建
加速Android Studio/Gradle构建 android android studio gradle 已经使用Android Studio进行开发超过一年,随着项目的增大,依赖库的增多, ...
- 利用免费cdn加速webpack单页应用
回顾现状 在之前的学习过程中,react单页应用经过webpack打包之后会输出大概如下的目录结构,它就是站点的所有前端组成了: 1 2 3 4 5 6 MacBook-Pro:output ba ...
- ffmpeg实现dxva2硬件加速
这几天在做dxva2硬件加速,找不到什么资料,翻译了一下微软的两篇相关文档.这是第二篇,记录用ffmpeg实现dxva2. 第一篇翻译的Direct3D device manager,链接:http: ...
- 用CSS开启硬件加速来提高网站性能
国外一篇文章,有点意思,转载过来,准备尝试下~ 中文地址:http://www.cnblogs.com/rubylouvre/p/3471490.html 原文地址:http://blog.teamt ...
- 迅雷9、迅雷极速版之迅雷P2P加速:流量吸血鬼?为什么你装了迅雷之后电脑会感觉很卡很卡?
原文地址:http://www.whosmall.com/post/90 关闭极速版迅雷ThunderPlatform.exe进程 ThunderPlatform.exe目的:利用P2P技术进行用户间 ...
随机推荐
- linux 使用crontab 创建定时任务
转载请注明出处: 在服务器中需要创建一个定时任务,每天执行去清理很早之前备份的文件,所以想到在linux上创建一个shell脚本,通过linux的 crontab 命令定时去执行该shell脚本,从而 ...
- crazy
说实话刚拿到题目我是一点思路没有,因为我感觉伪代码里面的函数名都太奇怪了,怀疑应该不是在这方面出题,结果看了wp发现就是在这方面出题... 这种情况我是从后面开始看的,看看出现正确提示会需要什么条件 ...
- [CTF/Web] PHP 反序列化学习笔记
Serialize & unserialize 这两个方法为 PHP 中的方法, 参见 serialize 和 unserialize 的官方文档. 以下内容中可能存在 字段, 属性, 成员 ...
- 【scipy 基础】--稀疏矩阵
稀疏矩阵是一种特殊的矩阵,其非零元素数目远远少于零元素数目,并且非零元素分布没有规律.这种矩阵在实际应用中经常出现,例如在物理学.图形学和网络通信等领域. 稀疏矩阵其实也可以和一般的矩阵一样处理,之所 ...
- 字节跳动今日头条-抖音小程序序html富文本显示解决办法
我所知道的,目前很多微信小程序开发者大都使用了"wxParse"的一个小程序端富文本解析代码,但对于开发抖音.今日头条小程序的人来说,貌似官方或者第三方也没有出一个解决html富文 ...
- .net 下优秀的DI框架推荐,看看你用过几个?
在.NET生态系统中,有许多出色的依赖注入(DI)框架可供选择.每个框架都有其独特的特点和优点,可以根据项目需求和偏好进行选择.下面详细介绍一些.NET中优秀的DI框架,它们的优点以及适用场景. 1. ...
- .net下优秀的MQTT框架MQTTnet使用方法,物联网通讯必备
MQTTnet 是一个高性能的MQTT类库,支持.NET Core和.NET Framework. MQTTnet 原理: MQTTnet 是一个用于.NET的高性能MQTT类库,实现了MQTT协议的 ...
- jvm的jshell,学生的工具
jshell 在我眼里,只能作为学校教学的一个玩具,事实上官方也做了解释,以下是官方的解释: 在学习编程语言时,即时反馈很重要,并且 它的 API.学校引用远离Java的首要原因 教学语言是其他语言 ...
- zookeeper JavaApi 查询节点
/** * 1.查询数据 :get * 2.查询子节点 : ls * 3.查询节点的状态信息 :ls -s * * */ @Test public void testGet1() throws Exc ...
- 9 "网址"--URI
目录 URI和URL URI详细介绍 URI的组成 URI的查询参数 URI的编码 疑问 URI和URL URI:统一资源标识符(Uniform Resource Identifier) 有两种形式: ...