大模型必备 - 中文最佳向量模型 acge_text_embedding
近期,上海合合信息科技股份有限公司发布的文本向量化模型 acge_text_embedding 在中文文本向量化领域取得了重大突破,荣获 Massive Text Embedding Benchmark (MTEB) 中文榜单(C-MTEB)第一名的成绩。这一成就标志着该模型将在大模型领域的应用中发挥更加迅速和广泛的影响。

MTEB概述
假设你需要了解如何在家中自制咖啡,可能会在搜索引擎中输入‘家庭咖啡制作方法’。如果没有Embedding模型,传统的引擎会简单地匹配包含关键词的文章,提供一些表面相关的内容而非实用的指南。”团队成员提到,借助Embedding模型,引擎便能更准确地理解用户意图,从而提供包括但不限于选择咖啡豆、磨豆技巧、不同的冲泡方法等更专业的内容。
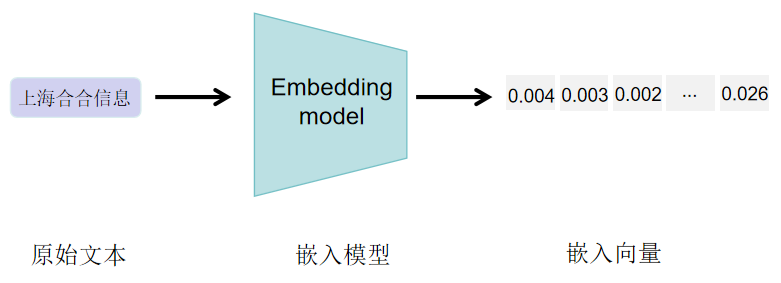
Text Embeddings 文本嵌入是一种将文本转化为包含语义信息的向量表示,因为机器处理信息需要数值输入,因此文本嵌入在许多自然语言处理(NLP)应用中起着至关重要的作用。例如,谷歌就利用文本嵌入来提升其搜索引擎的效能。此外,文本嵌入也可以用于通过聚类发现大量文本中的模式,或作为文本分类模型的输入。然而,文本嵌入的质量高度依赖于所使用的嵌入模型。
为此,Massive Text Embedding Benchmark(MTEB)旨在帮助用户在多种任务中找到最佳的嵌入模型。
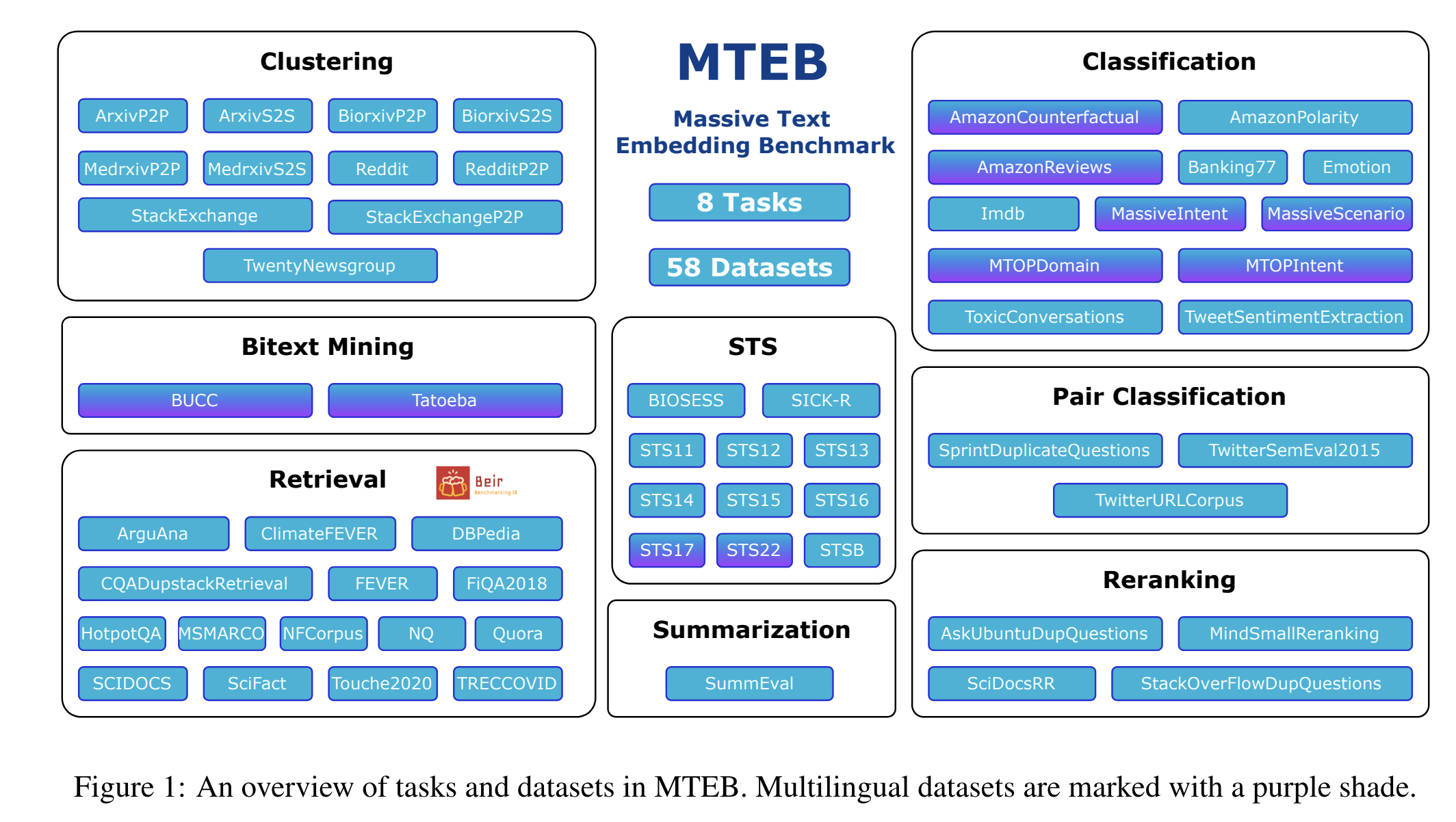
MTEB具备以下特点:
- 广泛性:MTEB包含8个任务领域的56个数据集,并在排行榜上总结了超过2000个结果。
- 多语言支持:MTEB涵盖高达112种不同语言,并对多种多语言模型进行了比特挖掘、分类和语义文本相似度(STS)任务的基准测试。
- 可扩展性:无论是新增任务、数据集、评价指标还是排行榜更新,MTEB都非常欢迎任何贡献。
MTEB榜单
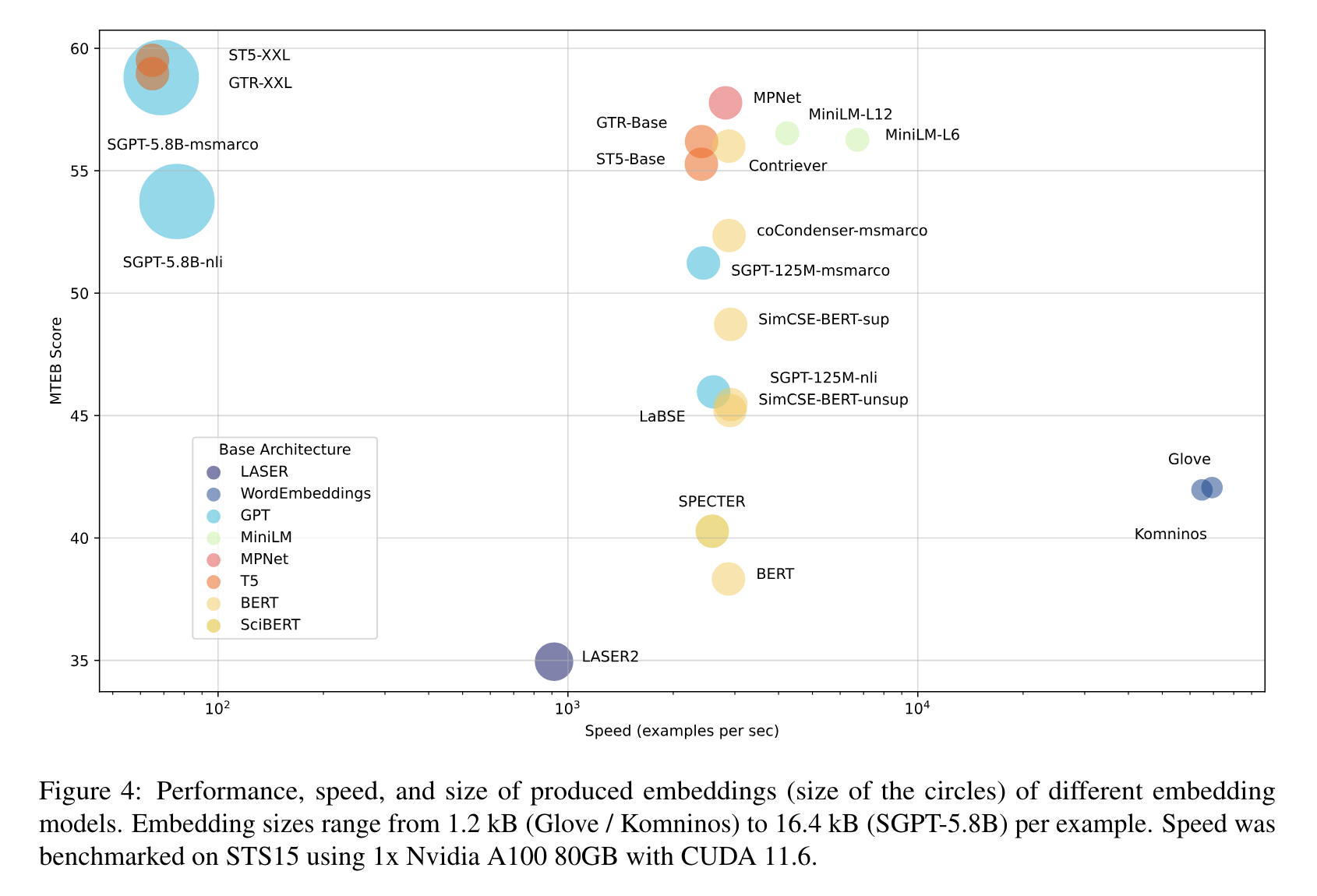
在MTEB的初步基准测试中,关注了以下特点。
- 最高速度:如Glove这类模型提供高速处理能力,但由于缺乏上下文意识,通常在MTEB上的平均得分较低。
- ⚖️ 速度与性能平衡:虽然速度略慢,但性能明显更强,如 all-mpnet-base-v2 或 all-MiniLM-L6-v2,它们在速度和性能之间提供了良好的平衡。
- 最高性能:多亿参数模型如 ST5-XXL、GTR-XXL 或 SGPT-5.8B-msmarco 在MTEB上表现卓越。这些模型往往也会产生较大的嵌入向量,例如SGPT-5.8B-msmarco 生成的4096维嵌入向量需要更多的存储空间!
C-MTEB榜单

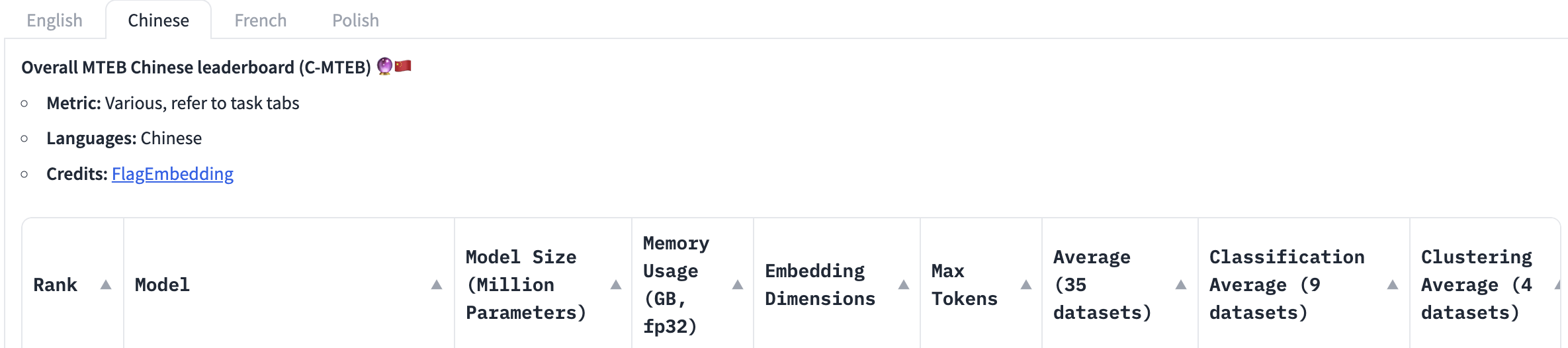
当前最全面的中文语义向量评测基准C-MTEB 开源,涵盖6大类评测任务(检索、排序、句子相似度、推理、分类、聚类),涉及31个相关数据集。
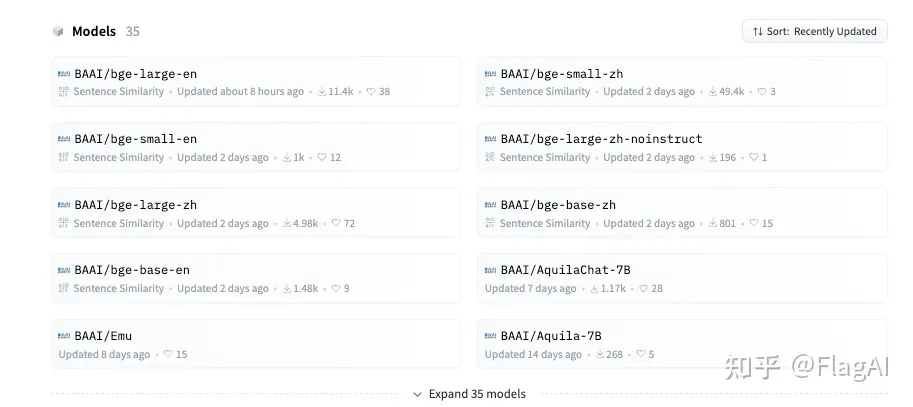
C-MTEB 是当前最大规模、最为全面的中文语义向量评测基准,为可靠、全面的测试中文语义向量的综合表征能力提供了实验基础。
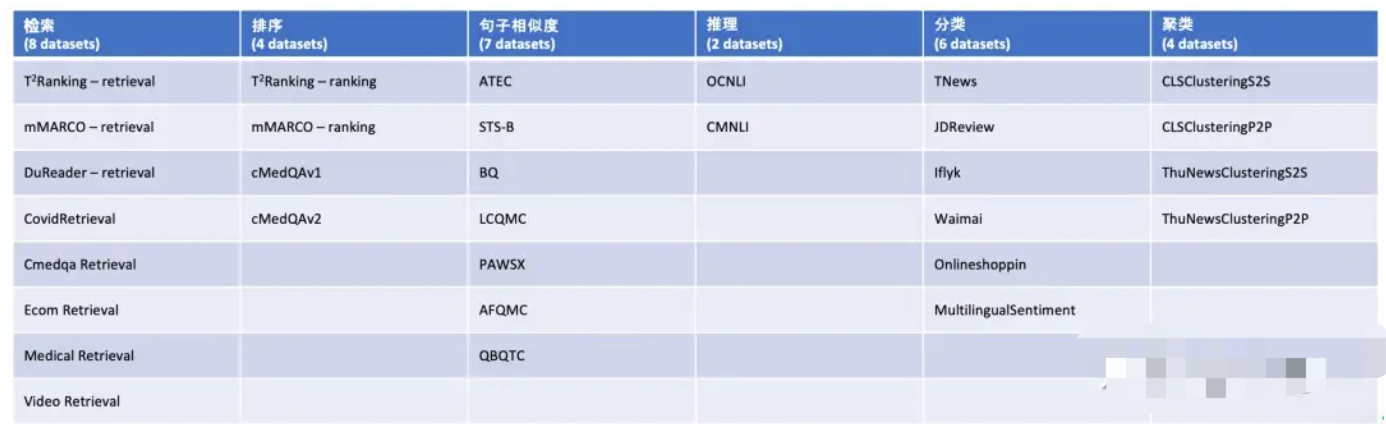
合合信息acge_text_embedding排名C-MTEB榜单第一
acge模型来自于合合信息技术团队,对外技术试用平台TextIn.com。合合信息是行业领先的人工智能及大数据科技企业,致力于通过智能文字识别及商业大数据领域的核心技术、C端和B端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。
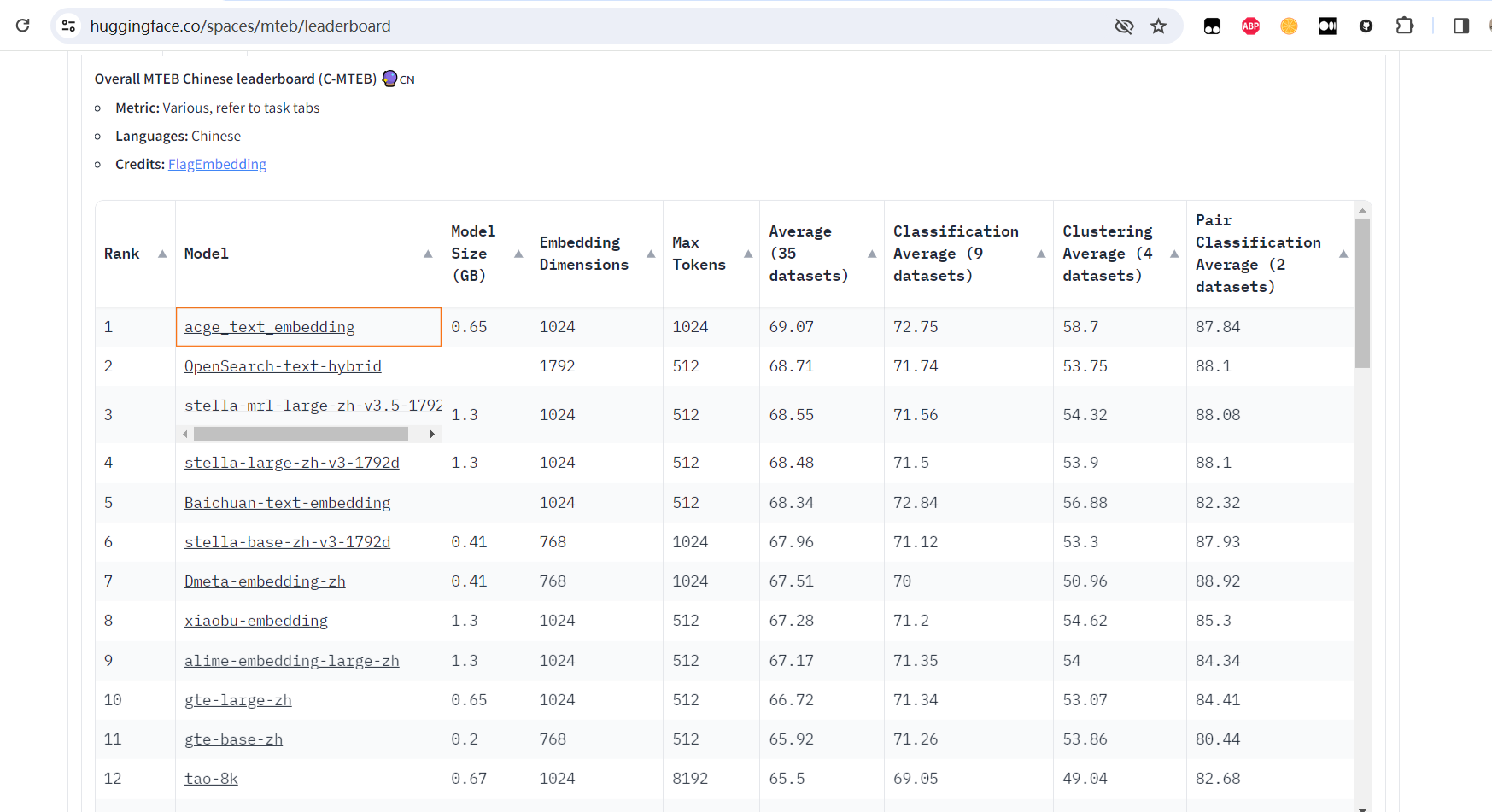
acge是一个通用的文本编码模型,是一个可变长度的向量化模型,使用了Matryoshka Representation Learning,如图所示:

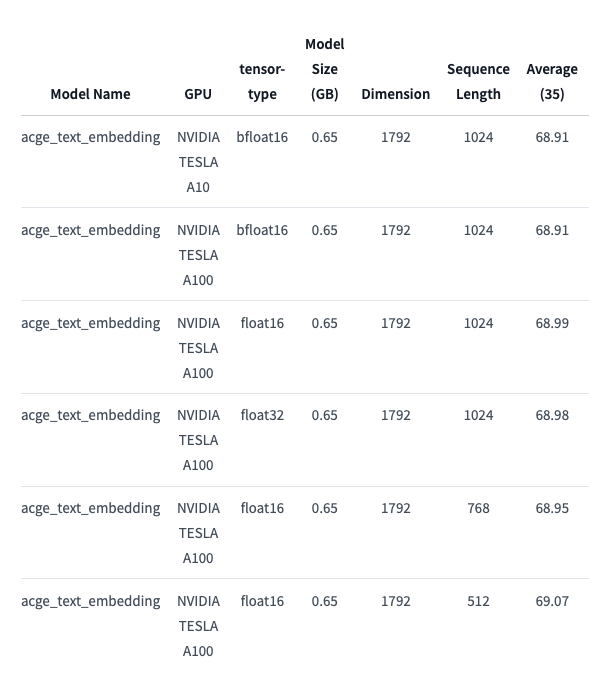
测试的时候因为数据的随机性、显卡、推理的数据类型导致每次推理的结果不一致,总共测试了4次,不同的显卡(A10 A100),不同的数据类型,测试结果放在了result文件夹中,选取了一个精度最低的测试作为最终的精度测试。 根据infgrad的建议,选取不用的输入的长度作为测试,Sequence Length为512时测试最佳。
相比于传统的预训练或微调垂直领域模型,acge模型支持在不同场景下构建通用分类模型、提升长文档信息抽取精度,且应用成本相对较低,可帮助大模型在多个行业中快速创造价值,推动科技创新和产业升级,为构建新质生产力提供强有力的技术支持。
具体实践上,为做好不同任务的针对性学习,团队使用策略学习训练方式,显著提升了检索、聚类、排序等任务上的性能;引入持续学习训练方式,克服了神经网络存在灾难性遗忘的问题,使模型训练迭代能够达到相对优秀的收敛空间;运用MRL技术,实现一次训练,获取不同维度的表征。
与目前C-MTEB榜单上排名前五的开源模型相比,合合信息本次发布的acge模型较小,占用资源少;模型输入文本长度为1024,满足绝大部分场景的需求。此外,acge模型还支持可变输出维度,让企业能够根据具体场景去合理分配资源。
合合信息acge_text_embedding集成实战
在sentence-transformer库中的使用方法:
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
model = SentenceTransformer('acge_text_embedding')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
合合信息TextIn.com
如果对该模型或智能文档处理等技术感兴趣,请访问textin.com。
OCR服务大降价,单次调用仅需0.025元!合合TextIn平台全线推出OCR云服务优惠活动,享单次最低0.025元!包括文字识别、表格识别、证照识别、票据识别及验真、PDF转WORD及图像处理等服务全线下调价格。详情请电脑端进入textin.com市场中查看。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
大模型必备 - 中文最佳向量模型 acge_text_embedding的更多相关文章
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 使用BERT模型生成句子序列向量
之前我写过一篇文章,利用bert来生成token级向量(对于中文语料来说就是字级别向量),参考我的文章:<使用BERT模型生成token级向量>.但是这样做有一个致命的缺点就是字符序列长度 ...
- 词袋模型(BOW,bag of words)和词向量模型(Word Embedding)概念介绍
例句: Jane wants to go to Shenzhen. Bob wants to go to Shanghai. 一.词袋模型 将所有词语装进一个袋子里,不考虑其词法和语序的问题,即每个 ...
- 基于word2vec的文档向量模型的应用
基于word2vec的文档向量模型的应用 word2vec的原理以及训练过程具体细节就不介绍了,推荐两篇文档:<word2vec parameter learning explained> ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
- 使用 TF-IDF 加权的空间向量模型实现句子相似度计算
使用 TF-IDF 加权的空间向量模型实现句子相似度计算 字符匹配层次计算句子相似度 计算两个句子相似度的算法有很多种,但是对于从未了解过这方面算法的人来说,可能最容易想到的就是使用字符串匹配相关的算 ...
- 词向量模型word2vector详解
目录 前言 1.背景知识 1.1.词向量 1.2.one-hot模型 1.3.word2vec模型 1.3.1.单个单词到单个单词的例子 1.3.2.单个单词到单个单词的推导 2.CBOW模型 3.s ...
随机推荐
- 记录--js小练习(弹幕、 电梯导航、 倒计时、 随机点名、 购物放大镜)
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 DOM小练习 弹幕 电梯导航 倒计时 随机点名 购物放大镜 1.弹幕 效果预览 功能:输入弹幕内容,按下回车显示一条弹幕(弹幕颜色.字体随 ...
- Jmeter教程-JMeter 环境安装及配置
JMeter 环境安装及配置 在使用 JMeter 之前,需要配置相应的环境,包括安装JDK和JMeter. 首先,了解一下JDK,它就是Java的开发工具包. JMeter 是使用 Java 编写的 ...
- BlockQNN:NASNet同期,商汤提出block-wise版的MetaQNN | CVPR 2018
作为NASNet的同期论文,BlockQNN同样地将目光从整体网络转换到了block-wise,整体思路大概是MetaQNN的block版,增加了一些细节地小修改.配合Early Stop Strat ...
- KingbaseES kdb_database_link客户端字符集导致的乱码问题
前言 关于我们经常见到的字符集乱码问题,很可能因为数据库服务器端的操作系统字符集和客户端字符集不一致导致的. 当我们通过kdb_database_link插件访问oracle数据库出现乱码,只需要调整 ...
- KingbaseES V8R6 集群环境备库不结束旧事务快照将影响主库的vacuum操作
前言 昨天同事遇到了一个有关vacuum的典型问题. V8R6读写分离集群环境,一主多备. 版本:kingbaseesv008r006c004 问题现象: 主库日常巡检发现日志大量记录: waring ...
- Windows下获取设备管理器列表信息-setupAPI
背景及问题: 在与硬件打交道时,经常需要知道当前设备连接的硬件信息,以便连接正确的硬件,比如串口通讯查询连接的硬件及端口,一般手工的方式就是去设备管理器查看相应的信息,应用程序如何读取这一部分信息呢, ...
- 5 JavaScript变量提升
5 变量提升 看以下代码, 或多或少会有些问题的. function fn(){ console.log(name); var name = '大马猴'; } fn() 发现问题了么. 这么写代码, ...
- 【直播回顾】OpenHarmony知识赋能六期第三课—OpenHarmony智能家居项目之控制面板功能实现
7月14日晚上19点,知识赋能第六期第三节直播 <OpenHarmony智能家居项目之控制面板功能实现> ,在OpenHarmony开发者成长计划社群内成功举行. 本次直播是"O ...
- Python调用动态库,获取BSTR字符串
今天客户在用Python调用我们的动态库的时候,遇到一个问题,调用动态库中的函数,函数返回的是BSTR字符串,但是客户接收到的是一个8位长度的数字. 动态库函数原型:EXTERN_C BSTR ELO ...
- loguru 简单使用
使用Python自带的 logging 来记录日志会比较麻烦,查了下 大家都在用 loguru,看了下文档,发现是挺好用的,记录下笔记 安装 pip install loguru 简单使用 f ...