【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
一、爬虫对象-豆瓣读书TOP250
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣读书TOP250排行榜数据:
https://book.douban.com/top250
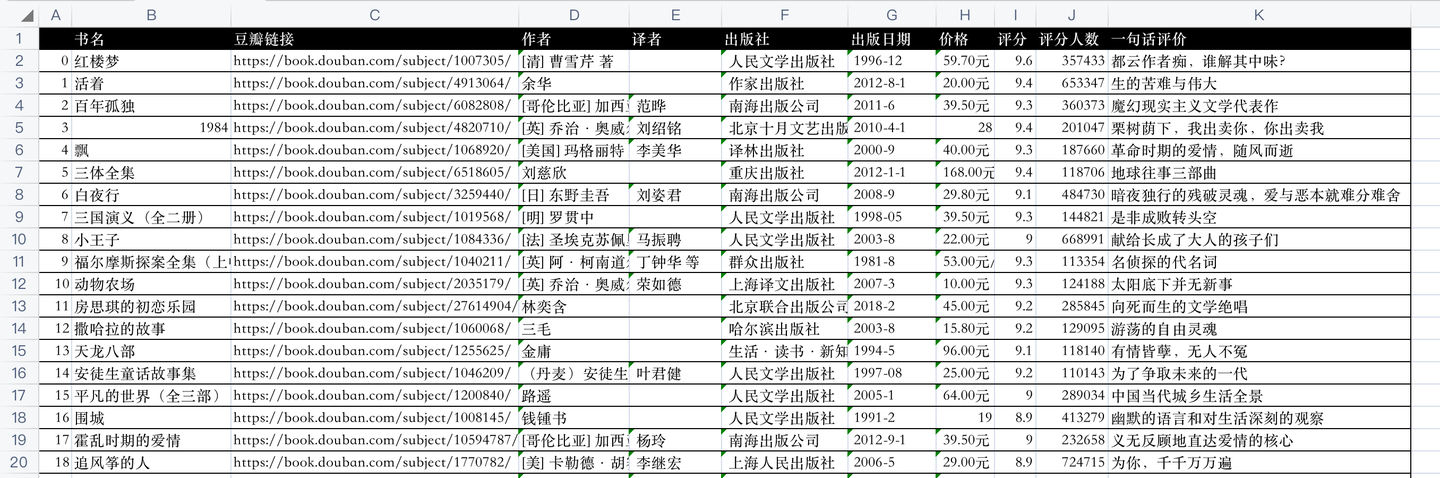
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣读书网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = book.select('.pl2 a')[0]['title'] # 书名
book_name.append(name)
bkurl = book.select('.pl2 a')[0]['href'] # 书籍链接
book_url.append(bkurl)
star = book.select('.rating_nums')[0].text # 书籍评分
book_star.append(star)
star_people = book.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
book_star_people.append(star_people)
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['书名'] = book_name
df['豆瓣链接'] = book_url
df['作者'] = book_author
df['译者'] = book_translater
df['出版社'] = book_publisher
df['出版日期'] = book_pub_year
df['价格'] = book_price
df['评分'] = book_star
df['评分人数'] = book_star_people
df['一句话评价'] = book_comment
df.to_csv(csv_name, encoding='utf8') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
三、讲解视频
同步讲解视频:https://www.zhihu.com/zvideo/1464515550177546240
四、完整源码
附完整源代码:【python爬虫案例】利用python爬虫爬取豆瓣读书TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣读书TOP250排行榜!的更多相关文章
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- 豆瓣读书top250数据爬取与可视化
爬虫–scrapy 题目:根据豆瓣读书top250,根据出版社对书籍数量分类,绘制饼图 搭建环境 import scrapy import numpy as np import pandas as p ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
随机推荐
- AndroidStudio开发体温上报安卓APP------问题总结
总结一下出现的问题: 1.首先是AndroidStudio的配置问题 在这里可以看sdk版本配置 这里可以看gradle的版本信息和下载目录 AndroidStudio手动配置gradle 1.首先编 ...
- #团,构造#洛谷 3524 [POI2011]IMP-Party
题目 有一个 \(3n\) 个点的无向图,保证有一个大小为 \(2n\) 的团,输出一个大小为 \(n\) 的团 分析 每次选择两个不相连的点删掉,那么剩下的 \(n\) 个点一定是团, 因为每次至少 ...
- #李超线段树 or 斜率优化+CDQ分治#洛谷 4655 [CEOI2017]Building Bridges
题目 分析 列出方程即为\(dp[i]=\min\{dp[j]+(h[i]-h[j])^2+s[i-1]-s[j]\}\) \(dp[j]+h[j]^2-s[j]=2*h[i]*h[j]+dp[i]- ...
- 深入解析 Java 面向对象编程与类属性应用
Java 面向对象编程 面向对象编程 (OOP) 是一种编程范式,它将程序组织成对象.对象包含数据和操作数据的方法. OOP 的优势: 更快.更易于执行 提供清晰的结构 代码更易于维护.修改和调试 提 ...
- HarmonyOS应用窗口管理(Stage模型)
一. 窗口开发概述 窗口模块的定义 窗口模块用于在同一块物理屏幕上,提供多个应用界面显示.交互的机制. ● 对应用开发者而言,窗口模块提供了界面显示和交互能力. ● 对终端用户而言,窗口模块提供 ...
- 在 Google Cloud 上轻松部署开放大语言模型
今天,我们想向大家宣布:"在 Google Cloud 上部署"功能正式上线! 这是 Hugging Face Hub 上的一个新功能,让开发者可以轻松地将数千个基础模型使用 Ve ...
- HH的项链—树状数组
题目描述 HH有一串由各种漂亮的贝壳组成的项链.HH相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义. HH不断地收集新的贝壳,因此他的项链变得越来越长.有一天 ...
- MMDeploy部署实战系列【第一章】:Docker,Nvidia-docker安装
MMDeploy部署实战系列[第一章]:Docker,Nvidia-docker安装 这个系列是一个随笔,是我走过的一些路,有些地方可能不太完善.如果有那个地方没看懂,评论区问就可以,我给补充. 版权 ...
- Java实现学生投票系统
"感谢您阅读本篇博客!如果您觉得本文对您有所帮助或启发,请不吝点赞和分享给更多的朋友.您的支持是我持续创作的动力,也欢迎留言交流,让我们一起探讨技术,共同成长!谢谢!" 代码 im ...
- 力扣1076(MySQL)-员工项目Ⅱ(简单)
题目: 编写一个SQL查询,报告所有雇员最多的项目. 查询结果格式如下所示: 解题思路: 方法一:将两个表联结,以project_id进行分组,统计员工数降序排序,然后筛选出第一条数据. 1 sel ...