在进行神经网络训练时需要使用的显存空间大小的预估——300MB的神经网络在训练时最少需要占用多大的显存空间
以Tensorflow为例。
=======================================
神经网络(TensorFlow举例)在GPU中训练时需要占用的内存大概有下面几部分组成:
1. TensorFlow的自身的计算库导入显存时所在内存,一般在session初始化时就会自动导入,这部分大小与TensorFlow的版本有关,这里大概估计普遍为450MB大小;
2. 神经网络的本身模型大小;
3. 优化器对神经网络模型进行优化时自身参数大小,一般一阶优化器的自身参数大小和神经网络模型本身大小相同,二阶优化器一般为模型本身大小的两倍(如:RMSProp优化器);
4. 神经网络前向计算时所产生的临时Tensor,这部分Tensor需要被临时保存,以便在反传计算梯度时使用,这部分Tensor的大小和模型的每一层结构形状有关(必须根据具体模型的每层形状来计算)也和具体的batch_size大小以及输入数据input_data的大小有关;
5. 神经网络向后性计算时被人为设定的一些负责监督运行状态或其他操作的Tensor,如:某些层的反传计算出的梯度进行正则化后或进行求mean/std/max/min等操作产生的Tensor,某些层前传时计算该层输出的一些统计Tensor(求mean/std/max/min等操作产生的Tensor);
--------------------------------------------
在估计一个模型在训练时所需的显存空间一般可以考虑将上面1, 2, 3部分的大小加总即可;4部分的大小难以计算,毕竟这个大小还和输入数据的大小和batch_size有关,而且每层的输出结构也是差异极大的;5部分的大小一般有限,可以不主要考虑。
PS:
这里需要说明一下,有些时候我们在跑模型训练的时候发现显存不够报错的时候我们可以通过调小batch_size的方式来解决,这时候我们就是通过调小第4部分显存大小来解决的;但是有些时候即使把batch_size设置为1也无法满足,那么就应该是第1,2,3部分所占显存空间已经超出了可用空间大小。
--------------------------------------------
关于第一部分显存大小,下面给出TensorFlow1.14版本的情况:


查看显存占用:

可以看到导入库后所占显存大小为104MB。
--------------------------------------------
关于第2, 3部分的大小,我们使用例子:(只给出项目中进行修改的文件)
https://gitee.com/devilmaycry812839668/paac/blob/master/actor_learner.py
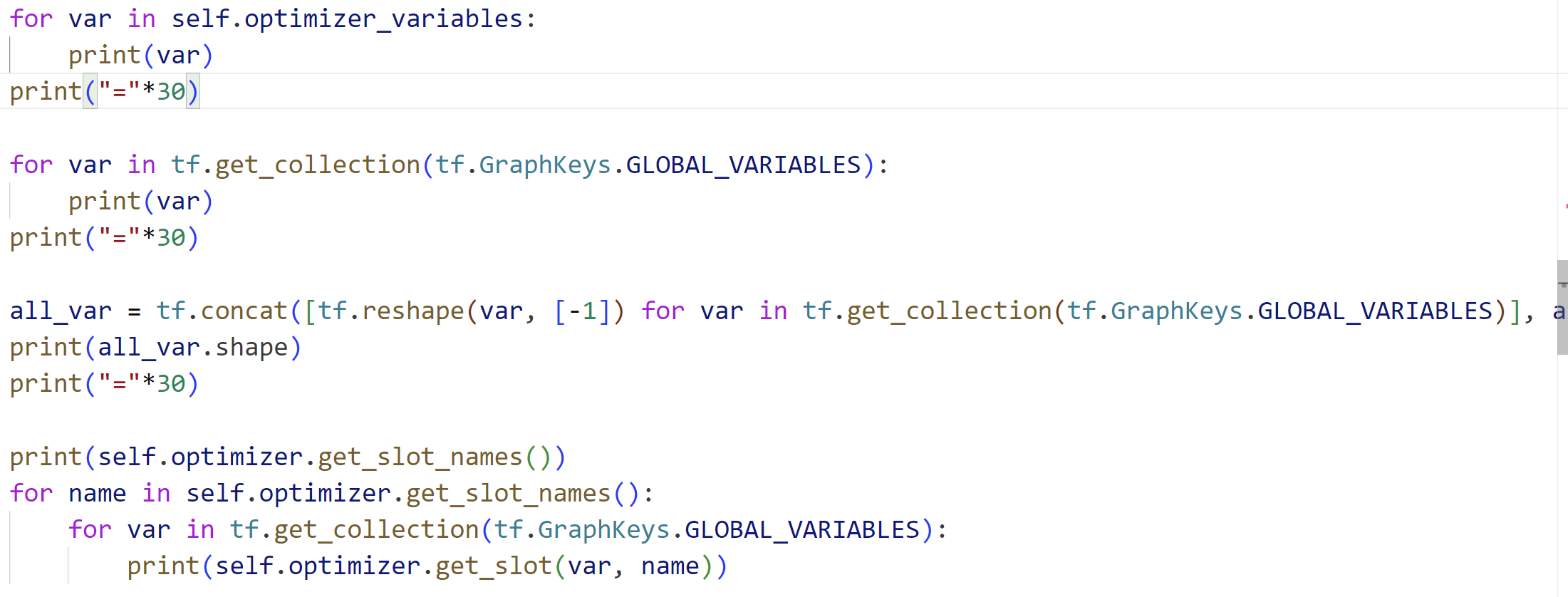
我们在__init__函数中添加下面代码:
for var in self.optimizer_variables:
print(var)
print("="*30) for var in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES):
print(var)
print("="*30) all_var = tf.concat([tf.reshape(var, [-1]) for var in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)], axis=0)
print(all_var.shape)
print("="*30) print(self.optimizer.get_slot_names())
for name in self.optimizer.get_slot_names():
for var in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES):
print(self.optimizer.get_slot(var, name))
运行结果:
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables_1:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables_1:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables_1:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables_1:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables_1:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables_1:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables_1:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables_1:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables_1:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables_1:0' shape=(1,) dtype=float32_ref>
==============================
<tf.Variable 'local_learning_1/conv1_weights:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables_1:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables_1:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables_1:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables_1:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables_1:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables_1:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables_1:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables_1:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables_1:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables_1:0' shape=(1,) dtype=float32_ref>
==============================
(2033829,)
==============================
['momentum', 'rms']
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables_1:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables_1:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables_1:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables_1:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables_1:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables_1:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables_1:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables_1:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables_1:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables_1:0' shape=(1,) dtype=float32_ref>
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables:0' shape=(1,) dtype=float32_ref>
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
None
通过结果我们可以知道,第2部分显存为模型的参数,即10个Tensor Variable所占,第3部分为20个针对模型参数的优化器参数,即20个Tensor Variable所占;其中模型参数(10个Variable)大小总共为(MB):

优化器的参数时模型参数的两倍,所以总共的Variable参数为3倍的模型参数(MB):

模型参数,10个Variable:
<tf.Variable 'local_learning_1/conv1_weights:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases:0' shape=(1,) dtype=float32_ref>
优化器参数(二阶),20个Variable:
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables_1:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables_1:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables_1:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables_1:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables_1:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables_1:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables_1:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables_1:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables_1:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables:0' shape=(1,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables_1:0' shape=(1,) dtype=float32_ref>
其中,这20个优化器参数在槽['momentum']中的有:
<tf.Variable 'local_learning_1/conv1_weights/OptimizerVariables_1:0' shape=(8, 8, 4, 16) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables_1:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables_1:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables_1:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables_1:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables_1:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables_1:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables_1:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables_1:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables_1:0' shape=(1,) dtype=float32_ref>
其中,这20个优化器参数在槽['rms']中的有:
<tf.Variable 'local_learning_1/conv1_biases/OptimizerVariables:0' shape=(16,) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_weights/OptimizerVariables:0' shape=(4, 4, 16, 32) dtype=float32_ref>
<tf.Variable 'local_learning_1/conv2_biases/OptimizerVariables:0' shape=(32,) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_weights/OptimizerVariables:0' shape=(2592, 256) dtype=float32_ref>
<tf.Variable 'local_learning_1/fc3_biases/OptimizerVariables:0' shape=(256,) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_weights/OptimizerVariables:0' shape=(256, 6) dtype=float32_ref>
<tf.Variable 'local_learning_2/actor_output_biases/OptimizerVariables:0' shape=(6,) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_weights/OptimizerVariables:0' shape=(256, 1) dtype=float32_ref>
<tf.Variable 'local_learning_2/critic_output_biases/OptimizerVariables:0' shape=(1,) dtype=float32_ref>
判断优化器中参数是否可以训练:



查询结果:

------------------------------------------------------
可以看到,在例子中,第2部分和第3部分的显存大小共为:7.7584MB
而第1部分的显存占用为104MB,那么我们运行下例子所在的项目,看下总共在训练时占用显存大小:

由此我们可以知道,即使是一些模型大小特别小的模型(模型参数加优化器参数共7.7584MB)也可以在运行时占用大量显存,这时候所占用显存的主要为第4部分和第5部分所占,我们将batch_size设置为1,然后再看下:
此时项目启动命令:python3 train.py -g pong -df logs/ -ec 1 -ew 1 --max_local_steps 1

PS:
通过这个例子,我们可以知道,即使一个模型特别小(优化器参数也随之很小,共7.7584MB),但是计算过程中所需导入显存的lib库和训练过程中产生的临时Tensor、用于检测的Tensor所占的空间大小也可以是很大的,甚至是近百倍于模型参数大小;所以说一个模型在训练过程中所需最小显存空间并不由模型参数大小所完全决定,有时候训练过程中的临时Tensor大小会大于模型参数大小;通过修改batch_size可以缩小训练过程中的临时Tensor大小,但是这个缩小程度毕竟有限,例子中通过减小batch size所获增加的空余显存空间为832-592=240MB。
------------------------------------------------------
RMSProp优化器:

参考:
https://www.coder.work/article/93009
=======================================
在进行神经网络训练时需要使用的显存空间大小的预估——300MB的神经网络在训练时最少需要占用多大的显存空间的更多相关文章
- 交叉熵代价函数——当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢
交叉熵代价函数 machine learning算法中用得很多的交叉熵代价函数. 1.从方差代价函数说起 代价函数经常用方差代价函数(即采用均方误差MSE),比如对于一个神经元(单输入单输出,sigm ...
- 用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列。
数据库中有A B C三列,用SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列. 方法一: select (case when a>b then a el ...
- 设置一个div网页滚动时,使其固定在头部,当页面滚动到距离头部300px时,隐藏该div,另一个div在底部,此时显示;当页面滚动到起始位置时,头部div出现,底部div隐藏
设置一个div网页滚动时,使其固定在头部,当页面滚动到距离头部300px时,隐藏该div,另一个div在底部,此时显示: 当页面滚动到起始位置时,头部div出现,底部div隐藏 前端代码: <! ...
- 在mvc返回JSON时出错:序列化类型为“System.Data.Entity.DynamicProxies.Photos....这个会的对象时检测到循环引用 的解决办法
在MVC中返回JSON时出错,序列化类型为“System.Data.Entity.DynamicProxies.Photos....这个会的对象时检测到循环引用. public ActionResul ...
- 题目:企业发放的奖金根据利润提成。 利润(I)低于或等于10万元时,奖金可提10%; 利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提成7.5%; 20万到40万之间时,高于20万元的部分,可提成5%; 40万到60万之间时高于40万元的部分,可提成 3%; 60万到100万之间时,高于60万元的部分,可提成1.5%; 高于100万元时,超过
题目:企业发放的奖金根据利润提成. 利润(I)低于或等于10万元时,奖金可提10%: 利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提成7.5%: 20万到 ...
- SQL语句实现:当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列
分享一道今天的面试题:SQL语句实现:数据库中有A B C三列,当A列大于B列时选择A列否则选择B列,当B列大于C列时选择B列否则选择C列 第一种:使用case when...then...else ...
- 代码实现:企业发放的奖金根据利润提成。利润(I)低于或等于10万元时,奖金可提10%; 利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提成7.5%; 20万到40万之间时,高于20万元的部分,可提成5%;40万到60万之间时高于40万元的部分,可提成3%; 60万到100万之间时,高于60万元的部分,可提成1.5%,高于100万元时,超过100万元
import java.util.Scanner; /* 企业发放的奖金根据利润提成.利润(I)低于或等于10万元时,奖金可提10%: 利润高于10万元,低于20万元时,低于10万元的部分按10%提成 ...
- iOS开发之UIImage在压缩时失真问题,压缩图片的大小
今天遇到UIImage在压缩时失真问题,压缩图片的大小图片模糊 错误的方案 /** * 压缩图片 * image:将要压缩的图片 size:压缩后的尺寸 */ -(UIImage*) OriginIm ...
- 深度学习原理与框架-猫狗图像识别-卷积神经网络(代码) 1.cv2.resize(图片压缩) 2..get_shape()[1:4].num_elements(获得最后三维度之和) 3.saver.save(训练参数的保存) 4.tf.train.import_meta_graph(加载模型结构) 5.saver.restore(训练参数载入)
1.cv2.resize(image, (image_size, image_size), 0, 0, cv2.INTER_LINEAR) 参数说明:image表示输入图片,image_size表示变 ...
- 【神经网络与深度学习】Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
在经过前面Caffe框架的搭建以及caffe基本框架的了解之后,接下来就要回到正题:使用caffe来进行模型的训练. 但如果对caffe并不是特别熟悉的话,从头开始训练一个模型会花费很多时间和精力,需 ...
随机推荐
- flutter 环境搭配 (一)
首先下载flutter SDK Flutter中文网 官网 (p2hp.com 选择下载 SDK 解压后 ,添加到环境变量中. 配置国内镜像, PUB_HOSTED_URL=https://pub.f ...
- 行为型模式(Behavioer Pattern)
行为型设计模式 行为型模式定义了系统中对象之间的交互与通信,研究系统在运行时对象之间的相互通信与协作,进一步明确对象的职责,包括对系统中较为复杂的流程的控制. 在软件系统运行时对象并不是孤立存在的,它 ...
- spring事务传递特性-REQUIRES_NEW和NESTED
spring对于事务的实现的确是它的一大优点,节省了程序员不少时间. 关于事务,有许多可以聊的内容,例如实现方式.实现原理.传递特性等. 本文讨论传递特性中的REQUIRES_NEW,NESTED. ...
- mysql多表删除指定记录
在Mysql4.0之后,mysql开始支持跨表delete. Mysql可以在一个sql语句中同时删除多表记录,也可以根据多个表之间的关系来删除某一个表中的记录. 假定我们有两张表:Product表和 ...
- python基础-数据容器的通用操作
五种数据容器的特性 列表list[] 元组tuple() 字符串str"" 集合set{} 字典dict{key:value} 元素数量 支持多个 支持多个 支持多 ...
- 可视化学习:如何用WebGL绘制3D物体
在之前的文章中,我们使用WebGL绘制了很多二维的图形和图像,在学习2D绘图的时候,我们提过很多次关于GPU的高效渲染,但是2D图形的绘制只展示了WebGL部分的能力,WebGL更强大的地方在于,它可 ...
- 面试官:Dubbo一次RPC调用会经过哪些环节?
大家好,我是三友~~ 今天继续探秘系列,扒一扒一次RPC请求在Dubbo中经历的核心流程. 本文是基于Dubbo3.x版本进行讲解 一个简单的Demo 这里还是老样子,为了保证文章的完整性和连贯性,方 ...
- webgl径向模糊实现体积光
体积光介绍 首先,我们要确认一下什么是体积光.体积光通俗来说是我们能看见的"光路",并不是所有灯光都会形成体积光效果,它是光照到大气中粒子散射后得到的效果(丁达尔效应).我们有时候 ...
- Bootstrip HTML 查询搜索常用格式模版
Bootstrip HTML 查询搜索常用格式模版 <form class="form-inline my-3 d-flex align-items-center justify-co ...
- [oeasy]python0145_版本控制_git_备份还原
git版本控制 回忆上次内容 上次我们了解了 try 的完全体 try 尝试运行 except 发现异常时运行的代码块 else 没有发现异常时运行的代码块 finally 无论是否发现异 ...