cloudpickle —— Python分布式序列化的专用模块
给出cloudpickle的GitHub地址:
https://github.com/cloudpipe/cloudpickle
=======================================================
单机的Python序列化模块有自带的pickle,但是在Python的分布式计算中进行序列化则是使用cloudpickle。之所以在分布式计算中Python的序列化使用cloudpickle模块的原因有:
1. cloudpickle是使用value序列化的方式,而pickle则是使用reference序列化的方式。因此在反序列化时pickle需要运行环境内存在序列化对象的定义,因为pickle进行序列化的只是对象(函数、类对象)的参数;而cloudpickle在序列化时会把对象的定义和参数值一并序列化,所以在分布式计算中传递cloudpickle序列化对象时接受方可以没有对象的定义(如果序列化的是类对象,那么接收方可以没有类的定义)。
例子:
import pickle class A():pass a=A() a_pick = pickle.dumps(a)
a_unpick = pickle.loads(a_pick)
print(a_unpick) del A
b_unpick = pickle.loads(a_pick)

import cloudpickle as pickle class A():pass a=A() a_pick = pickle.dumps(a)
a_unpick = pickle.loads(a_pick)
print(a_unpick) del A
b_unpick = pickle.loads(a_pick)

--------------------------------------------------------
import cloudpickle, pickle CONSTANT = 42
def my_function(data: int) -> int:
return data + CONSTANT pickled_function = cloudpickle.dumps(my_function)
pickled_function_2 = pickle.dumps(my_function) CONSTANT = 0
depickled_function = cloudpickle.loads(pickled_function)
depickled_function_2 = pickle.loads(pickled_function_2) print(depickled_function(43))
print(depickled_function_2(43))

2. pickle模块不能序列化lambda函数,cloudpickle可以序列化lambda函数。
例子:
import pickle
squared = lambda x: x ** 2
pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda)
new_squared(2)

import cloudpickle as pickle
squared = lambda x: x ** 2
pickled_lambda = pickle.dumps(squared) new_squared = pickle.loads(pickled_lambda)
new_squared(2)

===========================================
从上面的例子可以看出,cloudpickle更像是打包序列化,在序列化一个对象时会把该对象设计到的参数和定义也一并打包进行序列化。那么cloudpickle有没有打包不了的对象呢,这个确实还是有的,那就是序列化对象(函数、类对象)中如果包含有import语句的并不会把import语句中所涉及的对象进行一并打包。对于cloudpickle不能把序列化对象中包含的import引入的对象一并打包这个事情我个人的观点是其实现的难点在于import对象中会涉及大量的对象,这样进行一并打包要包含哪些对象难以确定、并且全部打包也是会造成序列化后对象字节码过长、序列化用时过长等问题。
例子:
模块: another_module.py

def g():
print("hello world")
return 100
模块 x.py:
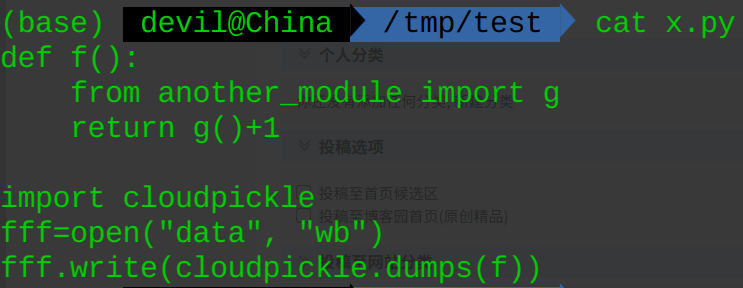
def f():
from another_module import g
return g()+1 import cloudpickle
fff=open("data", "wb")
fff.write(cloudpickle.dumps(f))
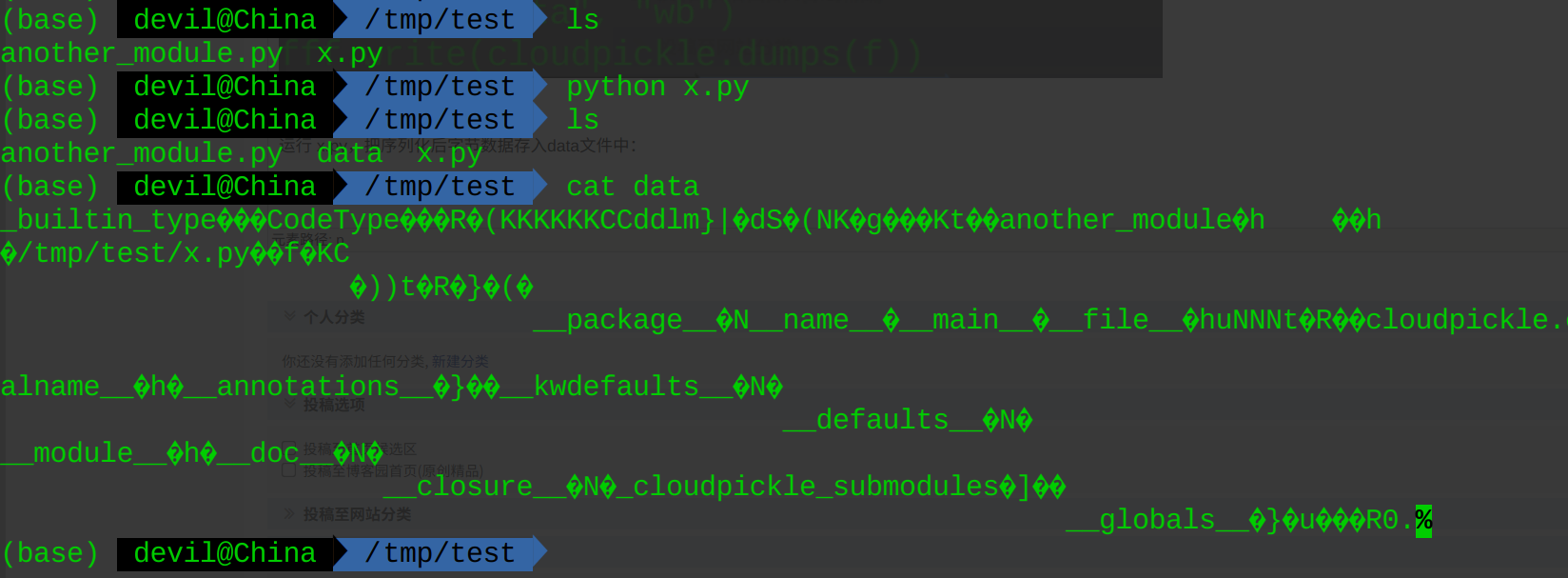
运行 x.py,把序列化后字节数据存入data文件中:
----------------------------------
给出反序列化文件 y.py:
import cloudpickle
fff=open("abc", "rb")
f = cloudpickle.loads(fff.read())
f()
如果把序列化文件data和反序列化文件y.py放在另一个单独的文件夹中并运行y.py,结果如下:
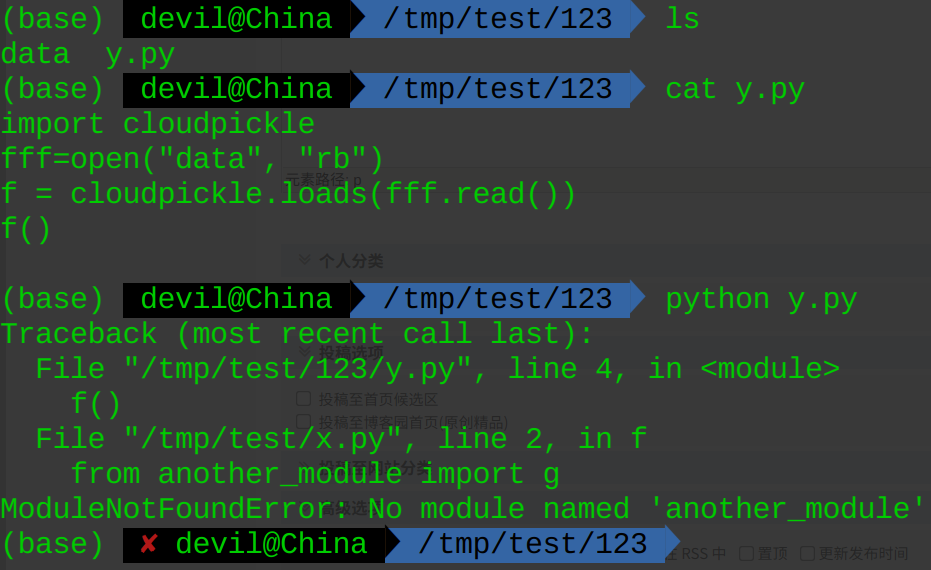
可以看到,使用cloudpickle并没有把涉及到的import语句中引入的对象进行一并的打包序列化。
PS: cloudpickle的底层实现依旧是调用pickle模块,可以说cloudpickle模块是对pickle模块的进一步包装,其实现的功能就是把pickle序列化中没有打包的对象以value的形式进行一并打包。
====================================================
cloudpickle —— Python分布式序列化的专用模块的更多相关文章
- Python:序列化 pickle JSON
序列化 在程序运行的过程中,所有的变量都储存在内存中,例如定义一个dict d=dict(name='Bob',age=20,score=88) 可以随时修改变量,比如把name修改为'Bill',但 ...
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- python 序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- python之序列化模块、双下方法(dict call new del len eq hash)和单例模式
摘要:__new__ __del__ __call__ __len__ __eq__ __hash__ import json 序列化模块 import pickle 序列化模块 补充: 现在我们都应 ...
- Python基础(正则、序列化、常用模块和面向对象)-day06
写在前面 上课第六天,打卡: 天地不仁,以万物为刍狗: 一.正则 - 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法: - 在线正则工具:http://tool ...
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为 ...
- python模块知识二 random -- 随机模块、序列化 、os模块、sys -- 系统模块
4.random -- 随机模块 a-z:97 ~ 122 A-Z :65 ~ 90 import random #浮点数 print(random.random())#0~1,不可指定 print( ...
- Python 序列化 pickle/cPickle模块
Python 序列化 pickle/cPickle模块 2013-10-17 Posted by yeho Python序列化的概念很简单.内存里面有一个数据结构,你希望将它保存下来,重用,或者发送给 ...
- python序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- [python] Python数据序列化模块pickle使用笔记
pickle是一个Python的内置模块,用于在Python中实现对象结构序列化和反序列化.Python序列化是一个将Python对象层次结构转换为可以本地存储或者网络传输的字节流的过程,反序列化则是 ...
随机推荐
- 590. N 叉树的后序遍历 | Javascript 递归实现
题目 题目链接:590. N 叉树的后序遍历 解题思路 递归后续遍历,正常的思路 然后有一个要注意的地方就是如果js定义了全局变量来存储结果,每次调用函数之前一定要记得清空,否则答案会带上之前的结果. ...
- xxlJob端口号及故障转移设置,解决负载均衡调度任务执行
xxlJob端口号及故障转移设置,解决负载均衡调度任务执行 my.xxljob.executorPort = 1162 my.xxljob.executorAppName = myService-jo ...
- JavaScript:JS对象_Array
<!DOCTYPE html><html> <head> <meta charset="utf-8"> ...
- 认真学习css3-2-css的选择器
关于有哪些选择器,具体可以查看w3school. 本文写了一个考卷的例子,带有部分js,jquery.不会针对每个选择器做示例,只练习了一些常用的,有意思的. 先看html/js代码: <!DO ...
- .NET使用CsvHelper快速读取和写入CSV文件
前言 在日常开发中使用CSV文件进行数据导入和导出.数据交换是非常常见的需求,今天我们来讲讲在.NET中如何使用CsvHelper这个开源库快速实现CSV文件读取和写入. CsvHelper类库介绍 ...
- Ubuntu 下 python 安装pip
背景 python的强大在于它的第三方库. 安装 python2 sudo apt-get install python-pip python3 curl https://bootstrap.pypa ...
- 【ClickHouse】0:clickhouse学习2之数据类型
一 :如何查看clickhouse具体支持哪些数据类型? 1:查看官方文档:https://clickhouse.tech/docs/en/sql-reference/data-types/ 2:查看 ...
- ChiFAN 的进程表
ChiFAN 的进程表 tip 有些题写了题解,思路做法都在里面,就只丢一个传送门了. 2023.1.9 生日蛋糕 传送门 IDA* 经过一番推式子可得,若还剩下 \(K\) 的体积,表面积为 \(2 ...
- 一个简单的html时间显示页面-可做小工具
代码由 chatgpt3.5 生成,已验证 index.html <!DOCTYPE html> <html> <head> <meta charset=&q ...
- 使用Nginx在80端口上代理多个.NET CORE网站
有两个.NET CORE3.1网站部署在CentOS7上(内网IP是192.168.2.32),现在想实现访问http://192.168.2.32时访问A网站,访问http://192.168.2. ...