mapreduce的shuffle机制
1.1 概述:
mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;(从map的输出到reduce的输入)
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,缓存);
具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序;
1.2 主要流程:
Shuffle缓存流程:
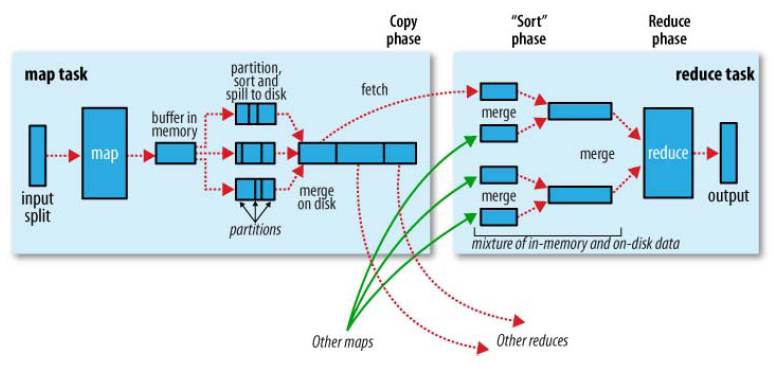
Buffer in memory:内存缓冲区
Partition:分区
Sort:分类
Spill to disk:切片到磁盘
Merge on disk:合并到磁盘
Fetch:拿来,拿取
Copy phase:复制阶段
Mixture of in-memory and on-disk data:内存和磁盘数据的混合
(可以看出一个maptask可以对应多个reducetask)
shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的,整体来看,分为3个操作:
1、分区partition
2、Sort根据key排序
3、Combiner进行局部value的合并
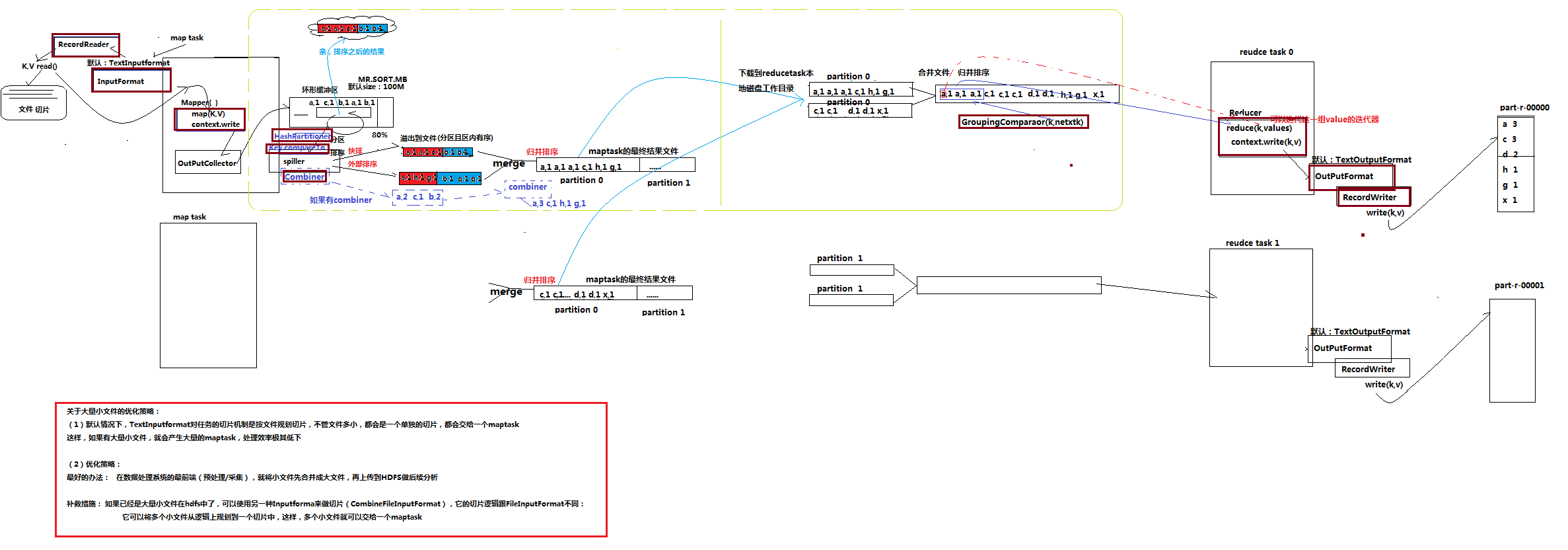
1.3 详细流程
1、 maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
(环形缓冲区默认100M)
2、 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(经过patition分区,key的compareto方法,经过排序,由combiner合并同key键值对,再经过快排/外部排序,溢出到文件)
3、 多个溢出文件会被合并成大的溢出文件
(经过merge文件合并,归并排序,得到maptask的最终结果文件)
------------------------------------------------------------------------------------------------------------
4、 在溢出过程,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5、 reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6、 reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)(一个reducetask可以对应多个maptask,两者是多对多)
7、 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M
1.4 详细流程示意图
mapreduce的shuffle机制的更多相关文章
- MapReduce(五) mapreduce的shuffle机制 与 Yarn
一.shuffle机制 1.概述 (1)MapReduce 中, map 阶段处理的数据如何传递给 reduce 阶段,是 MapReduce 框架中最关键的一个流程,这个流程就叫 Shuffle:( ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- MapReduce原理——Shuffle机制
在Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle. Map方法输出的数据会获得对应的分区,进入环形缓冲区(缓冲区一半写索引,另一半写数据).数据达到缓冲区的80%会发生溢写.在 ...
- 【待完成】[MapReduce_9] MapReduce 的 Shuffle 机制
0. 说明 待补充...
- Hadoop_18_MapRduce 内部的shuffle机制
1.Mapreduce的shuffle机制: Mapreduce中,map阶段处理的数据如何传递给Reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle 将mapta ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- shuffle机制和TextInputFormat分片和读取分片数据(九)
shuffle机制 1:每个map有一个环形内存缓冲区,用于存储任务的输出.默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
随机推荐
- 设置WordPress文章关键词自动获取,文章所属分类名称,描述自动获取文章内容,给文章的图片自动加上AlT标签
最近在优化网站,SEO优化标准:每一篇文章都要有关键词,关键词的个数为3到6个.每一篇文章都要有描述,描述的字数为汉字在70~80之间,在160个字符之间.每一篇文章的图片都要有Alt标签,自动给图片 ...
- Istio(三):服务网格istio可观察性:Prometheus,Grafana,Zipkin,Kiali
目录 一.模块概览 二.系统环境 三.可观察性 四.指标 4.1 代理级指标 4.2 服务级指标 4.3 控制平面度量 五.Prometheus 5.1 安装Prometheus 5.2 部署示例应用 ...
- vue我自己的动态菜单思路
1.在router里把所有的路由都加上. 2.后端存储路由path和其他设计需要的信息. 3.登录后,后端返回菜单树,根据权限不同,返回的菜单不同,并且还要返回每个path代表的页面具有的权限数组.可 ...
- 【C#】做一个winform版本的软考成绩查询软件
返回的json SWCJ代表 上午的成绩 XWCJ代表下午的成绩. 主要步骤: 1. 获取验证码图片 2. 获取cookie 3. 发送验证验证码请求 4 发送成绩查询请求,并获取返回的json ...
- Python Pandas 数据分组
在数据处理中,分箱.分组是一种常见的技术,用于将连续数据的间隔分组到"箱"或"桶"中.我们将讨论以下两种方法: 使用 Pandas 的 between 和 lo ...
- Ceph配置与认证授权
目录 Ceph配置与认证授权 1. 为什么现在不采用修改配置文件的方式了呢? 2. Ceph元变量 3. 使用命令行修改配置 3.1 全部修改(使用服务名) 3.2 部分修改(修改进程) 3.3 临时 ...
- 研二学妹面试字节,竟倒在了ThreadLocal上,这是不要应届生还是不要女生啊?
一.写在开头 今天和一个之前研二的学妹聊天,聊及她上周面试字节的情况,着实感受到了Java后端现在找工作的压力啊,记得在18,19年的时候,研究生计算机专业的学生,背背八股文找个Java开发工 ...
- 【C# 序列化】System.Text.Json.Nodes ---Json数据交换格式 对应C#类
请先阅读 JSON数据交换格式 Json数据交换格式 对应C#类 System.Text.Json.Nodes:.NET 6 依微软的计划,System.Text.Json 应取代Newtonsoft ...
- 鸿蒙极速入门(五)-路由管理(Router)
页面路由指在应用程序中实现不同页面之间的跳转和数据传递.HarmonyOS提供了Router模块,通过不同的url地址,可以方便地进行页面路由,轻松地访问不同的页面. 一.基础使用 Router模块提 ...
- 机器学习策略篇:详解可避免偏差(Avoidable bias)
可避免偏差 如果希望学习算法能在训练集上表现良好,但有时实际上并不想做得太好.得知道人类水平的表现是怎样的,可以确切告诉算法在训练集上的表现到底应该有多好,或者有多不好,让我说明是什么意思吧. 经常使 ...