Hudi自带工具DeltaStreamer的实时入湖最佳实践
摘要:本文介绍如何使用Hudi自带入湖工具DeltaStreamer进行数据的实时入湖。
本文分享自华为云社区《华为FusionInsight MRS实战 - Hudi实时入湖之DeltaStreamer工具最佳实践》,作者: 晋红轻 。
背景
传统大数据平台的组织架构是针对离线数据处理需求设计的,常用的数据导入方式为采用sqoop定时作业批量导入。随着数据分析对实时性要求不断提高,按小时、甚至分钟级的数据同步越来越普遍。由此展开了基于spark/flink流处理机制的(准)实时同步系统的开发。
然而实时同步从一开始就面临如下几个挑战:
- 小文件问题。不论是spark的microbatch模式,还是flink的逐条处理模式,每次写入HDFS时都是几MB甚至几十KB的文件。长时间下来产生的大量小文件,会对HDFS namenode产生巨大的压力。
- 对update操作的支持。HDFS系统本身不支持数据的修改,无法实现同步过程中对记录进行修改。
- 事务性。不论是追加数据还是修改数据,如何保证事务性。即数据只在流处理程序commit操作时一次性写入HDFS,当程序rollback时,已写入或部分写入的数据能随之删除。
Hudi就是针对以上问题的解决方案之一。使用Hudi自带的DeltaStreamer工具写数据到Hudi,开启–enable-hive-sync 即可同步数据到hive表。
Hudi DeltaStreamer写入工具介绍
DeltaStreamer工具使用参考 https://hudi.apache.org/cn/docs/writing_data.html
HoodieDeltaStreamer实用工具 (hudi-utilities-bundle中的一部分) 提供了从DFS或Kafka等不同来源进行摄取的方式,并具有以下功能。
- 从Kafka单次摄取新事件,从Sqoop、HiveIncrementalPuller输出或DFS文件夹中的多个文件
- 支持json、avro或自定义记录类型的传入数据
- 管理检查点,回滚和恢复
- 利用DFS或Confluent schema注册表的Avro模式。
- 支持自定义转换操作
场景说明

- 生产库数据通过CDC工具(debezium)实时录入到MRS集群中Kafka的指定topic里。
- 通过Hudi提供的DeltaStreamer工具,读取Kafka指定topic里的数据并解析处理。
- 同时使用DeltaStreamer工具将处理后的数据写入到MRS集群的hive里。
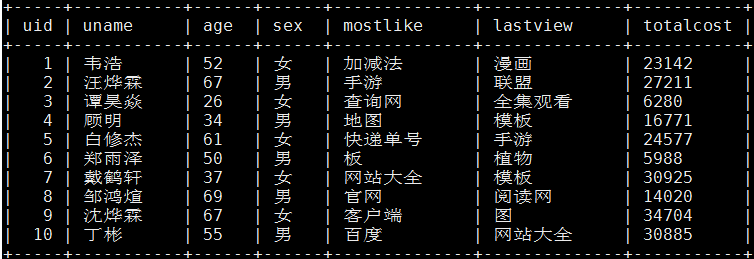
样例数据简介
生产库MySQL原始数据:
CDC工具debezium简介
对接步骤具体参考:https://fusioninsight.github.io/ecosystem/zh-hans/Data_Integration/DEBEZIUM/
完成对接后,针对MySQL生产库分别做增、改、删除操作对应的kafka消息
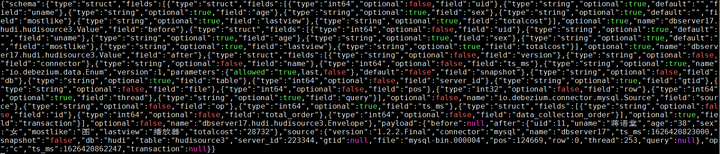
增加操作: insert into hudi.hudisource3 values (11,“蒋语堂”,“38”,“女”,“图”,“播放器”,“28732”);
对应kafka消息体:
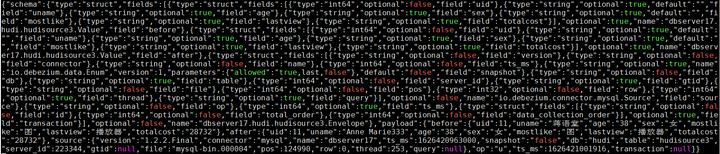
更改操作: UPDATE hudi.hudisource3 SET uname=‘Anne Marie333’ WHERE uid=11;
对应kafka消息体:
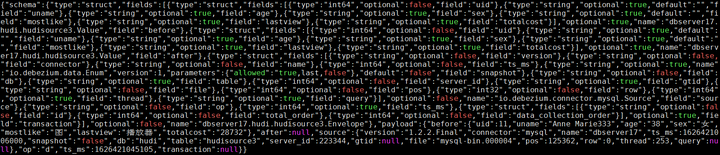
删除操作: delete from hudi.hudisource3 where uid=11;
对应kafka消息体:
调试步骤
华为MRS Hudi样例工程获取
根据实际MRS版本登录github获取样例代码: https://github.com/huaweicloud/huaweicloud-mrs-example/tree/mrs-3.1.0
打开工程SparkOnHudiJavaExample
样例代码修改及介绍

1.debeziumJsonParser
说明:对debezium的消息体进行解析,获取到op字段。
源码如下:
package com.huawei.bigdata.hudi.examples;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.TypeReference; public class debeziumJsonParser { public static String getOP(String message){ JSONObject json_obj = JSON.parseObject(message);
String op = json_obj.getJSONObject("payload").get("op").toString();
return op;
}
}
2.MyJsonKafkaSource
说明:DeltaStreamer默认使用org.apache.hudi.utilities.sources.JsonKafkaSource消费kafka指定topic的数据,如果消费阶段涉及数据的解析操作,则需要重写MyJsonKafkaSource进行处理。
以下是源码,增加注释
package com.huawei.bigdata.hudi.examples; import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.common.util.Option;
import org.apache.hudi.config.HoodieWriteConfig;
import org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamerMetrics;
import org.apache.hudi.utilities.schema.SchemaProvider;
import org.apache.hudi.utilities.sources.InputBatch;
import org.apache.hudi.utilities.sources.JsonSource;
import org.apache.hudi.utilities.sources.helpers.KafkaOffsetGen;
import org.apache.hudi.utilities.sources.helpers.KafkaOffsetGen.CheckpointUtils;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.log4j.LogManager;
import org.apache.log4j.Logger;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.spark.streaming.kafka010.OffsetRange;
import java.util.Map; /**
* Read json kafka data.
*/
public class MyJsonKafkaSource extends JsonSource { private static final Logger LOG = LogManager.getLogger(MyJsonKafkaSource.class); private final KafkaOffsetGen offsetGen; private final HoodieDeltaStreamerMetrics metrics; public MyJsonKafkaSource(TypedProperties properties, JavaSparkContext sparkContext, SparkSession sparkSession,
SchemaProvider schemaProvider) {
super(properties, sparkContext, sparkSession, schemaProvider);
HoodieWriteConfig.Builder builder = HoodieWriteConfig.newBuilder();
this.metrics = new HoodieDeltaStreamerMetrics(builder.withProperties(properties).build());
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer", StringDeserializer.class);
offsetGen = new KafkaOffsetGen(properties);
} @Override
protected InputBatch<JavaRDD<String>> fetchNewData(Option<String> lastCheckpointStr, long sourceLimit) {
OffsetRange[] offsetRanges = offsetGen.getNextOffsetRanges(lastCheckpointStr, sourceLimit, metrics);
long totalNewMsgs = CheckpointUtils.totalNewMessages(offsetRanges);
LOG.info("About to read " + totalNewMsgs + " from Kafka for topic :" + offsetGen.getTopicName());
if (totalNewMsgs <= 0) {
return new InputBatch<>(Option.empty(), CheckpointUtils.offsetsToStr(offsetRanges));
}
JavaRDD<String> newDataRDD = toRDD(offsetRanges);
return new InputBatch<>(Option.of(newDataRDD), CheckpointUtils.offsetsToStr(offsetRanges));
} private JavaRDD<String> toRDD(OffsetRange[] offsetRanges) {
return KafkaUtils.createRDD(this.sparkContext, this.offsetGen.getKafkaParams(), offsetRanges, LocationStrategies.PreferConsistent()).filter((x)->{
//过滤空行和脏数据
String msg = (String)x.value();
if (msg == null) {
return false;
}
try{
String op = debeziumJsonParser.getOP(msg);
}catch (Exception e){
return false;
}
return true;
}).map((x) -> {
//将debezium接进来的数据解析写进map,在返回map的tostring, 这样结构改动最小
String msg = (String)x.value();
String op = debeziumJsonParser.getOP(msg);
JSONObject json_obj = JSON.parseObject(msg, Feature.OrderedField);
Boolean is_delete = false;
String out_str = "";
Object out_obj = new Object();
if(op.equals("c")){
out_obj = json_obj.getJSONObject("payload").get("after");
}
else if(op.equals("u")){
out_obj = json_obj.getJSONObject("payload").get("after");
}
else {
is_delete = true;
out_obj = json_obj.getJSONObject("payload").get("before");
}
Map out_map = (Map)out_obj;
out_map.put("_hoodie_is_deleted",is_delete);
out_map.put("op",op); return out_map.toString();
});
}
}
3.TransformerExample
说明: 入湖hudi表或者hive表时候需要指定的字段
以下是源码,增加注释
package com.huawei.bigdata.hudi.examples; import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.utilities.transform.Transformer;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List; /**
* 功能描述
* 对获取的数据进行format
*/
public class TransformerExample implements Transformer, Serializable { /**
* format data
*
* @param JavaSparkContext jsc
* @param SparkSession sparkSession
* @param Dataset<Row> rowDataset
* @param TypedProperties properties
* @return Dataset<Row>
*/
@Override
public Dataset<Row> apply(JavaSparkContext jsc, SparkSession sparkSession, Dataset<Row> rowDataset,
TypedProperties properties) {
JavaRDD<Row> rowJavaRdd = rowDataset.toJavaRDD();
List<Row> rowList = new ArrayList<>();
for (Row row : rowJavaRdd.collect()) { Row one_row = buildRow(row);
rowList.add(one_row);
}
JavaRDD<Row> stringJavaRdd = jsc.parallelize(rowList);
List<StructField> fields = new ArrayList<>();
builFields(fields);
StructType schema = DataTypes.createStructType(fields);
Dataset<Row> dataFrame = sparkSession.createDataFrame(stringJavaRdd, schema);
return dataFrame;
} private void builFields(List<StructField> fields) {
fields.add(DataTypes.createStructField("uid", DataTypes.IntegerType, true));
fields.add(DataTypes.createStructField("uname", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("age", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("sex", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("mostlike", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("lastview", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("totalcost", DataTypes.StringType, true));
fields.add(DataTypes.createStructField("_hoodie_is_deleted", DataTypes.BooleanType, true));
fields.add(DataTypes.createStructField("op", DataTypes.StringType, true));
} private Row buildRow(Row row) {
Integer uid = row.getInt(0);
String uname = row.getString(1);
String age = row.getString(2);
String sex = row.getString(3);
String mostlike = row.getString(4);
String lastview = row.getString(5);
String totalcost = row.getString(6);
Boolean _hoodie_is_deleted = row.getBoolean(7);
String op = row.getString(8);
Row returnRow = RowFactory.create(uid, uname, age, sex, mostlike, lastview, totalcost, _hoodie_is_deleted, op);
return returnRow;
}
}
4.DataSchemaProviderExample
说明: 分别指定MyJsonKafkaSource返回的数据格式为source schema,TransformerExample写入的数据格式为target schema
以下是源码
package com.huawei.bigdata.hudi.examples; import org.apache.avro.Schema;
import org.apache.hudi.common.config.TypedProperties;
import org.apache.hudi.utilities.schema.SchemaProvider;
import org.apache.spark.api.java.JavaSparkContext; /**
* 功能描述
* 提供sorce和target的schema
*/
public class DataSchemaProviderExample extends SchemaProvider { public DataSchemaProviderExample(TypedProperties props, JavaSparkContext jssc) {
super(props, jssc);
}
/**
* source schema
*
* @return Schema
*/
@Override
public Schema getSourceSchema() {
Schema avroSchema = new Schema.Parser().parse(
"{\"type\":\"record\",\"name\":\"hoodie_source\",\"fields\":[{\"name\":\"uid\",\"type\":\"int\"},{\"name\":\"uname\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"string\"},{\"name\":\"sex\",\"type\":\"string\"},{\"name\":\"mostlike\",\"type\":\"string\"},{\"name\":\"lastview\",\"type\":\"string\"},{\"name\":\"totalcost\",\"type\":\"string\"},{\"name\":\"_hoodie_is_deleted\",\"type\":\"boolean\"},{\"name\":\"op\",\"type\":\"string\"}]}");
return avroSchema;
}
/**
* target schema
*
* @return Schema
*/
@Override
public Schema getTargetSchema() {
Schema avroSchema = new Schema.Parser().parse(
"{\"type\":\"record\",\"name\":\"mytest_record\",\"namespace\":\"hoodie.mytest\",\"fields\":[{\"name\":\"uid\",\"type\":\"int\"},{\"name\":\"uname\",\"type\":\"string\"},{\"name\":\"age\",\"type\":\"string\"},{\"name\":\"sex\",\"type\":\"string\"},{\"name\":\"mostlike\",\"type\":\"string\"},{\"name\":\"lastview\",\"type\":\"string\"},{\"name\":\"totalcost\",\"type\":\"string\"},{\"name\":\"_hoodie_is_deleted\",\"type\":\"boolean\"},{\"name\":\"op\",\"type\":\"string\"}]}");
return avroSchema;
}
}
将工程打包(hudi-security-examples-0.7.0.jar)以及json解析包(fastjson-1.2.4.jar)上传至MRS客户端
DeltaStreamer启动命令
登录客户端执行一下命令获取环境变量以及认证
source /opt/hadoopclient/bigdata_env
kinit developuser
source /opt/hadoopclient/Hudi/component_env
DeltaStreamer启动命令如下:
spark-submit --master yarn-client \
--jars /opt/hudi-demo2/fastjson-1.2.4.jar,/opt/hudi-demo2/hudi-security-examples-0.7.0.jar \
--driver-class-path /opt/hadoopclient/Hudi/hudi/conf:/opt/hadoopclient/Hudi/hudi/lib/*:/opt/hadoopclient/Spark2x/spark/jars/*:/opt/hudi-demo2/hudi-security-examples-0.7.0.jar \
--class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer \
spark-internal --props file:///opt/hudi-demo2/kafka-source.properties \
--target-base-path /tmp/huditest/delta_demo2 \
--table-type COPY_ON_WRITE \
--target-table delta_demo2 \
--source-ordering-field uid \
--source-class com.huawei.bigdata.hudi.examples.MyJsonKafkaSource \
--schemaprovider-class com.huawei.bigdata.hudi.examples.DataSchemaProviderExample \
--transformer-class com.huawei.bigdata.hudi.examples.TransformerExample \
--enable-hive-sync --continuous
kafka.properties配置
// hudi配置
hoodie.datasource.write.recordkey.field=uid
hoodie.datasource.write.partitionpath.field=
hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.NonpartitionedKeyGenerator
hoodie.datasource.write.hive_style_partitioning=true
hoodie.delete.shuffle.parallelism=10
hoodie.upsert.shuffle.parallelism=10
hoodie.bulkinsert.shuffle.parallelism=10
hoodie.insert.shuffle.parallelism=10
hoodie.finalize.write.parallelism=10
hoodie.cleaner.parallelism=10
hoodie.datasource.write.precombine.field=uid
hoodie.base.path = /tmp/huditest/delta_demo2
hoodie.timeline.layout.version = 1 // hive config
hoodie.datasource.hive_sync.table=delta_demo2
hoodie.datasource.hive_sync.partition_fields=
hoodie.datasource.hive_sync.assume_date_partitioning=false
hoodie.datasource.hive_sync.partition_extractor_class=org.apache.hudi.hive.NonPartitionedExtractor
hoodie.datasource.hive_sync.use_jdbc=false // Kafka Source topic
hoodie.deltastreamer.source.kafka.topic=hudisource
// checkpoint
hoodie.deltastreamer.checkpoint.provider.path=hdfs://hacluster/tmp/delta_demo2/checkpoint/ // Kafka props
bootstrap.servers=172.16.9.117:21005
auto.offset.reset=earliest
group.id=a5
offset.rang.limit=10000
注意:kafka服务端配置 allow.everyone.if.no.acl.found 为true
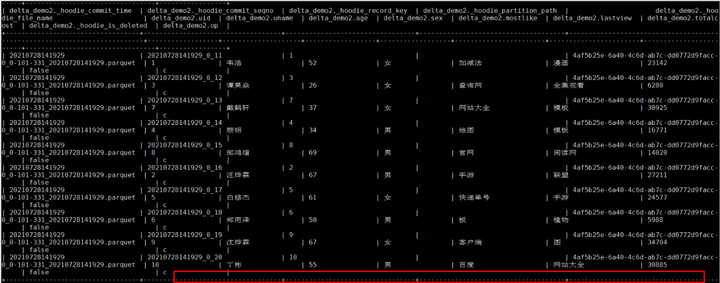
使用Spark查询
spark-shell --master yarn
val roViewDF = spark.read.format("org.apache.hudi").load("/tmp/huditest/delta_demo2/*")
roViewDF.createOrReplaceTempView("hudi_ro_table")
spark.sql("select * from hudi_ro_table").show()
Mysql增加操作对应spark中hudi表查询结果:

Mysql更新操作对应spark中hudi表查询结果:

删除操作:

使用Hive查询
beeline select * from delta_demo2;
Mysql增加操作对应hive表中查询结果:

Mysql更新操作对应hive表中查询结果:

Mysql删除操作对应hive表中查询结果:
Hudi自带工具DeltaStreamer的实时入湖最佳实践的更多相关文章
- UI实时预览最佳实践(转)
UI实时预览最佳实践 概要:Android中实时预览UI和编写UI的各种技巧.本文的例子都可以在结尾处的示例代码中看到并下载.如果喜欢请star,如果觉得有纰漏请提交issue,如果你有更好的点子可以 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- Qcon 实时音视频专场:实时互动的最佳实践与未来展望
互动直播.线上会议.在线医疗和在线教育是实时音视频技术应用的重要场景,而这些场景对高可用.高可靠.低延时有着苛刻的要求,很多团队在音视频产品开发过程中会遇到各种各样的问题.例如:流畅性,如果在视频过程 ...
- 微信小程序客服消息实时通知之最佳实践
我们做微信小程序开发的都知道,只要在小程序页面中添加如下代码即可进入小程序的客服会话界面: <button open-type="contact" >联系我们</ ...
- 30分钟带你了解Springboot与Mybatis整合最佳实践
前言:Springboot怎么使用想必也无需我多言,Mybitas作为实用性极强的ORM框架也深受广大开发人员喜爱,有关如何整合它们的文章在网络上随处可见.但是今天我会从实战的角度出发,谈谈我对二者结 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- JDK自带工具keytool生成ssl证书
前言: 因为公司项目客户要求使用HTTPS的方式来保证数据的安全,所以木有办法研究了下怎么生成ssl证书来使用https以保证数据安全. 百度了不少资料,看到JAVA的JDK自带生成SSL证书的工具: ...
- SpringBoot打包成exe(别再用exe4j了,使用JDK自带工具)
SpringBoot打包成exe(别再用exe4j了,使用JDK自带工具) 搜到大部分打包exe的文章都是使用exe4j打包 步骤贼多,安装麻烦,打包麻烦 收费软件,公司使用会吃律师函 JDK14以上 ...
- 如何利用 Visual Studio 自带工具提高开发效率
Visual Stuido 是一款强大的Windows 平台集成开发工具,你是否好好地利用了它呢? 显示行号 有些时候(比如错误定位)的时候,显示行号将有利于我们进行快速定位. 如何显示 1. 工具 ...
- 教你用Windows自带工具给优盘/移动硬盘添加密码
教你用Windows自带工具给优盘/移动硬盘添加密码 本文中优盘,移动硬盘和分区操作方式一样,为方便描述,下文将只说优盘 优盘成了很多人每天都会用到的工具,有时候自己优盘会存着一些不希望别人看到的文件 ...
随机推荐
- 虹科案例 | 丝芙兰xDomo:全球美妆巨头商业智能新玩法
全球美妆行业的佼佼者丝芙兰,其走向成功绝非仅依靠品牌知名度和营销手段.身为数据驱动型企业,2018年以来,丝芙兰就率先在行业内采用虹科提供的Domo商业智能进行数据分析和决策,并首先享受了运营优化.效 ...
- 组合的输出 题解(lgP1157)
一看就是 dfs 然而窝并不会做 调了一个多小时才调出来.漏洞连篇.(第一次写的基本没有对的地方QAQ 题解见注释. #include<bits/stdc++.h> using names ...
- 一些 trick 和思考收获
2023.1.7 P1117 优秀的拆分 对于一眼看上去只能直接求解的题可以设置一些节点变为求每个节点的贡献 *2023 7.24 补充:这个 trick 也被称为设置关键点,通常用于区间长度固定或是 ...
- JAVA类的加载(1) ——类的加载及类加载器介绍
过程:当程序主动使用某个类时,如果该类还未被加载到内存中,系统会通过加载.连接.初始化三个步骤来对该类进行初始化,有时候称为类加载(类初始化) 类加载 定义:类加载 指的是将类的class文件读入 ...
- AndroGenshin
是一个apk文件 jadx打开以后发现主要操作 找到mainactivity,研究代码可以知道主要操作就是对两个字符串进行RC4加密再进行一次换表的base64操作,最后再将加密后的结果与flag做对 ...
- C语言输入一个三位的正整数,按逆序打印出该数的各位数字。
#include <stdio.h> int main() { int n, a, b, c;//定义3位数,个位数,十位数,百位数变量 scanf_s("%d", & ...
- 你知道Spring中BeanFactoryPostProcessors是如何执行的吗?
Spring中的BeanFactoryPostProcessor是在Spring容器实例化Bean之后,初始化之前执行的一个扩展机制.它允许开发者在Bean的实例化和初始化之前对BeanDefinit ...
- Eclipse 安装 ABAP 插件报错 Microsoft Visual C++ 2013 (x64) 快速解决
去官网下载Microsoft Visual C++ 2013 (x64) 安装 Download Visual C++ Redistributable Packages for Visual St ...
- execl表格if函数and和or的使用方法?
当在Excel中处理数据时,IF函数是非常有用的函数之一.它允许您根据指定的条件执行不同的操作.在IF函数中,AND和OR函数可以帮助您组合多个条件以实现更复杂的逻辑判断.接下来,我将详细描述IF函数 ...
- Aignize第一期完善产品逻辑+类图说明书
Aiganize产品说明+拟类图(第一期) ·附图: 此应用由: 前端:微信小程序前端+vue3后台管理系统后端:Springboot+Mysql 服务器:后端服务器+AI交互服务器 整个应用流程大致 ...