看FusionInsight Spark如何支持JDBCServer的多实例特性
摘要:采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力。
本文分享自华为云社区《FusionInsight Spark支持JDBCServer的多实例特性介绍》,作者: 一枚核桃。
基于社区已有的JDBCServer基础上,采用多主实例模式实现了其高可用性方案。集群中支持同时共存多个JDBCServer服务,通过客户端可以随机连接其中的任意一个服务进行业务操作。即使集群中一个或多个JDBCServer服务停止工作,也不影响用户通过同一个客户端接口连接其他正常的JDBCServer服务。
多主实例模式相比主备模式的HA方案,优势主要体现在对以下两种场景的改进。
- 主备模式下,当发生主备切换时,会存在一段时间内服务不可用,该时间JDBCServer无法控制,取决于Yarn服务的资源情况。
- Spark中通过类似于HiveServer2的Thrift JDBC提供服务,用户通过Beeline以及JDBC接口访问。因此JDBCServer集群的处理能力取决于主Server的单点能力,可扩展性不够。
采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力。
实现方案
多主实例模式的HA方案原理如下图所示。
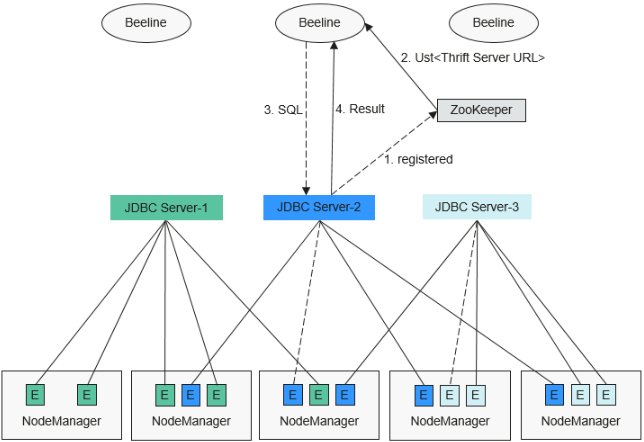
1、JDBCServer在启动时,向ZooKeeper注册自身消息,在指定目录中写入节点,节点包含了该实例对应的IP,端口,版本号和序列号等信息(多节点信息之间以逗号隔开)。
示例如下:
[serverUri=192.168.169.84:22550;version=8.1.2;sequence=0000001244,serverUri=192.168.195.232:22550 ;version=8.1.2;sequence=0000001242,serverUri=192.168.81.37:22550 ;version=8.1.2;sequence=0000001243]
2、客户端连接JDBCServer时,需要指定Namespace,即访问ZooKeeper哪个目录下的JDBCServer实例。在连接的时候,会从Namespace下随机选择一个实例连接,详细URL参见URL连接介绍。
3、客户端成功连接JDBCServer服务后,向JDBCServer服务发送SQL语句。
4、JDBCServer服务执行客户端发送的SQL语句后,将结果返回给客户端。
在HA方案中,每个JDBCServer服务(即实例)都是独立且等同的,当其中一个实例在升级或者业务中断时,其他的实例也能接受客户端的连接请求。
多主实例方案遵循以下规则:
- 当一个实例异常退出时,其他实例不会接管此实例上的会话,也不会接管此实例上运行的业务。
- 当JDBCServer进程停止时,删除在ZooKeeper上的相应节点。
- 由于客户端选择服务端的策略是随机的,可能会出现会话随机分配不均匀的情况,进而可能引起实例间的负载不均衡。
- 实例进入维护模式(即进入此模式后不再接受新的客户端连接)后,当达到退服超时时间,仍在此实例上运行的业务有可能会发生失败。
URL连接介绍
多主实例模式
多主实例模式的客户端读取ZooKeeper节点中的内容,连接对应的JDBCServer服务。连接字符串为:
- 安全模式下:
- Kinit认证方式下的JDBCURL如下所示:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;
说明:
- 其中“<zkNode_IP>:<zkNode_Port>”是ZooKeeper的URL,多个URL以逗号隔开。
例如:“192.168.81.37:24002,192.168.195.232:24002,192.168.169.84:24002”。
- 其中“sparkthriftserver2x”是ZooKeeper上的目录,表示客户端从该目录下随机选择JDBCServer实例进行连接。
示例:安全模式下通过Beeline客户端连接时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;"
Keytab认证方式下的JDBCURL如下所示:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;user.principal=<principal_name>;user.keytab=<path_to_keytab>
其中<principal_name>表示用户使用的Kerberos用户的principal,如“test@<系统域名>”。<path_to_keytab>表示<principal_name>对应的keytab文件路径,如“/opt/auth/test/user.keytab”。
- 普通模式下:
jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;
示例:普通模式下通过Beeline客户端连接时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<zkNode1_IP>:<zkNode1_Port>,<zkNode2_IP>:<zkNode2_Port>,<zkNode3_IP>:<zkNode3_Port>/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;"
非多主实例模式
非多主实例模式的客户端连接的是某个指定JDBCServer节点。该模式的连接字符串相比多主实例模式的去掉关于Zookeeper的参数项“serviceDiscoveryMode”和“zooKeeperNamespace”。
示例:安全模式下通过Beeline客户端连接非多主实例模式时执行以下命令:
sh CLIENT_HOME/spark/bin/beeline -u "jdbc:hive2://<server_IP>:<server_Port>/;user.principal=spark2x/hadoop.<系统域名>@<系统域名>;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.<系统域名>@<系统域名>;"
说明
- 其中“<server_IP>:<server_Port>”是指定JDBCServer节点的URL。
- “CLIENT_HOME”是指客户端路径。
多主实例模式与非多主实例模式两种模式的JDBCServer接口相比,除连接方式不同外其他使用方法相同。由于Spark JDBCServer是Hive中的HiveServer2的另外一个实现,具体使用方法,请参见Hive官网:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients。
看FusionInsight Spark如何支持JDBCServer的多实例特性的更多相关文章
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- nginx+tomcat+二级域名静态文件分离支持mp4视频播放配置实例
nginx+tomcat+二级域名静态文件分离支持mp4视频播放配置实例 二级域名配置 在/etc/nginx/conf.d/目录下配置二级域名同名的conf文件,路径改成对应的即可 statics. ...
- Java RMI 介绍和例子以及Spring对RMI支持的实际应用实例
RMI 相关知识 RMI全称是Remote Method Invocation-远程方法调用,Java RMI在JDK1.1中实现的,其威力就体现在它强大的开发分布式网络应用的能力上,是纯Java的网 ...
- 【Spark】Spark2.x版的新特性
一.API 1. 出现新的上下文接口:SparkSession,统一了SQLContext和HiveContext,并且为SparkSession开发了新的流式调用的configuration API ...
- Atitti 存储引擎支持的国内点与特性attilax总结
Atitti 存储引擎支持的国内点与特性attilax总结 存储引擎处理的事情: · 并发性:某些应用程序比其他应用程序具有很多的颗粒级锁定要求(如行级锁定). · 事务支持:并非所有的应用程序都需要 ...
- Spring 4支持的Java 8新特性一览
有众多新特性和函数库的Java 8发布之后,Spring 4.x已经支持其中的大部分.有些Java 8的新特性对Spring无影响,可以直接使用,但另有些新特性需要Spring的支持.本文将带您浏览S ...
- 一篇文章看懂spark 1.3+各版本特性
Spark 1.6.x的新特性Spark-1.6是Spark-2.0之前的最后一个版本.主要是三个大方面的改进:性能提升,新的 Dataset API 和数据科学功能的扩展.这是社区开发非常重要的一个 ...
- 【Spark】一张图看懂Spark的运行架构,以standAlone模式为例
- 查看当前看k8s集群支持的版本命令
# kubectl api-versions admissionregistration.k8s.io/v1 admissionregistration.k8s.io/v1beta1 apiexten ...
- Spark的RDD原理以及2.0特性的介绍
转载自:http://www.tuicool.com/articles/7VNfyif 王联辉,曾在腾讯,Intel 等公司从事大数据相关的工作.2013 年 - 2016 年先后负责腾讯 Yarn ...
随机推荐
- Unity - EditorWindow 折叠树显示(IMGUI)
仅适用于2018之前的版本,有UIElements或者UIWidgets的最好用新的 基本实现 树节点 public interface ITreeNode { ITreeNode Parent { ...
- 标子查询优化和改写SQL案例
京华开发一哥们找我优化条报表SQL,反馈执行时间很慢需要 18s 才能出结果,安排. -- 原SQL SELECT 2 AS TYPE, to_char(a."create_time&quo ...
- [NOIP 考前备战] 线段树刷题
备战线段树 T1 AcWing .1275. 最大数 查询最大值 + 单点修改 #include <bits/stdc++.h> #define int long long using n ...
- OpenCL任务调度基础介绍
当前,科学计算需求急剧增加,基于CPU-GPU异构系统的异构计算在科学计算领域得到了广泛应用,OpenCL由于其跨平台特性在异构计算领域渐为流行,其调度困难的问题也随之暴露,传统的OpenCL任务调度 ...
- LabVIEW基于机器视觉的实验室设备管理系统(4)
目录 行动计划 后面板连线 初始化 返回 注册 账号限制 查重账号或者姓名 确认密码 注册 效果演示 我们上一期制作完了给账户修改密码,那么我们这一期就来完成账户注册这一功能.老规矩哦,先来计划 ...
- 生产实践:Redis与Mysql的数据强一致性方案
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 数据库和Redis如何保持强一致性,这篇文章告诉你 目的 Redis和Msql来保持数据同步,并且强一致,以此来提高对应接 ...
- Modbus转Profinet 网关 TS-180
产品简介 实现 PROFINET 网络与串口网络之间的数据通信,三个串口可分别连接具有 RS232 或 RS485 接口的设 备到 PROFINET 网络.即将串口设备转换为 PROFINET 设备. ...
- 【外包杯】【无语的报错】意想不到的逗号Unexpected comma.(已解决)
解决了,答案是没保存,看见那些文件是型号了吗,就是这个原因.
- RLHF · PBRL | B-Pref:生成多样非理性 preference,建立 PBRL benchmark
论文题目:B-Pref: Benchmarking Preference-Based Reinforcement Learning,2021 NeurIPS Track Datasets and Be ...
- Excel 中使用数据透视图进行数据可视化
使用数据透视表(PivotTable)是在Excel中进行数据可视化的强大工具.下面将提供详细的步骤来使用数据透视表进行数据可视化. **步骤一:准备数据** 首先,确保你有一个包含所需数据的Exce ...