阿里云EMR Remote Shuffle Service在小米的实践
简介:阿里云EMR自2020年推出Remote Shuffle Service(RSS)以来,帮助了诸多客户解决Spark作业的性能、稳定性问题,并使得存算分离架构得以实施,与此同时RSS也在跟合作方小米的共建下不断演进。本文将介绍RSS的最新架构,在小米的实践,以及开源。

作者 | 一锤、明济、紫槿
来源 | 阿里技术公众号
阿里云EMR自2020年推出Remote Shuffle Service(RSS)以来,帮助了诸多客户解决Spark作业的性能、稳定性问题,并使得存算分离架构得以实施,与此同时RSS也在跟合作方小米的共建下不断演进。本文将介绍RSS的最新架构,在小米的实践,以及开源。
一 问题回顾
Shuffle是大数据计算中最为重要的算子。首先,覆盖率高,超过50%的作业都包含至少一个Shuffle[2]。其次,资源消耗大,阿里内部平台Shuffle的CPU占比超过20%,LinkedIn内部Shuffle Read导致的资源浪费高达15%[1],单Shuffle数据量超100T[2]。第三,不稳定,硬件资源的稳定性CPU>内存>磁盘≈网络,而Shuffle的资源消耗是倒序。OutOfMemory和Fetch Failure可能是Spark作业最常见的两种错误,前者可以通过调参解决,而后者需要系统性重构Shuffle。
传统Shuffle如下图所示,Mapper把Shuffle数据按PartitionId排序写盘后交给External Shuffle Service(ESS)管理,Reducer从每个Mapper Output中读取属于自己的Block。
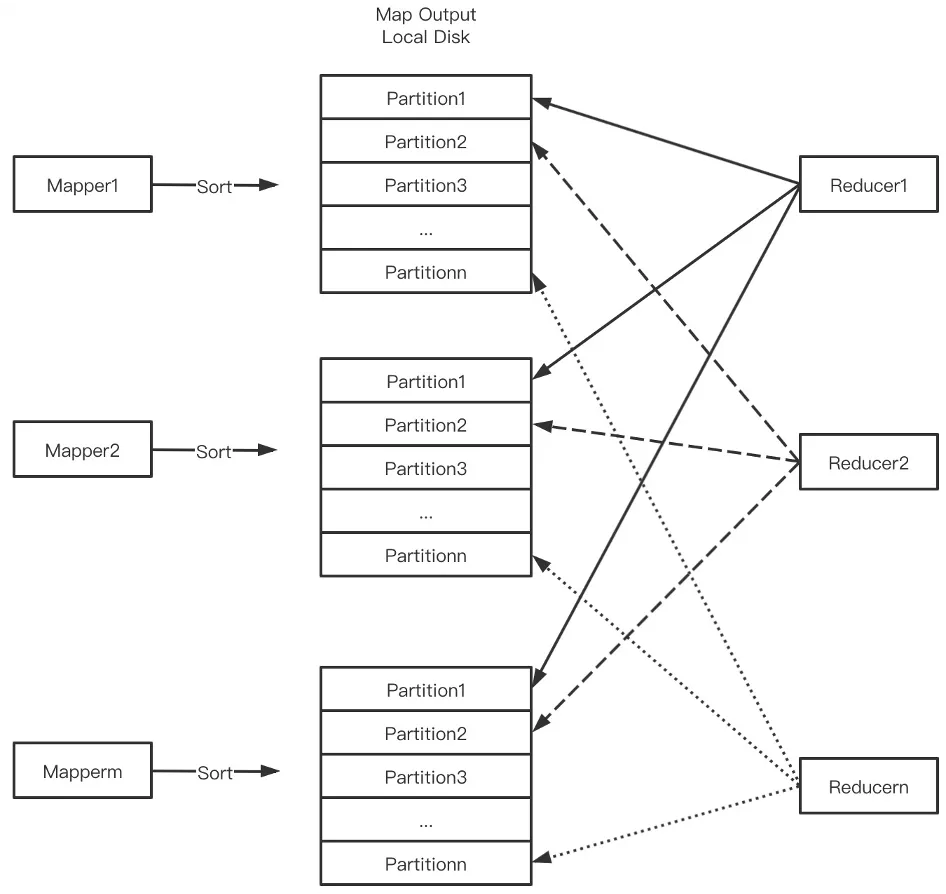
传统Shuffle存在以下问题。
- 本地盘依赖限制了存算分离。存算分离是近年来兴起的新型架构,它解耦了计算和存储,可以更灵活地做机型设计:计算节点强CPU弱磁盘,存储节点强磁盘强网络弱CPU。计算节点无状态,可根据负载弹性伸缩。存储端,随着对象存储(OSS, S3)+数据湖格式(Delta, Iceberg, Hudi)+本地/近地缓存等方案的成熟,可当作容量无限的存储服务。用户通过计算弹性+存储按量付费获得成本节约。然而,Shuffle对本地盘的依赖限制了存算分离。
- 写放大。当Mapper Output数据量超过内存时触发外排,从而引入额外磁盘IO。
- 大量随机读。Mapper Output属于某个Reducer的数据量很小,如Output 128M,Reducer并发2000,则每个Reducer只读64K,从而导致大量小粒度随机读。对于HDD,随机读性能极差;对于SSD,会快速消耗SSD寿命。
- 高网络连接数,导致线程池消耗过多CPU,带来性能和稳定性问题。
- Shuffle数据单副本,大规模集群场景坏盘/坏节点很普遍,Shuffle数据丢失引发的Stage重算带来性能和稳定性问题。
二 RSS发展历程
针对Shuffle的问题,工业界尝试了各种方法,近两年逐渐收敛到Push Shuffle的方案。
1 Sailfish
Sailfish3最早提出Push Shuffle + Partition数据聚合的方法,对大作业有20%-5倍的性能提升。Sailfish魔改了分布式文件系统KFS[4],不支持多副本。
2 Dataflow
Goolge BigQuery和Cloud Dataflow5实现了Shuffle跟计算的解耦,采用多层存储(内存+磁盘),除此之外没有披露更多技术细节。
3 Riffle
Facebook Riffle2采用了在Mapper端Merge的方法,物理节点上部署的Riffle服务负责把此节点上的Shuffle数据按照PartitionId做Merge,从而一定程度把小粒度的随机读合并成较大粒度。
4 Cosco
Facebook Cosco[6]7采用了Sailfish的方法并做了重设计,保留了Push Shuffle + Parititon数据聚合的核心方法,但使用了独立服务。服务端采用Master-Worker架构,使用内存两副本,用DFS做持久化。Cosco基本上定义了RSS的标准架构,但受到DFS的拖累,性能上并没有显著提升。
5 Zeus
Uber Zeus[8]9同样采用了去中心化的服务架构,但没有类似etcd的角色维护Worker状态,因此难以做状态管理。Zeus通过Client双推的方式做多副本,采用本地存储。
6 RPMP
Intel RPMP10依靠RDMA和PMEM的新硬件来加速Shuffle,并没有做数据聚合。
7 Magnet
LinkedIn Magnet1融合了本地Shuffle+Push Shuffle,其设计哲学是"尽力而为",Mapper的Output写完本地后,Push线程会把数据推给远端的ESS做聚合,且不保证所有数据都会聚合。受益于本地Shuffle,Magnet在容错和AE的支持上的表现更好(直接Fallback到传统Shuffle)。Magnet的局限包括依赖本地盘,不支持存算分离;数据合并依赖ESS,对NodeManager造成额外压力;Shuffle Write同时写本地和远端,性能达不到最优。Magnet方案已经被Apache Spark接纳,成为默认的开源方案。
8 FireStorm
FireStorm11混合了Cosco和Zeus的设计,服务端采用Master-Worker架构,通过Client多写实现多副本。FireStorm使用了本地盘+对象存储的多层存储,采用较大的PushBlock(默认3M)。FireStorm在存储端保留了PushBlock的元信息,并记录在索引文件中。FireStorm的Client缓存数据的内存由Spark MemoryManager进行管理,并通过细颗粒度的内存分配(默认3K)来尽量避免内存浪费。
从上述描述可知,当前的方案基本收敛到Push Shuffle,但在一些关键设计上的选择各家不尽相同,主要体现在:
- 集成到Spark内部还是独立服务。
- RSS服务侧架构,选项包括:Master-Worker,含轻量级状态管理的去中心化,完全去中心化。
- Shuffle数据的存储,选项包括:内存,本地盘,DFS,对象存储。
- 多副本的实现,选项包括:Client多推,服务端做Replication。
阿里云RSS12由2020年推出,核心设计参考了Sailfish和Cosco,并且在架构和实现层面做了改良,下文将详细介绍。
三 阿里云RSS核心架构
针对上一节的关键设计,阿里云RSS的选择如下:
- 独立服务。考虑到将RSS集成到Spark内部无法满足存算分离架构,阿里云RSS将作为独立服务提供Shuffle服务。
- Master-Worker架构。通过Master节点做服务状态管理非常必要,基于etcd的状态状态管理能力受限。
- 多种存储方式。目前支持本地盘/DFS等存储方式,主打本地盘,将来会往分层存储方向发展。
- 服务端做Replication。Client多推会额外消耗计算节点的网络和计算资源,在独立部署或者服务化的场景下对计算集群不友好。
下图展示了阿里云RSS的关键架构,包含Client(RSS Client, Meta Service),Master(Resource Manager)和Worker三个角色。Shuffle的过程如下:
- Mapper在首次PushData时请求Master分配Worker资源,Worker记录自己所需要服务的Partition列表。
- Mapper把Shuffle数据缓存到内存,超过阈值时触发Push。
- 隶属同个Partition的数据被Push到同一个Worker做合并,主Worker内存接收到数据后立即向从Worker发起Replication,数据达成内存两副本后即向Client发送ACK,Flusher后台线程负责刷盘。
- Mapper Stage运行结束,MetaService向Worker发起CommitFiles命令,把残留在内存的数据全部刷盘并返回文件列表。
- Reducer从对应的文件列表中读取Shuffle数据。
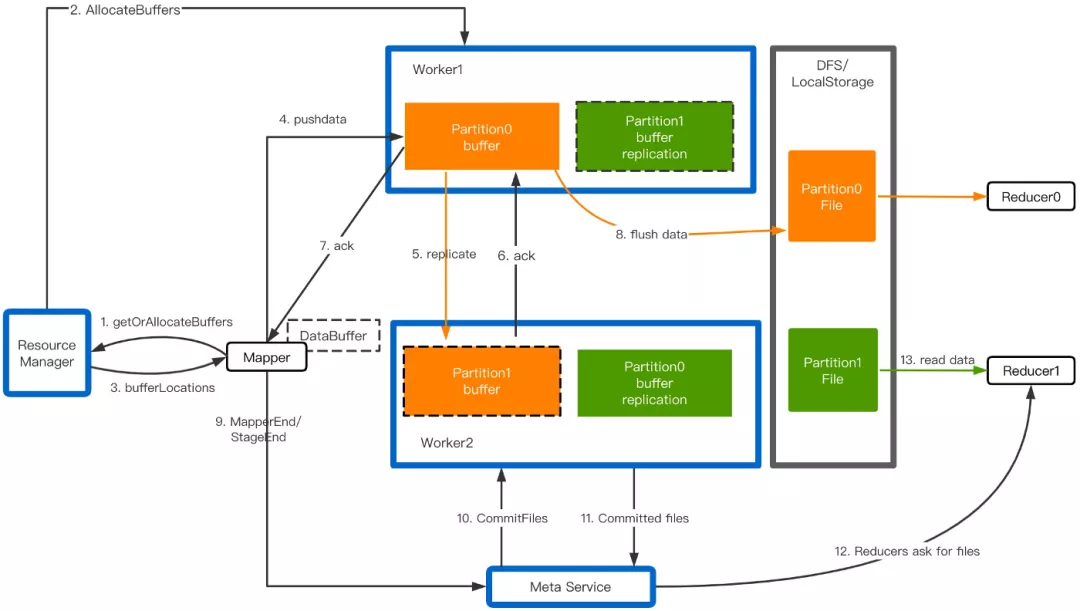
阿里云RSS的核心架构和容错方面的介绍详见[13],本文接下来介绍阿里云RSS近一年的架构演进以及不同于其他系统的特色。
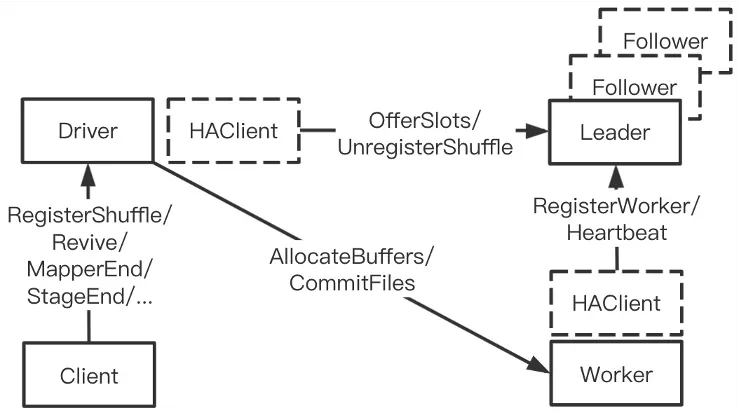
1 状态下沉
RSS采用Master-Worker架构,最初的设计中Master统一负责集群状态管理和Shuffle生命周期管理。集群状态包括Worker的健康度和负载;生命周期包括每个Shuffle由哪些Worker服务,每个Worker所服务的Partition列表,Shuffle所处的状态(Shuffle Write,CommitFile,Shuffle Read),是否有数据丢失等。维护Shuffle生命周期需要较大数据量和复杂数据结构,给Master HA的实现造成阻力。同时大量生命周期管理的服务调用使Master易成为性能瓶颈,限制RSS的扩展性。
为了缓解Master压力,我们把生命周期状态管理下沉到Driver,由Application管理自己的Shuffle,Master只需维护RSS集群本身的状态。这个优化大大降低Master的负载,并使得Master HA得以顺利实现。

2 Adaptive Pusher
在最初的设计中,阿里云RSS跟其他系统一样采用Hash-Based Pusher,即Client会为每个Partition维护一个(或多个[11])内存Buffer,当Buffer超过阈值时触发推送。这种设计在并发度适中的情况下没有问题,而在超大并发度的情况下会导致OOM。例如Reducer的并发5W,在小Buffer[13]的系统中(64K)极端内存消耗为64K5W=3G,在大Buffer[11]的系统中(3M)极端内存消耗为3M5W=146G,这是不可接受的。针对这个问题,我们开发了Sort-Based Pusher,缓存数据时不区分Partition,当总的数据超过阈值(i.e. 64M)时对当前数据按照PartitionId排序,然后把数据Batch后推送,从而解决内存消耗过大的问题。
Sort-Based Pusher会额外引入一次排序,性能上比Hash-Based Pusher略差。我们在ShuffleWriter初始化阶段根据Reducer的并发度自动选择合适的Pusher。
3 磁盘容错
出于性能的考虑,阿里云RSS推荐本地盘存储,因此处理坏/慢盘是保证服务可靠性的前提。Worker节点的DeviceMonitor线程定时对磁盘进行检查,检查项包括IOHang,使用量,读写异常等。此外Worker在所有磁盘操作处(创建文件,刷盘)都会捕捉异常并上报。IOHang、读写异常被认为是Critical Error,磁盘将被隔离并终止该磁盘上的存储服务。慢盘、使用量超警戒线等异常仅将磁盘隔离,不再接受新的Partition存储请求,但已有的Partition服务保持正常。在磁盘被隔离后,Worker的容量和负载将发生变化,这些信息将通过心跳发送给Master。
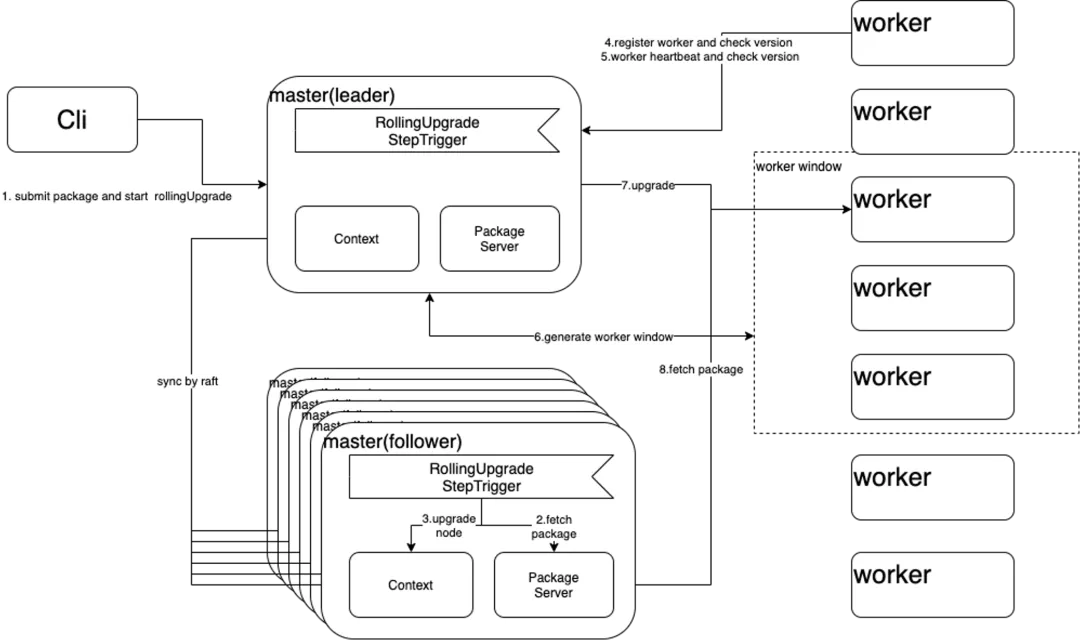
4 滚动升级
RSS作为常驻服务,有永不停服的要求,而系统本身总在向前演进,因此滚动升级是必选的功能。尽管通过Sub-Cluster部署方式可以绕过,即部署多个子集群,对子集群做灰度,灰度的集群暂停服务,但这种方式依赖调度系统感知正在灰度的集群并动态修改作业配置。我们认为RSS应该把滚动升级闭环掉,核心设计如下图所示。Client向Master节点的Leader角色(Master实现了HA,见上文)发起滚动升级请求并把更新包上传给Leader,Leader通过Raft协议修改状态为滚动升级,并启动第一阶段的升级:升级Master节点。Leader首先升级所有的Follower,然后替换本地包并重启。在Leader节点改变的情况下,升级过程不会中断或异常。Master节点升级结束后进入第二阶段:Worker节点升级。RSS采用滑动窗口做升级,窗口内的Worker尽量优雅下线,即拒绝新的Partition请求,并等待本地Shuffle结束。为了避免等待时间过长,会设置超时时间。此外,窗口内的Worker选择会尽量避免同时包含主从两副本以降低数据丢失的概率。
5 混乱测试框架
对于服务来说,仅依靠UT、集成测试、e2e测试等无法保证服务可靠性,因为这些测试无法覆盖线上复杂环境,如坏盘、CPU过载、网络过载、机器挂掉等。RSS要求在出现这些复杂情况时保持服务稳定,为了模拟线上环境,我们开发了仿真(混乱)测试框架,在测试环境中模拟线上可能出现的异常,同时保证满足RSS运行的最小运行环境,即至少3个Master节点和2个Worker节点可用,并且每个Worker节点至少有一块盘。我们持续对RSS做此类压力测试。
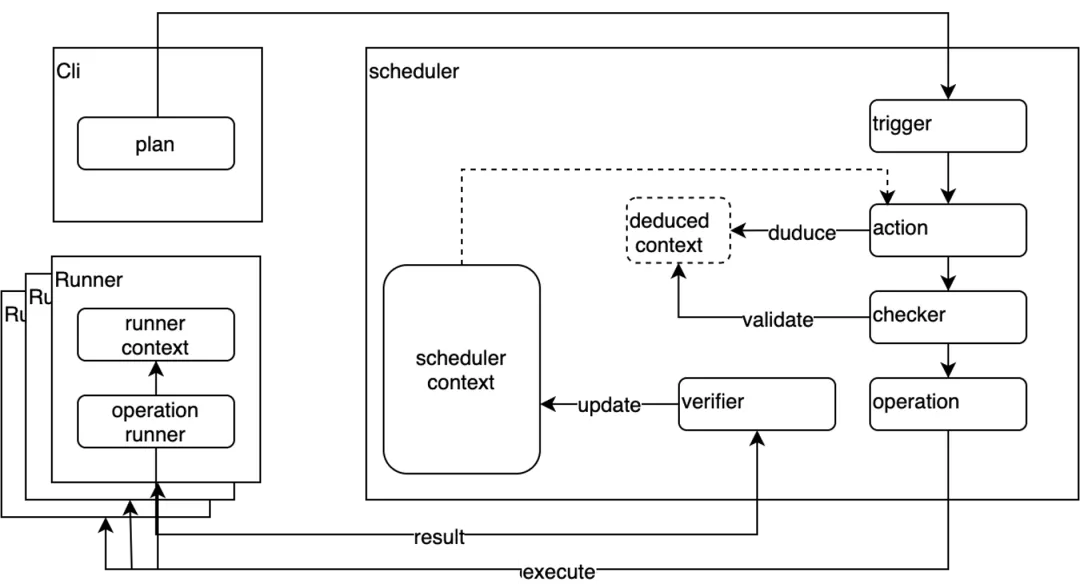
仿真测试框架架构如下图所示,首先定义测试Plan来描述事件类型、事件触发的顺序及持续时间,事件类型包括节点异常,磁盘异常,IO异常,CPU过载等。客户端将Plan提交给Scheduler,Scheduler根据Plan的描述给每个节点的Runner发送具体的Operation,Runner负责具体执行并汇报当前节点的状态。在触发Operation之前,Scheduler会推演该事件发生产生的后果,若导致无法满足RSS的最小可运行环境,将拒绝此事件。
我们认为仿真测试框架的思路是通用设计,可以推广到更多的服务测试中。
6 多引擎支持
Shuffle是通用操作,不跟引擎绑定,因此我们尝试了多引擎支持。当前我们支持了Hive+RSS,同时也在探索跟流计算引擎(Flink),MPP引擎(Presto)结合的可能性。尽管Hive和Spark都是批计算引擎,但Shuffle的行为并不一致,最大的差异是Hive在Mapper端做排序,Reducer只做Merge,而Spark在Reducer端做排序。由于RSS暂未支持计算,因此需要改造Tez支持Reducer排序。此外,Spark有干净的Shuffle插件接口,RSS只需在外围扩展,而Tez没有类似抽象,在这方面也有一定侵入性。
当前大多数引擎都没有Shuffle插件化的抽象,需要一定程度的引擎修改。此外,流计算和MPP都是上游即时Push给下游的模式,而RSS是上游Push,下游Pull的模式,这两者如何结合也是需要探索的。
7 测试
我们对比了阿里云RSS、Magent及开源系统X。由于大家的系统还在向前演进,因此测试结果仅代表当前。
测试环境
Header 1: ecs.g6e.4xlarge, 16 2.5GHz/3.2GHz, 64GiB, 10Gbps
Worker 3: ecs.g6e.8xlarge, 32 2.5GHz/3.2GHz, 128GiB, 10Gbps
阿里云RSS vs. Magnet
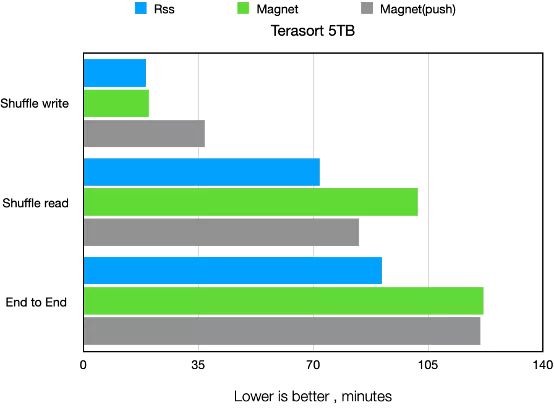
5T Terasort的性能测试如下图所示,如上文描述,Magent的Shuffle Write有额外开销,差于RSS和传统做法。Magent的Shuffle Read有提升,但差于RSS。在这个Benchmark下,RSS明显优于另外两个,Magent的e2e时间略好于传统Shuffle。
阿里云RSS vs. 开源系统X
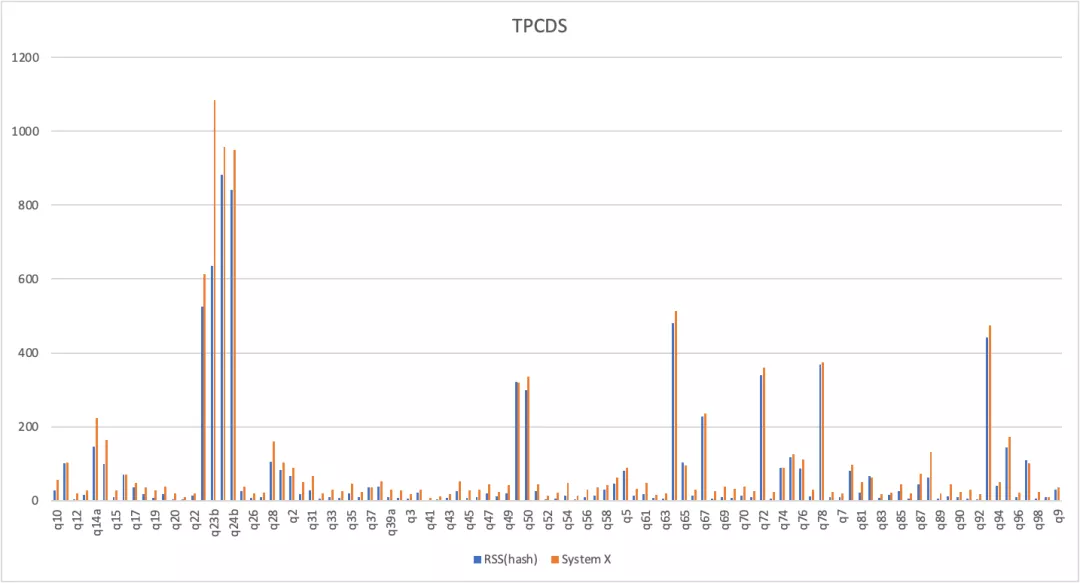
RSS跟开源系统X在TPCDS-3T的性能对比如下,总时间RSS快了20%。
稳定性
在稳定性方面,我们测试了Reducer大规模并发的场景,Magnet可以跑通但时间比RSS慢了数倍,System X在Shuffle Write阶段报错。
四 阿里云RSS在小米的实践
1 现状及痛点
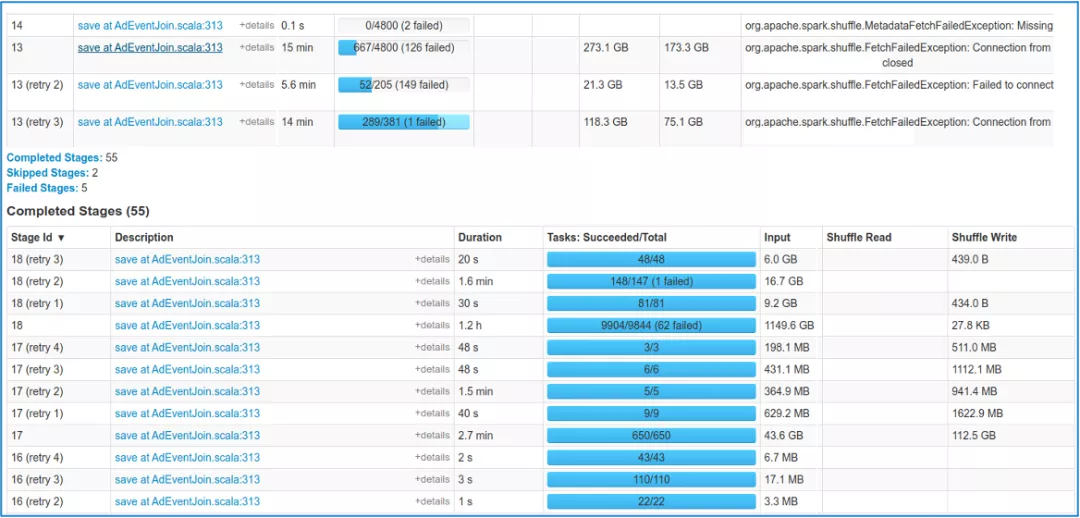
小米的离线集群以Yarn+HDFS为主,NodeManager和DataNode混合部署。Spark是主要的离线引擎,支撑着核心计算任务。Spark作业当前最大的痛点集中在Shuffle导致的稳定性差,性能差和对存算分离架构的限制。在进行资源保证和作业调优后,作业失败原因主要归结为Fetch Failure,如下图所示。由于大部分集群使用的是HDD,传统Shuffle的高随机读和高网络连接导致性能很差,低稳定性带来的Stage重算会进一步加剧性能回退。此外,小米一直在尝试利用存算分离架构的计算弹性降低成本,但Shuffle对本地盘的依赖造成了阻碍。

2 RSS在小米的落地
小米一直在关注Shuffle优化相关技术,21年1月份跟阿里云EMR团队就RSS项目建立了共创关系,3月份第一个生产集群上线,开始接入作业,6月份第一个HA集群上线,规模达100+节点,9月份第一个300+节点上线,集群默认开启RSS,后续规划会进一步扩展RSS的灰度规模。
在落地的过程,小米主导了磁盘容错的开发,大大提高了RSS的服务稳定性,技术细节如上文所述。此外,在前期RSS还未完全稳定阶段,小米在多个环节对RSS的作业进行了容错。在调度端,若开启RSS的Spark作业因Shuffle报错,则Yarn的下次重试会回退到ESS。在ShuffleWriter初始化阶段,小米主导了自适应Fallback机制,根据当前RSS集群的负载和作业的特征(如Reducer并发是否过大)自动选择RSS或ESS,从而提升稳定性。
3 效果
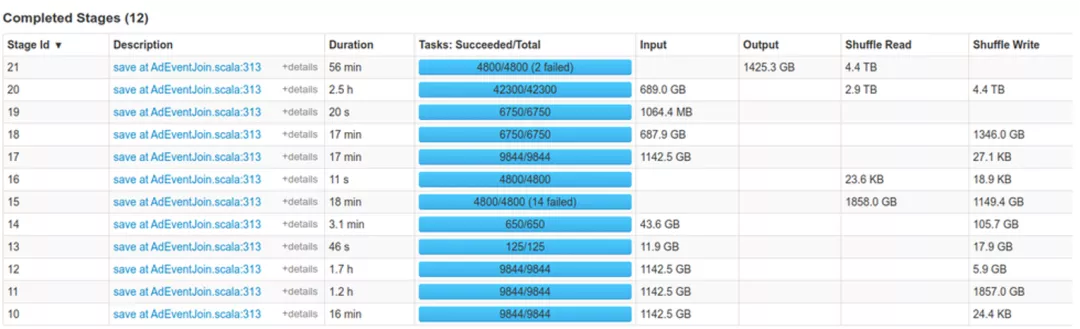
接入RSS后,Spark作业的稳定性、性能都取得了显著提升。之前因Fetch Failure失败的作业几乎不再失败,性能平均有20%的提升。下图展示了接入RSS前后作业稳定性的对比。
ESS:
RSS:
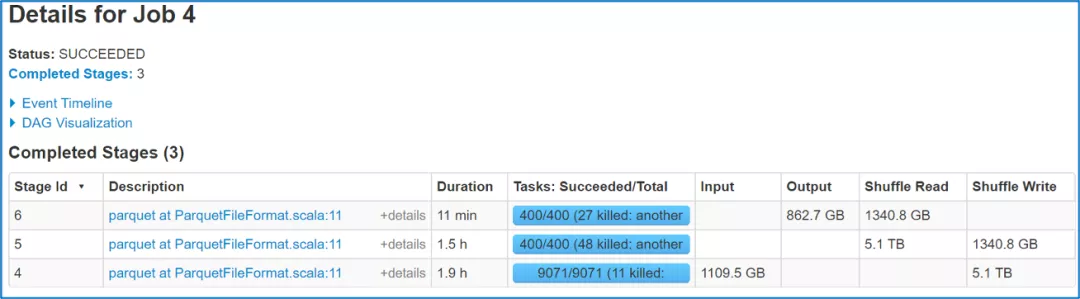
下图展示了接入RSS前后作业运行时间的对比。
ESS:
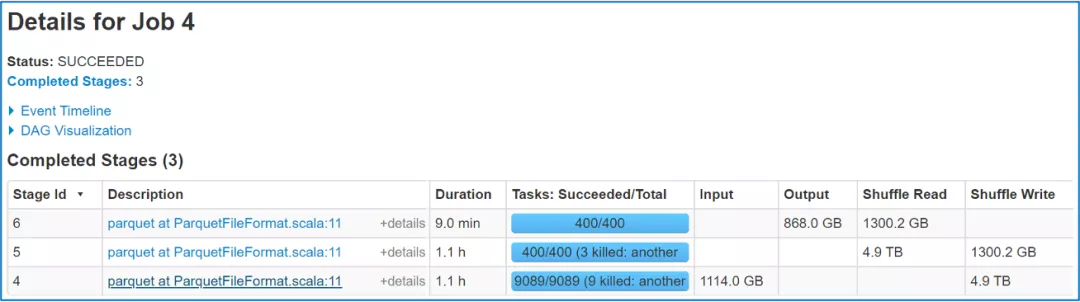
RSS:
在存算分离方面,小米海外某集群接入RSS后,成功上线了1600+ Core的弹性集群,且作业运行稳定。
在阿里云EMR团队及小米Spark团队的共同努力下,RSS带来的稳定性和性能提升得到了充分的验证。后续小米将会持续扩大RSS集群规模以及作业规模,并且在弹性资源伸缩场景下发挥更大的作用。
五 开源
重要的事说三遍:“阿里云RSS开源啦!” X 3
git地址: https://github.com/alibaba/RemoteShuffleService
开源代码包含核心功能及容错,满足生产要求。
计划中的重要Feature:
- AE
- Spark多版本支持
- Better 流控
- Better 监控
- Better HA
- 多引擎支持
欢迎各路开发者共建!
六 Reference
[1]Min Shen, Ye Zhou, Chandni Singh. Magnet: Push-based Shuffle Service for Large-scale Data Processing. VLDB 2020.
[2]Haoyu Zhang, Brian Cho, Ergin Seyfe, Avery Ching, Michael J. Freedman. Riffle: Optimized Shuffle Service for Large-Scale Data Analytics. EuroSys 2018.
[3]Sriram Rao, Raghu Ramakrishnan, Adam Silberstein. Sailfish: A Framework For Large Scale Data Processing. SoCC 2012.
[4]KFS. http://code.google.com/p/kosmosfs/
[5]Google Dataflow Shuffle. https://cloud.google.com/blog/products/data-analytics/how-distributed-shuffle-improves-scalability-and-performance-cloud-dataflow-pipelines
[6]Cosco: An Efficient Facebook-Scale Shuffle Service. Cosco: An Efficient Facebook-Scale Shuffle Service - Databricks
[7]Flash for Apache Spark Shuffle with Cosco. Flash for Apache Spark Shuffle with Cosco - Databricks
[8]Uber Zeus. Zeus: Uber's Highly Scalable and Distributed Shuffle as a Service - Databricks
[9]Uber Zeus. https://github.com/uber/RemoteShuffleService
[10]Intel RPMP. Accelerating Apache Spark Shuffle for Data Analytics on the Cloud with Remote Persistent Memory Pools - Databricks
[11]Tencent FireStorm. https://github.com/Tencent/Firestorm
[12]Aliyun RSS在趣头条的实践. 降本增效利器!趣头条Spark Remote Shuffle Service最佳实践-阿里云开发者社区
[13]Aliyun RSS架构. Serverless Spark的弹性利器 - EMR Shuffle Service-阿里云开发者社区
本文为阿里云原创内容,未经允许不得转载。
阿里云EMR Remote Shuffle Service在小米的实践的更多相关文章
- 降本增效利器!趣头条Spark Remote Shuffle Service最佳实践
王振华,趣头条大数据总监,趣头条大数据负责人 曹佳清,趣头条大数据离线团队高级研发工程师,曾就职于饿了么大数据INF团队负责存储层和计算层组件研发,目前负责趣头条大数据计算层组件Spark的建设 范振 ...
- 阿里云EMR集群初始化后的开发准备工作
前言:EMR的集群使用越来越普遍,但是每一次的集群释放到集群的重新创建,期间总有一些反复的工作需要查询与配置.为方便后续工作查阅,现在对集群初始化后的工作进行大概的梳理如下. ...
- 阿里云上万个 Kubernetes 集群大规模管理实践
点击下载<不一样的 双11 技术:阿里巴巴经济体云原生实践> 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击上方图片即可下载! 作者 | 汤志敏,阿里 ...
- 悠星网络基于阿里云分析型数据库PostgreSQL版的数据实践
说到“大数据”,当下这个词很火,各行各业涉及到数据的,目前都在提大数据,提数据仓库,数据挖掘或者机器学习,但同时另外一个热门的名词也很火,那就是“云”.越来越多的企业都在搭建属于自己的云平台,也有一些 ...
- EventBridge助力阿里云视觉智能开放平台AI智能存储实践
本文作者:李建,阿里巴巴达摩院技术专家. 01 视觉智能开放平台(VIAPI)业务场景介绍 阿里云视觉智能开放平台(简称 VIAPI),是基于之前很多技术实践经验积累的 AI 能力的沉淀平台.目前整个 ...
- 阿里云对象存储OSS访问控制
阿里云对象存储OSS的Android SDK提供了STS鉴权模式和自签名模式来保障移动终端的安全性. OSS可以通过阿里云STS (Security Token Service) 进行临时授权访问.交 ...
- 阿里云 centos 服务器无法自动挂载 nas 的问题
阿里云服务器 centos 7.3 ,开始是通过 fstab 配置的自动挂载: xxx.cn-hangzhou.nas.aliyuncs.com:/ /nas nfs4 auto 0 0 但服务器启动 ...
- android 阿里云oss上传
购买了阿里云的oss空间,于是用它来存储图片,不过中间的使用算是出了些问题,导致很长的才成功. 不得不说,阿里云文档真的是无力吐槽...乱七八糟的.我完全是东拼西凑,才完成的图片上传功能. 走了很多的 ...
- 云计算之路-阿里云上:愚人节被阿里云OCS愚
今天是愚人节,而我们却被阿里云OCS愚,很多地方的缓存一直不过期,造成很多页面中的数据一直不更新.这篇博文将向您分享我们这两天遇到的OCS问题. 阿里云OCS(Open Cache Service)是 ...
- 持续优化云原生体验,阿里云在Serverless容器与多云上的探索
近日,阿里云宣布推出Serverless Kubernetes服务此举意在降低容器技术的使用门槛.简化容器平台运维.并同时发布阿里云服务对Open Service Broker API标准支持,通过一 ...
随机推荐
- KTL 一个支持C++14编辑公式的K线技术工具平台 - 第八版,数据解析。附带通达信gbbq解码。
K,K线,Candle蜡烛图. T,技术分析,工具平台 L,公式Language语言使用c++14,Lite小巧简易. 项目仓库:https://github.com/bbqz007/KTL 国内仓库 ...
- 如何让AR物体更真实?
在增强现实中,除了虚拟物体本身的模型材质等因素,影响物体真实性的主要是光照.反射.阴影.接下来3DCAT实时渲染云平台将带您从这三个方面探索如何让AR物体更真实! AR光估测 要让一个虚拟物体很好的融 ...
- View事件机制源码分析
目录介绍 01.Android中事件分发顺序 02.Activity的事件分发机制 2.1 源码分析 2.2 点击事件调用顺序 2.3 得出结论 03.ViewGroup事件的分发机制 3.1 看一下 ...
- 从静态到动态化,Python数据可视化中的Matplotlib和Seaborn
本文分享自华为云社区<Python数据可视化大揭秘:Matplotlib和Seaborn高效应用指南>,作者: 柠檬味拥抱. 安装Matplotlib和Seaborn 首先,确保你已经安装 ...
- Kingbase ES 函数返回-return语句
文章概要: 本文在https://www.cnblogs.com/kingbase/p/15703611.html 一文的基础上总结了Kingbase ES中函数能支持的return语句,整体上兼容o ...
- Java开发岗面试题小结
8种基本数据类型 类型名称 关键字 占用内存 取值范围 字节型 byte 1 字节 -128~127 短整型 short 2 字节 -32768~32767 整型 int 4 字节 -21474836 ...
- PyQt5 GUI编程(QMainWindow与QWidget模块结合使用)
一.简介 QWidget是所有用户界面对象的基类,而QMainWindow用于创建主应用程序窗口的类.它是QWidget的一个子类,提供了创建具有菜单栏.工具栏.状态栏等的主窗口所需的功能.上篇主要介 ...
- 【FAQ】接入HMS Core广告服务中的常见问题总结和解决方法
HMS Core广告服务(Ads Kit)为开发者提供流量变现服务和广告标识服务,依托华为终端能力,整合资源,帮助开发者获取高质量的广告内容.同时提供转化跟踪参数服务,支持三方监测平台.广告主进行转化 ...
- Qt:Qt自适应高分辨率屏幕
现在的电脑分辨率越来越高,DPI也越来越大,使用Qt创建出来的界面,在小分辨率电脑上显示的很好,但是在大分辨率电脑上显示异常,感觉边框被压缩了,看起来很不协调. 从Qt 5.6 还是从Qt 5.14 ...
- mysql迁移sqlServer和mybatisPlus下查询语句转换为SqlServer2008
mysql数据迁移sqlServer2008 mybatisPlus下查询语句转换 一.mysql数据迁移到sqlServer2008中(包括数据结构和数据) 最近公司项目需要使用sqlServer以 ...