释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇--简洁版],支持Linux/Windows部署安装
- 效果展示
PaddleNLP Pipelines 是一个端到端智能文本产线框架,面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力。本项目将通过一种简单高效的方式搭建一套语义检索系统,使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配。
基于ES(ElasticSearch)打造高效的语义搜索系统效果展示链接
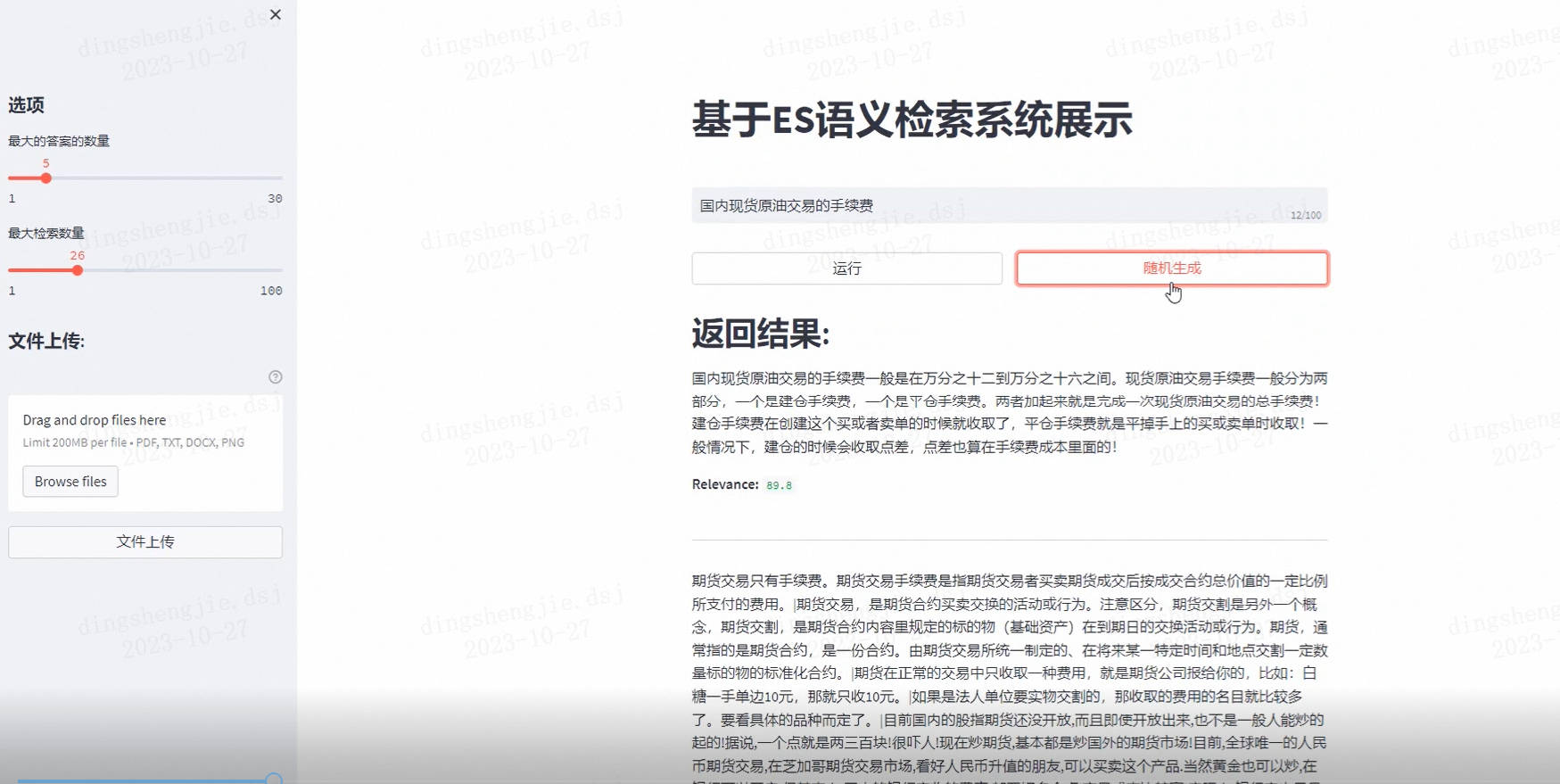
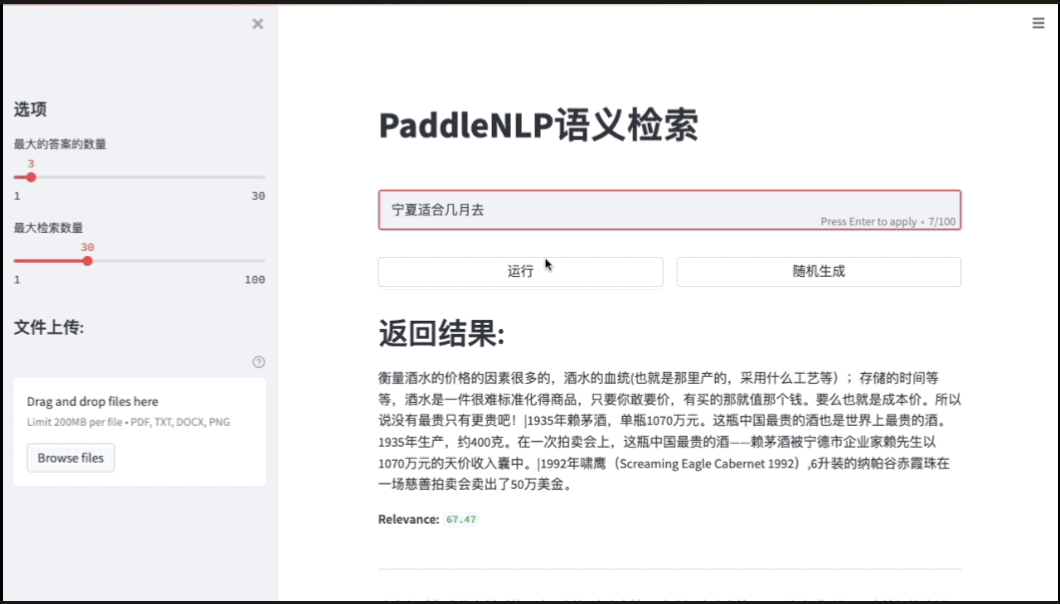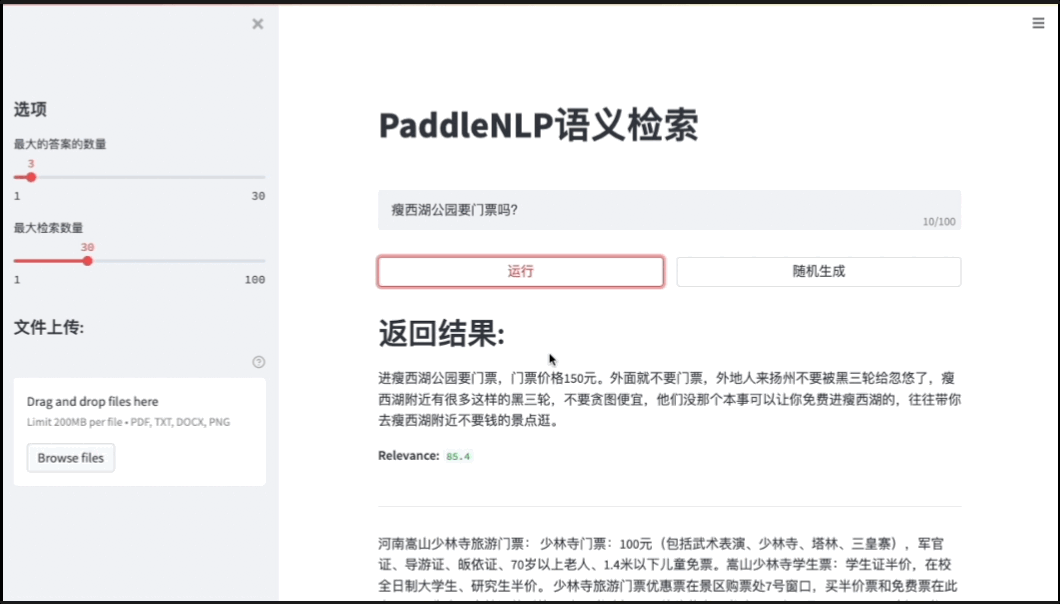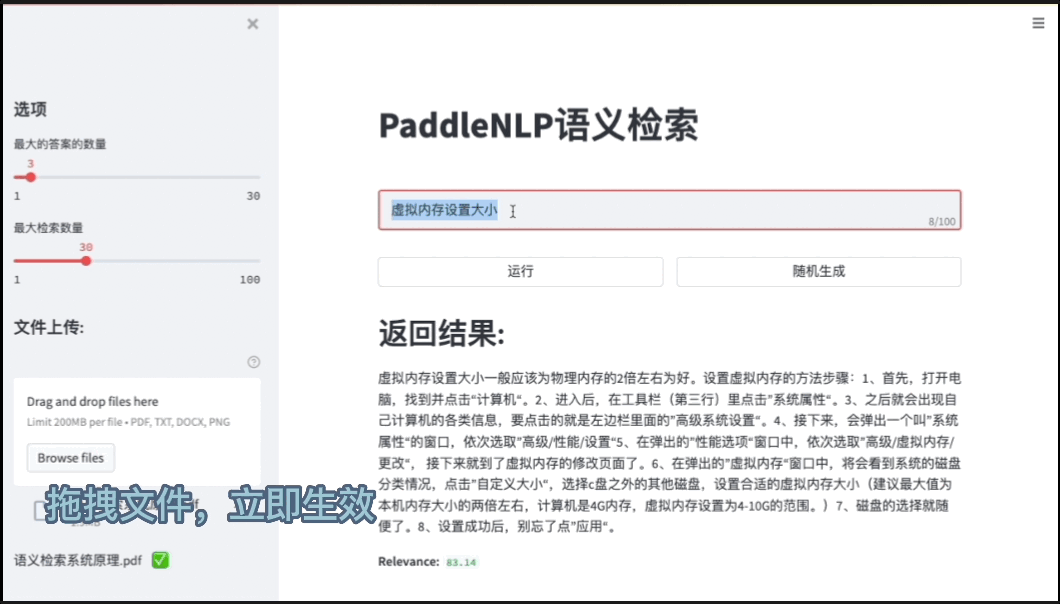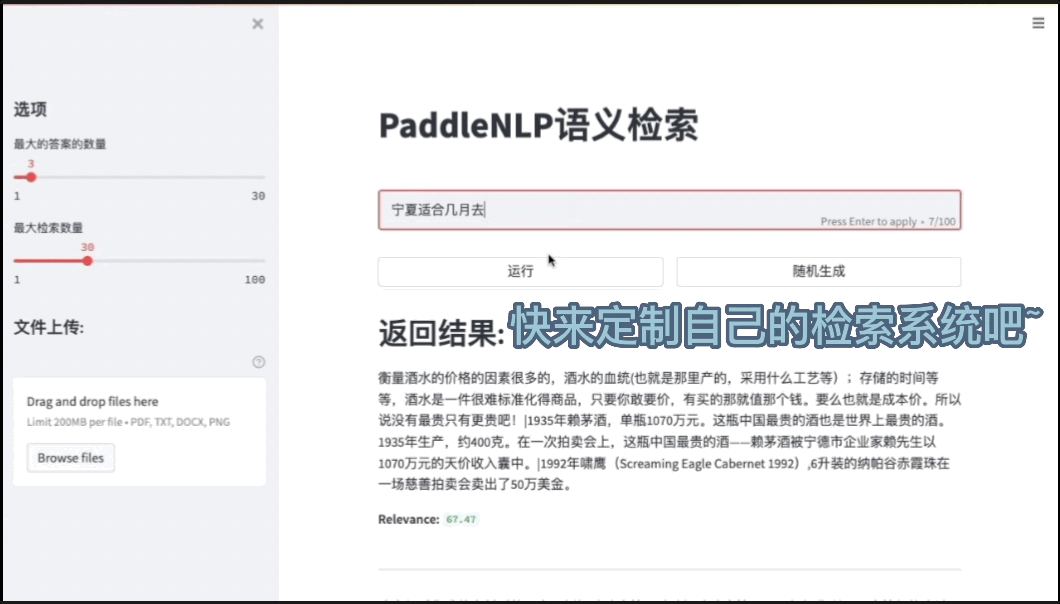
- 点击链接进行跳转:
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇---完整版],支持Linux/Windows部署安装
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[2.项目讲解篇],支持Linux/Windows部署安装
A1.Windows下搭建语义检索系统
conda activate temp_es
e:
cd /temp_ES/PaddleNLP-develop/pipelines
腾讯镜像:-i https://mirrors.cloud.tencent.com/pypi/simple
pip list版本:
paddle-pipelines 0.6.0
paddlenlp 2.6.0
paddlepaddle 2.5.1
streamlit 1.11.1
pip install streamlit1.11.1 -i https://mirrors.cloud.tencent.com/pypi/simple
pip install altair4.2.2 -i https://mirrors.cloud.tencent.com/pypi/simple
A1.1运行环境安装
git clone https://github.com/tvst/htbuilder.git
cd htbuilder/
python setup.py install
A1.2 paddlenlp安装(包含了paddlenlp)
pip install paddlenlp==2.6.0 -i https://mirrors.cloud.tencent.com/pypi/simple
#pip install --upgrade paddle-pipelines -i https://pypi.tuna.tsinghua.edu.cn/simple
#或者源码进行安装最新版本
cd ${HOME}/PaddleNLP/pipelines/
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python setup.py install
A1.3下载pipelines源代码:github下载 or 手动下载
git clone https://github.com/PaddlePaddle/PaddleNLP.git
cd PaddleNLP/pipelines
A1.4 运行案例查看效果
* 我们建议在 GPU 环境下运行本示例,运行速度较快
```python examples/semantic-search/semantic_search_example.py --device gpu```
* 如果只有 CPU 机器,安装CPU版本的Paddle后,可以通过 --device 参数指定 cpu 即可, 运行耗时较长
```python examples/semantic-search/semantic_search_example.py --device cpu```
模型相关修改见3.3
A2.ES相关配置
A2.1 版本安装 ES版本提前官网下载好即可,放在对应路径,进入虚拟环境
官网:https://www.elastic.co/cn/downloads/elasticsearch
https://blog.csdn.net/sinat_39620217/article/details/133984629
A2.2可视化工具Kibana
elasticsearch可视化工具Kibana:为了更好的对数据进行管理,可以使用Kibana可视化工具进行管理和分析,下载链接为Kibana,下载完后解压,直接双击运行 bin\kibana.bat即可。
链接:http://localhost:5601/app/home
A2.3 ES修改:config
需要编辑config/elasticsearch.yml,在末尾添加:elasticsearch.yml 把xpack.security.enabled 设置成false,
xpack.security.enabled: false然后直接双击bin(右击管理员)目录下的elasticsearch.bat即可启动(elasticsearch-8.3.3\bin\elasticsearch.bat)。
Elastic search 日志显示错误 exception during geoip databases update
ingest.geoip.downloader.enabled: false
#查看es是否成功启动
curl http://localhost:9200/_aliases?pretty=true
A2.4文档数据写入ann索引库(重点)
官网直接给这条语句,但会报错的,需要修改一下参数。
python utils/offline_ann.py --index_name dureader_robust_query_encoder
- 可行命令:
python utils/offline_ann.py --index_name dureader_robust_query_encoder --doc_dir data/dureader_dev --search_engine elastic --embed_title True --delete_index --device cpu --query_embedding_model rocketqa-zh-nano-query-encoder --passage_embedding_model rocketqa-zh-nano-para-encoder --embedding_dim 312
- 关注三个参数
- query_embedding_model rocketqa-zh-nano-query-encoder
- passage_embedding_model rocketqa-zh-nano-para-encoder
- embedding_dim 312
这里都使用nano版本模型,向量维度312
(尝试过可以换成base模型,768维度,需要注意的是:启动 RestAPI 模型服务的时候,这三个参数一定要跟这里一致,否则报错,或者检索无效)
- 查看es中是否已经是有数据:
curl http://localhost:9200/dureader_robust_query_encoder/_search
- 如果需要重新写入数据,则需要先删除索引:
curl -XDELETE http://localhost:9200/dureader_robust_query_encoder
- 基于Kibana查看
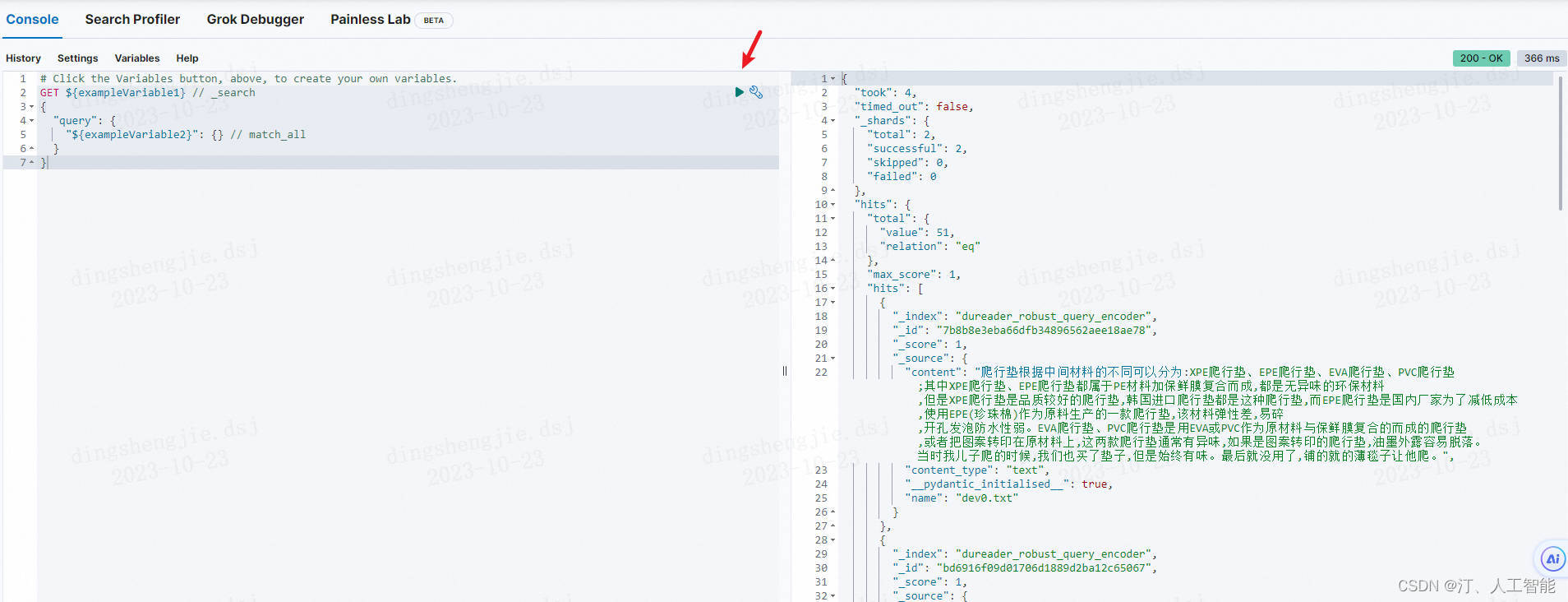
A3.启动Rest API模型服务
这里要用要用anaconda powershell,不能用Anaconda prompt !!!
这里要用anaconda powershell !!!
这里要用anaconda powershell !!!
#指定语义检索系统的Yaml配置文件,Linux/macos
export PIPELINE_YAML_PATH=rest_api/pipeline/semantic_search.yaml
#指定语义检索系统的Yaml配置文件,Windows powershell
$env:PIPELINE_YAML_PATH='rest_api/pipeline/semantic_search.yaml'
# 使用端口号 8891 启动模型服务
python rest_api/application.py 8891
#主要关注这三个参数:
#embedding_dim: 312
#query_embedding_model: rocketqa-zh-nano-query-encoder
#passage_embedding_model: rocketqa-zh-nano-para-encoder
#后面Ranker的model_name_or_path不用跟这里一致
成功显示:端口链接显示
A4.启动WebUI
streamlit安装
pip install streamlit==1.11.1 -i https://mirrors.cloud.tencent.com/pypi/simple
#anaconda powershell
#配置模型服务地址
$env:API_ENDPOINT='http://127.0.0.1:8891'
#在指定端口 8502 启动 WebUI
python -m streamlit run ui/webapp_semantic_search.py --server.port 8502
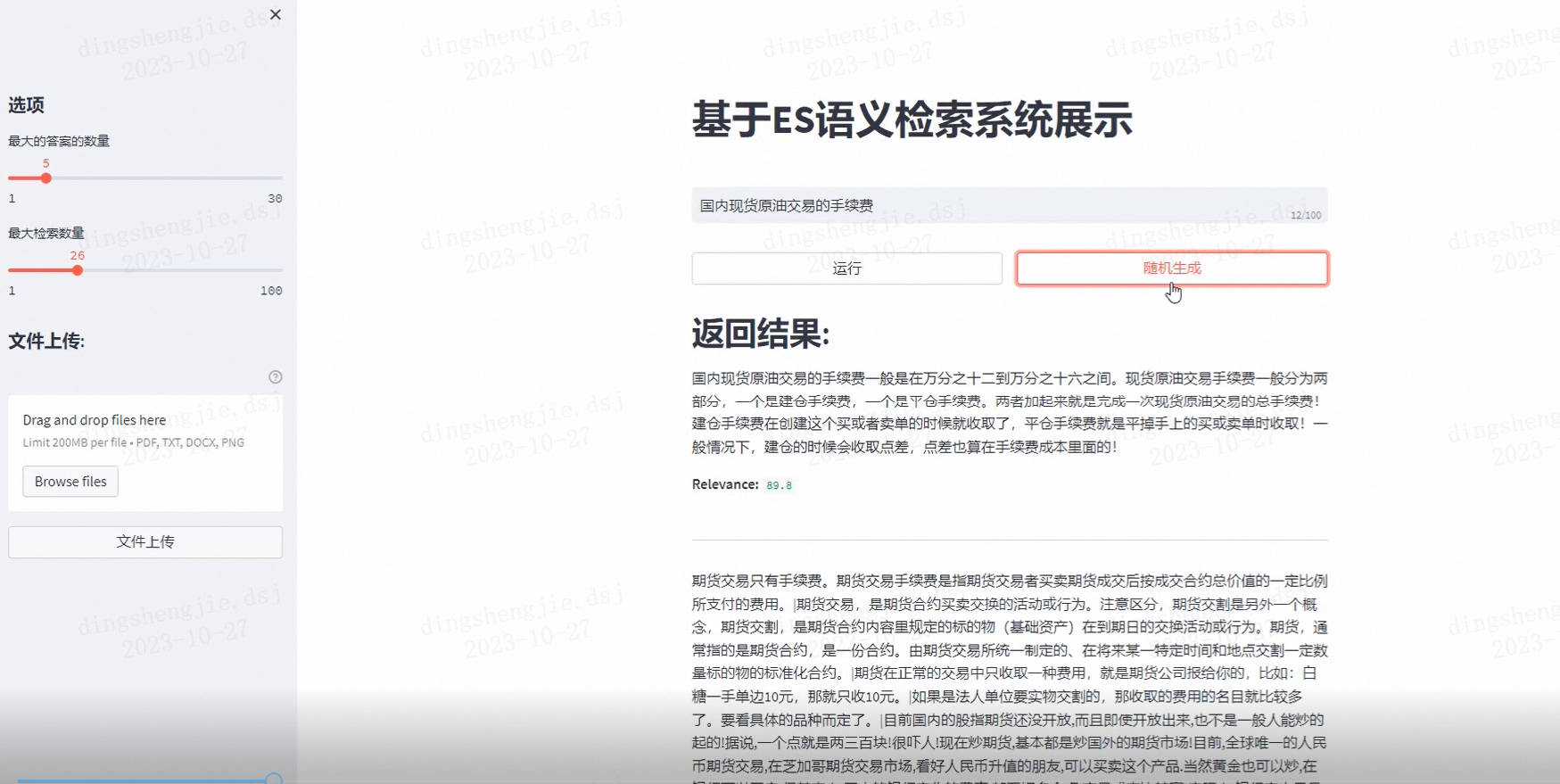
- 本地打开这个网页可以使用语义检索系统了:
http://127.0.0.1:8502
A5. 数据更新
数据更新的方法有两种,第一种使用前面的 utils/offline_ann.py进行数据更新,另一种是使用前端界面的文件上传进行数据更新,支持txt,pdf,image,word的格式,以txt格式的文件为例,每段文本需要使用空行隔开,程序会根据空行进行分段建立索引,示例数据如下(demo.txt):
兴证策略认为,最恐慌的时候已经过去,未来一个月市场迎来阶段性修复窗口。
从海外市场表现看,
对俄乌冲突的恐慌情绪已显著释放,
海外权益市场也从单边下跌转入双向波动。
长期,继续聚焦科技创新的五大方向。1)新能源(新能源汽车、光伏、风电、特高压等),2)新一代信息通信技术(人工智能、大数据、云计算、5G等),3)高端制造(智能数控机床、机器人、先进轨交装备等),4)生物医药(创新药、CXO、医疗器械和诊断设备等),5)军工(导弹设备、军工电子元器件、空间站、航天飞机等)。
B.linux下搭建语义检索系统
B.1 GPU版本
提示:Centos系统下坑比较多,需要使用paddle 2.4.2 Ubuntu推荐使用2.5.1 or develop。
1.1安装依赖
conda create -n paddlenlp_gpu python=3.8
conda activate paddlenlp_gpu
python -m pip install --upgrade pip
PaddleGPU、CUDA cudnn安装见:https://blog.csdn.net/sinat_39620217/article/details/131675175
当前版本:cuda11.2、paddle-develop版本(2.5.1存在bug解决方案见上述链接,可以使用2.5.2版本)
ImportError: libssl.so.1.1: cannot open shared object file: No such file or directory等问题
- 版本查看:
pip install paddlepaddle-gpu==
(from versions: 1.8.5.post97, 1.8.5.post107, 2.0.0rc0, 2.0.0rc1, 2.0.0, 2.0.1, 2.0.2, 2.1.0, 2.1.1, 2.1.2, 2.1.3, 2.2.0rc0, 2.2.0, 2.2.1, 2.2.2, 2.3.0rc0, 2.3.0, 2.3.1, 2.3.2, 2.4.0rc0, 2.4.0, 2.4.1, 2.4.2, 2.5.0rc0, 2.5.0rc1, 2.5.0, 2.5.1, 2.5.2)
pip install paddlenlp==
(from versions: 2.0.0a0, 2.0.0a1, 2.0.0a2, 2.0.0a3, 2.0.0a4, 2.0.0a5, 2.0.0a6, 2.0.0a7, 2.0.0a8, 2.0.0a9, 2.0.0b0, 2.0.0b1, 2.0.0b2, 2.0.0b3, 2.0.0b4, 2.0.0rc0, 2.0.0rc1, 2.0.0rc2, 2.0.0rc3, 2.0.0rc4, 2.0.0rc5, 2.0.0rc6, 2.0.0rc7, 2.0.0rc8, 2.0.0rc9, 2.0.0rc10, 2.0.0rc11, 2.0.0rc12, 2.0.0rc13, 2.0.0rc14, 2.0.0rc15, 2.0.0rc16, 2.0.0rc17, 2.0.0rc18, 2.0.0rc19, 2.0.0rc20, 2.0.0rc21, 2.0.0rc22, 2.0.0rc23, 2.0.0rc24, 2.0.0rc25, 2.0.0, 2.0.1, 2.0.2, 2.0.3, 2.0.4, 2.0.5, 2.0.6, 2.0.7, 2.0.8, 2.1.0, 2.1.1, 2.2.0, 2.2.1, 2.2.2, 2.2.3, 2.2.4, 2.2.5, 2.2.6, 2.3.0rc0, 2.3.0rc1, 2.3.0, 2.3.1, 2.3.2, 2.3.3, 2.3.4, 2.3.5, 2.3.7, 2.4.0, 2.4.1.dev0, 2.4.1, 2.4.2, 2.4.3, 2.4.4, 2.4.5, 2.4.6, 2.4.7, 2.4.8, 2.4.9, 2.5.0, 2.5.1, 2.5.2, 2.6.0rc0, 2.6.0, 2.6.1)
python -m pip install paddlepaddle-gpu==0.0.0.post112 -f https://www.paddlepaddle.org.cn/whl/linux/gpu/develop.html
python -m pip install paddlepaddle-gpu==2.5.2 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
pip install --upgrade paddlenlp -i https://mirrors.cloud.tencent.com/pypi/simple
#看报错修改指令pip install --use-pep517 --upgrade paddlenlp -i https://mirrors.cloud.tencent.com/pypi/simple --trusted-host mirrors.aliyun.com
pip install --upgrade paddle-pipelines -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install onnxruntime-gpu onnx onnxconverter-common -i https://mirrors.cloud.tencent.com/pypi/simple
1.2 测试效果
conda activate paddlenlp_2.6.0
cd /algorithm/temp_es/PaddleNLP-develop/pipelines
cd /algorithm/temp_es/elasticsearch-8.3.3
#到pipelines路径下
python examples/semantic-search/semantic_search_example.py --device gpu --search_engine faiss
python examples/semantic-search/semantic_search_example.py --device gpu --query_embedding_model rocketqa-zh-nano-query-encoder --params_path checkpoints/model_40/model_state.pdparams --embedding_dim 256
1.3 执行ES
创建新用户使用:创建一个新的用户,例如"elasticsearch":
sudo useradd elasticsearch1
#将Elasticsearch的安装目录的所有权更改为"elasticsearch":
sudo chown -R elasticsearch1:elasticsearch1 /algorithm/temp_es/elasticsearch-8.3.3
#切换到"elasticsearch"用户,并尝试再次运行Elasticsearch:
su elasticsearch1
./bin/elasticsearch
#常驻待确定
查看es启动了几个
ps aux | grep elasticsearch
ps -ef | grep elasticsearch
#Elasticsearch在启动过程中遇到了问题。具体来说,它无法获取节点锁,可能是由于数据路径不可写或者多个节点试图使用同一个数据路径。
#尝试清理数据路径/algorithm/temp_es/elasticsearch-8.3.3/data,删除其中的节点锁和其他临时文件
rm -rf /algorithm/temp_es/elasticsearch-8.3.3/data/*
1.4 构建ANN 索引库
# 以DuReader-Robust 数据集为例建立 ANN 索引库
python utils/offline_ann.py --index_name dureader_robust_neural_search --doc_dir data/dureader_dev --query_embedding_model rocketqa-zh-nano-query-encoder --passage_embedding_model rocketqa-zh-nano-para-encoder --embedding_dim 312 --delete_index
#查看数据,打印几条数据
curl http://localhost:9200/dureader_robust_neural_search/_search
#删除索引也可以使用下面的命令:
curl -XDELETE http://localhost:9200/dureader_robust_query_encoder
1.5 启动 RestAPI 模型服务
#指定语义检索系统的Yaml配置文件
export PIPELINE_YAML_PATH=rest_api/pipeline/semantic_search_custom.yaml
#使用端口号 8891 启动模型服务
python rest_api/application.py 8891
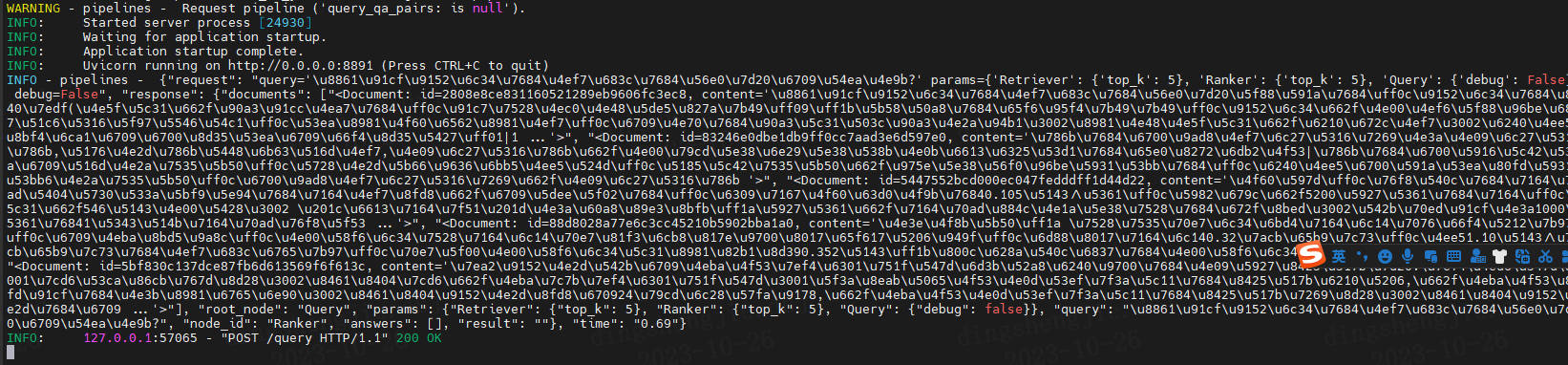
nltk_data加载,如果感觉很慢卡住了,可以见问题C.20
- Linux 用户推荐采用 Shell 脚本来启动服务:
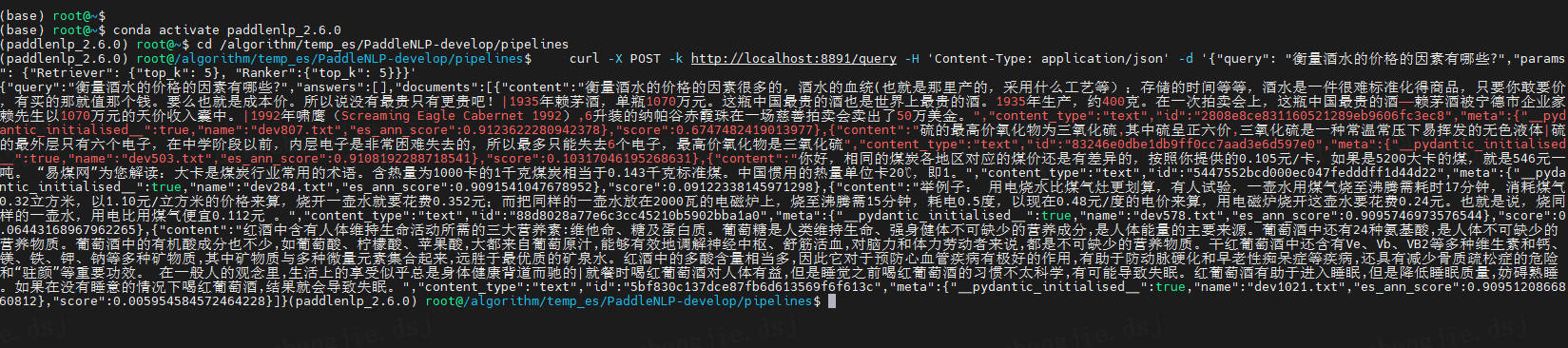
sh examples/semantic-search/run_neural_search_server.sh - 启动后可以使用curl命令验证是否成功运行:
curl -X POST -k http://localhost:8891/query -H 'Content-Type: application/json' -d '{"query": "衡量酒水的价格的因素有哪些?","params": {"Retriever": {"top_k": 5}, "Ranker":{"top_k": 5}}}'
1.6 启动web页面
pip install streamlit==1.11.1
pip install altair==4.2.2 -i https://mirrors.cloud.tencent.com/pypi/simple
#配置模型服务地址
export API_ENDPOINT=http://127.0.0.1:8891
#在指定端口 8502 启动 WebUI
python -m streamlit run ui/webapp_semantic_search.py --server.port 8502
#需要运维开阿里云网管以及端口授权
- Linux 用户推荐采用 Shell 脚本来启动服务:
sh examples/semantic-search/run_search_web.sh
到这里就可以打开浏览器访问 http://127.0.0.1:8502
关闭进程:
control+c
lsof -i:8502
kill -9 PID
B.2 CPU版本
2.1安装依赖库
安装同GPU选择paddle-2.5.1版本,提示:Centos系统下坑比较多需要使用paddle 2.4.2;Ubuntu推荐使用2.5.1 or develop。
conda activate paddlenlpcpu_2.6.0
cd /algorithm/temp_es/PaddleNLP-develop/pipelines
cd /algorithm/temp_es/elasticsearch-8.3.3
python -m pip install paddlepaddle==2.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --upgrade paddlenlp -i https://mirrors.cloud.tencent.com/pypi/simple
#paddle2.4.2 对应NLP 2.5.2版本
pip install --upgrade paddle-pipelines -i https://pypi.tuna.tsinghua.edu.cn/simple
- demo测试
python examples/semantic-search/semantic_search_example.py --device cpu --embedding_dim 256
python examples/semantic-search/semantic_search_example.py --device cpu --query_embedding_model rocketqa-zh-nano-query-encoder --passage_embedding_model rocketqa-zh-nano-para-encoder --params_path checkpoints/model_40/model_state.pdparams --embedding_dim 312
2.3 执行ES
创建新用户使用:创建一个新的用户,例如"esuser":
sudo useradd esuser
#将Elasticsearch的安装目录的所有权更改为"esuser":
sudo chown -R esuser:esuser /algorithm/temp_es/elasticsearch-8.3.3
#切换到"esuser"用户,并尝试再次运行Elasticsearch:
su esuser
./bin/elasticsearch
2.4 构建索引
python utils/offline_ann.py --index_name dureader_robust_neural_search --doc_dir data/dureader_dev --embedding_dim 256 --device cpu --delete_index
#查看数据,打印几条数据
curl http://localhost:9200/dureader_robust_neural_search/_search
#删除索引也可以使用下面的命令:
curl -XDELETE http://localhost:9200/dureader_robust_query_encoder
lsof -i:8502
kill -9 PID
python -m streamlit run ui/webapp_semantic_search.py --server.port 8502 --server.address 127.0.0.1
C.安装过程遇到相关问题解决---相关项目链接:
目前共记录21个在Windows和LInux下遇到的相关问题
点击链接进行跳转:
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[1.安装部署篇---完整版],支持Linux/Windows部署安装
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握[2.项目讲解篇],支持Linux/Windows部署安装
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握的更多相关文章
- EasySwoole+ElasticSearch打造 高性能 小视频服务系统
EasySwoole+ElasticSearch打造高性能小视频服务 第1章 课程概述 第2章 EasySwoole框架快速上手 第3章 性能测试 第4章 玩转高性能消息队列服务 第5章 小视频服务平 ...
- #研发解决方案介绍#基于ES的搜索+筛选+排序解决方案
郑昀 基于胡耀华和王超的设计文档 最后更新于2014/12/3 关键词:ElasticSearch.Lucene.solr.搜索.facet.高可用.可伸缩.mongodb.SearchHub.商品中 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 基于Kafka和Elasticsearch构建实时站内搜索功能的实践
作者:京东物流 纪卓志 目前我们在构建一个多租户多产品类网站,为了让用户更好的找到他们所需要的产品,我们需要构建站内搜索功能,并且它应该是实时更新的.本文将会讨论构建这一功能的核心基础设施,以及支持此 ...
- es简单打造站内搜索
最近挺忙的,在外出差,又同时干两个项目.白天一个晚上一个,特别是白天做的项目,马上就要上线了,在客户这里 三天两头开会,问题很多真的很想好好静下来怼代码,半夜做梦都能fix bugs~ 和客户交流真的 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 四十七 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/se ...
- 基于层级表达的高效网络搜索方法 | ICLR 2018
论文基于层级表达提出高效的进化算法来进行神经网络结构搜索,通过层层堆叠来构建强大的卷积结构.论文的搜索方法简单,从实验结果看来,达到很不错的准确率,值得学习 来源:[晓飞的算法工程笔记] 公众号 ...
- 四十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
Django实现搜索功能 1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` lis ...
随机推荐
- Nacos 1.2.1 集群搭建(一)环境准备
虚机准备.Nacos 文件准备.MySQL 5.7 安装 https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html 根据官网要求,至少3个节点 ...
- Sublime Ctrl+B 编译输出乱码
1.输入乱码如图 2.Preferences -> Browse Packages.. 3.加入 "env": { "PYTHONIOENCODING" ...
- COOIS选择屏幕增强
一.COOIS生产订单抬头选择屏幕添加筛选条件,并将自定义数据添加到报表 二.修改抬头表AUFK,新增自定义字段 三.选择屏幕新增筛选字段 四.函数模块中,将选择屏幕筛选条件抛到内存 五.BADI:W ...
- HTML5 postMessage 跨域跨窗口传递消息
父页面代码: <!DOCTYPE html> <html> <head> <title>选择位置demo</title> <meta ...
- VMware15.5安装Ubuntu20.04
一.安装前的准备 1.下载好Ubuntu20.04的镜像文件,直接从官网下载就好,激活密匙. 2.准备好VMware软件,这里就忽略安装过程了. 二.建立虚拟机以及开启正式的Ubuntu安装过程 参考 ...
- kafka集群六、java操作kafka(没有密码验证)
系列导航 一.kafka搭建-单机版 二.kafka搭建-集群搭建 三.kafka集群增加密码验证 四.kafka集群权限增加ACL 五.kafka集群__consumer_offsets副本数修改 ...
- nextTick使用
- idea新建spring boot 项目右键无package及java类的选项
新创建的spring boot项目,只有一个默认的资源目录及启动配置. 在 group 的目录下右键新建包路径时 ,发现没有package选项,也没有Java Class的选项: 解决办法: File ...
- 问题--链表指针传参,修改next指针只传值
1.问题--链表指针传参,修改next指针只传值 Link_creat_head(&head, p_new);//将新节点加入链表 在这当中head头指针传的是地址,而p_new传的是值,这二 ...
- Git Clone一个GitHub仓库时,发生报错
1.问题 1.使用HTTP方式:Git: fatal: unable to access ' https://github. com/Light-City/CPlusPlusThings. git/' ...