强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录

1.doccano的安装与初始配置
1.1 doccano的用途
- document classification 文本分类
- sequence labeling 序列标注,用于命名实体识别
- sequence to sequence seq2seq,用于翻译
- speech to text 语音转文本标注
命名实体标注
序列标注(如机器翻译)
文本分类任务(如情感分析)
官方文档:
GitHub - doccano/doccano: Open source annotation tool for machine learning practitioners.
1.2 安装与初始配置
记的进虚拟环境!!!!!
Step 1. 本地安装doccano(请勿在AI Studio内部运行,本地测试环境python=3.8)
$ pip install doccanoStep 2. 初始化数据库和账户(用户名和密码可替换为自定义值)
# 初始化,设置用户名= admin,密码=pass
doccano init
doccano createuser --username admin --password pass
-------------------------个人设置---------------------------
$ doccano init
$ doccano createuser --username my_admin_name --password my_passwordStep 3. 启动doccano
- 在一个窗口启动doccano的WebServer,保持窗口
$ doccano webserver --port 8000
- 在另一个窗口启动doccano的任务队列
$ doccano task
- 打开浏览器(推荐Chrome),在地址栏中输入
http://127.0.0.1:8000/后回车即得以下界面。
2. doccano无法上传标注的数据 or 无法导出标注数据
2.1 上传下载数据---界面不断加载状态
在另一个终端中,运行以下命令:
doccano task
看一下原文档。运行的话,重新按一下回车键!!!
2.2 端口被占用
启动的时候不要使用应用程序(我是开着酷狗音乐软件,这个软件占用了端口),如果使用的话会报以下错误:
OSError: [WinError 10013] 以一种访问权限不允许的方式做了一个访问套接字的尝试。2.3 导出数据报错
导出数据时如果报错:找到writer.py这个文件
C:\Users\Glenn.conda\envs\dataannotation\Lib\site-packages\backend\api\views\download\writer.py
line 9,增加encoding="utf-8"
class LineWriter(BaseWriter):
extension = 'txt'
def write(self, records: Iterator[Record]) -> str:
files = {}
for record in records:
filename = os.path.join(self.tmpdir, f'{record.user}.{self.extension}')
if filename not in files:
f = open(filename, mode='a',encoding="utf-8") #就是这个位置
files[filename] = f
f = files[filename]
line = self.create_line(record)
f.write(f'{line}\n')
for f in files.values():
f.close()
save_file = self.write_zip(files)
for file in files:
os.remove(file)
return save_file3.项目:doccano来标注实体和关系
3.1 项目创建
参考文档:
PaddleNLP/doccano.md at develop · PaddlePaddle/PaddleNLP · GitHub
登陆账户。点击右上角的
LOGIN(登录),输入Step 2中设置的用户名和密码登陆。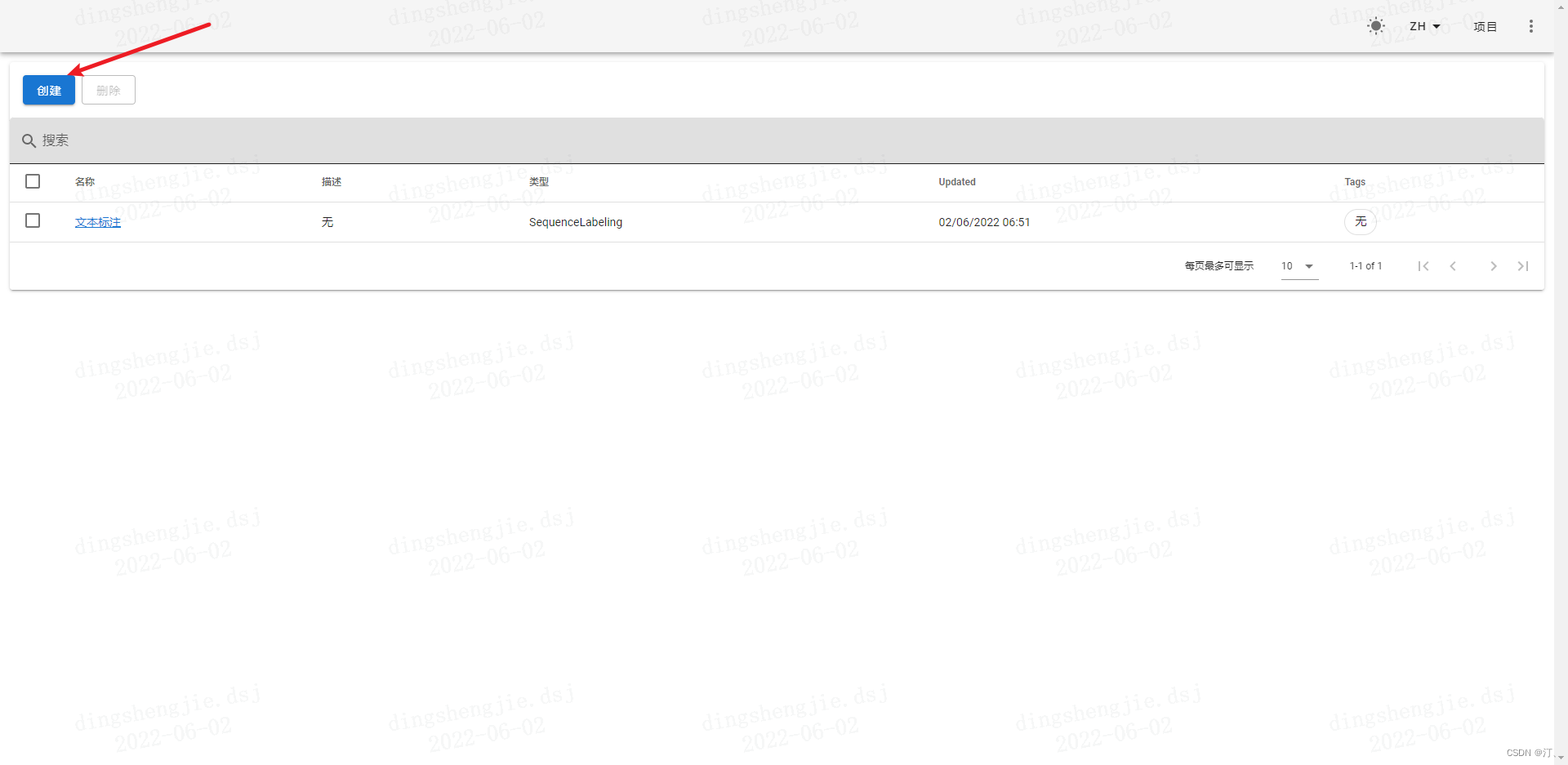
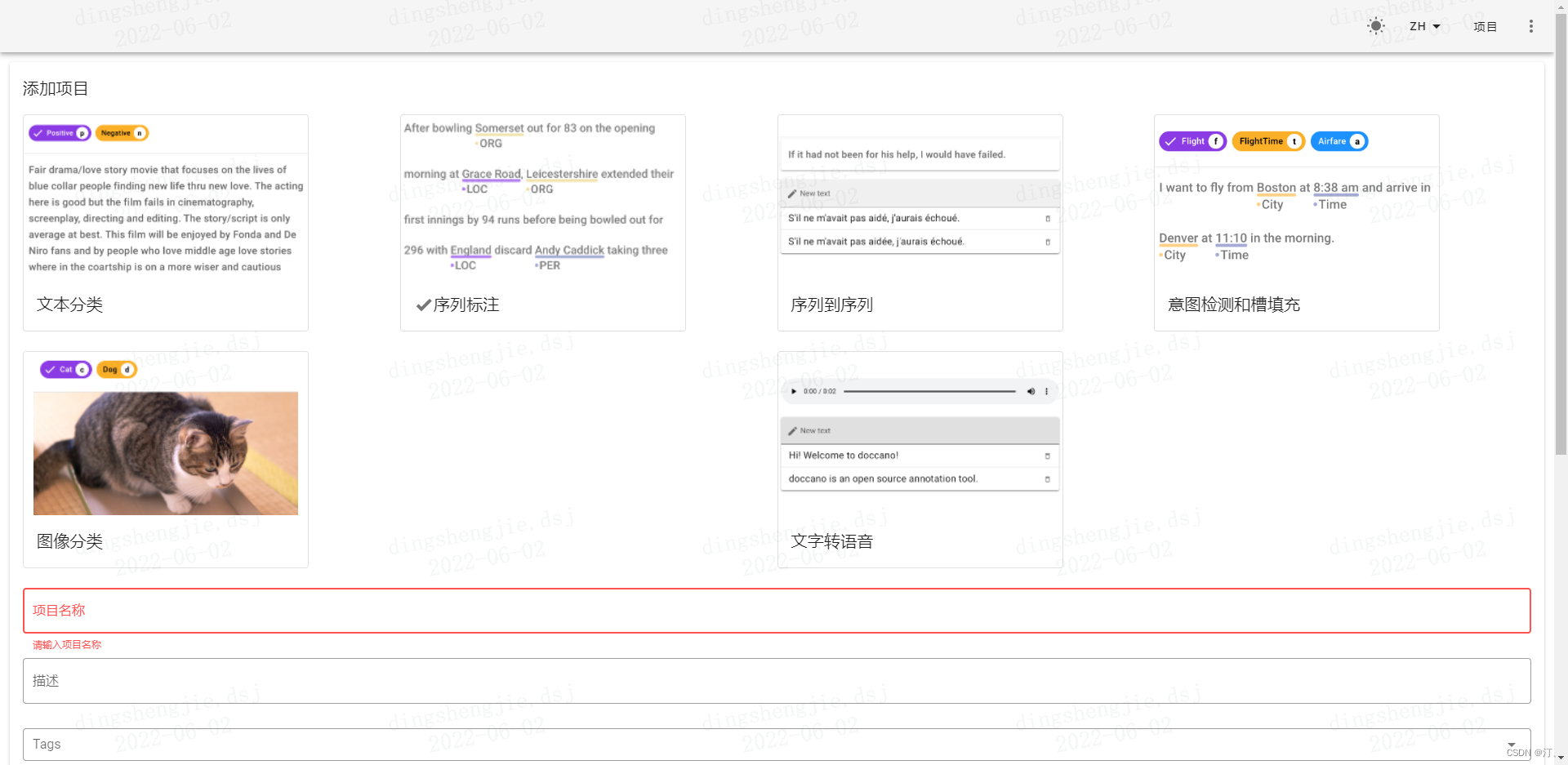
UIE支持抽取与分类两种类型的任务,根据实际需要创建一个新的项目:
- 抽取式任务项目创建
创建项目时选择序列标注任务,并勾选Allow overlapping entity及Use relation Labeling。适配命名实体识别、关系抽取、事件抽取、评价观点抽取等任务。
- 分类式任务项目创建
创建项目时选择文本分类任务。适配文本分类、句子级情感倾向分类等任务。
以抽取为例:
创建项目。点击左上角的
CREATE,跳转至以下界面。- 勾选序列标注(
Sequence Labeling) - 填写项目名称(
Project name)等必要信息 - 勾选允许实体重叠(
Allow overlapping entity)、使用关系标注(Use relation labeling) - 创建完成后,项目首页视频提供了从数据导入到导出的七个步骤的详细说明【可以学习参考】。
- 勾选序列标注(
3.2 数据上传


如图所示,doccano总共支持4种格式的文本,他们的区别如下:
- Textfile:要求上传的文件为txt格式,并且在打标的时候,一整个txt文件在打标的时候显示为一页内容;
- Textline:要求上传的文件为txt格式,并且在打标的时候,该txt文件的一行文字会在打标的时候显示为一页内容;
- JSONL:是JSON Lines的简写,每行是一个有效的JSON值。
- CoNLL:是“中文依存语料库”,是根据句子的依存结构而建立的树库。其中,依存结构描述的是句子中词与词之间直接的句法关系。具体介绍看汉语树库。
注意:
- doccano官方推荐的文档编码格式为UTF-8。
- 在使用JSONL格式的时候,文字数据本身要符合JSON格式的规范。
- 数据集中不要包含空行。
这里我们以Textline格式举例。

点击“TextLine格式”。然后在跳转到的界面里,设置File Format和Encoding。然后点击下图中的“Drop files here…”来上传文件。最后,点击右下角的“injest”将数据集添加到项目(此处有拼写错误,正确的拼写估计为“inject”或者ingest“)。
此时,再点击“数据集”的标签,我们就可以看到一条一条的文本已经被添加到项目中了。将来我们将对这些文本进行打标。

3.3 添加标签
构建抽取式任务标签
抽取式任务包含Span与Relation两种标签类型,Span指原文本中的目标信息片段,如实体识别中某个类型的实体,事件抽取中的触发词和论元;Relation指原文本中Span之间的关系,如关系抽取中两个实体(Subject&Object)之间的关系,事件抽取中论元和触发词之间的关系。
注意,这里只是添加将来可供选择的标签,是项目配置的过程,而不是进行文本标注。
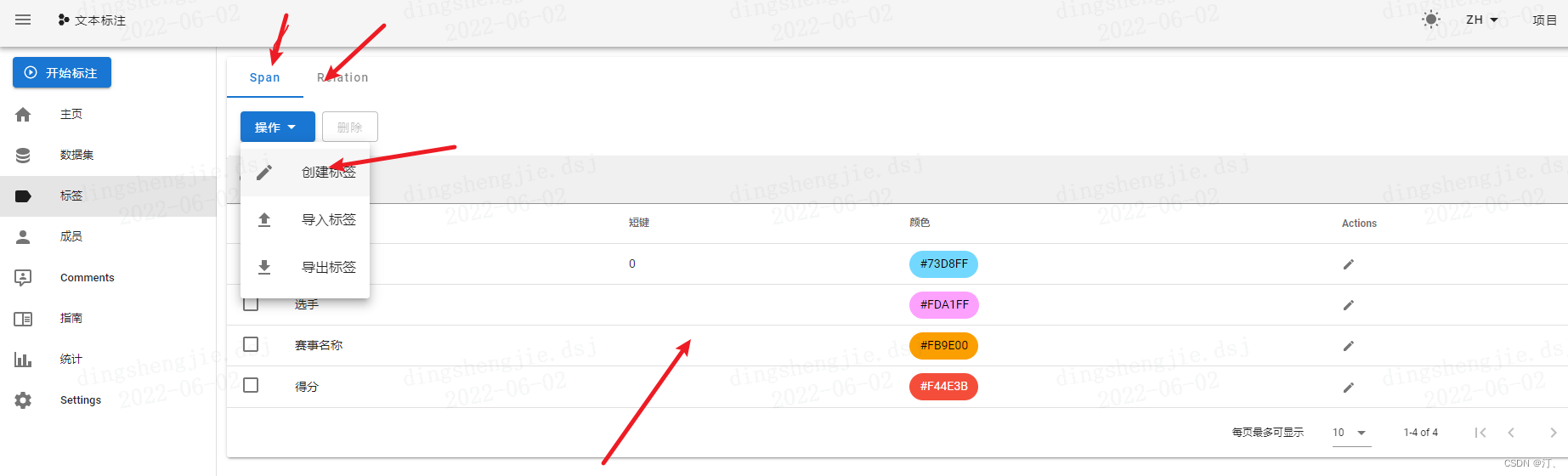
我们点击左侧的“标签”按钮,就来到了添加标签的界面。
设置标签。在Labels一栏点击
Actions,Create Label手动设置或者Import Labels从文件导入。
- 最上边Span表示实体标签,Relation表示关系标签,需要分别设置。
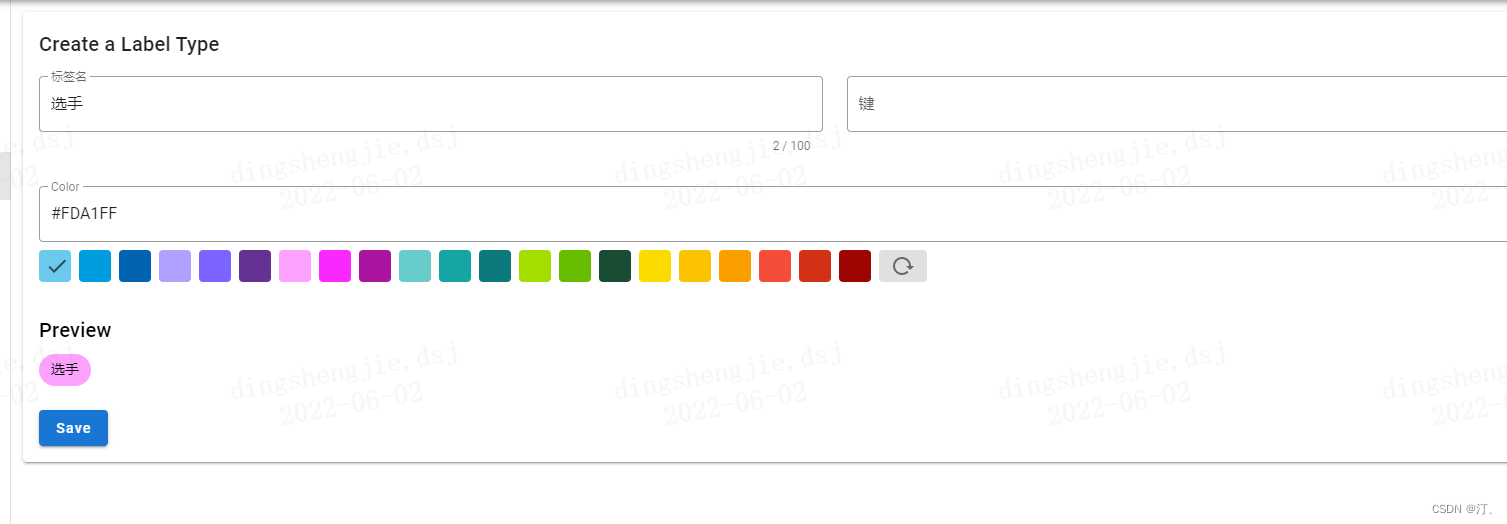
在弹出的“创建标签”窗口里面,在第一行写上标签的名字。例如在NER的例子中,可以写People、Location、Organization等。
在第二行添加该标签对应的快捷键---短键。例如,我们给People设置的快捷键是p。将来在打标的时候,右手用鼠标选中段落中的文字(例如“白居易”),左手在键盘按下快捷键p,就可以把被选中的文字打标成“People”。
再往下,我们可以给标签自定义颜色。
全部设置好以后,点击右下角的“保存”按钮。
此时,一个标签就添加完成了。我们以同样的方法添加其他所需要的标签。
3.4 任务标注
标注数据。点击每条数据最右边的
Annotate按钮开始标记。标记页面右侧的标签类型(Label Types)开关可在实体标签和关系标签之间切换。- 实体标注:直接用鼠标选取文本即可标注实体。
- 关系标注:首先点击待标注的关系标签,接着依次点击相应的头尾实体可完成关系标注。
3.4.1 命名实体识别
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
标注示例:
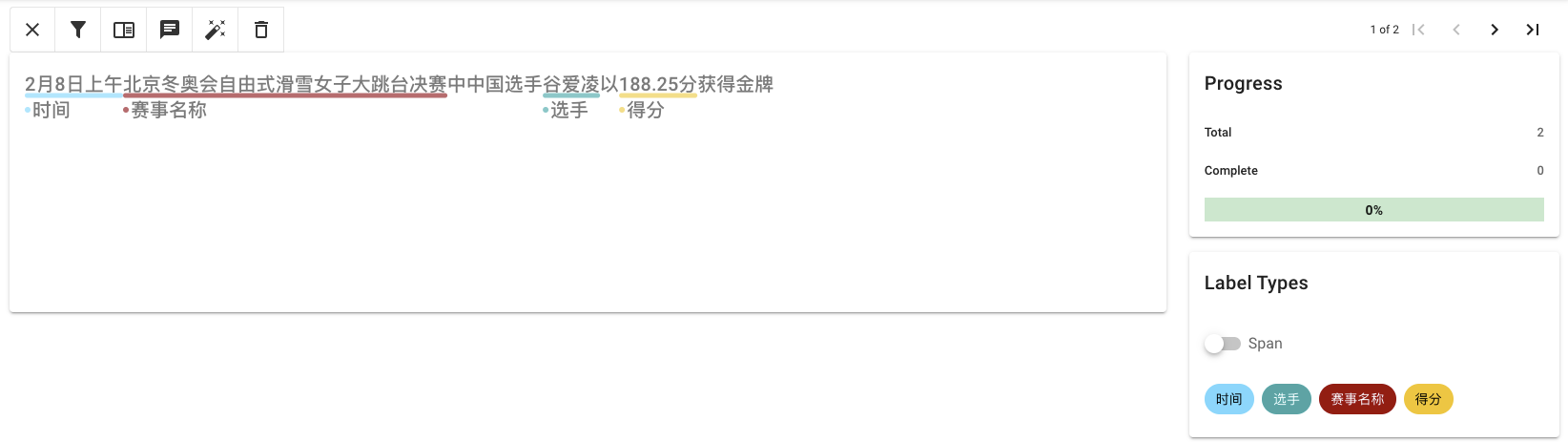
示例中定义了时间、选手、赛事名称和得分四种Span类型标签。
3.4.2 关系抽取
关系抽取(Relation Extraction,简称RE),是指从文本中识别实体并抽取实体之间的语义关系,即抽取三元组(实体一,关系类型,实体二)。
标注示例:

示例中定义了作品名、人物名和时间三种Span类型标签,以及歌手、发行时间和所属专辑三种Relation标签。Relation标签由Subject对应实体指向Object对应实体。
3.4.3 事件抽取
事件抽取 (Event Extraction, 简称EE),是指从自然语言文本中抽取事件并识别事件类型和事件论元的技术。UIE所包含的事件抽取任务,是指根据已知事件类型,抽取该事件所包含的事件论元。
标注示例:

示例中定义了地震触发词(触发词)、等级(事件论元)和时间(事件论元)三种Span标签,以及时间和震级两种Relation标签。触发词标签统一格式为XX触发词,XX表示具体事件类型,上例中的事件类型是地震,则对应触发词为地震触发词。Relation标签由触发词指向对应的事件论元。
3.4.4 评价观点抽取
评论观点抽取,是指抽取文本中包含的评价维度、观点词。
标注示例:

示例中定义了评价维度和观点词两种Span标签,以及观点词一种Relation标签。Relation标签由评价维度指向观点词。
3.4.5 分类任务
标注示例:

示例中定义了正向和负向两种类别标签对文本的情感倾向进行分类
3.5 数据导出
3.5.1 导出抽取式任务数据
导出数据。在Datasets一栏点击Actions、Export Dataset导出已标注的数据。
选择导出的文件类型为JSONL(relation),导出数据示例:
{
"id": 38,
"text": "百科名片你知道我要什么,是歌手高明骏演唱的一首歌曲,1989年发行,收录于个人专辑《丛林男孩》中",
"relations": [
{
"id": 20,
"from_id": 51,
"to_id": 53,
"type": "歌手"
},
{
"id": 21,
"from_id": 51,
"to_id": 55,
"type": "发行时间"
},
{
"id": 22,
"from_id": 51,
"to_id": 54,
"type": "所属专辑"
}
],
"entities": [
{
"id": 51,
"start_offset": 4,
"end_offset": 11,
"label": "作品名"
},
{
"id": 53,
"start_offset": 15,
"end_offset": 18,
"label": "人物名"
},
{
"id": 54,
"start_offset": 42,
"end_offset": 46,
"label": "作品名"
},
{
"id": 55,
"start_offset": 26,
"end_offset": 31,
"label": "时间"
}
]
}标注数据保存在同一个文本文件中,每条样例占一行且存储为json格式,其包含以下字段
id: 样本在数据集中的唯一标识ID。text: 原始文本数据。entities: 数据中包含的Span标签,每个Span标签包含四个字段:
id: Span在数据集中的唯一标识ID。start_offset: Span的起始token在文本中的下标。end_offset: Span的结束token在文本中下标的下一个位置。label: Span类型。relations: 数据中包含的Relation标签,每个Relation标签包含四个字段:
id: (Span1, Relation, Span2)三元组在数据集中的唯一标识ID,不同样本中的相同三元组对应同一个ID。from_id: Span1对应的标识ID。to_id: Span2对应的标识ID。type: Relation类型。
3.5.2 导出分类式任务数据
选择导出的文件类型为JSONL,导出数据示例:
{
"id": 41,
"data": "大年初一就把车前保险杠给碰坏了,保险杠和保险公司 真够倒霉的,我决定步行反省。",
"label": [
"负向"
]
}标注数据保存在同一个文本文件中,每条样例占一行且存储为json格式,其包含以下字段
id: 样本在数据集中的唯一标识ID。data: 原始文本数据。label: 文本对应类别标签。
3.6.添加成员、添加标注指南、开始给文本打标、审核标注结果、阅读项目信息
见链接:
Django 实现管理员登录:这个过程需要Django
占个坑位后续补充!!!!
在为机器学习的语料库打标的时候,由于语料库一般比较大,需要多个人协同完成语料库的打标工作。也就是在初始配置doccano的时候创建的超级用户admin。因此,为了让其他人参与到打标项目中来,我们首先需要为其他成员创建账户。
# 多人标注:设置用户名= admin,密码=pass
doccano createuser --username user1 --password 123456


3.7.标注完数据转化:
该章节详细说明如何通过doccano.py脚本对doccano平台导出的标注数据进行转换,一键生成训练/验证/测试集。
3.7.1 抽取式任务数据转换
- 当标注完成后,在 doccano 平台上导出
JSONL(relation)形式的文件,并将其重命名为doccano_ext.json后,放入./data目录下。- 通过 doccano.py 脚本进行数据形式转换,然后便可以开始进行相应模型训练。
python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type "ext" \
--save_dir ./data \
--negative_ratio 53.7.2 分类式任务数据转换
- 当标注完成后,在 doccano 平台上导出
JSON形式的文件,并将其重命名为doccano_cls.json后,放入./data目录下。 - 在数据转换阶段,我们会自动构造用于模型训练需要的prompt信息。例如句子级情感分类中,prompt为
情感倾向[正向,负向],可以通过prompt_prefix和options参数进行声明。 - 通过 doccano.py 脚本进行数据形式转换,然后便可以开始进行相应模型训练。
python doccano.py \
--doccano_file ./data/doccano_cls.json \
--task_type "cls" \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--prompt_prefix "情感倾向" \
--options "正向" "负向"可配置参数说明:
doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.
备注:
- 默认情况下 doccano.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。- 对于从doccano导出的文件,默认文件中的每条数据都是经过人工正确标注的。
各个任务标注文档参考:
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/doccano.md
强烈推荐:数据标注平台doccano----简介、安装、使用、踩坑记录的更多相关文章
- CentOS7.4安装MySQL踩坑记录
CentOS7.4安装MySQL踩坑记录 time: 2018.3.19 CentOS7.4安装MySQL时网上的文档虽然多但是不靠谱的也多, 可能因为版本与时间的问题, 所以记录下自己踩坑的过程, ...
- ubuntu 下安装docker 踩坑记录
ubuntu 下安装docker 踩坑记录 # Setp : 移除旧版本Docker sudo apt-get remove docker docker-engine docker.io # Step ...
- Android关于版本更新下载安装之踩坑记录(针对7.0以上)
最近刚刚把古老的项目targetSdk版本升级到26,升级之前是19(非常非常古老了).那么升级后一些问题开始出现. Android 8.0 (Android O)为了针对一些流氓软件引导用户安装其他 ...
- 虚拟机安装mysql踩坑记录
本章节主要讲解的是在虚拟机centOs7版本以上安装mysql5.6版本,亲测可以直接使用,有需要帮助的小伙伴可以加本人QQ2246451792@qq.com!!!! 卸载centOs7自带的mari ...
- windows 安装 python 踩坑记录
官方不建议使用 64 bit python,容易出各种问题 Unable to find vcvarsall.bat 凡是安装与操作系统底层相关的 python 扩展都会遇到这个问题,如 PIL,Pi ...
- 基于winds10 安装docker 踩坑记录
1.官方下载 https://www.docker.com/ 2.根据提示安装 并重庆计算机3.双击运行 报 Docker Desktop is shutting down 提示 计算机c: 盘 A ...
- DevOps落地实践点滴和踩坑记录-(2) -聊聊平台建设
很久没有写文章记录了,上一篇文章像流水账一样,把所见所闻一个个记录下来.这次专门聊聊DevOps平台的建设吧,有些新的体会和思考,希望给正在做这个事情的同学们一些启发吧. DevOps落地实践点滴和踩 ...
- Charles 抓包工具安装和采坑记录
Charles 抓包工具安装和采坑记录 网络抓包是解决网络问题的第一步,也是网络分析的基础.网络出现问题,第一步肯定是通过抓包工具进行路径分析,看哪一步出现异常.做网络爬虫,第一步就是通过抓包工具对目 ...
- linux centos7环境下安装apache2.4+php5.6+mysql5.6 安装及踩坑集锦(二)
linux centos7环境下安装apache2.4+php5.6+mysql5.6 安装及踩坑集锦(二) 安装apache web容器 . yum方式安装apache 注意apache在linux ...
- 复杂业务下向Mysql导入30万条数据代码优化的踩坑记录
从毕业到现在第一次接触到超过30万条数据导入MySQL的场景(有点low),就是在顺丰公司接入我司EMM产品时需要将AD中的员工数据导入MySQL中,因此楼主负责的模块connector就派上了用场. ...
随机推荐
- CO40/CO41转生产订单下达时不能创建采购申请
一.配置 CO01创建生产订单,创建时生成采购申请,改为下达时创建采购申请.通过配置,将预留/采购申请 更改为2即可. 但是CO41和CO40通过配置,并不能达到更改预留/采购申请 为2. 二.调试源 ...
- VS Code 2022路线图:大量Spring Boot优化提上日程
1月20日,一名微软开发者发布了一篇标题为<Java on Visual Studio Code Update>的文章. 文中介绍了VS Code 2021年的亮点,同时还透露了VS Co ...
- 第四届蓝桥杯(2013)C/C++大学A组省赛题解
第一题:高斯日记 大数学家高斯有个好习惯:无论如何都要记日记. 他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210 后来人们知道,那个整数就是日期,它表示那一天是高斯出生 ...
- 安全情报 | Pypi再现窃密攻击投毒
概述 悬镜安全自研的开源组件投毒检测平台通过对主流开源软件仓库(包括Pypi.NPM.Ruby等)发布的组件包进行持续性监控和自动化代码安全分析,同时结合专家安全经验复审,能够及时发现组件包投毒事件并 ...
- C#使用ParseExact方法将字符串转化为日期格式
private void btn_Convert_Click(object sender, EventArgs e) { #region 针对Windows 7系统 string s = string ...
- java进阶(12)--8种数据包装类型、Integer、常用方法
一.基本数据类型与包装类型 8种基本数据类型,对应的包装类,父类 1.byte-->java.lang.Byte-->Number 2.short-->java.lang.Short ...
- 机器学习-决策树系列-XGBoost算法-chentianqi大神-集成学习-31
目录
- Spring Boot Actuator 使用和常用配置
转载请注明出处: Spring Boot Actuator是Spring Boot提供的一个非常强大的工具,它可以帮助我们监控和管理我们的Spring Boot应用.Actuator提供了一系列的端点 ...
- MongoDB 增删改查 常用sql总结
本文为博主原创,转载请注明出处: 1.切换到指定数据库:如果不存在则创建 use database 2.查看所有文档 show tables show collections 3.创建表 #创建文档 ...
- Pgsql之查询一个月份的天数
前几天干活儿的时候,项目中有这么个需求,需要用pgsql查询某个月份有多少天,下面贴代码: select date_part('days', date_trunc('month', to_timest ...