传统RNN网络及其案例--人名分类
传统RNN网络及其案例--人名分类
传统的RNN模型简介
RNN
先上图
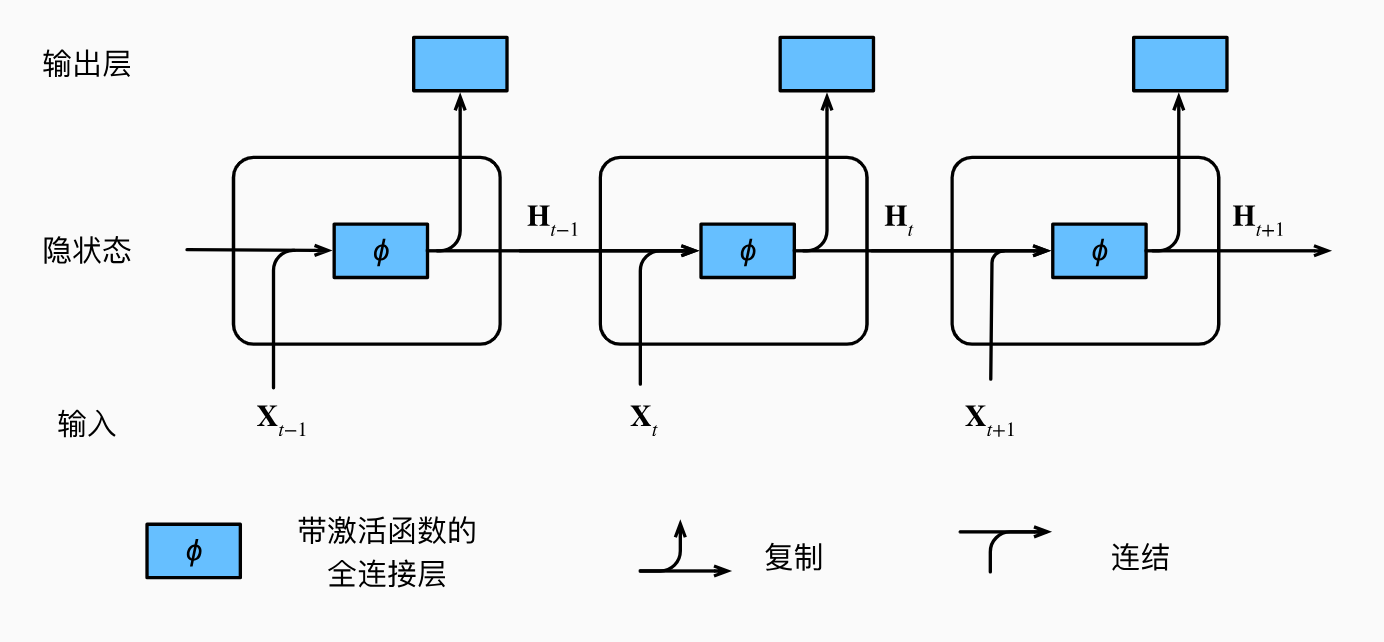
这图看起来莫名其妙,想拿着跟CNN对比着学第一眼看上去有点摸不着头脑,其实我们可以把每一个时刻的图展开来,如下
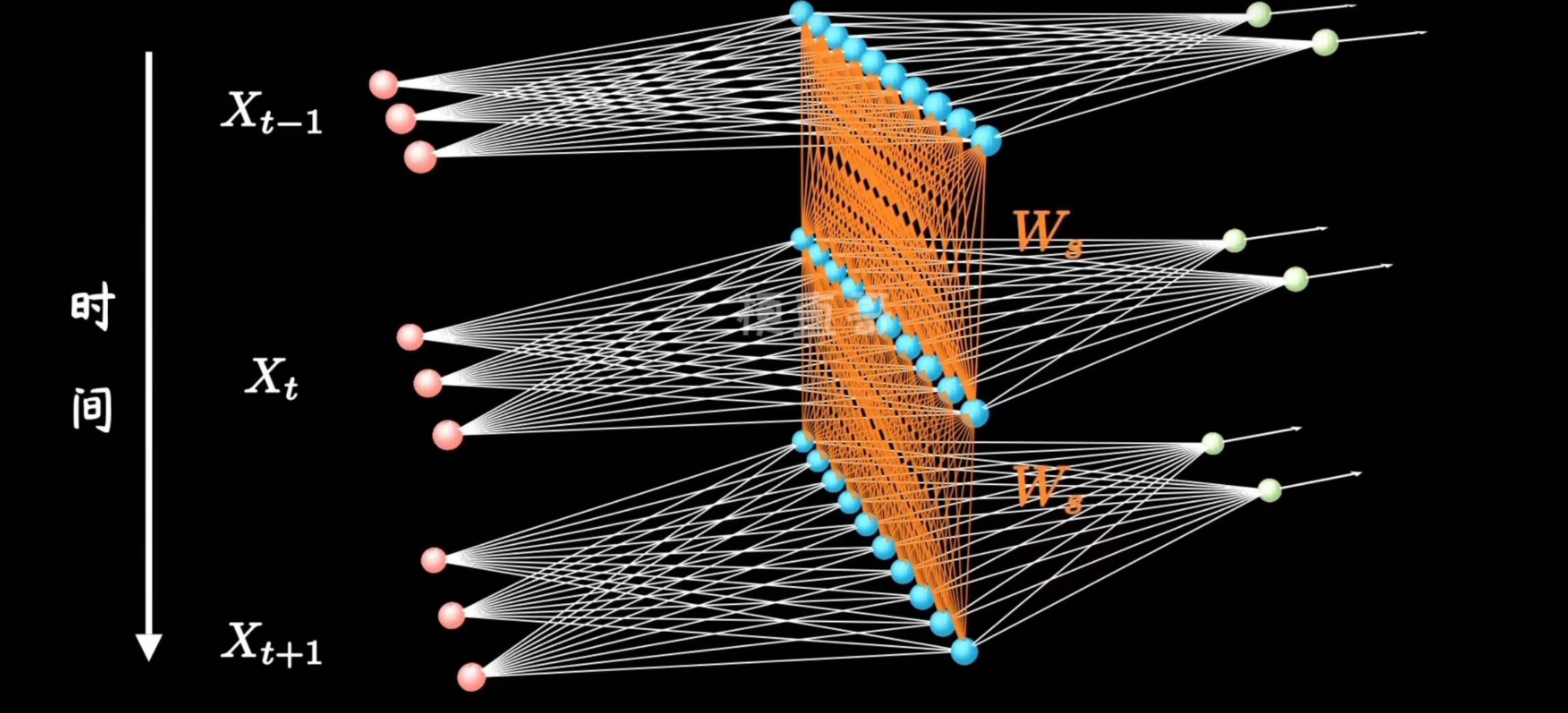
其中,为了简化计算,我们默认每一个隐层参数相同,这样看来RNN的结构就比较简单了,相比较CNN来说,RNN引入了更多的时序信息。
LSTM
在训练 RNN 时,每个时间步的输出都依赖于之前时间步的状态,这种依赖关系形成了一个链式结构。当反向传播时,梯度需要通过多个时间步传播回去,由于链式法则的存在,这个过程中梯度会多次进行乘法运算。如果这些乘法运算的结果小于1,梯度就会随着时间步的增加逐渐衰减,最终可能消失到几乎为零,就会导致梯度消失。RNN 中常用的激活函数如 Sigmoid 或者 tanh 函数,它们的输出范围都在 (0, 1) 或者 (-1, 1) 之间。在反向传播时,如果梯度在这些函数的导数范围内,则可以稳定地传播;但如果超出了这个范围,梯度可能会指数级增长或减少,导致梯度爆炸。而且这些在处理长序列时特别容易发生,因此,出现了RNN的改良版,LSTM。
先看图:
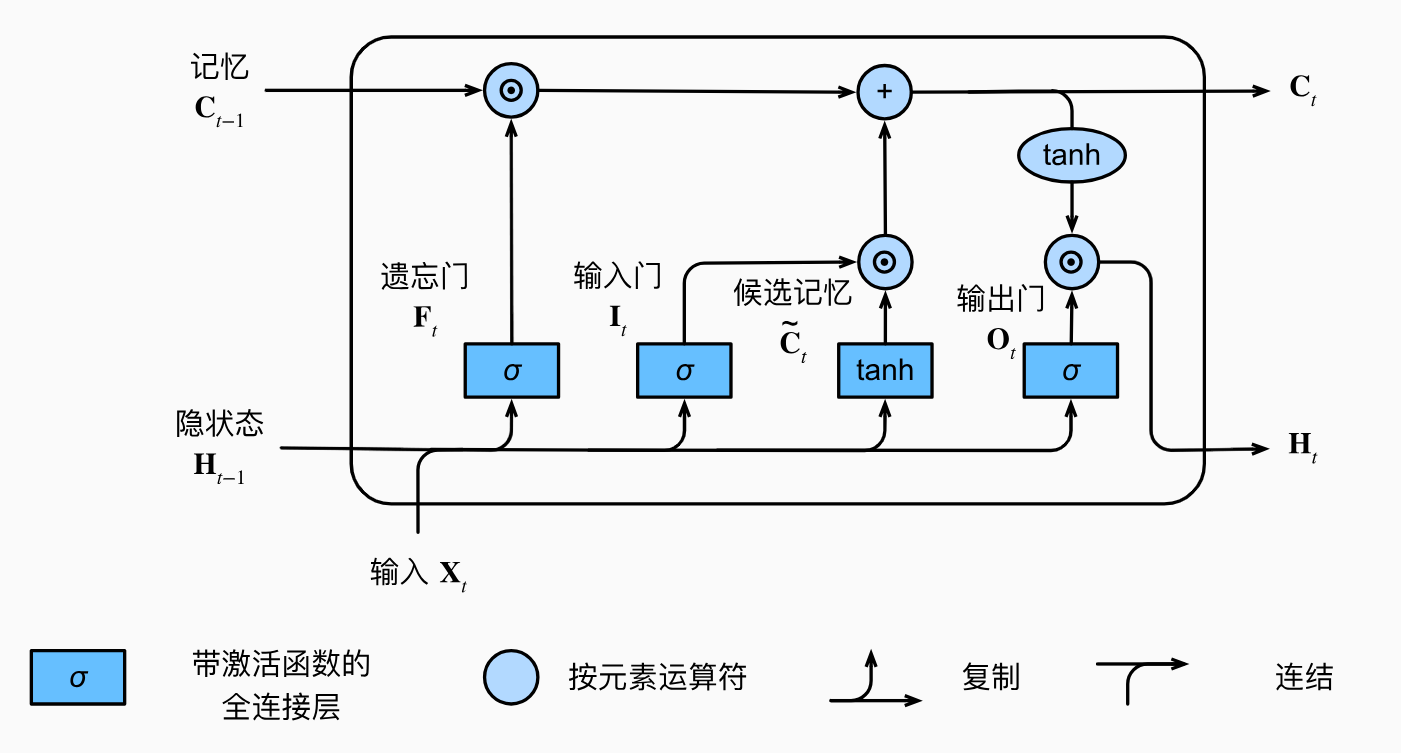
谈到LSTM就无法避免的提及它的三个门和最上面的记忆单元
记忆单元:记忆单元是LSTM的核心,用于存储信息。它可以看作是一条信息通道,贯穿整个 LSTM单元链条,允许信息直接传递,减少信息丢失。
遗忘门:遗忘门决定哪些信息需要从记忆单元中删除。它通过sigmoid函数(将当前输入和前一时刻的隐藏状态作为输入)输出一个0到1之间的值。接近0的值表示需要遗忘的信息,接近1的值表示需要保留的信息。
\[f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
\]输入门: 输入门决定哪些新的信息需要添加到记忆单元中。它由两个部分组成:一个sigmoid层决定哪些值将被更新;一个tanh层生成新的候选值向量。
\[i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
\]\[\tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C)
\]输出门:输出门决定记忆单元的哪些部分将被输出作为当前时刻的隐藏状态。它通过sigmoid层和tanh层来实现。
\[o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)
\]\[h_t = o_t * \tanh(C_t)
\]
LSTM的工作流程如下
遗忘阶段:计算遗忘门的值,以确定当前记忆单元状态中需要遗忘的部分。
\[C_t = f_t * C_{t-1}
\]输入阶段:计算输入门的值,并生成新的候选记忆内容。
\[C_t = C_t + i_t * \tilde{C}_t
\]更新记忆单元:结合遗忘门和输入门的输出,更新当前记忆单元的状态。
输出阶段:计算输出门的值,并生成新的隐藏状态。
完整公式流程:
\]
\]
\]
\]
\]
\]
GRU
LSTM固然很强,解决了RNN对于长序列模型表现很拉跨的难题,但是仔细查看LSTM的过程就会发现,相对于RNN来说他引入了太多的参数,很容易就过拟合和训练时间大大加长,因此,GRU改进这一问题
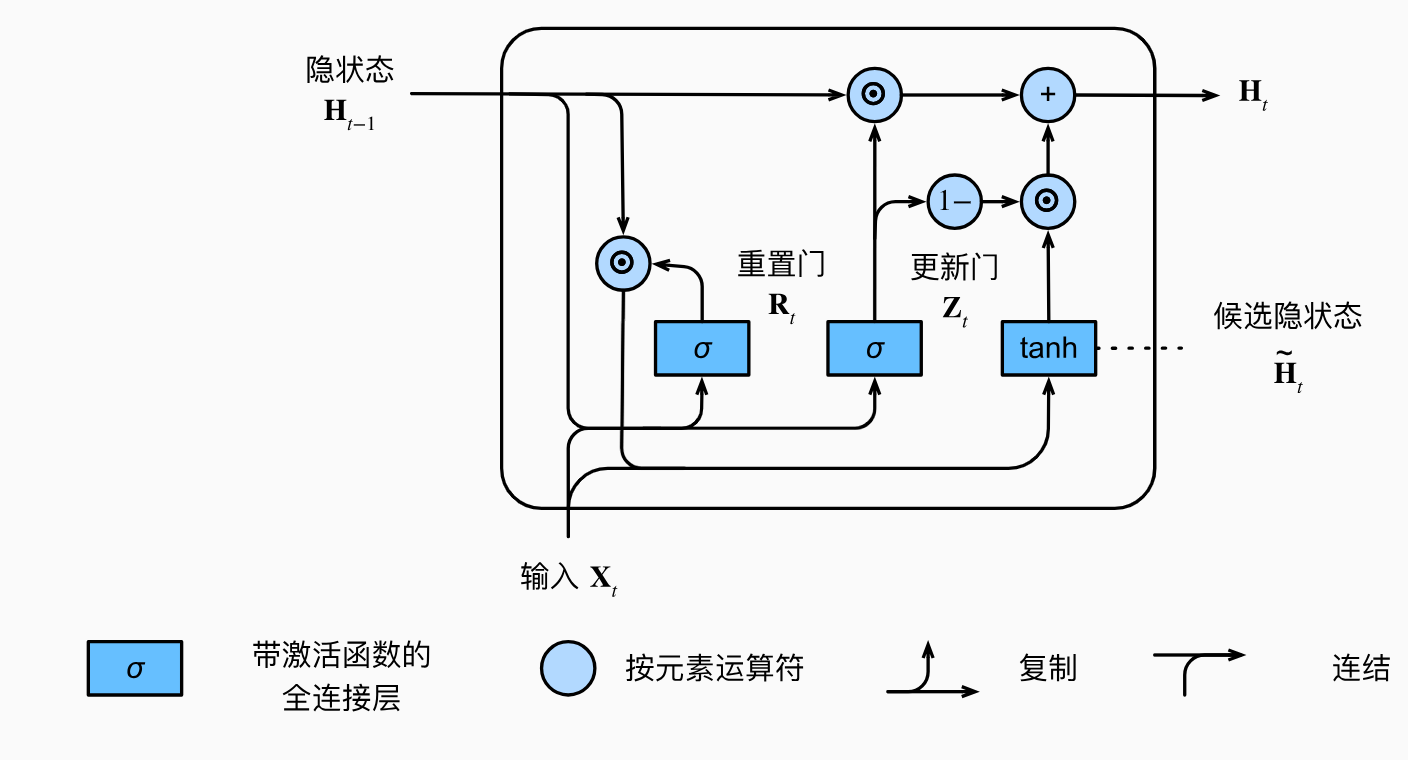
更新门:更新门控制着前一时间步的信息和当前时间步的新信息之间的混合。它通过sigmoid函数决定有多少过去的信息需要保留,以及有多少新的信息需要添加。
\[z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z)
\]重置门:重置门控制着前一时间步的隐藏状态在当前时间步中被遗忘的比例。它通过sigmoid函数决定有多少前一时间步的信息需要被重置。
\[r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r)
\]候选隐藏状态:候选隐藏状态结合了重置门的结果,决定当前时间步的隐藏状态。
\[\tilde{h}_t = \tanh(W \cdot [r_t * h_{t-1}, x_t] + b)
\]隐藏状态:最终的隐藏状态是更新门和候选隐藏状态的组合。
\[h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t
\]
工作流程如下:
重置阶段:计算重置门的值,以确定前一时间步的信息在当前时间步中被重置的比例。
\[r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r)
\]更新阶段:计算更新门的值,以确定有多少信息从前一时间步保留到当前时间步。
\[z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z)
\]候选隐藏状态阶段:计算候选隐藏状态,该状态结合了重置门的结果和当前输入信息。
\[\tilde{h}_t = \tanh(W \cdot [r_t * h_{t-1}, x_t] + b)
\]隐藏状态更新阶段:结合更新门和候选隐藏状态,更新当前时间步的隐藏状态。
\[h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t
\]完整工作流程
\[z_t = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z)
\]\[r_t = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r)
\]\[\tilde{h}_t = \tanh(W \cdot [r_t * h_{t-1}, x_t] + b)
\]\[h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t
\]
使用传统RNN模型来进行人名分类
1. 准备工作
导入一些包和写一个读取数据的函数(这段代码不是重点,直接抄就行了,只需要记住几个关键的变量)
category_lines: 人名类别与具体人名对应关系的字典,形式为{人名类别:[人名1,人名2,...]}
all_categories:所有的类别构成的列表
all_letters:所有的字符
import torch
from io import open
import glob
import os
import unicodedata
import string
import random
import time
import math
import torch.nn as nn
import matplotlib.pyplot as plt data_path = './data/names/'
all_letters = string.ascii_letters + " .,;'"
def unicodeToAscii(text):
"""
Converts a Unicode string to an ASCII string. Args:
text (str): The Unicode string to convert. Returns:
str: The ASCII string.
"""
return ''.join([
unicodedata.normalize('NFKD', char)
for char in text
if not unicodedata.combining(char)
]).encode('ascii', 'ignore').decode('ascii') def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines] # 构建一个人名类别与具体人名对应关系的字典
category_lines = {} # 构建所有类别的列表
all_categories = [] # 遍历所有的文件,使用glob.glob中可以利用正则表达式遍历
for filename in glob.glob(data_path + '*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
# 将类别与人名对应关系存储到字典中
category_lines[category] = lines # 测试
print(category_lines['Italian'][:5])
字符无法直接被网络识别,因此要将其编码,这里使用最简单的one-hot编码,实现一个函数
lineToTensor(line),将输入的名字编码成张量def lineToTensor(line):
# 首先初始化一个全0的张量,大小为len(line) * 1 * n_letters
# 代表人名每个字母都用一个(1 * n_letters)的one-hot向量表示
tensor = torch.zeros(len(line), 1, len(all_letters))
# 遍历人名的每个字母, 并搜索其在所有字母中的位置,将其对应的位置置为1
for li, letter in enumerate(line):
tensor[li][0][all_letters.find(letter)] = 1 return tensor
# 测试
line = "Bai"
tensor = lineToTensor(line)
print("line_tensor:", tensor)
print("line_tensor_size:", tensor.size())
2. 模型搭建
搭建RNN模型
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(RNN, self).__init__()
# input_size: 输入数据的特征维度
# hidden_size: RNN隐藏层的最后一个维度
# output_size: RNN网络最后线性层的输出维度
# num_layers: RNN网络的层数
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input1, hidden):
# input: 人名分类器中的输入张量,形状是1*n_letters
# hidden: 代表隐藏层张量,形状是self.num_layers*1*hidden_size
# 输入到RNN中的张量要求是三维张量,所以需要用unsqueeze()函数扩充维度
input1 = input1.unsqueeze(0)
rr, hn = self.rnn(input1, hidden)
# 将RNN中获得的结果通过线性层变换和softmax函数输出
return self.softmax(self.linear(rr)), hn def initHidden(self):
# 初始化隐藏层张量,全0张量,维度是3
return torch.zeros(self.num_layers, 1, self.hidden_size)
搭建LSTM模型
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input1, hidden, c):
# 注意:LSTM网络的输入有三个张量,不能忘记细胞状态C
input1 = input1.unsqueeze(0)
rr, (hn, cn) = self.lstm(input1, (hidden, c))
return self.softmax(self.linear(rr)), hn, cn def initHiddenAndC(self):
c = hidden = torch.zeros(self.num_layers, 1, self.hidden_size)
return hidden, c
搭建GRU模型
class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(GRU, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input1, hidden):
input1 = input1.unsqueeze(0)
rr, hn = self.gru(input1, hidden)
return self.softmax(self.linear(rr)), hn def initHidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)
3. 模型的实例化与训练
定义一些参数以及实例化模型
# 参数
input_size = len(all_letters)
n_hidden = 128
output_size = n_categories
input1 = lineToTensor('B').squeeze(0)
hidden = c = torch.zeros(1, 1, n_hidden) rnn = RNN(input_size, n_hidden, output_size)
lstm = LSTM(input_size, n_hidden, output_size)
gru = GRU(input_size, n_hidden, output_size) # 测试
rnn_output, rnn_hidden = rnn(input1, hidden)
lstm_output, lstm_hidden, next_c = lstm(input1, hidden, c)
gru_output, gru_hidden = gru(input1, hidden) # 打印输出信息
print("rnn_output:", rnn_output)
print("rnn_shape:", rnn_output.shape)
print("********************************")
print("lstm_output:", lstm_output)
print("lstm_shape:", lstm_output.shape)
print("********************************")
print("gru_output:", gru_output)
print("gru_shape:", gru_output.shape)
categoryFromOutput(output)函数功能为从模型输出中获取最大值和最大值的索引def categoryFromOutput(output):
# 从输出中获取最大值和最大值的索引
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i
randomTrainingExample()函数功能为随机选训练所需的数据def randomTrainingExample():
# 随机选择一个类别
category = random.choice(all_categories)
# 从该类别中随机选择一个人名
line = random.choice(category_lines[category])
# 将人名转换为张量
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor
构建训练函数
# 构建传统RNN训练函数
criterion = nn.NLLLoss()
learning_rate = 0.005
def trainRNN(category_tensor, line_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
output = None
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden) # rnn对象由nn.RNN实例化得到,最终输出得到的是三维张量,为了满足category_tensor的维度要求,需要将其转换为二维张量
loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
# 更新参数
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item() def trainLSTM(category_tensor, line_tensor):
hidden, c = lstm.initHiddenAndC()
lstm.zero_grad()
output = None
for i in range(line_tensor.size()[0]):
output, hidden, c = lstm(line_tensor[i], hidden, c) loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in lstm.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item() def trainGRU(category_tensor, line_tensor):
hidden = gru.initHidden()
gru.zero_grad()
output = None
for i in range(line_tensor.size()[0]):
output, hidden = gru(line_tensor[i], hidden) loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in gru.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item()
绘图的辅助函数
timeSince(since)用于记录代码运行时间# 构建时间计算函数
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return "%dm %ds" % (m, s)
构建完整的训练函数
# 训练轮次
n_iters = 1000
# 每隔print_every打印一次信息
print_every = 50
# 每个plot_every作为一次绘图采样点
plot_every = 10
def train(train_type_fn):
# 每个制图间隔损失保存列表
all_losses = []
# 获得开始的时间戳
start = time.time()
current_loss = 0
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train_type_fn(category_tensor, line_tensor)
current_loss += loss
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = "✓" if guess == category else "✗ (%s)" % category
print("%d %d%% (%s) %.4f %s / %s %s" % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0
return all_losses, int(time.time() - start)
训练并绘图
# 训练并制作对比图
all_losses1, period1 = train(trainRNN)
all_losses2, period2 = train(trainLSTM)
all_losses3, period3 = train(trainGRU) plt.figure(0)
plt.plot(all_losses1, label='RNN')
plt.plot(all_losses2, color='red', label='LSTM')
plt.plot(all_losses3, color='green', label='GRU')
plt.legend(loc='upper left') plt.figure(1)
x_data = ['RNN', 'LSTM', 'GRU']
y_data = [period1, period2, period3]
plt.bar(range(len(x_data)), y_data, color='green', tick_label=x_data)
为方便测试,训练轮次只设置了一千,图形跑出来看不是很清楚,以下为训练1e5次的效果
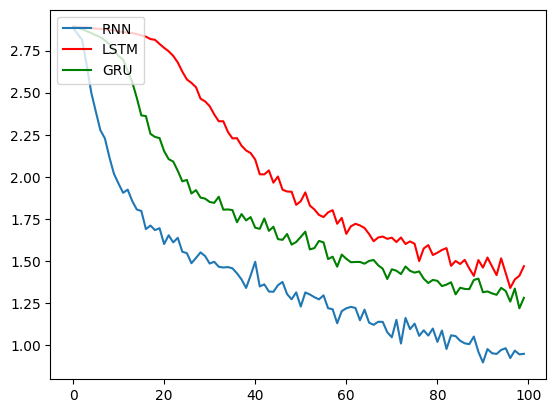
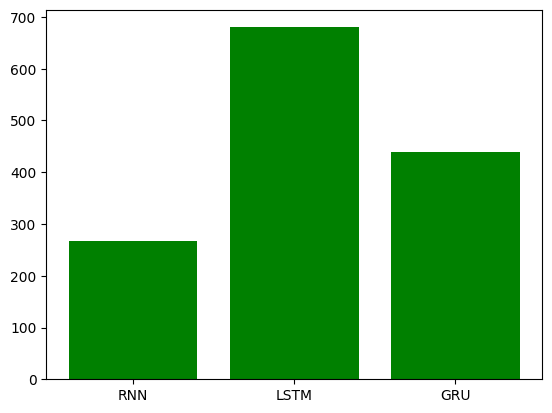
4. 构建评估函数和预测函数
评估函数
def evaluateRNN(line_tensor):
output = None
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output.squeeze(0) def evaluateLSTM(line_tensor):
output = None
hidden, c = lstm.initHiddenAndC()
for i in range(line_tensor.size()[0]):
output, hidden, c = lstm(line_tensor[i], hidden, c)
return output.squeeze(0) def evaluateGRU(line_tensor):
output = None
hidden = gru.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = gru(line_tensor[i], hidden)
return output.squeeze(0)
预测函数
def predict(input_line, evaluate, n_predictions=3):
print("\n> %s" % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
topv, topi = output.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print("(%.2f) %s" % (value, all_categories[category_index]))
predictions.append([value, all_categories[category_index]]) # 测试
for evaluate_fn in [evaluateRNN, evaluateLSTM, evaluateGRU]:
predict('Dovesky', evaluate_fn)
predict('Jackson', evaluate_fn)
predict('Satoshi', evaluate_fn)完整代码版(方便复制来测试)
import torch
from io import open
import glob
import os
import unicodedata
import string
import random
import time
import math
import torch.nn as nn
import matplotlib.pyplot as plt
data_path = './data/names/' all_letters = string.ascii_letters + " .,;'"
def unicodeToAscii(text):
"""
Converts a Unicode string to an ASCII string. Args:
text (str): The Unicode string to convert. Returns:
str: The ASCII string.
"""
return ''.join([
unicodedata.normalize('NFKD', char)
for char in text
if not unicodedata.combining(char)
]).encode('ascii', 'ignore').decode('ascii') def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines] # 构建一个人名类别与具体人名对应关系的字典
category_lines = {} # 构建所有类别的列表
all_categories = [] # 遍历所有的文件,使用glob.glob中可以利用正则表达式遍历
for filename in glob.glob(data_path + '*.txt'):
category = os.path.splitext(os.path.basename(filename))[0]
all_categories.append(category)
lines = readLines(filename)
# 将类别与人名对应关系存储到字典中
category_lines[category] = lines n_categories = len(all_categories) def lineToTensor(line):
# 首先初始化一个全0的张量,大小为len(line) * 1 * n_letters
# 代表人名每个字母都用一个(1 * n_letters)的one-hot向量表示
tensor = torch.zeros(len(line), 1, len(all_letters))
# 遍历人名的每个字母, 并搜索其在所有字母中的位置,将其对应的位置置为1
for li, letter in enumerate(line):
tensor[li][0][all_letters.find(letter)] = 1 return tensor class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(RNN, self).__init__()
# input_size: 输入数据的特征维度
# hidden_size: RNN隐藏层的最后一个维度
# output_size: RNN网络最后线性层的输出维度
# num_layers: RNN网络的层数
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input1, hidden):
# input: 人名分类器中的输入张量,形状是1*n_letters
# hidden: 代表隐藏层张量,形状是self.num_layers*1*hidden_size
# 输入到RNN中的张量要求是三维张量,所以需要用unsqueeze()函数扩充维度
input1 = input1.unsqueeze(0)
rr, hn = self.rnn(input1, hidden)
# 将RNN中获得的结果通过线性层变换和softmax函数输出
return self.softmax(self.linear(rr)), hn def initHidden(self):
# 初始化隐藏层张量,全0张量,维度是3
return torch.zeros(self.num_layers, 1, self.hidden_size) class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(LSTM, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input1, hidden, c):
# 注意:LSTM网络的输入有三个张量,不能忘记细胞状态C
input1 = input1.unsqueeze(0)
rr, (hn, cn) = self.lstm(input1, (hidden, c))
return self.softmax(self.linear(rr)), hn, cn def initHiddenAndC(self):
c = hidden = torch.zeros(self.num_layers, 1, self.hidden_size)
return hidden, c class GRU(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(GRU, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.gru = nn.GRU(input_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=-1) def forward(self, input1, hidden):
input1 = input1.unsqueeze(0)
rr, hn = self.gru(input1, hidden)
return self.softmax(self.linear(rr)), hn def initHidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size) # 参数
input_size = len(all_letters)
n_hidden = 128
output_size = n_categories
hidden = c = torch.zeros(1, 1, n_hidden) rnn = RNN(input_size, n_hidden, output_size)
lstm = LSTM(input_size, n_hidden, output_size)
gru = GRU(input_size, n_hidden, output_size) def categoryFromOutput(output):
# 从输出中获取最大值和最大值的索引
top_n, top_i = output.topk(1)
category_i = top_i[0].item()
return all_categories[category_i], category_i # category, category_i = categoryFromOutput(rnn_output)
# print("category:", category)
# print("category_i:", category_i) def randomTrainingExample():
# 随机选择一个类别
category = random.choice(all_categories)
# 从该类别中随机选择一个人名
line = random.choice(category_lines[category])
# 将人名转换为张量
category_tensor = torch.tensor([all_categories.index(category)], dtype=torch.long)
line_tensor = lineToTensor(line)
return category, line, category_tensor, line_tensor # 构建传统RNN训练函数
criterion = nn.NLLLoss()
learning_rate = 0.005
def trainRNN(category_tensor, line_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
output = None
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden) # rnn对象由nn.RNN实例化得到,最终输出得到的是三维张量,为了满足category_tensor的维度要求,需要将其转换为二维张量
loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
# 更新参数
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item() def trainLSTM(category_tensor, line_tensor):
hidden, c = lstm.initHiddenAndC()
lstm.zero_grad()
output = None
for i in range(line_tensor.size()[0]):
output, hidden, c = lstm(line_tensor[i], hidden, c) loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in lstm.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item() def trainGRU(category_tensor, line_tensor):
hidden = gru.initHidden()
gru.zero_grad()
output = None
for i in range(line_tensor.size()[0]):
output, hidden = gru(line_tensor[i], hidden) loss = criterion(output.squeeze(0), category_tensor)
loss.backward()
for p in gru.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.item() # 构建时间计算函数
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return "%dm %ds" % (m, s) # 完整的训练函数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
n_iters = 1000
print_every = 50
plot_every = 10
def train(train_type_fn):
# 每个制图间隔损失保存列表
all_losses = []
# 获得开始的时间戳
start = time.time()
current_loss = 0
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train_type_fn(category_tensor, line_tensor)
current_loss += loss
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = "✓" if guess == category else "✗ (%s)" % category
print("%d %d%% (%s) %.4f %s / %s %s" % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0
return all_losses, int(time.time() - start) # 训练并制作对比图
all_losses1, period1 = train(trainRNN)
all_losses2, period2 = train(trainLSTM)
all_losses3, period3 = train(trainGRU) plt.figure(0)
plt.plot(all_losses1, label='RNN')
plt.plot(all_losses2, color='red', label='LSTM')
plt.plot(all_losses3, color='green', label='GRU')
plt.legend(loc='upper left') plt.figure(1)
x_data = ['RNN', 'LSTM', 'GRU']
y_data = [period1, period2, period3]
plt.bar(range(len(x_data)), y_data, color='green', tick_label=x_data) # 构建评估函数
def evaluateRNN(line_tensor):
output = None
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output.squeeze(0) def evaluateLSTM(line_tensor):
output = None
hidden, c = lstm.initHiddenAndC()
for i in range(line_tensor.size()[0]):
output, hidden, c = lstm(line_tensor[i], hidden, c)
return output.squeeze(0) def evaluateGRU(line_tensor):
output = None
hidden = gru.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = gru(line_tensor[i], hidden)
return output.squeeze(0) # 构建预测函数
def predict(input_line, evaluate, n_predictions=3):
print("\n> %s" % input_line)
with torch.no_grad():
output = evaluate(lineToTensor(input_line))
topv, topi = output.topk(n_predictions, 1, True)
predictions = []
for i in range(n_predictions):
value = topv[0][i].item()
category_index = topi[0][i].item()
print("(%.2f) %s" % (value, all_categories[category_index]))
predictions.append([value, all_categories[category_index]]) # 调用试试
for evaluate_fn in [evaluateRNN, evaluateLSTM, evaluateGRU]:
predict('Dovesky', evaluate_fn)
predict('Jackson', evaluate_fn)
predict('Satoshi', evaluate_fn)
传统RNN网络及其案例--人名分类的更多相关文章
- RNN与应用案例:注意力模型与机器翻译
1. 注意力模型 1.2 注意力模型概述 注意力模型(attention model)是一种用于做图像描述的模型.在笔记6中讲过RNN去做图像描述,但是精准度可能差强人意.所以在工业界,人们更喜欢用a ...
- 第二十节,使用RNN网络拟合回声信号序列
这一节使用TensorFlow中的函数搭建一个简单的RNN网络,使用一串随机的模拟数据作为原始信号,让RNN网络来拟合其对应的回声信号. 样本数据为一串随机的由0,1组成的数字,将其当成发射出去的一串 ...
- 深度学习原理与框架-递归神经网络-RNN网络基本框架(代码?) 1.rnn.LSTMCell(生成单层LSTM) 2.rnn.DropoutWrapper(对rnn进行dropout操作) 3.tf.contrib.rnn.MultiRNNCell(堆叠多层LSTM) 4.mlstm_cell.zero_state(state初始化) 5.mlstm_cell(进行LSTM求解)
问题:LSTM的输出值output和state是否是一样的 1. rnn.LSTMCell(num_hidden, reuse=tf.get_variable_scope().reuse) # 构建 ...
- 深度学习原理与框架-递归神经网络-RNN_exmaple(代码) 1.rnn.BasicLSTMCell(构造基本网络) 2.tf.nn.dynamic_rnn(执行rnn网络) 3.tf.expand_dim(增加输入数据的维度) 4.tf.tile(在某个维度上按照倍数进行平铺迭代) 5.tf.squeeze(去除维度上为1的维度)
1. rnn.BasicLSTMCell(num_hidden) # 构造单层的lstm网络结构 参数说明:num_hidden表示隐藏层的个数 2.tf.nn.dynamic_rnn(cell, ...
- 使用tensorflow 构建rnn网络
使用tensorflow实现了简单的rnn网络用来学习加法运算. tensorflow 版本:1.1 import tensorflow as tf from tensorflow.contrib i ...
- Java 学习之网络编程案例
网络编程案例 一,概念 1,网络编程不等于网站编程 2,编程只和传输层打交道,即TCP和UDP两个协议 二,案例 1,TCP实现点对点的聊天 Server端:两个输入流:读客户端和控制台,一个输出端: ...
- 6.keras-基于CNN网络的Mnist数据集分类
keras-基于CNN网络的Mnist数据集分类 1.数据的载入和预处理 import numpy as np from keras.datasets import mnist from keras. ...
- boost asio 网络编程案例简单改写
boost教程:http://zh.highscore.de/cpp/boost/ 改写7.4网络编程案例,服务器支持连接多个客户端 服务端: #include <iostream> #i ...
- RNN网络【转】
本文转载自:https://zhuanlan.zhihu.com/p/29212896 简单的Char RNN生成文本 Sherlock I want to create some new thing ...
- Android Multimedia框架总结(二)MediaPlayer框架及播放网络视频案例
前言:前面一篇我们介绍MediaPlayer相关方法,有人说,没有实际例子,看得不是很明白,今天在分析MediaPlayer时,顺带一个播放网络视频例子.可以自行试试.今天分析的都是下几篇介绍各个模块 ...
随机推荐
- 2023 Stack Overflow 调研
一.Programming, scripting, and markup languages 二.Databases 三.Web frameworks and technologies 四.Other ...
- Spring如何控制Bean的加载顺序
前言 正常情况下,Spring 容器加载 Bean 的顺序是不确定的,那么我们如果需要按顺序加载 Bean 时应如何操作?本文将详细讲述我们如何才能控制 Bean 的加载顺序. 场景 我创建了 4 个 ...
- Java简单实现MQ架构和思路01
实现一个 MQ(消息队列)架构可以涉及到很多方面,包括消息的生产和消费.消息的存储和传输.消息的格式和协议等等.下面是一个简单的 MQ 架构的实现示例,仅供参考: 定义消息格式和协议:我们可以定义一个 ...
- 阿里DataX极简教程
目录 简介 工作流程 核心架构 核心模块介绍 DataX调度流程 支持的数据 实践 下载 环境 执行流程 引用 简介 DataX是一个数据同步工具,可以将数据从一个地方读取出来并以极快的速度写入另外一 ...
- Clear Code for Minimal API
我在写MinimalAPI的时候,发现不能最清晰的看到每个API,原因就是:WebAPI中不断增长逻辑处理过程 于是我在想如何简化API至一行,在一点一点想办法中,发现了简化DotNET Minima ...
- GROUP BY clause and contains nonaggregated 报错处理
1055 - Expression #16 of SELECT list is not in GROUP BY clause and contains nonaggregated column 报错处 ...
- Android OpenMAX - 开篇
Android Media是一块非常庞大的内容,上到APP的书写,中到播放器的实现.封装格式的了解,下到OMX IL层的实现.Decoder的封装,每一块都需要我们下很大的功夫学习.除此之外,我们还要 ...
- Flutter(五):Flutter 加入现有App的方案选择(Flutter_Boost)
一.介绍 用 Flutter 一次性重写整个已有的应用是不切实际的.对于这些情况,Flutter 可以作为一个库或模块,集成进现有的应用当中.模块引入到您的 Android 或 iOS 应用(当前支持 ...
- 使用rem、动态vh自适应移动端
前言 这是我的 模仿抖音 系列文章的第六篇 第一篇:200行代码实现类似Swiper.js的轮播组件 第二篇:实现抖音 "视频无限滑动"效果 第三篇:Vue 路由使用介绍以及添加转 ...
- 7.12考试总结(NOIP模拟12)[简单的区间·简单的玄学·简单的填数]
即使想放弃,也没法放弃最想要的东西,这就是人 前言 这次应该是和 SDFZ 一起打的第一场比赛吧. 然而我还是 FW 一个... 这次考试也有不少遗憾,主要的问题是码力不足,不敢去直面正解,思考程度不 ...