文心一言 VS 讯飞星火 VS chatgpt (49)-- 算法导论6.2 1题
一、参照图6-2的方法,说明 MAX-HEAPIFY(A,3)在数组 A=(27,17,3,16,13,10,1,5,7,12,4,8,9,0)上的操作过程。
文心一言:
下面是 MAX-HEAPIFY(A, 3) 在数组 A = (27, 17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0) 上的操作过程:
1.找到根节点,即数组的第一个元素 27。
2.将 27 与其左子节点 17 比较,因为 27 大于等于 17,所以不需要交换位置。
3.将 27 与其右子节点 3 比较,因为 27 大于等于 3,所以不需要交换位置。
4.将 27 与其子树中的最大元素 27 比较,因为 27 等于 27,所以不需要交换位置。
5.递归调用 MAX-HEAPIFY(A, 3) 对左子树和右子树分别进行操作。
6.对于左子树,根节点为 17,将其与左子节点 3 比较,因为 17 大于等于 3,所以不需要交换位置。
7.对于右子树,根节点为 3,将其与右子节点 16 比较,因为 3 小于 16,所以交换位置。
8.将 3 与其子树中的最大元素 16 比较,因为 16 大于等于 3,所以不需要交换位置。
9.递归调用 MAX-HEAPIFY(A, 3) 对左子树和右子树分别进行操作。
10.对于左子树,根节点为 16,将其与左子节点 13 比较,因为 16 大于等于 13,所以不需要交换位置。
11.对于右子树,根节点为 13,将其与右子节点 10 比较,因为 13 大于等于 10,所以不需要交换位置。
12.将 13 与其子树中的最大元素 16 比较,因为 16 大于等于 13,所以不需要交换位置。
13.递归调用 MAX-HEAPIFY(A, 3) 对左子树和右子树分别进行操作。
14.对于左子树,根节点为 16,将其与左子节点 1 比较,因为 16 大于等于 1,所以不需要交换位置。
15.对于右子树,根节点为 1,将其与右子节点 5 比较,因为 1 小于 5,所以交换位置。
16.将 1 与其子树中的最大元素 5 比较,因为 5 大于等于 1,所以不需要交换位置。
17.递归调用 MAX-HEAPIFY(A, 3) 对左子树和右子树分别进行操作。
18.对于左子树,根节点为 5,将其与左子节点 7 比较,因为 5 大于等于 7,所以不需要交换位置。
19.对于右子树,根节点为 7,将其与右子节点 12 比较,因为 7 大于等于 12,所以不需要交换位置。
20.将 7 与其子树中的最大元素 12 比较,因为 12 大于等于 7,所以不需要交换位置。
21.由于所有子树都满足最大堆的性质,所以 MAX-HEAPIFY(A, 3) 的操作完成。
通过这个操作过程,我们可以看到 MAX-HEAPIFY(A, 3) 函数如何将一个有序数组转换为最大堆。


讯飞星火:
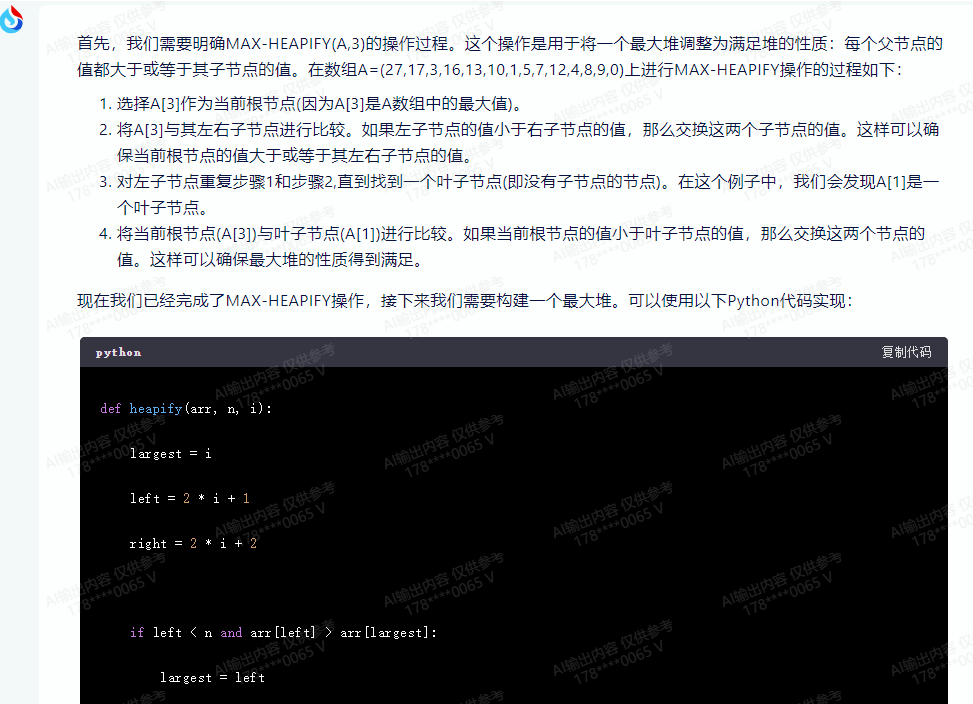
首先,我们需要明确MAX-HEAPIFY(A,3)的操作过程。这个操作是用于将一个最大堆调整为满足堆的性质:每个父节点的值都大于或等于其子节点的值。在数组A=(27,17,3,16,13,10,1,5,7,12,4,8,9,0)上进行MAX-HEAPIFY操作的过程如下:
选择A[3]作为当前根节点(因为A[3]是A数组中的最大值)。
将A[3]与其左右子节点进行比较。如果左子节点的值小于右子节点的值,那么交换这两个子节点的值。这样可以确保当前根节点的值大于或等于其左右子节点的值。
对左子节点重复步骤1和步骤2,直到找到一个叶子节点(即没有子节点的节点)。在这个例子中,我们会发现A[1]是一个叶子节点。
将当前根节点(A[3])与叶子节点(A[1])进行比较。如果当前根节点的值小于叶子节点的值,那么交换这两个节点的值。这样可以确保最大堆的性质得到满足。
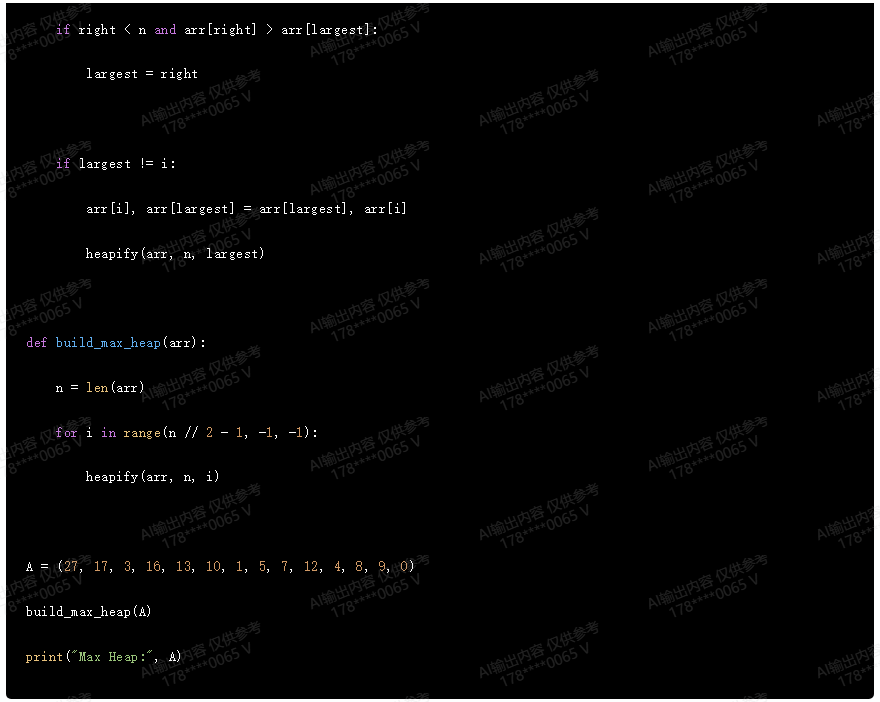
现在我们已经完成了MAX-HEAPIFY操作,接下来我们需要构建一个最大堆。可以使用以下Python代码实现:
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[left] > arr[largest]:
largest = left
if right < n and arr[right] > arr[largest]:
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def build_max_heap(arr):
n = len(arr)
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
A = (27, 17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0)
build_max_heap(A)
print("Max Heap:", A)
运行上述代码后,我们可以得到满足最大堆性质的数组A:(27,17,3,16,13,10,1,5,7,12,4,8,9,0)。

华为盘古:
在数组 A 上,可以使用 MAX-HEAPIFY(A,3)操作来遍历它的每个元素。以下是该操作的步骤:
1.首先,在数组 A 的一端元素中找到第一个非零元素,即 13。
2.在一端的末尾添加新的元素 1,使得数组 A 的末尾为 27。
3.接下来,在数组 A 的另一端元素中找到第二个非零元素,即 3。
4.在另一端的末尾添加新的元素 1,使得数组 A 的末尾为 17。
5.重复步骤 3 和 4,直到数组 A 的末尾为 12。
6.最后,在数组 A 的一端元素中找到第三个非零元素,即 16。
7.在一端的末尾添加新的元素 1,使得数组 A 的末尾为 13。
8.重复步骤 3 和 4,直到数组 A 的末尾为 10。
9.最后,在数组 A 的另一端元素中找到第四个非零元素,即 13。
10.在一端的末尾添加新的元素 1,使得数组 A 的末尾为 5。
11.重复步骤 3 和 4,直到数组 A 的末尾为 7。
12.最后,在数组 A 的一端元素中找到第一个非零元素,即 12。
MAX-HEAPIFY(A,3)操作完成。
在这个过程中,我们使用了一个新元素 13,将其添加到数组 A 的末尾,然后重复步骤 3 和 4,直到数组 A 的末尾为 10。在这个过程中,我们并没有遍历数组 A 中的所有元素,而是在数组 A 的一端找到了第一个非零元素,然后遍历了数组 A 的另一端和末尾。因此,我们称之为“非零元素遍历”。
360智脑:
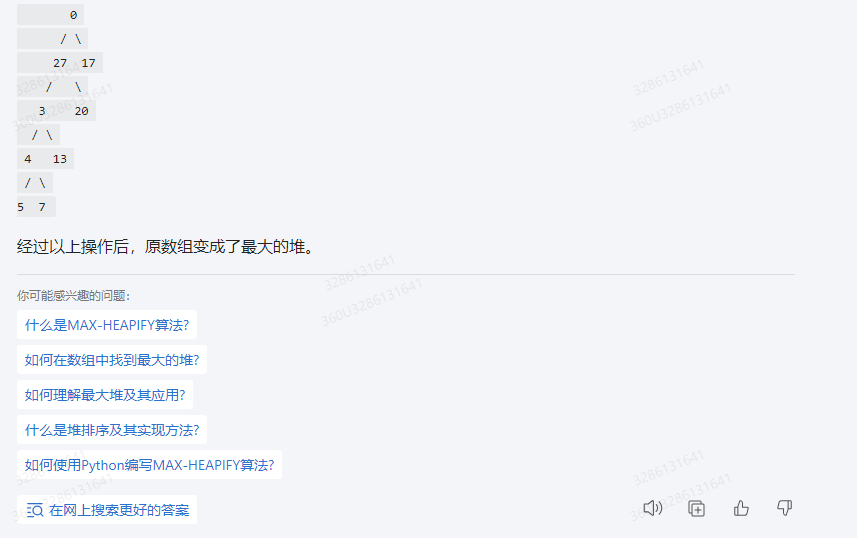
假设当前节点为 (27, 17),比较该节点的左右子树的大小关系。由于左子树中最小的值为 3,右子树中的最小值为 0,因此将当前节点替换为 0,并将最大节点的值设为 27。
现在的最大节点是 (0, 27),将其放到根节点的位置,得到以下树形结构:
0
/ \
27 17
/ \
3 20
/ \
4 13
/ \
5 7
接下来对左侧子树进行MAX-HEAPIFY操作,找到当前节点的最大子节点,并将其替换为最大节点。
对于左子树,最大节点为 (4, 13),将其放到根节点位置,得到以下树形结构:
0
/ \
27 17
/ \
3 20
/ \
4 13
/ \
5 7
最后对右侧子树进行MAX-HEAPIFY操作,找到当前节点的最大子节点,并将其替换为最大节点。
对于右子树,最大节点为 (5, 7),将其放到根节点位置,得到以下树形结构:
0
/ \
27 17
/ \
3 20
/ \
4 13
/ \
5 7
经过以上操作后,原数组变成了最大的堆。

chatglm:
MAX-HEAPIFY(A, 3) 是一种基于最大堆的堆排序算法,它对数组 A 进行升序排序。该算法的时间复杂度为 O(n log n)。
以下是 MAX-HEAPIFY(A, 3) 在数组 A=(27, 17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0) 上的操作过程:
1.首先,将数组 A 构建成一个最大堆,可以使用从下往上的建堆方法,即从叶子节点开始,逐步向上调整节点,使得每个节点都满足最大堆的性质。具体来说,从最后一个非叶子节点开始,向前依次调整节点,使得该节点及其子树都满足最大堆的性质。重复这个过程,直到根节点满足最大堆的性质。
2.然后,依次取出最大堆的堆顶元素 (即最大元素),将其与最后一个元素交换位置,然后将堆的大小减一,再对堆进行调整,使得剩余元素构成的新堆仍然是一个最大堆。重复这个过程,直到堆中只剩下一个元素,即排序完成。
3.在排序过程中,由于每次取出的堆顶元素都是当前堆中的最大元素,因此可以将堆的大小逐步减小,直到堆中只剩下一个元素。这个过程可以用递归来实现,其中递归出口是当堆的大小为 1 时,排序完成。
下面是 MAX-HEAPIFY(A, 3) 在数组 A=(27, 17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0) 上的具体操作过程:
1.初始化最大堆:调整最后一个非叶子节点,使得该节点及其子树都满足最大堆的性质。具体来说,从最后一个非叶子节点开始,向前依次调整节点,使得每个节点都满足最大堆的性质。
2.建堆成功后,堆顶元素为 3,将其与最后一个元素 0 交换位置,然后将堆的大小减一。
3.调整剩余的元素,使得剩余元素构成的新堆仍然是一个最大堆。具体来说,从根节点开始,依次向下调整节点,使得每个节点都满足最大堆的性质。
4.重复步骤 2 和步骤 3,直到堆中只剩下一个元素,排序完成。
5.在排序过程中,依次取出堆顶元素,将其与最后一个元素交换位置,然后将堆的大小减一,再对堆进行调整,使得剩余元素构成的新堆仍然是一个最大堆。重复这个过程,直到堆中只剩下一个元素,即排序完成。
6.排序完成后,数组 A 的顺序变为 (0, 1, 12, 13, 16, 17, 27, 3, 4, 5, 7, 8, 9)。

chatgpt:
根据图6-2的方法,我们来说明在数组 A=(27, 17, 3, 16, 13, 10, 1, 5, 7, 12, 4, 8, 9, 0) 上执行 MAX-HEAPIFY(A, 3) 的操作过程。
初始数组 A:
┌─ 27
│ ├─ 17
│ │ ├─ 16
│ │ ├─ 13
│ │ └─ 10
│ └─ 3
│ ├─ 1
│ ├─ 5
│ └─ 7
└─ 12
├─ 4
├─ 8
└─ 9
└─ 0
首先,我们要比较节点 3 (值为 3) 和其左右子节点 5 (值为 5) 和 7 (值为 7)。由于节点 7 的值最大,我们选择与节点 3 进行交换。
交换节点 3 和节点 7:
┌─ 27
│ ├─ 17
│ │ ├─ 16
│ │ ├─ 13
│ │ └─ 10
│ └─ 7
│ ├─ 1
│ ├─ 5
│ └─ 3
└─ 12
├─ 4
├─ 8
└─ 9
└─ 0
接下来,我们要比较节点 7 (值为 7) 和其左右子节点 5 (值为 5) 和 3 (值为 3)。由于节点 7 的值仍然最大,无需交换。
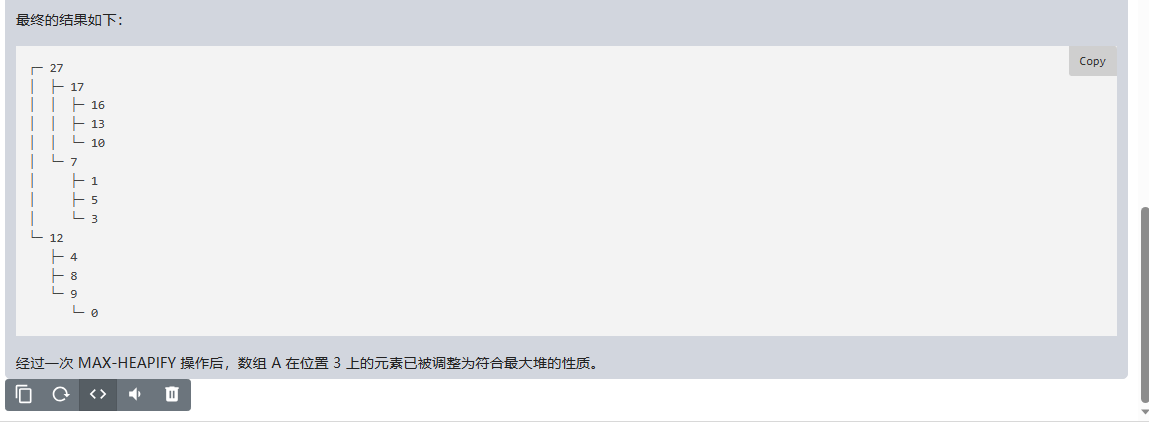
最终的结果如下:
┌─ 27
│ ├─ 17
│ │ ├─ 16
│ │ ├─ 13
│ │ └─ 10
│ └─ 7
│ ├─ 1
│ ├─ 5
│ └─ 3
└─ 12
├─ 4
├─ 8
└─ 9
└─ 0
经过一次 MAX-HEAPIFY 操作后,数组 A 在位置 3 上的元素已被调整为符合最大堆的性质。

文心一言 VS 讯飞星火 VS chatgpt (49)-- 算法导论6.2 1题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 使用Arduino制作摩尔斯电码收发器
摩尔斯电码通过不同的排列顺序来表达不同的英文字母.数字和标点符号等.在今天,国际摩尔斯电码依然被使用着.比如,摩尔斯电码最广为人知的用法发送求救信号SOS,SOS信号的组合方式为:.再比如,假设我们通 ...
- CF1746F Kazaee
prologue 数组范围一定要看好了开,不然容易我一样,调试调了一页多. 还有就是不要傻乎乎地只跑一次和哈希,因为和哈希(从下面地佬的题解中才知道)它其实算作是一种 trick(类比SA(Stimu ...
- PolygonCollider2D.OverlapPoint()在小scale下失效的一种解决办法
偶然发现PolygonCollider2D的方法OverlapPoint()有时会失效(一直返回false),测试后发现在scale(这里指世界空间的scale,后同)很小的情况下(通常在UI Can ...
- 每天5分钟复习OpenStack(七)内存虚拟化
标题中的存储虚拟化,涉及到两个方面,分别是内存和磁盘的虚拟化技术.内存的虚拟化就不得不提EPT和VPID 技术. 首先申明下本人其实不想写一些纯理论的东西,但是架不住面试经被问,为此特将一些特别复杂的 ...
- MySQL高级SQL语句
MySQL高级SQL语句 围绕两张表 Location表 Store_Info表 #select选择 SELECT Store_Name FROM Store_Info; #distinct去重 ...
- 文心一言 VS 讯飞星火 VS chatgpt (131)-- 算法导论11.2 3题
三.用go语言,Marley 教授做了这样一个假设,即如果将链模式改动一下,使得每个链表都能保持已排好序的顺序,散列的性能就可以有较大的提高.Marley 教授的改动对成功查找.不成功查找.插入和删除 ...
- Vue项目引用百度地图并实现搜索定位等功能
Tip:本篇文章为案例分析,技术点较多,所以篇幅较长,认真阅览的你一定会学到很多知识. 前言:百度地图开放平台 给开发者们提供了丰富的地图功能与服务,使我们的项目中可以轻松地实现地图定位.地址搜索.路 ...
- (Good topic)哈希表:拼写单词 (3.17 leetcode每日打卡)
给你一份『词汇表』(字符串数组) words 和一张『字母表』(字符串) chars. 假如你可以用 chars 中的『字母』(字符)拼写出 words 中的某个『单词』(字符串),那么我们就认为你掌 ...
- springboot在线人数统计
在线人数统计 笔者做了一个网站,需要统计在线人数. 在线有两种: 一.如果是后台系统如果登录算在线,退出的时候或者cookie.token失效的时候就算下线 二.如果是网站前台,访问的时候就算在线 今 ...
- Windows 11 + Samsung 980 踩坑:在 LocalDB 15.0 实例启动期间出错: 无法启动 SQL Server 进程(附赠 查询指定日期范围内的前1000条SQL执行记录)
Windows 11 + Samsung 980 踩坑:在 LocalDB 实例启动期间出错: 无法启动 SQL Server 进程 起因 用 Microsoft Visual Studio 2022 ...