ELK查询和汇总
查询表明细:
ELK的KQL样例,显示时间请选择最近15天:
样例1:查询ol_lc 表增删改查,不是jy2_rw的账号明细
KQL:(ol_lc or oc.ol_lc) and (select or update or delete or insert or replace) and not User.keyword=jy2_rw
样例2:查询ol_lc表,不是ems_rw账号只读的SQL执行时间在2月24号的明细
KQL: (ol_lc or oc.ol_lc) and select and not User.keyword=ems_rw and Timestamp.keyword <="2021-02-24 23:59:59" and Timestamp.keyword >="2021-02-24 00:00:00"
样例3,查询ol_lc表,oc写主库d8t的edu_rw账号明细
KQL: (ol_lc or oc.ol_lc) and edu_rw and d8t
KQL建议:
只读: (表 or oc.表) and select (可以过滤 show columns from 表)
写: (表 or oc.表) and (update or delete or replace or insert)
读写: (表 or oc.表) and (update or delete or select or replace or insert)
说明: 如不加上 oc.表, 如查ol_lc: SQL中有oc.ol_lc是查不出来的,切记。
KQL官网帮助文档: https://www.elastic.co/guide/en/kibana/current/kuery-query.html#kuery-query
汇总表
表在各实例的账号调用情况,方法如下:
ELK--Visualize–创建可视化–选择"数据表",如下图:
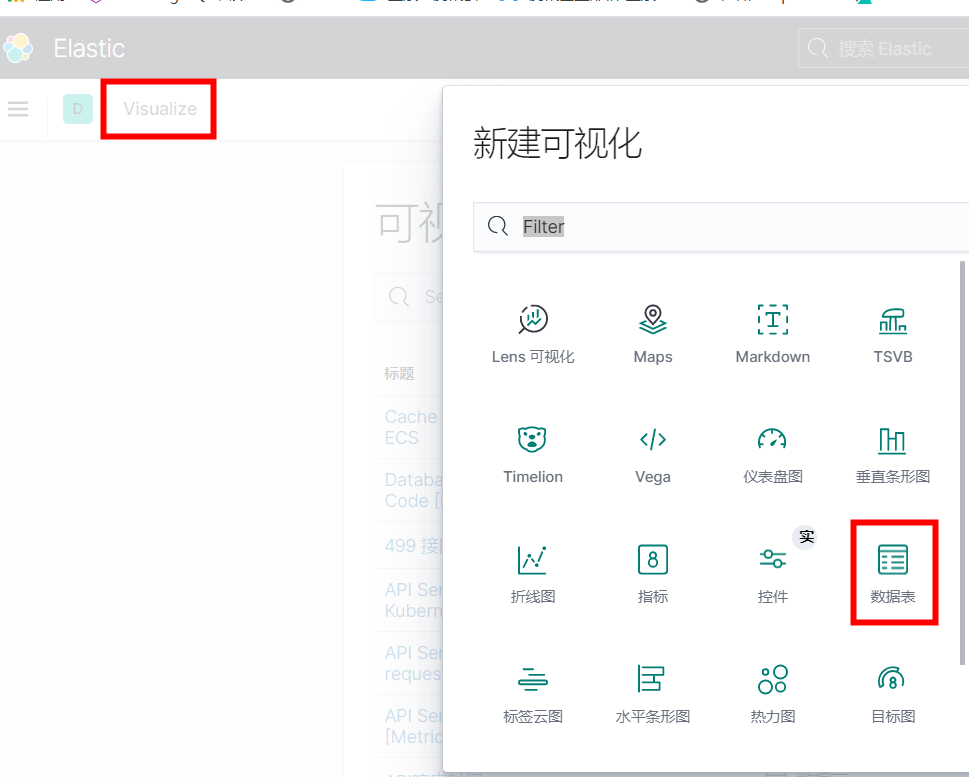
选择"数据源": logstash-myaudit*,跳动聚合分析页面。
在右边选择下列,对聚合的字段汇总计数:
其中:
数据Tab:
1,指标,选择"计数"
2,存储桶,
执行“添加”–“拆分行”: 子聚合:选择“词” 字段:选择“user.keyword” 排序依据:选择“计数”,降序:大小改成:10000(或更大),定制标签:填写:用户
执行“添加”–“拆分行”: 子聚合:选择“词” 字段:选择“Name.keyword” 排序依据:选择“计数”,降序:大小改成:10000(或更大),定制标签:填写:名称
选项Tab:
每页最大行数改成: 10000(或更大)
百分比列改成:计数 (如需做百分比分析)

输入KQL如:ttachment and select,显示日期:选择最近15天, 表在各实例账号调用情况,能快速出来:
KQL可以根据实际情况灵活使用,如果不想查以前,在KQL里加上时间限制。

该结果,能通过点击“原始”或者"格式化"导出csv,根据列表提供的实例名找到对应具体数据库实例。
相关文档:
用ELK分析每天4亿多条腾讯云MySQL审计日志(1)--解决过程
用ELK分析每天4亿多条腾讯云MySQL审计日志(2)--EQL
用ELK分析每天4亿多条腾讯云MySQL审计日志(3)--下载日志
ELK查询和汇总的更多相关文章
- #ThinkPHP_3.2.2模型# where查询条件汇总
特别喜欢 ThinkPHP_3.2.3 框架的Model,结合官方手册及查看源代码,汇总出其大体用法: 核心转换方法: $this->parseWhere($where); $whereStr ...
- ELK查询命令详解
目录 ELK查询命令详解 倒排索引 使用ElasticSearch API 实现CRUD 批量获取文档 使用Bulk API 实现批量操作 版本控制 什么是Mapping? 基本查询(Query查询) ...
- DRF框架中链表数据通过ModelSerializer深度查询方法汇总
DRF框架中链表数据通过ModelSerializer深度查询方法汇总 一.准备测试和理解准备 创建类 class Test1(models.Model): id = models.IntegerFi ...
- ELK查询命令详解总结
目录 ELK查询命令详解 倒排索引 倒排索引原理 分词器介绍及内置分词器 使用ElasticSearch API 实现CRUD 批量获取文档 使用Bulk API 实现批量操作 版本控制 什么是Map ...
- 各种SQL查询技巧汇总 (转)
原文地址: https://blog.csdn.net/tim_phper/article/details/54963828 select select * from student; all 查询所 ...
- django学习-15.ORM查询方法汇总
1.前言 django的ORM框架提供的查询数据库表数据的方法很多,不同的方法返回的结果也不太一样,不同方法都有各自对应的使用场景. 主要常用的查询方法个数是13个,按照特点分为这4类: 方法返回值是 ...
- Java数据库分表与多线程查询结果汇总
今天接到一个需求:要对一个物理分表的逻辑表进行查询统计.而数据库用的是公司自己研发的产品,考虑的到公司产品的特点以及业务的需求,该逻辑表是按年月进行分表的,而非分区.我们来看一下,在按时间段进行查询统 ...
- elk查询语法
查询指定IP段,如123.123.123.* geo.ip=123.123.123.*
- SQL学习笔记——SQL中的数据查询语句汇总
where条件表达式 --统计函数 Select count(1) from student; --like模糊查询 --统计班上姓张的人数 select count(*) from student ...
- hibernate 查询方式汇总
主要摘自 http://blog.sina.com.cn/s/blog_7ffb8dd501014a6o.html ,http://blog.csdn.net/xingtianyiyun/artic ...
随机推荐
- linux环境C语言实现:h264与pcm封装成mp4视频格式
前言 H.264是压缩过的数据,PCM是原始数据,MP4是一种视频封装格式.实际H.264与PCM不能直接合成MP4格式,因为音频格式不对.这里需要中间对音频做一次压缩处理.基本流程为:将PCM音频数 ...
- [转帖]如何查看Docker容器环境变量,如何向容器传递环境变量
https://www.cnblogs.com/larrydpk/p/13437535.html 1 前言 欢迎访问南瓜慢说 www.pkslow.com获取更多精彩文章! 了解Docker容器的运行 ...
- ARMv8.0下duckdb的安装与编译过程-解决 Failed to allocate block of 2048 bytes
ARMv8.0下duckdb的安装与编译过程-解决 Failed to allocate block of 2048 bytes 背景 duckdb 是一个很流行的单机版数据库引擎 同事下载了相关的预 ...
- [转帖]Nginx应用调优案例
https://bbs.huaweicloud.com/blogs/146367 [摘要] 1 问题背景nginx的应用程序移植到TaiShan服务器上,发现业务吞吐量没有达到硬件预期,需要做相应调优 ...
- [转帖]Spring Cloud Alibaba Nacos 注册中心使用教程
一. 什么是Nacos Nacos是一个更易于构建云原生应用的动态服务发现(Nacos Discovery ).服务配置(Nacos Config)和服务管理平台,集注册中心+配置中心+服务管理于一身 ...
- Beyond Compare 的比较以及导出的简单设置方法
最近需要对文件进行对比 但是发现对比的工作量比较难搞. 用到了beyond compare 的工具 感觉挺好用的 但是需要注意事项比较多这里记录一下 1. session setting 里面进行设 ...
- 基于Seata探寻分布式事务的实现方案
作者:京东物流技术与数据智能部 张硕 1 背景知识 随着业务的快速发展.业务复杂度越来越高,几乎每个公司的系统都会从单体走向分布式,特别是转向微服务架构.随之而来就必然遇到分布式事务这个难题,这篇文章 ...
- 一次JSF上线问题引发的MsgPack深入理解,保证对你有收获
作者: 京东零售 肖梦圆 前序 某一日晚上上线,测试同学在回归项目黄金流程时,有一个工单项目接口报JSF序列化错误,马上升级对应的client包版本,编译部署后错误消失. 线上问题是解决了,但是作为程 ...
- VOP 消息仓库演进之路|如何设计一个亿级企业消息平台
作者:京东零售 李孟冬 VOP作为京东企业业务对外的API对接采购供应链解决方案平台,一直致力于从企业采购数字化领域出发,发挥京东数智化供应链能力,通过产业链上下游耦合与链接,有效助力企业客户的成本优 ...
- 【K哥爬虫普法】字节前高管,离职后入侵今日头条数据库,是阴谋、还是利诱?
案情介绍 2016年至2017年间,张洪禹.宋某.侯明强作为被告单位上海晟品网络科技有限公司主管人员,在上海市共谋采用技术手段抓取北京字节跳动网络技术有限公司(办公地点位于本市海淀区北三环西路43号中 ...