Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data
KNime - GUI based
Spark MLlib - inside Spark
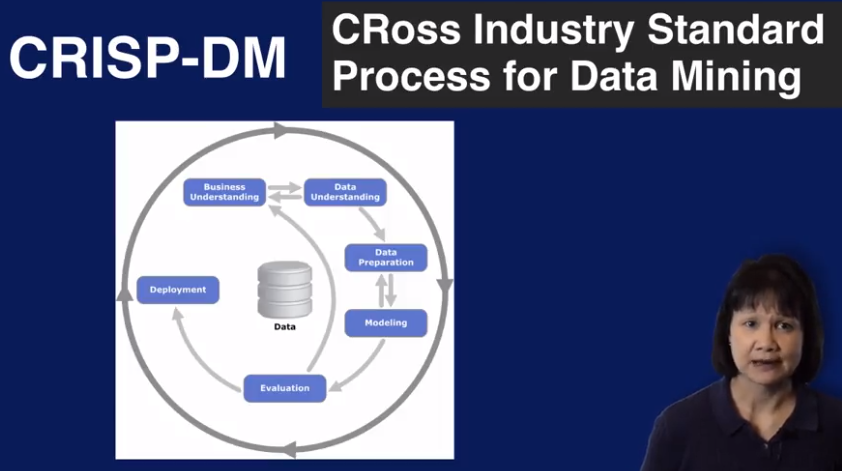
CRISP-DM

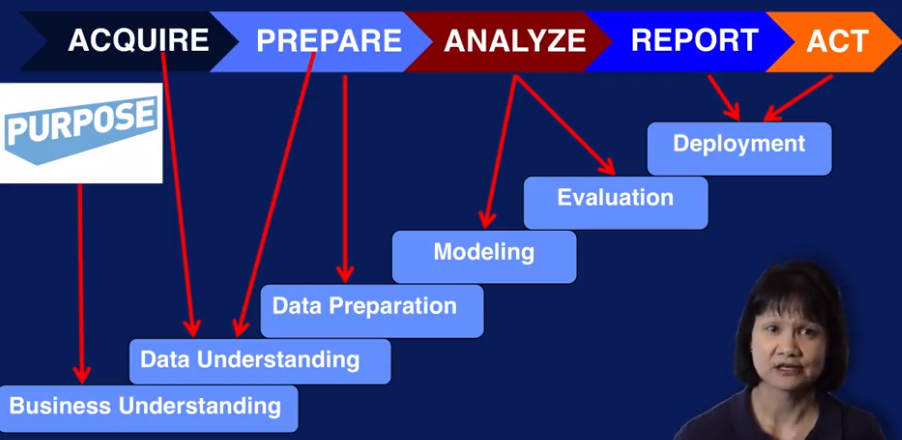
Week 2, Data Exploration
一般有两种方法,summary statistics 和 visualization

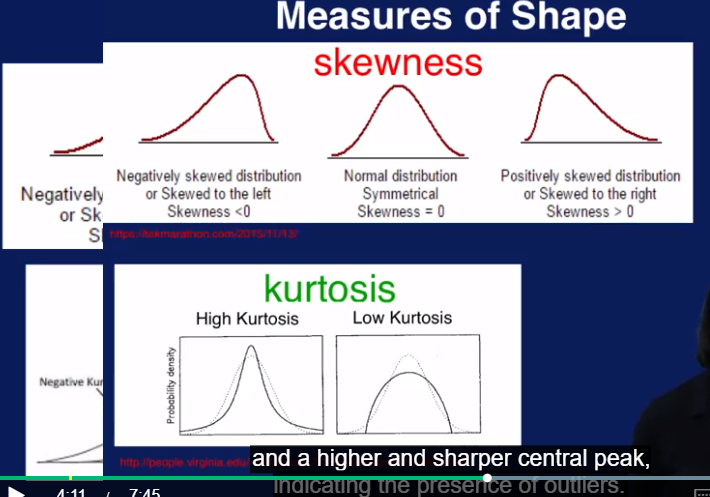
Summary statistics (mean 平均数,median 中位数, mode 最常见的数)


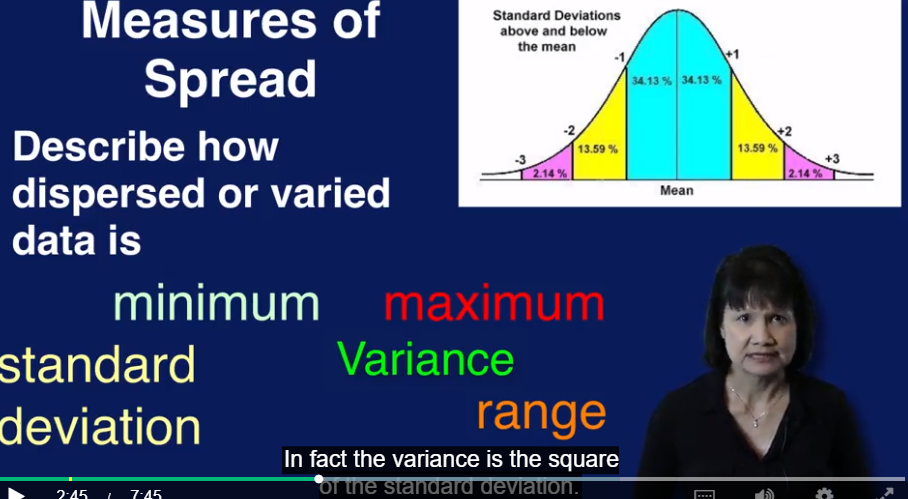
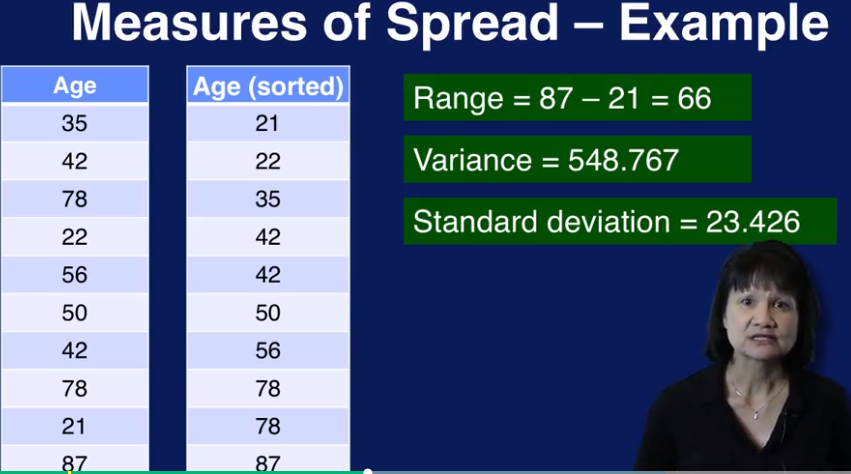
high Kurtosis 预示着有outlier的存在
visualization

这里详细讲一下 box plot
下图的 upper quartile 和 lower quartile 分别指的是 75% 和 25% 的点, median 很明显是中位数点,中间柱状部分的数据占了总数据的50%. Upper extreme 和 Lower extreme 分别是90% 和 10% 数据的点,超出部分就是outliers.

Data preparing


data wrangling 主要是transformation

Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)的更多相关文章
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
- In machine learning, is more data always better than better algorithms?
In machine learning, is more data always better than better algorithms? No. There are times when mor ...
- [Javascript] Classify JSON text data with machine learning in Natural
In this lesson, we will learn how to train a Naive Bayes classifier and a Logistic Regression classi ...
- Coursera 学习笔记|Machine Learning by Standford University - 吴恩达
/ 20220404 Week 1 - 2 / Chapter 1 - Introduction 1.1 Definition Arthur Samuel The field of study tha ...
- [Machine Learning with Python] Data Preparation through Transformation Pipeline
In the former article "Data Preparation by Pandas and Scikit-Learn", we discussed about a ...
- [Machine Learning with Python] Data Preparation by Pandas and Scikit-Learn
In this article, we dicuss some main steps in data preparation. Drop Labels Firstly, we drop labels ...
- 斯坦福大学公开课机器学习:machine learning system design | data for machine learning(数据量很大时,学习算法表现比较好的原理)
下图为四种不同算法应用在不同大小数据量时的表现,可以看出,随着数据量的增大,算法的表现趋于接近.即不管多么糟糕的算法,数据量非常大的时候,算法表现也可以很好. 数据量很大时,学习算法表现比较好的原理: ...
- [Machine Learning with Python] Data Visualization by Matplotlib Library
Before you can plot anything, you need to specify which backend Matplotlib should use. The simplest ...
- Coursera《machine learning》--(14)数据降维
本笔记为Coursera在线课程<Machine Learning>中的数据降维章节的笔记. 十四.降维 (Dimensionality Reduction) 14.1 动机一:数据压缩 ...
随机推荐
- extjs 中比较常见且好用的监听事件
ComboBox listeners:{ expand:function(){ //此函数是,点击下拉框展开的时候事件 }, select:function(com, record, index){ ...
- .net prams关键字
先举个例子: 代码如下: class Program { static void Main(string[] args) { Console.WriteLine(Sum(1)); Console.Wr ...
- golang学习和使用经验总结
学习网址 https://studygolang.com/pkgdoc go标准库网站 https://blog.csdn.net/sanxiaxugang/article/details/60324 ...
- ansible roles
roles 特点 目录结构清晰 重复调用相同的任务 目录结构相同 web - tasks - install.yml - copfile.yml - start.yml - main.yml - t ...
- google 跨域解决办法
--args --disable-web-security --user-data-dir
- filebeat-6.4.3-windows-x86_64输出Kafka
配置filebeat.yml文件 filebeat.prospectors: - type: log encoding: utf- enabled: true paths: - e:\log.log ...
- Nginx CONTENT阶段 concat模块
L67 concat_delimiter : 根据js 指定 分隔符 比如 “|” 那么每个文件分隔符为 “|” concat_types : 指定要合并文件的类型 concat_unique : s ...
- 【Spring】Spring随笔索引
Spring随笔索引 [Spring]Spring bean的实例化 [Spring]手写Spring MVC [Spring]Spring Data JPA
- Bellman-Ford&&SPFA
我们前文说过,有关最短路径除了Floyed算法之外,还有许多更加好的方法.这里讲一下有关 Bellman-Ford和SPFA的知识 Bellman-Ford:复杂度O(VE) 有关Bellman-Fo ...
- Python爬虫之三
1)使用Scrapy,什么叫做Scrapy Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据 ...