关于Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题答案就得去读官方文档吧。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import MySQLdb df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\aaa.csv',encoding='gb2312')
这是我本地测试用的,先看一下效果。
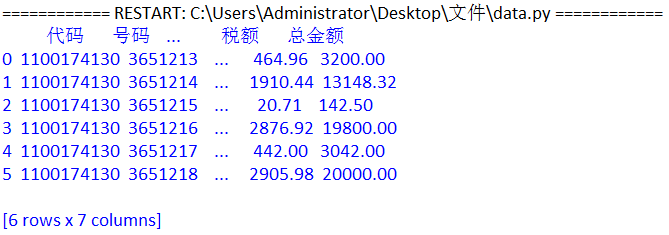
这里看到每一行中间都会出现一个“...”省略号,这是因为模块对于每一行的显示限制,以内存最小形式来显示,所以会以省略号代替其中间的内容。
如果数据行很多的话,对于pandas模块是自动默认只显示100行数据,如果超100行,例如120行,则中间的20行会被“ ... ”替代!
先处理pandas 读取数据后在行中间省略部分的处理:
df = pd.read_csv('C:\\Users\\Administrator\\Desktop\\aaa.csv',encoding='gb2312')
pd.set_option('display.width',None)
print df
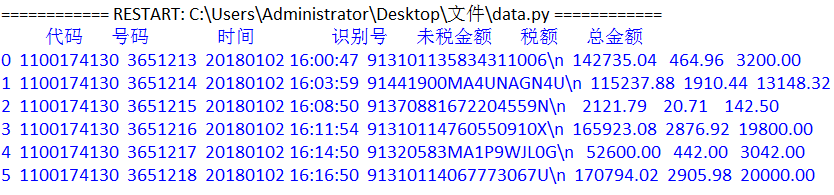
这里只需要添加pd.set_option('display.width',None)即可,http://pandas.pydata.org/pandas-docs/stable/options.html 我也是在官方文档中查找到的,其中有详细的解释,和set_option函数的其他方法。

在度娘中死活也找不到相关的回答,在google中也只有寥寥无几的回答,并且极少出现过这种情况,唯独我遇上了,所以记载以下。
如果是行与行之间的省略,则只需要添加:
pd.set_option('display.max_rows', None)

同样是以最大行数来显示数据。
这里分享一下pandas模块连接数据库的操作:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import numpy as np
import pandas as pd
import MySQLdb #读取url为csv
data_url = 'https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv'
dat = pd.read_csv(data_url) mysql_da = MySQLdb.connect(host='localhost',port=3306,user='root',passwd='root',db='库名')
df = pd.read_sql('select * from 表',con = mysql_da)
pd.set_option('display.width',None)
mysql_da.close()
print df
这部分内容引用:https://www.cnblogs.com/zzhzhao/p/5269217.html#undefined 文章,这是一篇很好的文章,我也是其中学习了很多,但是博主她不知道有没有遇到我的问题。
因为我遇到了这样的问题,所以查了很多资料也未能解决,最后还是在官方文档中偶然间看到的!所以分享给遇到同样问题不知道答案的人!
关于Python pandas模块输出每行中间省略号问题的更多相关文章
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载文件
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- [Python]-pandas模块-CSV文件读写
Pandas 即Python Data Analysis Library,是为了解决数据分析而创建的第三方工具,它不仅提供了丰富的数据模型,而且支持多种文件格式处理,包括CSV.HDF5.HTML 等 ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-03-数据整理
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- python pandas模块简单使用(读取excel为例)
第一步:模块安装 pip install pandas 第二步:使用(单个工作表为例) 说明:如果有多个工作表,那么只要指定sheetname=索引,(第一个工作表为0,第二个工作表为1,以此类推) ...
- python: pandas模块
10分钟入门 pandas 评:我跟作者的智商差距是有多大,才能让我用60分钟看完作者认为10分钟的内容... 详细内容见 Cookbook 习惯上我们先导入 : In [1]: import pan ...
- Python Logging模块 输出日志颜色、过期清理和日志滚动备份
# coding:utf-8 import logging from logging.handlers import RotatingFileHandler # 按文件大小滚动备份 import co ...
- python pandas模块,nba数据处理(1)
pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数.pandas兼具Numpy高性能的数组计算功能以及电子表格和关系型数据(如SQL)灵活的数据处理能力.它提供了复杂精细的索引功 ...
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- python重要的第三方库pandas模块常用函数解析之DataFrame
pandas模块常用函数解析之DataFrame 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器 ...
随机推荐
- mysql免解压版的配置
很多朋友在安装mysq解压版l时出现: “mysql 服务无法启动 服务没报告任何错误” 以前我安装时也是遇到这样的问题: 其实mysql在5.6后就没有了data目录,很多朋友按照以前的版本安装会去 ...
- react-native自定义TextInput光标颜色
<TextInput defaultValue="Highlight Color is red" selectionColor={'red'} style={styles.s ...
- hbase参数配置和说明
版本:0.94-cdh4.2.1 hbase-site.xml配置 hbase.tmp.dir 本地文件系统tmp目录,一般配置成local模式的设置一下,但是最好还是需要设置一下,因为很多文件都会默 ...
- 微服务框架——SpringCloud
1.SpringCloud微服务框架 a.概念:SpringCloud是基于SpringBoot的微服务框架 b.五大神兽:Eureka(服务发现).Ribbon(客服端负载均衡).Hystrix(断 ...
- SQL Server 优化
SELECT TOP 10 [Total Cost] = ROUND(avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) ...
- 爬虫之正则和xpath
一.正解解析 常用正则表达式回顾: 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [-] \D : 非数字 \w :数字.字母.下划线.中 ...
- java 虚拟机学习--未完
1.学习了解GC垃圾回收 参考:https://www.ibm.com/developerworks/cn/java/l-JavaMemoryLeak2/ 2.类加载机制 http://blog.cs ...
- Selenium 实现 Web 自动化的原理 (软件测试52讲学习笔记)
Selenium 1.0 的工作原理 Selenium 1.0,又称Selenium RC ,RC是Remote Control的缩写.Selenium RC利用的原理:JavaScript代码可以方 ...
- mysql学习3
1.索引 索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据.对于索引, 会保存在额外的文件中. 作用: 约束 加速查找 1.1.建立索引 a.额外的文件保存特殊的数据结构 ...
- git教程——工作流程
Git 工作流程 本章节我们将为大家介绍 Git 的工作流程. 一般工作流程如下: 克隆 Git 资源作为工作目录. 在克隆的资源上添加或修改文件. 如果其他人修改了,你可以更新资源. 在提交前查看修 ...