Scrapyd 改进第二步: Web Interface 添加 STOP 和 START 超链接, 一键调用 Scrapyd API
0.提出问题
Scrapyd 提供的开始和结束项目的API如下,参考 Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码,准备继续在页面上进一步添加 START 和 STOP 超链接。
http://scrapyd.readthedocs.io/en/stable/api.html#schedule-json
Example request:
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
Example response:
{"status": "ok", "jobid": "6487ec79947edab326d6db28a2d86511e8247444"}
http://scrapyd.readthedocs.io/en/stable/api.html#cancel-json
Example request:
$ curl http://localhost:6800/cancel.json -d project=myproject -d job=6487ec79947edab326d6db28a2d86511e8247444
Example response:
{"status": "ok", "prevstate": "running"}
1.解决思路
尝试直接通过浏览器地址栏 GET 请求页面 http://localhost:6800/schedule.json?project=myproject&spider=somespider
返回提示需要使用 POST 请求
{"node_name": "pi-desktop", "status": "error", "message": "Expected one of [b'HEAD', b'object', b'POST']"}
那就继续通过 URL 查询对传参,通过 JS 发起 POST 异步请求吧
2.修改 Scrapyd 代码
/site-packages/scrapyd/website.py
改动位置:
(1) table 添加最后两列,分别用于 UTF-8 和 STOP/START 超链接,见红色代码
def render(self, txrequest):
cols = 10 ######## 8
s = "<html><head><meta charset='UTF-8'><title>Scrapyd</title></head>"
s += "<body>"
s += "<h1>Jobs</h1>"
s += "<p><a href='..'>Go back</a></p>"
s += "<table border='1'>"
s += "<tr><th>Project</th><th>Spider</th><th>Job</th><th>PID</th><th>Start</th><th>Runtime</th><th>Finish</th><th>Log</th>"
if self.local_items:
s += "<th>Items</th>"
#cols = 9 ########
cols += 1 ########
(2) 有两处需要添加 UTF-8 超链接,分别对应 Running 和 Finished,见红色代码
前面 Running 部分添加 UTF-8 超链接后继续添加 STOP 超链接,见蓝色代码
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
s += "<td><a href='/logs/scrapyd.html?opt=cancel&project=%s&job_or_spider=%s' target='_blank'>STOP</a></td>" % (p.project, p.job) ########
后面 Finished 部分添加 UTF-8 超链接后继续添加 START 超链接,见蓝色代码
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
s += "<td><a href='/logs/scrapyd.html?opt=schedule&project=%s&job_or_spider=%s' target='_blank'>START</a></td>" % (p.project, p.spider) ########
(3) 完整代码
from datetime import datetime import socket from twisted.web import resource, static
from twisted.application.service import IServiceCollection from scrapy.utils.misc import load_object from .interfaces import IPoller, IEggStorage, ISpiderScheduler from six.moves.urllib.parse import urlparse class Root(resource.Resource): def __init__(self, config, app):
resource.Resource.__init__(self)
self.debug = config.getboolean('debug', False)
self.runner = config.get('runner')
logsdir = config.get('logs_dir')
itemsdir = config.get('items_dir')
local_items = itemsdir and (urlparse(itemsdir).scheme.lower() in ['', 'file'])
self.app = app
self.nodename = config.get('node_name', socket.gethostname())
self.putChild(b'', Home(self, local_items))
if logsdir:
self.putChild(b'logs', static.File(logsdir.encode('ascii', 'ignore'), 'text/plain'))
if local_items:
self.putChild(b'items', static.File(itemsdir, 'text/plain'))
self.putChild(b'jobs', Jobs(self, local_items))
services = config.items('services', ())
for servName, servClsName in services:
servCls = load_object(servClsName)
self.putChild(servName.encode('utf-8'), servCls(self))
self.update_projects() def update_projects(self):
self.poller.update_projects()
self.scheduler.update_projects() @property
def launcher(self):
app = IServiceCollection(self.app, self.app)
return app.getServiceNamed('launcher') @property
def scheduler(self):
return self.app.getComponent(ISpiderScheduler) @property
def eggstorage(self):
return self.app.getComponent(IEggStorage) @property
def poller(self):
return self.app.getComponent(IPoller) class Home(resource.Resource): def __init__(self, root, local_items):
resource.Resource.__init__(self)
self.root = root
self.local_items = local_items def render_GET(self, txrequest):
vars = {
'projects': ', '.join(self.root.scheduler.list_projects())
}
s = """
<html>
<head><meta charset='UTF-8'><title>Scrapyd</title></head>
<body>
<h1>Scrapyd</h1>
<p>Available projects: <b>%(projects)s</b></p>
<ul>
<li><a href="/jobs">Jobs</a></li>
""" % vars
if self.local_items:
s += '<li><a href="/items/">Items</a></li>'
s += """
<li><a href="/logs/">Logs</a></li>
<li><a href="http://scrapyd.readthedocs.org/en/latest/">Documentation</a></li>
</ul> <h2>How to schedule a spider?</h2> <p>To schedule a spider you need to use the API (this web UI is only for
monitoring)</p> <p>Example using <a href="http://curl.haxx.se/">curl</a>:</p>
<p><code>curl http://localhost:6800/schedule.json -d project=default -d spider=somespider</code></p> <p>For more information about the API, see the <a href="http://scrapyd.readthedocs.org/en/latest/">Scrapyd documentation</a></p>
</body>
</html>
""" % vars
return s.encode('utf-8') class Jobs(resource.Resource): def __init__(self, root, local_items):
resource.Resource.__init__(self)
self.root = root
self.local_items = local_items def render(self, txrequest):
cols = 10 ######## 8
s = "<html><head><meta charset='UTF-8'><title>Scrapyd</title></head>"
s += "<body>"
s += "<h1>Jobs</h1>"
s += "<p><a href='..'>Go back</a></p>"
s += "<table border='1'>"
s += "<tr><th>Project</th><th>Spider</th><th>Job</th><th>PID</th><th>Start</th><th>Runtime</th><th>Finish</th><th>Log</th>"
if self.local_items:
s += "<th>Items</th>"
#cols = 9 ########
cols += 1 ########
s += "</tr>"
s += "<tr><th colspan='%s' style='background-color: #ddd'>Pending</th></tr>" % cols
for project, queue in self.root.poller.queues.items():
for m in queue.list():
s += "<tr>"
s += "<td>%s</td>" % project
s += "<td>%s</td>" % str(m['name'])
s += "<td>%s</td>" % str(m['_job'])
s += "</tr>"
s += "<tr><th colspan='%s' style='background-color: #ddd'>Running</th></tr>" % cols
for p in self.root.launcher.processes.values():
s += "<tr>"
for a in ['project', 'spider', 'job', 'pid']:
s += "<td>%s</td>" % getattr(p, a)
s += "<td>%s</td>" % p.start_time.replace(microsecond=0)
s += "<td>%s</td>" % (datetime.now().replace(microsecond=0) - p.start_time.replace(microsecond=0))
s += "<td></td>"
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
s += "<td><a href='/logs/scrapyd.html?opt=cancel&project=%s&job_or_spider=%s' target='_blank'>STOP</a></td>" % (p.project, p.job) ########
if self.local_items:
s += "<td><a href='/items/%s/%s/%s.jl'>Items</a></td>" % (p.project, p.spider, p.job)
s += "</tr>"
s += "<tr><th colspan='%s' style='background-color: #ddd'>Finished</th></tr>" % cols
for p in self.root.launcher.finished:
s += "<tr>"
for a in ['project', 'spider', 'job']:
s += "<td>%s</td>" % getattr(p, a)
s += "<td></td>"
s += "<td>%s</td>" % p.start_time.replace(microsecond=0)
s += "<td>%s</td>" % (p.end_time.replace(microsecond=0) - p.start_time.replace(microsecond=0))
s += "<td>%s</td>" % p.end_time.replace(microsecond=0)
s += "<td><a href='/logs/%s/%s/%s.log'>Log</a></td>" % (p.project, p.spider, p.job)
s += "<td><a href='/logs/UTF-8.html?project=%s&spider=%s&job=%s' target='_blank'>UTF-8</a></td>" % (p.project, p.spider, p.job) ########
s += "<td><a href='/logs/scrapyd.html?opt=schedule&project=%s&job_or_spider=%s' target='_blank'>START</a></td>" % (p.project, p.spider) ########
if self.local_items:
s += "<td><a href='/items/%s/%s/%s.jl'>Items</a></td>" % (p.project, p.spider, p.job)
s += "</tr>"
s += "</table>"
s += "</body>"
s += "</html>" txrequest.setHeader('Content-Type', 'text/html; charset=utf-8')
txrequest.setHeader('Content-Length', len(s)) return s.encode('utf-8')
/site-packages/scrapyd/website.py
3.新建 scrapyd.html
根据 http://scrapyd.readthedocs.io/en/stable/config.html 确定 Scrapyd 所使用的 logs_dir,在该目录下添加如下文件
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>scrapyd</title>
</head> <body>
<p>仅用于内网环境下执行 scrapyd API</p>
<div id="result"></div> <script>
function parseQueryString(url) {
var urlParams = {};
url.replace(
new RegExp("([^?=&]+)(=([^&]*))?", "g"),
function($0, $1, $2, $3) {
urlParams[$1] = $3;
}
);
return urlParams;
} function curl(opt, project, job_or_spider) {
console.log(opt);
console.log(project);
console.log(job_or_spider);
var formdata = new FormData();
formdata.append('project', project);
if(opt == 'cancel') {
formdata.append('job', job_or_spider);
} else {
formdata.append('spider', job_or_spider);
} var req = new XMLHttpRequest();
req.onreadystatechange = function() {
if (this.readyState == 4) {
if (this.status == 200) {
document.querySelector('#result').innerHTML = this.responseText;
} else {
alert('status code: ' + this.status);
}
} else {
document.querySelector('#result').innerHTML = this.readyState;
}
};
req.open('post', window.location.protocol+'//'+window.location.host+'/'+opt+'.json', Async = true); req.send(formdata);
} var kwargs = parseQueryString(location.search);
if (kwargs.opt == 'cancel' || kwargs.opt == 'schedule') {
curl(kwargs.opt, kwargs.project, kwargs.job_or_spider);
}
</script>
</body>
</html>
scrapyd.html
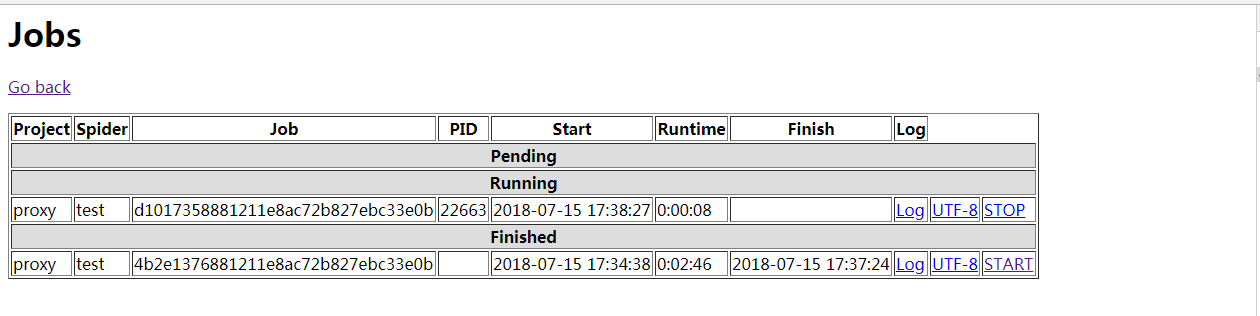
4.实现效果
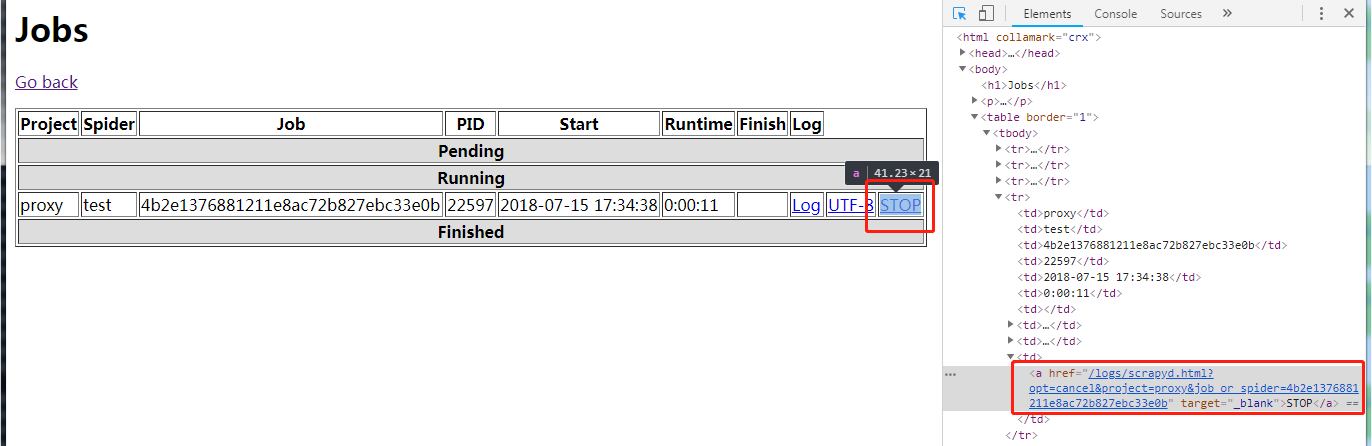
(1) 点击 STOP 超链接

(2) 返回 Jobs 页面
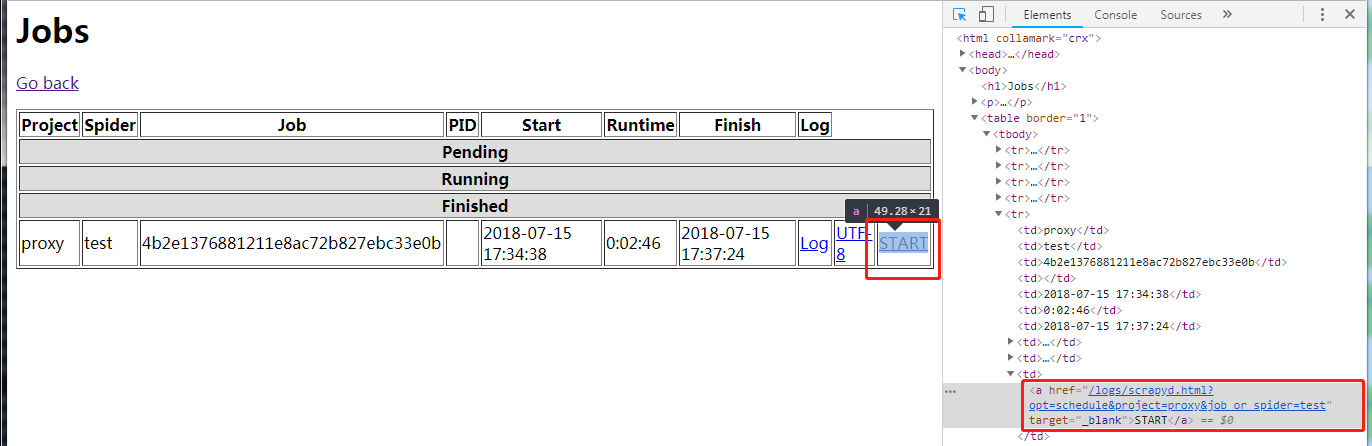
(3) 点击 START 超链接

(4) 返回 Jobs 页面
Scrapyd 改进第二步: Web Interface 添加 STOP 和 START 超链接, 一键调用 Scrapyd API的更多相关文章
- Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码
0.问题现象和原因 如下图所示,由于 Scrapyd 的 Web Interface 的 log 链接直接指向 log 文件,Response Headers 的 Content-Type 又没有声明 ...
- Hive- Hive Web Interface
当我们安装好hive时候,我们启动hive的UI界面的时候,命令: hive –-service hwi ,报错,没有war包 我们查看hive/conf/hive-default.xml.templ ...
- django web 中添加超链接
django web 中添加不传参的超链接的方法如下: html: 在web中的超链接中加入一下url <a href="{% url 'app_name.views.url_func ...
- kubernetes Helm-chart web UI添加
charts web ui 添加chart仓库 helm repo add cherryleo https://fileserver-1253732882.cos.ap-chongqing.myqcl ...
- Hive Web Interface的安装
Hive Web Interface,简称hwi,是Hive的Web接口. 首先,安装ant,下载ant,解压,并在/etc/profile中设置: export ANT_HOME=/opt/apac ...
- maven 如何给web项目添加jar包依赖
maven 如何给web项目添加jar包依赖 CreateTime--2018年4月19日19:06:21 Author:Marydon 开发工具:eclipse 1.打开pom.xml文件--& ...
- 通过J2EE Web工程添加Flex项目,进行BlazeDS开发
http://www.cnblogs.com/noam/archive/2010/07/22/1782955.html 环境:Eclipse 7.5 + Flex Builder 4 plugin f ...
- 为Azure Web Site 添加ADFS验证支持之二 在代码里使用ADFS
下面我们来创建一个MVC 5.0的ASP.Net程序,并且将它部署到Azure Web Site上 通过Visual Studio 2015创建Web Project 在选择ASP.net模板的地方, ...
- 为Azure Web Site 添加ADFS验证支持之一 设置ADFS的信任关系
很多时候企业开发的应用都会通过AD(Active Directory)进行验证用户名密码的,在企业里面统一一个AD来进行账号密码管理也是一个很好的实践.当企业打算将一个应用迁移到Azure的时候,使用 ...
随机推荐
- Spring WebFlux 要革了谁的命?
Spring WebFlux 要革了谁的命? mp.weixin.qq.com 托梦 Java国王昨晚做了一个梦. 梦中有个白胡子老头儿,颇有仙风道骨, 告诉他说:“你们Java啊,实在是太弱了,连 ...
- 关于Aop切面中的@Before @Around等操作顺序的说明
[转]http://www.cnblogs.com/softidea/p/6123307.html 话不多说,直接上代码: package com.cdms.aop.aspectImpl; impor ...
- Java程序设计第一次作业
虽说这学期Java比上学期的C语言要简单些许,但是初次面对java程序,还是有点难度的.
- python通过套接字来发送接收消息
案例如下: 1.启动一个服务端套接字服务 2.启动一个客户端套接字服务 3.客户端向服务端发送一个hello,服务端则回复一个word,并打印 参考地址:https://www.cnblogs.com ...
- 【转】TEA、XTEA、XXTEA加密解密算法(C语言实现)
ref : https://blog.csdn.net/gsls200808/article/details/48243019 在密码学中,微型加密算法(Tiny Encryption Algorit ...
- JGUI源码:实现简单进度条(19)
程序效果如下 实现进度条动画主要有两种方法:(1)使用缓动,(2)使用Jquery Animate,本文使用第二种方法,先实现代码,后续进行控件封装 <style> .jgui-proce ...
- Studio 5000 指针(间接寻址)编程
前言:自动化控制系统是综合性.复杂性的,处于现场层的PLC控制器虽然进行各种控制,但最终还是对数据进行处理,对数据的处理,包含两种方式,一种是直接使用,第二种就是间接使用.针对第二种处理方式,就要用 ...
- map集合的常用方法
package test; import java.util.Collection; import java.util.HashMap; import java.util.Map; import ja ...
- 入坑DL CV 一些基础技能学习
进入实验室学习了一个月左右,记录一下新手入门所学的基本知识,都是入门级别的教程 1.Python 快速入门:廖雪峰Python教程--> https://www.liaoxuefeng.com/ ...
- Selective Kernel Network
senet: https://arxiv.org/abs/1709.01507 sknet: http://arxiv.org/abs/1903.06586 TL, DR Selective Kern ...